Spark Key-Value RDD操作
下述操作在Spark shell中
RDD整体上分为Value 类型和 Key-Value类型。
实际使用更多的是key-value 类型的RDD,也称为PairRDD
Value 类型RDD的操作基本集中在 RDD.scala 中
key-value 类型的RDD操作集中在 PairRDDFunctions.scala 中;
1.1 创建Pair RDD
val arr = (1 to 10).toArray
val arr1 = arr.map(x => (x, x*10, x*100))
// rdd1 不是 Pair RDD
val rdd1 = sc.makeRDD(arr1)
// rdd2 是 Pair RDD
val arr2 = arr.map(x => (x, (x*10, x*100)))
val rdd2 = sc.makeRDD(arr2)
Pair RDD需要有明确的key,当时用collectAsMap不会出现异常
scala> rdd1.collectAsMap
<console>:26: error: value collectAsMap is not a member of org.apache.spark.rdd.RDD[(Int, Int, Int)]
rdd1.collectAsMap
scala> rdd2.collectAsMap
res3: scala.collection.Map[Int,(Int, Int)] = Map(8 -> (80,800), 2 -> (20,200), 5 -> (50,500), 4 -> (40,400), 7 -> (70,700), 10 -> (100,1000), 1 -> (10,100), 9 -> (90,900), 3 -> (30,300), 6 -> (60,600))
1.2 Transformation操作
-
类似 map 操作
-
mapValues 实现交换value(Int,Int)的值
scala> rdd2.collect res25: Array[(Int, (Int, Int))] = Array((1,(10,100)), (2,(20,200)), (3,(30,300)), (4,(40,400)), (5,(50,500)), (6,(60,600)), (7,(70,700)), (8,(80,800)), (9,(90,900)), (10,(100,1000))) scala> rdd2.mapValues(x => (x._2,x._1)).collect res26: Array[(Int, (Int, Int))] = Array((1,(100,10)), (2,(200,20)), (3,(300,30)), (4,(400,40)), (5,(500,50)), (6,(600,60)), (7,(700,70)), (8,(800,80)), (9,(900,90)), (10,(1000,100))) ## map实现 scala> rdd2.map{case (x,y)=>(x,(y._2,y._1))}.collect res28: Array[(Int, (Int, Int))] = Array((1,(100,10)), (2,(200,20)), (3,(300,30)), (4,(400,40)), (5,(500,50)), (6,(600,60)), (7,(700,70)), (8,(800,80)), (9,(900,90)), (10,(1000,100))) -
flatMapValues压平操作
scala> val a = sc.parallelize(List((1,2),(3,4),(5,6))) a: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[15] at parallelize at <console>:24 scala> a.flatMapValues(x => 1 to x).collect res37: Array[(Int, Int)] = Array((1,1), (1,2), (3,1), (3,2), (3,3), (3,4), (5,1), (5,2), (5,3), (5,4), (5,5), (5,6))map实现scala> a.mapValues(x=> 1 to x).flatMap{case (x,y)=>{y.map(z=>(x,z))}}.collect res39: Array[(Int, Int)] = Array((1,1), (1,2), (3,1), (3,2), (3,3), (3,4), (5,1), (5,2), (5,3), (5,4), (5,5), (5,6)) -
keys
scala> a.keys.collect res41: Array[Int] = Array(1, 3, 5)map实现scala> a.map{case (k, v) => k}.collect res43: Array[Int] = Array(1, 3, 5) -
values
scala> a.keys.collect res41: Array[Int] = Array(1, 3, 5)map实现scala> a.map{case (k, v) => v}.collect res44: Array[Int] = Array(2, 4, 6)
1.3 聚合操作
主要有groupByKey / reduceByKey / foldByKey / aggregateByKey 其底层实现调用了下列两种
combineByKey(老版本) / combineByKeyWithClassTag (新版本)
subtractByKey:类似于subtract,删掉 RDD 中键与 other RDD 中的键相同的元素
求平均价格scala> val rdd = sc.makeRDD(Array(("Java", 12), ("C++", 26),("C", 23), ("Java", 15), ("scala", 26),("spark", 25),("C", 21), ("Java", 16), ("scala", 24), ("scala", 16))) rdd: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[24] at makeRDD at <console>:24-
groupByKey 通过key聚合,聚合后主键为key,value为Iterable
scala> rdd.groupByKey.collect res46: Array[(String, Iterable[Int])] = Array((Java,CompactBuffer(16, 12, 15)), (C++,CompactBuffer(26)), (spark,CompactBuffer(25)), (scala,CompactBuffer(26, 16, 24)), (C,CompactBuffer(23, 21))) scala> rdd.groupByKey.map{case (x,y)=>(x, y.sum.toDouble / y.size)}.collect res49: Array[(String, Double)] = Array((Java,14.333333333333334), (C++,26.0), (spark,25.0), (scala,22.0), (C,22.0)) scala> rdd.groupByKey.mapValues (y=> y.sum.toDouble / y.size).collect res50: Array[(String, Double)] = Array((Java,14.333333333333334), (C++,26.0), (spark,25.0), (scala,22.0), (C,22.0)) -
reduceByKey
scala> rdd.mapValues(v =>(v,1)).reduceByKey((x,y) => (x._1+y._1, x._2+y._2)).mapValues(x=>x._1.toDouble / x._2).collect res52: Array[(String, Double)] = Array((Java,14.333333333333334), (C++,26.0), (spark,25.0), (scala,22.0), (C,22.0)) -
foldByKey
scala> rdd.mapValues(v =>(v,1)).foldByKey((0,0))((x,y) => (x._1+y._1, x._2+y._2)).mapValues(x=>x._1.toDouble / x._2).collect res57: Array[(String, Double)] = Array((Java,14.333333333333334), (C++,26.0), (spark,25.0), (scala,22.0), (C,22.0)) -
aggregateByKey => 定义初值 + 分区内的聚合函数 + 分区间的聚合函数
scala> rdd.mapValues(v =>(v,1)).aggregateByKey((0,0))((x,y)=>(x._1+y._1, x._2+y._2), (a,b)=>(a._1+b._1, a._2+b._2)).mapValues(x=>x._1.toDouble / x._2).collect res61: Array[(String, Double)] = Array((Java,14.333333333333334), (C++,26.0), (spark,25.0), (scala,22.0), (C,22.0)) scala> rdd.aggregateByKey((0,0))((x,y)=>(x._1+y, x._2+1), (a,b)=>(a._1+b._1, a._2+b._2)).mapValues(x=>x._1.toDouble / x._2).collect res63: Array[(String, Double)] = Array((Java,14.333333333333334), (C++,26.0), (spark,25.0), (scala,22.0), (C,22.0))
groupByKey在一般情况下效率低,尽量少用
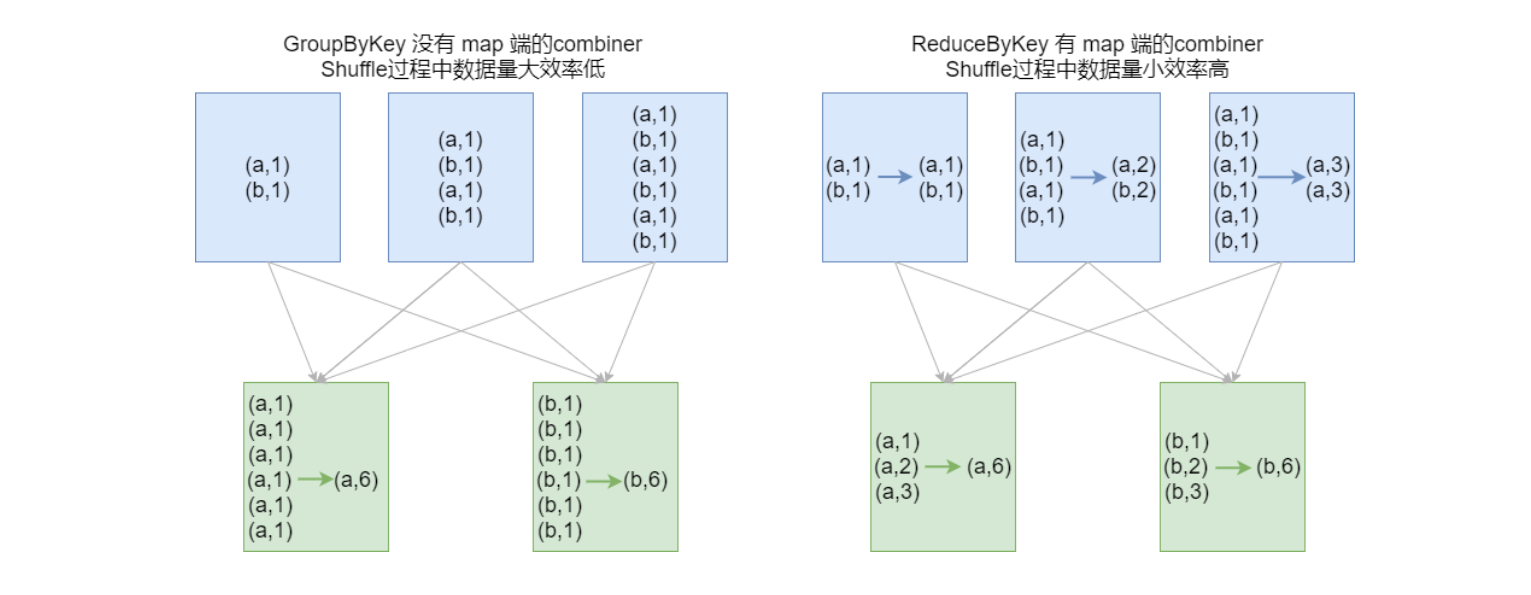
-
1.4 Join操作
cogroup / join / leftOuterJoin / rightOuterJoin / fullOuterJoin
scala> val rdd1 = sc.makeRDD(Array((1,"Spark"), (2,"Hadoop"), (3,"Kylin"), (4,"Flink")))
rdd1: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[50] at makeRDD at <console>:24
scala> val rdd2 = sc.makeRDD(Array((3,"李四"), (4,"王五"), (5,"赵六"), (6,"冯七")))
rdd2: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[51] at makeRDD at <console>:24
scala> val rdd3 = rdd1.cogroup(rdd2)
rdd3: org.apache.spark.rdd.RDD[(Int, (Iterable[String], Iterable[String]))] = MapPartitionsRDD[53] at cogroup at <console>:27
scala> rdd3.collect.foreach(println)
(1,(CompactBuffer(Spark),CompactBuffer()))
(2,(CompactBuffer(Hadoop),CompactBuffer()))
(3,(CompactBuffer(Kylin),CompactBuffer(李四)))
(4,(CompactBuffer(Flink),CompactBuffer(王五)))
(5,(CompactBuffer(),CompactBuffer(赵六)))
(6,(CompactBuffer(),CompactBuffer(冯七)))
val rdd1 = sc.makeRDD(Array(("1","Spark"),("2","Hadoop"),
("3","Scala"),("4","Java")))
val rdd2 = sc.makeRDD(Array(("3","20K"),("4","18K"),
("5","25K"),("6","10K")))
rdd1.join(rdd2).collect
rdd1.leftOuterJoin(rdd2).collect
rdd1.rightOuterJoin(rdd2).collect
rdd1.fullOuterJoin(rdd2).collect
1.5 Action操作
collectAsMap / countByKey / lookup(key)
lookup(key):高效的查找方法,只查找对应分区的数据(如果RDD有分区器的话)
val rdd1 = sc.makeRDD(Array(("1","Spark"),("2","Hadoop"),
("3","Scala"),("1","Java")))
val rdd2 = sc.makeRDD(Array(("3","20K"),("4","18K"),
("5","25K"),("6","10K")))
rdd1.lookup("1")
rdd2.lookup("3")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号