Java第三单元总结
一、JML语言的理论基础、应用工具链情况
JML:
(1)概述
Java建模语言(Java Modeling Language, JML)是一种用来进行详细设计的表示法,它倡导一种思考方法和类的新思路。JML将注释添加到Java代码中,让我们能够去描述方法预期的功能,而不必去说明如何做到这一点,这样JML就把面向对象拓展到了方法设计阶段。
为了能够对于功能进行说明,JML引入了许多的构造,包括模型字段、量词、断言的可见度范围、前置条件、后置条件、异常行为的规范等。
(2)注释方式
JML以javadoc注释的方式来表示规格,每行都以@起头。有两种注释方式,行注释和块注释。
行注释://@annotation
块注释:/*@ annotation @*/
(3)JML表达式构成
<1>原子表达式:
\result:表示一个非void类型的方法执行所获得的结果,即方法执行的返回值。
\old(expr):表示一个表达式expr在相应方法执行前的取值。
\not_assigned(x,y,...):用来表示括号中的变量是否在方法执行过程中被赋值。
\not_modifieded(x,y,...):限制括号中的变量在方法执行期间的取值未发生变化。
\nonnullelements(container):表示container对象中存储的对象不会有null。
\type(type):返回类型type对应的类型。
\typeof(expr):返回expr对应的准确类型。
<2>量化表达式:
\forall:全称量词修饰的表达式。表示给定范围内的元素都要满足相对应的约束条件。
\exists:存在量词修饰的表达式。表示给定范围内存在元素满足相对应的约束条件。
\sum:返回给定范围内的表达式的和。
\product:返回给定范围内的表达式的连乘结果。
\max:返回给定范围内的表达式的最大值。
\min:返回给定范围内的表达式的最小值。
\num_of:返回指定变量中满足相应条件的取值个数。
<3>综合表达式:
可以在JML规格中构造一个局部的集合(容器),明确集合中可以包含的元素。例如:
new JMLObjectSet{Integer i | s.contains(i) && 0 < i.intvalue()}
<4>操作符
子关系操作符:E1<:E2,E1为E2的子类型或者相同类型时为真,否则为假。
等价关系操作符:b_expr1<=>b_expr2,表示b_expr1== b_expr2。
推理操作符:b_expr1==>b_expr2,表示除了b_expr1==true且b_expr2==false的情况外整个表达式的值为true。
变量引用操作符:\nothing(表示一个空集)、\evething(表示一个全集)。
<5>方法规格
前置条件:对输入参数的限制,方法输入必须满足前置条件。(requires p)
后置条件:对输出参数的限制,执行结果需要满足后置条件。(ensures q)
副作用范围限定:方法在执行过程中对对象的属性数据或者类的静态成员数据进行修改的副作用范围。(modifiable、assignable)
signals子句:signals (***Exception e) b_expr,满足b_expr==true时抛出异常。
<6>类型规格
不变式:要求在所有可见状态下都必须满足的特性(invariant p)
状态变化约束:对前序可见状态和当前可见状态的关系进行约束。(constraint)
JML工具链:
OpenJML:进行规格的检查。
JMLUnit:自动生成测试样例对于程序进行检测。
二、部署JMLUnitNG/JMLUnit
由于在使用过程中,\forall等部分表达式可能存在不被软件所“接受”的情况存在,所以我自己编写了一个较为简单的程序。代码如下:
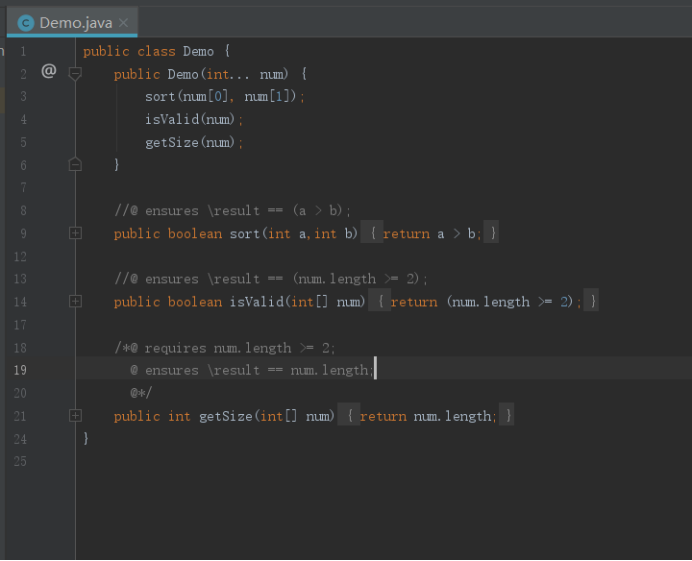
经过检查之后,我获得了以下的结果,即为:
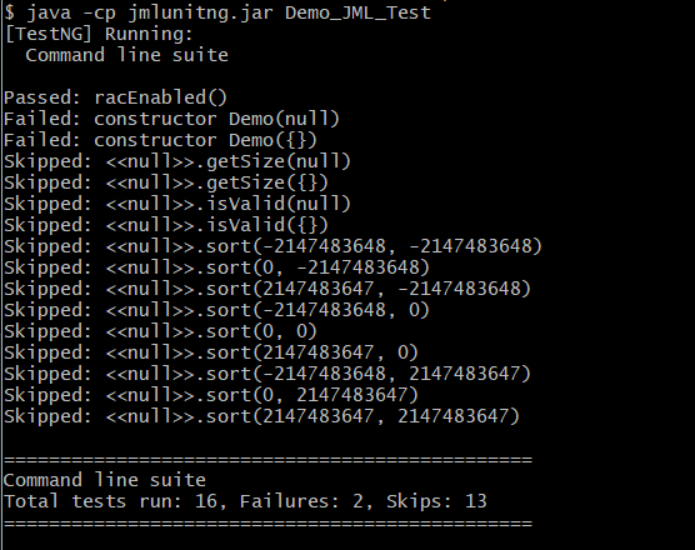
实现结果基本符合预期。
三、架构设计
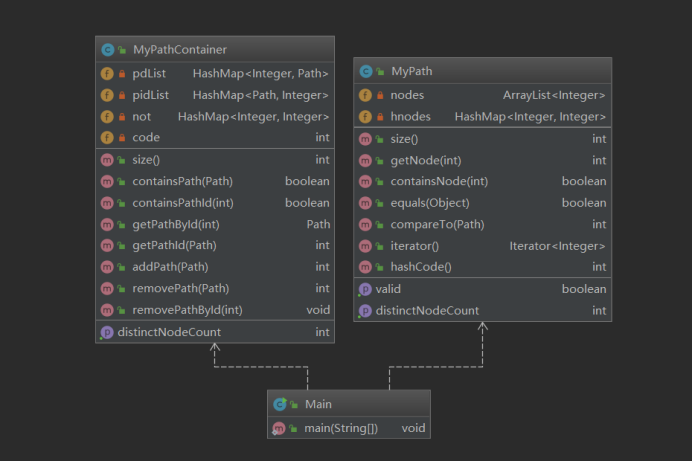
(1)第一次作业
第一次作业的主体要求是对于path的添加删除和查询,主要是为了让我们熟悉jml规格的理解和初步实现。由于指令较为简单,这次作业只需要将path和对应的id存入Hashmap或者是ArrayList中即可以实现这些功能。在架构上由于我们不需要对于这些path所构成的图进行操作,所以并没有太多的注意点。
主体架构如下:
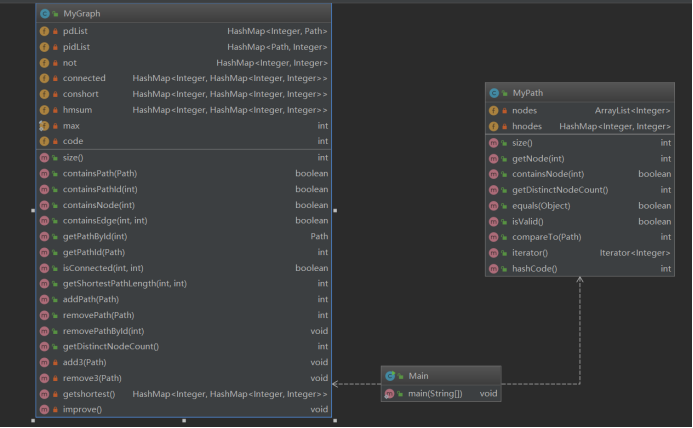
(2)第二次作业
相较于第一次作业,第二次作业主要是增加了对于path所建立的图中各节点之间的最短距离进行计算。因此在继承上一次作业的架构上,我将每个path上各节点与其他节点之间的连线存入一个新的Hashmap中(Hashmap<Integer, Hashmap<Integer, Integer>>,前两个Integer存入对应的节点id,后一个是两个节点之间的距离,相当于一个邻接矩阵)。在这个Hashmap的基础上利用弗洛伊德算法进行每个节点与其他节点之间最短距离之间的更新,这就是第二次作业的大体架构。
主体架构如下:
(3)第三次作业
在第二次作业的基础上引入了“权”的概念是我们第三次作业的亮点。这也就意味着我们无法直接套用第二次作业的架构。在我的新的架构中,最低票价和最少不满意度的计算我只是在第二次作业中的Hashmap进行了一定的修改,将所存储的距离加上了换乘的代价(票价2元或是32不满意度),这样在实际的计算过程中我们大概能模拟最短距离的计算(需要保证存储的数据永远是实际票价或者不满意度加上1个换乘代价)就可以实现最低票价或者是最少不满意度的计算。
而最小换乘则是将每条path上的节点之间的距离设为1,存入类似的Hashmap中。这样我们一样是模拟最短距离的计算,只有换乘才会导致距离的增加,即我们算法得到的最后距离即为换乘次数+1,实现了最小换乘的计算。
主体架构如下:
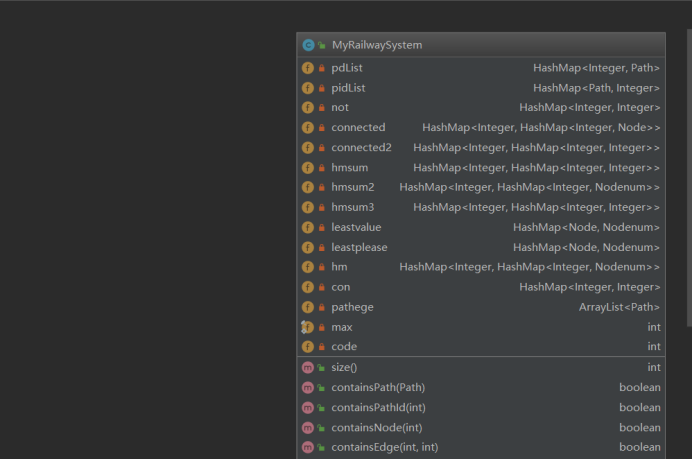
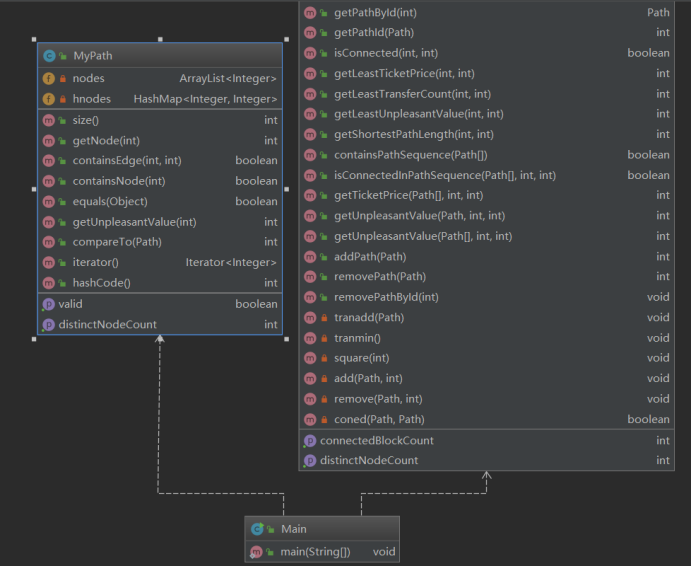
四、作业中的bug及修复
在本单元的作业中,我的bug主要出现在第二和第三次作业中。
(1)第二次作业
bug:在利用path间各点之间的最短距离的邻接矩阵时,我的算法应该以现存的点作为n进行弗洛伊德算法,复杂度应该为o(n3);但在实际操作的过程中,我只是将在path_remove中被删除的点所包含的信息全部清除,但是并未将该节点从列表中删除,导致遍历时的n中包含了被删除的节点,遍历时间变长,最终导致超时。
修复:在path_remove时,判断了该节点是否还存在于图中,若不存在,则删除。如下图:
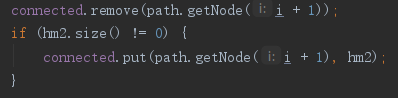
这样就保证了遍历的n与现存节点个数完全相同。
(2)第三次作业
bug:存在计算连通块的个数时的错误和tle两个bug,但在实际修复中其实只是计算连通块中一个bug(由于这个bug导致了tle)。我在计算连通块过程中想利用并查集,但在实际操作过程中两个连通块合并时只是将连通块b中与a中(添加了一条path后)相连的path转移到a中,而没有去找这两个连通块的父节点,导致了错误。
修复:寻找每个连通块的父节点,将其中一个的父节点指向另一个的父节点。如下图:

这样就能实现连通块的合并。
五、心得体会
这个单元的作业以jml规格为约束条件,指引我们通过对jml规格的分析填写能够实现相对应功能的代码,并在代码实现的基础上对于我们的运行时间有了一定的限制,强化了我们对于代码性能的重视程度,让我们在写程序时不至于像之前一样只重视功能的实现,而不在意如何对于现有的程序进行优化。
总体来说,我在这个单元的代码编写过程中最主要碰到的问题就是如何能够尽量降低程序的复杂度以加快程序的运行。无论是便利时遍历对象的选择,或是遍历方法的选择,都是我在这个单元的作业中所需要去关注的。这种对于方法优劣的对比是必要的,也是我们在接下来的学习生活中不得不去重视的一个话题。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号