1. 搭建scapy
参考手册上,用http://www.dmoz.org/里的demo来快速入门
创建一个新的Scrapy项目
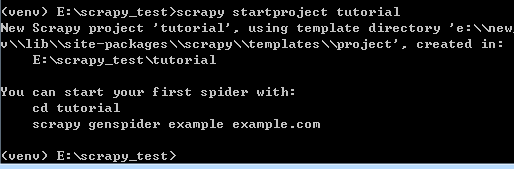
创建好后,工程目录如下:
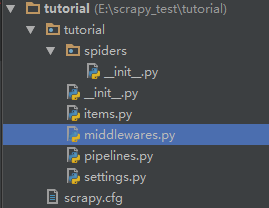
scrapy.cfg: 项目的配置文件。
tutorial/: 该项目的python模块。之后您将在此加入代码。
tutorial/items.py: 项目中的item文件。
tutorial/pipelines.py: 项目中的pipelines文件。
tutorial/settings.py: 项目的设置文件。
tutorial/spiders/: 放置spider代码的目录。
定义一个item保存数据
import scrapy class DemoItem(scrapy.Item): title = scrapy.Field() link = scrapy.Field() desc = scrapy.Field()
编写第一个爬虫(Spider)
# -*- coding: utf-8 -*- import scrapy class DmozSpider(scrapy.Spider): name = "dmoz" allowed_domains = ["dmoz.org"] start_urls = [ "http://www.dmoz.org/Computers/Programming/Languages/Python/Books/", "http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/" ] def parse(self, response): filename = response.url.split("/")[-2] with open(filename, 'wb') as f: f.write(response.body)
创建一个Spider,您必须继承 Scrapy.Spider类, 且定义以下三个属性:
name: 用于区别Spider。 该名字必须是唯一的,您不可以为不同的Spider设定相同的名字。
start_urls: 包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取。
parse:是spider的一个方法。 被调用时,每个初始URL完成下载后生成的Response 对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request对象。
启动
进入tutorial 执行命令 scrapy crawl dmoz
悲剧了!

安装pywin32包,找了一圈只找到exe包,安装时出现这样的问题

路径改不了。。。没发装在virtualenv环境
继续google,,呵呵呵最后通过注册表搞定
HKEY_LOCAL_MACHINE\SOFTWARE\Python\PythonCore\2.7\InstallPath
把“默认”字符串值修改成virtualenv的路径就好了。
小插曲后,运行命令启动,OK。。。

查看包含 [dmoz] 的输出,可以看到输出的log中包含定义在 start_urls 的初始URL,并且与spider中是一一对应的。在log中可以看到其没有指向其他页面( (referer:None) )。
除此之外,如同 parse 方法指定的那样,有两个包含url所对应的内容的文件被创建了: Book , Resources 。
Scrapy为Spider的 start_urls 属性中的每个URL创建了 scrapy.Resquest 对象,并将 parse 方法作为回调函数(callback)赋值给了Request。
Request对象经过调度,执行生成 scrapy.http.Response 对象并送回给spider parse() 方法。
提取Item
得到了数据,需要把所需要的东西提取出来(Scrapy Selectors)。
进入项目的根目录,执行下列命令来启动shell(先安装好IPython,通过pip install ipython):
scrapy shell "http://www.dmoz.org/Computers/Programming/Languages/Python/Books/"

shell根据response初始化selector,可以使用selector的方法来分析
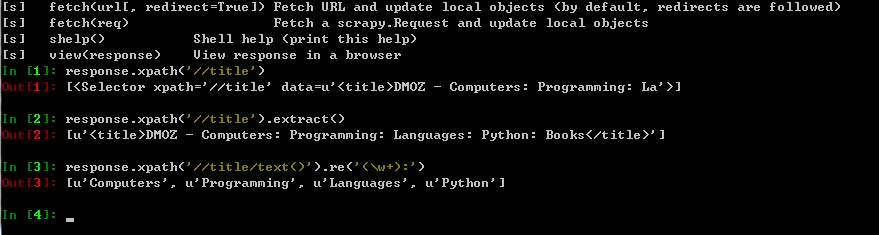
提取数据
每个.xpath()返回selector组成的List, 可以通过多个.xpath()来获取某个节点。
# -*- coding: utf-8 -*- import scrapy class DmozSpider(scrapy.Spider): name = "dmoz" allowed_domains = ["dmoz.org"] start_urls = [ "http://www.dmoz.org/Computers/Programming/Languages/Python/Books/", "http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/" ] def parse(self, response): # filename = response.url.split("/")[-2] # with open(filename, 'wb') as f: # f.write(response.body) for sel in response.xpath("//ul/li"): title = sel.xpath('a/text()').extract() link = sel.xpath('a/@href').extract() desc = sel.xpath('text()').extract() print title, link, desc
再次用命令,scrapy crawl dmoz启动时可看到网站信息

保存爬取到的数据
使用
scrapy crawl dmoz -o items.json,输出爬取的数据采用json格式序列化,并生成items.json


 浙公网安备 33010602011771号
浙公网安备 33010602011771号