
Python实现简单遗传算法(SGA)
Simple Genetic Alogrithm是模拟生物进化过程而提出的一种优化算法。SGA采用随机导向搜索全局最优解或者说近似全局最优解。传统的爬山算法(例如梯度下降,牛顿法)一次只优化一个解,并且对于多峰的目标函数很容易陷入局部最优解,而SGA算法一次优化一个种群(即一次优化多个解),SGA比传统的爬山算法更容易收敛到全局最优解或者近似全局最优解。 SGA基本流程如下:
1、对问题的解进行二进制编码。编码涉及精度的问题,在本例中精度delta=0.0001,根据决策变量的上下界确定对应此决策变量的染色体基因的长度(m)。假设一个决策变量x0上界为upper,下界为lower,则精度delta = (upper-lower)/2^m-1。如果已知决策变量边界和编码精度,那么可以用下面的公式确定编码决策变量x0所对应的染色体长度:
2^(length-1)<(upper-lower)/delta<=2^length-1
2、对染色体解码得到表现形:
解码后得到10进制的值;decoded = lower + binary2demical(chromosome)*delta。其中binary2demical为二进制转10进制的函数,在代码中有实现,chromosome是编码后的染色体。
3、确定初始种群,初始种群随机生成
4、根据解码函数得到初始种群的10进制表现型的值
5、确定适应度函数,对于求最大值最小值问题,一般适应度函数就是目标函数。根据适应度函数确定每个个体的适应度值Fi=FitnessFunction(individual);然后确定每个个体被选择的概率Pi=Fi/sum(Fi),sum(Fi)代表所有个体适应度之和。
6、根据轮盘赌选择算子,选取适应度较大的个体。一次选取一个个体,选取n次,得到新的种群population
7、确定交叉概率Pc,对上一步得到的种群进行单点交叉。每次交叉点的位置随机。
8、确定变异概率Pm,假设种群大小为10,每个个体染色体编码长度为33,则一共有330个基因位,则变异的基因位数是330Pm。接下来,要确定是那个染色体中哪个位置的基因发生了变异。将330按照10进制序号进行编码即从0,1,2,.......229。随机从330个数中选择330Pm个数,假设其中一个数时154,chromosomeIndex = 154/33 =4, geneIndex = 154%33 = 22。由此确定了第154号位置的基因位于第4个染色体的第22个位置上,将此位置的基因值置反完成基本位变异操作。
9、以上步骤完成了一次迭代的所有操作。接下就是评估的过程。对变异后得到的最终的种群进行解码,利用解码值求得每个个体的适应度值,将最大的适应度值保存下来,对应的解码后的决策变量的值也保存下来。
10、根据迭代次数,假设是500次,重复执行1-9的步骤,最终得到是一个500个数值的最优适应度取值的数组以及一个500n的决策变量取值数组(假设有n个决策变量)。从500个值中找到最优的一个(最大或者最小,根据定义的适应度函数来选择)以及对应的决策变量的取值。 对于以上流程不是很清楚的地方,在代码中有详细的注释。也可以自行查找资料补充理论。本文重点是实现 本代码实现的问题是: maxf(x1,x2) = 21.5+x1sin(4pix1)+x2sin(20pi*x2) s.t. -3.0<=x1<=12.1 4.1<=x2<=5.8
初始种群的编码结果如下图所示:

初始种群的解码结果如下图所示:
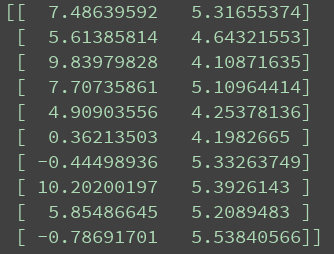
适应度值如图所示:
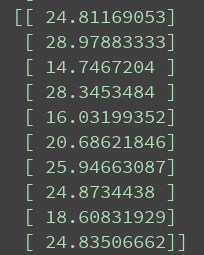
轮盘赌选择后的种群如图所示;

单点交叉后的种群如图所示:

基本位变异后的种群如图所示;

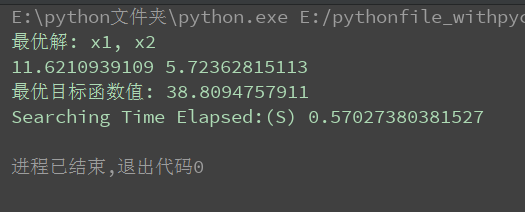
最终结果如下图所示;
源代码如下;
# !/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: wsw
# 简单实现SGA算法
import numpy as np
from scipy.optimize import fsolve, basinhopping
import random
import timeit
# 根据解的精度确定染色体(chromosome)的长度
# 需要根据决策变量的上下边界来确定
def getEncodedLength(delta=0.0001, boundarylist=[]):
# 每个变量的编码长度
lengths = []
for i in boundarylist:
lower = i[0]
upper = i[1]
# lamnda 代表匿名函数f(x)=0,50代表搜索的初始解
res = fsolve(lambda x: ((upper - lower) * 1 / delta) - 2 ** x - 1, 50)
length = int(np.floor(res[0]))
lengths.append(length)
return lengths
pass
# 随机生成初始编码种群
def getIntialPopulation(encodelength, populationSize):
# 随机化初始种群为0
chromosomes = np.zeros((populationSize, sum(encodelength)), dtype=np.uint8)
for i in range(populationSize):
chromosomes[i, :] = np.random.randint(0, 2, sum(encodelength))
# print('chromosomes shape:', chromosomes.shape)
return chromosomes
# 染色体解码得到表现型的解
def decodedChromosome(encodelength, chromosomes, boundarylist, delta=0.0001):
populations = chromosomes.shape[0]
variables = len(encodelength)
decodedvalues = np.zeros((populations, variables))
for k, chromosome in enumerate(chromosomes):
chromosome = chromosome.tolist()
start = 0
for index, length in enumerate(encodelength):
# 将一个染色体进行拆分,得到染色体片段
power = length - 1
# 解码得到的10进制数字
demical = 0
for i in range(start, length + start):
demical += chromosome[i] * (2 ** power)
power -= 1
lower = boundarylist[index][0]
upper = boundarylist[index][1]
decodedvalue = lower + demical * (upper - lower) / (2 ** length - 1)
decodedvalues[k, index] = decodedvalue
# 开始去下一段染色体的编码