import pandas as pd
import re
import jieba.posseg as psg
import numpy as np
reviews = pd.read_csv(r"G:\data\data\reviews.csv")
reviews = reviews[['content', 'content_type']].drop_duplicates()
content = reviews['content']
strinfo = re.compile('[0-9a-zA-Z]|京东|美的|电热水器|热水器|')
content = content.apply(lambda x: strinfo.sub('', x))
worker = lambda s: [(x.word, x.flag) for x in psg.cut(s)]
seg_word = content.apply(worker)
n_word = seg_word.apply(lambda x: len(x))
n_content = [[x+1]*y for x,y in zip(list(seg_word.index), list(n_word))]
index_content = sum(n_content, [])
seg_word = sum(seg_word, [])
word = [x[0] for x in seg_word]
nature = [x[1] for x in seg_word]
content_type = [[x]*y for x,y in zip(list(reviews['content_type']), list(n_word))]
content_type = sum(content_type, [])
result = pd.DataFrame({"index_content":index_content,
"word":word,
"nature":nature,
"content_type":content_type})
result = result[result['nature'] != 'x']
stop_path = open(r"G:\data\data\stoplist.txt", 'r',encoding='UTF-8')
stop = stop_path.readlines()
stop = [x.replace('\n', '') for x in stop]
word = list(set(word) - set(stop))
result = result[result['word'].isin(word)]
n_word = list(result.groupby(by = ['index_content'])['index_content'].count())
index_word = [list(np.arange(0, y)) for y in n_word]
index_word = sum(index_word, [])
result['index_word'] = index_word
ind = result[['n' in x for x in result['nature']]]['index_content'].unique()
result = result[[x in ind for x in result['index_content']]]
import matplotlib.pyplot as plt
from wordcloud import WordCloud
frequencies = result.groupby(by = ['word'])['word'].count()
frequencies = frequencies.sort_values(ascending = False)
backgroud_Image=plt.imread(r"G:\data\data\pl.jpg")
wordcloud = WordCloud(font_path="C:\Windows\Fonts\STZHONGS.ttf",
max_words=100,
background_color='white',
mask=backgroud_Image)
my_wordcloud = wordcloud.fit_words(frequencies)
plt.imshow(my_wordcloud)
plt.axis('off')
plt.show()
result.to_csv(r"G:\data\data\word.csv", index = False, encoding = 'utf-8')
import numpy as np
worker = lambda s: [(x.word, x.flag) for x in psg.cut(s)]
seg_word = content.apply(worker)
n_word = seg_word.apply(lambda x: len(x))
n_content = [[x+1]*y for x,y in zip(list(seg_word.index), list(n_word))]
index_content = sum(n_content, [])
seg_word = sum(seg_word, [])
word = [x[0] for x in seg_word]
nature = [x[1] for x in seg_word]
content_type = [[x]*y for x,y in zip(list(reviews['content_type']),
list(n_word))]
content_type = sum(content_type, [])
result = pd.DataFrame({"index_content":index_content,
"word":word,
"nature":nature,
"content_type":content_type})
result = result[result['nature'] != 'x']
stop_path = open(r"G:\data\data\stoplist.txt", 'r',encoding='UTF-8')
stop = stop_path.readlines()
stop = [x.replace('\n', '') for x in stop]
word = list(set(word) - set(stop))
result = result[result['word'].isin(word)]
n_word = list(result.groupby(by = ['index_content'])['index_content'].count())
index_word = [list(np.arange(0, y)) for y in n_word]
index_word = sum(index_word, [])
result['index_word'] = index_word
ind = result[['n' in x for x in result['nature']]]['index_content'].unique()
result = result[[x in ind for x in result['index_content']]]
import matplotlib.pyplot as plt
from wordcloud import WordCloud
frequencies = result.groupby(by = ['word'])['word'].count()
frequencies = frequencies.sort_values(ascending = False)
backgroud_Image=plt.imread(r"G:\data\data\pl.jpg")
wordcloud = WordCloud(font_path="C:\Windows\Fonts\STZHONGS.ttf",
max_words=100,
background_color='white',
mask=backgroud_Image)
my_wordcloud = wordcloud.fit_words(frequencies)
plt.imshow(my_wordcloud)
plt.axis('off')
plt.show()
result.to_csv(r"G:\data\data\word.csv", index = False, encoding = 'utf-8')
import pandas as pd
import numpy as np
word = pd.read_csv(r"G:\data\data\word.csv")
pos_comment = pd.read_csv(r"G:\data\data\正面评价词语(中文).txt", header=None, sep="\n",
encoding='utf-8', engine='python')
neg_comment = pd.read_csv(r"G:\data\data\负面评价词语(中文).txt", header=None, sep="\n",
encoding='utf-8', engine='python')
pos_emotion = pd.read_csv(r"G:\data\data\正面情感词语(中文).txt", header=None, sep="\n",
encoding='utf-8', engine='python')
neg_emotion = pd.read_csv(r"G:\data\data\负面情感词语(中文).txt", header=None, sep="\n",
encoding='utf-8', engine='python')
positive = set(pos_comment.iloc[:, 0]) | set(pos_emotion.iloc[:, 0])
negative = set(neg_comment.iloc[:, 0]) | set(neg_emotion.iloc[:, 0])
intersection = positive & negative
positive = list(positive - intersection)
negative = list(negative - intersection)
positive = pd.DataFrame({"word": positive,
"weight": [1] * len(positive)})
negative = pd.DataFrame({"word": negative,
"weight": [-1] * len(negative)})
posneg = positive.append(negative)
data_posneg = posneg.merge(word, left_on='word', right_on='word',
how='right')
data_posneg = data_posneg.sort_values(by=['index_content', 'index_word'])
notdict = pd.read_csv(r"G:\data\data\not.csv")
data_posneg['amend_weight'] = data_posneg['weight']
data_posneg['id'] = np.arange(0, len(data_posneg))
only_inclination = data_posneg.dropna()
only_inclination.index = np.arange(0, len(only_inclination))
index = only_inclination['id']
for i in np.arange(0, len(only_inclination)):
review = data_posneg[data_posneg['index_content'] ==
only_inclination['index_content'][i]]
review.index = np.arange(0, len(review))
affective = only_inclination['index_word'][i]
if affective == 1:
ne = sum([i in notdict['term'] for i in review['word'][affective - 1]])
if ne == 1:
data_posneg['amend_weight'][index[i]] = - \
data_posneg['weight'][index[i]]
elif affective > 1:
ne = sum([i in notdict['term'] for i in review['word'][[affective - 1,
affective - 2]]])
if ne == 1:
data_posneg['amend_weight'][index[i]] = - \
data_posneg['weight'][index[i]]
only_inclination = only_inclination.dropna()
emotional_value = only_inclination.groupby(['index_content'],
as_index=False)['amend_weight'].sum()
emotional_value = emotional_value[emotional_value['amend_weight'] != 0]
emotional_value['a_type'] = ''
emotional_value['a_type'][emotional_value['amend_weight'] > 0] = 'pos'
emotional_value['a_type'][emotional_value['amend_weight'] < 0] = 'neg'
result = emotional_value.merge(word,
left_on='index_content',
right_on='index_content',
how='left')
result = result[['index_content', 'content_type', 'a_type']].drop_duplicates()
confusion_matrix = pd.crosstab(result['content_type'], result['a_type'],
margins=True)
(confusion_matrix.iat[0, 0] + confusion_matrix.iat[1, 1]) / confusion_matrix.iat[2, 2]
ind_pos = list(emotional_value[emotional_value['a_type'] == 'pos']['index_content'])
ind_neg = list(emotional_value[emotional_value['a_type'] == 'neg']['index_content'])
posdata = word[[i in ind_pos for i in word['index_content']]]
negdata = word[[i in ind_neg for i in word['index_content']]]
import matplotlib.pyplot as plt
from wordcloud import WordCloud
freq_pos = posdata.groupby(by=['word'])['word'].count()
freq_pos = freq_pos.sort_values(ascending=False)
backgroud_Image = plt.imread(r"G:\data\data\pl.jpg")
wordcloud = WordCloud(font_path="C:\Windows\Fonts\STZHONGS.ttf",
max_words=100,
background_color='white',
mask=backgroud_Image)
pos_wordcloud = wordcloud.fit_words(freq_pos)
plt.imshow(pos_wordcloud)
plt.axis('off')
plt.show()<br><br>
freq_neg = negdata.groupby(by=['word'])['word'].count()
freq_neg = freq_neg.sort_values(ascending=False)
neg_wordcloud = wordcloud.fit_words(freq_neg)
plt.imshow(neg_wordcloud)
plt.axis('off')
plt.show()
posdata.to_csv(r"G:\data\data\posdata.csv", index=False, encoding='utf-8')
negdata.to_csv(r"G:\data\data\negdata.csv", index=False, encoding='utf-8')
import pandas as pd
import numpy as np
import re
import itertools
import matplotlib.pyplot as plt
posdata = pd.read_csv(r"G:\data\data\posdata.csv", encoding='utf-8')
negdata = pd.read_csv(r"G:\data\data\negdata.csv", encoding='utf-8')
from gensim import corpora, models
pos_dict = corpora.Dictionary([[i] for i in posdata['word']])
neg_dict = corpora.Dictionary([[i] for i in negdata['word']])
pos_corpus = [pos_dict.doc2bow(j) for j in [[i] for i in posdata['word']]]
neg_corpus = [neg_dict.doc2bow(j) for j in [[i] for i in negdata['word']]]
def cos(vector1, vector2):
dot_product = 0.0;
normA = 0.0;
normB = 0.0;
for a, b in zip(vector1, vector2):
dot_product += a * b
normA += a ** 2
normB += b ** 2
if normA == 0.0 or normB == 0.0:
return (None)
else:
return (dot_product / ((normA * normB) ** 0.5))
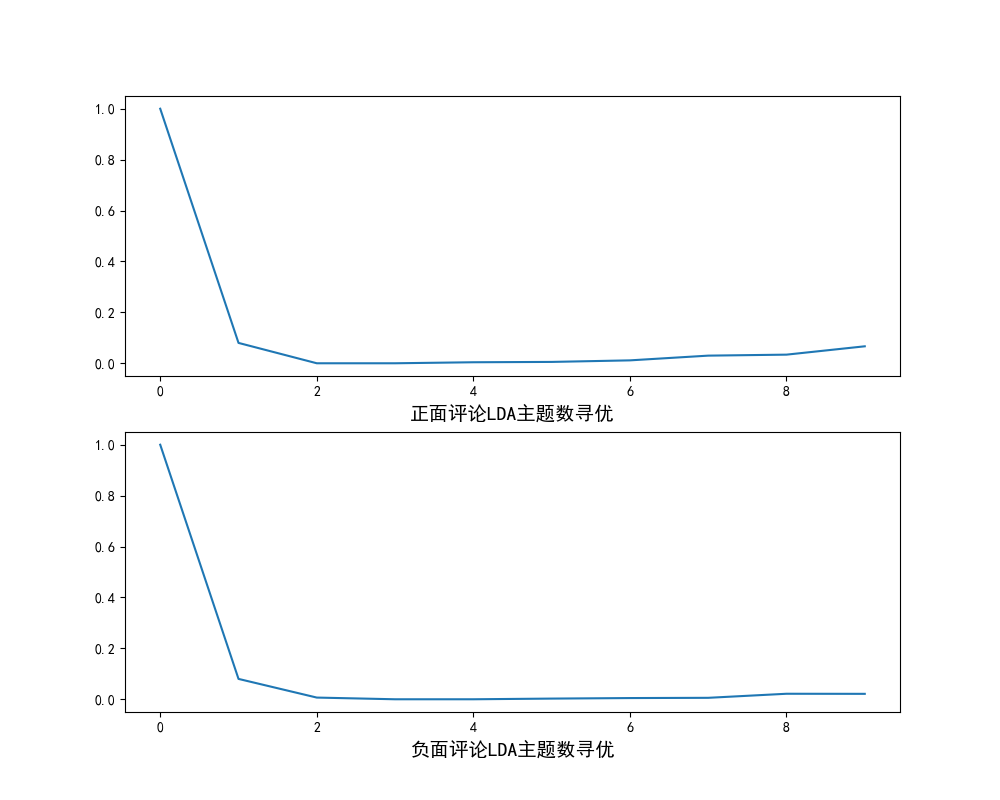
def lda_k(x_corpus, x_dict):
mean_similarity = []
mean_similarity.append(1)
for i in np.arange(2, 11):
lda = models.LdaModel(x_corpus, num_topics=i, id2word=x_dict)
for j in np.arange(i):
term = lda.show_topics(num_words=50)
top_word = []
for k in np.arange(i):
top_word.append([''.join(re.findall('"(.*)"', i)) \
for i in term[k][1].split('+')])
word = sum(top_word, [])
unique_word = set(word)
mat = []
for j in np.arange(i):
top_w = top_word[j]
mat.append(tuple([top_w.count(k) for k in unique_word]))
p = list(itertools.permutations(list(np.arange(i)), 2))
l = len(p)
top_similarity = [0]
for w in np.arange(l):
vector1 = mat[p[w][0]]
vector2 = mat[p[w][1]]
top_similarity.append(cos(vector1, vector2))
mean_similarity.append(sum(top_similarity) / l)
return (mean_similarity)
pos_k = lda_k(pos_corpus, pos_dict)
neg_k = lda_k(neg_corpus, neg_dict)
from matplotlib.font_manager import FontProperties
font = FontProperties(size=14)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
fig = plt.figure(figsize=(10, 8))
ax1 = fig.add_subplot(211)
ax1.plot(pos_k)
ax1.set_xlabel('正面评论LDA主题数寻优', fontproperties=font)
ax2 = fig.add_subplot(212)
ax2.plot(neg_k)
ax2.set_xlabel('负面评论LDA主题数寻优', fontproperties=font)
pos_lda = models.LdaModel(pos_corpus, num_topics=3, id2word=pos_dict)
neg_lda = models.LdaModel(neg_corpus, num_topics=3, id2word=neg_dict)
pos_lda.print_topics(num_words=10)
neg_lda.print_topics(num_words=10)
plt.show()