大数据测试技术——课堂测试
数据分析练习
以下源代码均以自己情况为主,如需参考,请谨慎再谨慎
1、原始表为access数据库,转为csv格式
直接另存为就可以了
2、将三省的科技成果数据汇总到同一个表中
由于表结构不一致,所以合并前要进行相似和表达意思相同的字段的合并(独有字段置为空)
整理一下
表1.1
|
名 |
类型 |
长度 |
小数点 |
不是null |
|
ID |
Varchar |
255 |
0 |
|
|
成果名称 |
Varchar |
255 |
0 |
|
|
项目年度编号 |
Varchar |
255 |
0 |
|
|
省市 |
Varchar |
255 |
0 |
|
|
中国分类号 |
Varchar |
255 |
0 |
|
|
成果类别 |
Varchar |
255 |
0 |
|
|
成果分布年份 |
Varchar |
255 |
0 |
|
|
关键词 |
Varchar |
255 |
0 |
|
|
成果简介 |
Text |
|
0 |
|
|
鉴定部门 |
Varchar |
255 |
0 |
|
|
登记号 |
Varchar |
255 |
0 |
|
|
完成单位 |
Varchar |
255 |
0 |
|
|
完成人 |
Varchar |
255 |
0 |
|
|
应用行业名称 |
Varchar |
255 |
0 |
|
|
应用行业代码 |
Varchar |
255 |
0 |
|
|
联系单位地址 |
Varchar |
255 |
0 |
|
|
传真 |
Varchar |
255 |
0 |
|
|
电子邮件 |
Varchar |
255 |
0 |
|
表1.2
|
名 |
类型 |
长度 |
小数点 |
不是null |
|
序号 |
Varchar |
255 |
0 |
|
|
成果名称 |
Varchar |
255 |
0 |
|
|
行业 |
Varchar |
255 |
0 |
|
|
年度 |
Varchar |
255 |
0 |
|
|
批准登记号 |
Varchar |
255 |
0 |
|
|
单位名称 |
Varchar |
255 |
0 |
|
|
课题来源 |
Varchar |
255 |
0 |
|
|
单位名称 |
Varchar |
255 |
0 |
|
|
主要人员 |
Varchar |
255 |
0 |
|
|
评价单位名称 |
Varchar |
255 |
0 |
|
|
成果简介 |
Text |
0 |
0 |
|
表1.3
|
名 |
类型 |
长度 |
小数点 |
不是null |
|
序号 |
Varchar |
255 |
0 |
|
|
单位 |
Varchar |
255 |
0 |
|
|
成果名称 |
Varchar |
255 |
0 |
|
|
技术水平 |
Varchar |
255 |
0 |
|
|
负责人 |
Varchar |
255 |
0 |
|
|
所属技术领域 |
Varchar |
255 |
0 |
|
|
合作单位 |
Varchar |
255 |
0 |
|
|
项目总规模或评估价值(万元) |
Varchar |
255 |
0 |
|
|
目前所处阶段 |
Varchar |
255 |
0 |
|
|
知识产权情况 |
Varchar |
255 |
0 |
|
|
项目简介 |
Varchar |
255 |
0 |
|
#基于成果名称合并 import pandas as pd # 读取三个CSV文件 df1 = pd.read_csv('cg_天津科技成果.csv') df2 = pd.read_csv('cg_2015年第1_2_3期.csv') df3 = pd.read_csv('科技成果.csv') # 合并三个表格 merged_df = pd.merge(df1, df2, on='成果名称', how='outer') merged_df = pd.merge(merged_df, df3, on='成果名称', how='outer') # 将缺失值填充为空值 merged_df = merged_df.fillna('') # 将合并后的数据保存为CSV文件 merged_df.to_csv('all.csv', index=False)
拟合并字段√
cg_天津科技成果.csv
cg_2015年第1_2_3期.csv
科技成果.csv
单位 成果名称 负责人 所属技术领域 年度 项目简介
| | | | | |
单位名称 成果名称 主要成员 行业 年度 成果简介
| | | | | |
完成单位 成果名称 完成人 应用行业名称 成果分布年份 成果简介
import pandas as pd # 读取合并后的CSV文件 df = pd.read_csv('all.csv') # 合并列组 df['单位'] = df['单位'].fillna(df['单位名称']).fillna(df['完成单位']).fillna('') df['负责人'] = df['负责人'].fillna(df['主要人员']).fillna(df['完成人']).fillna('') df['所属技术领域'] = df['所属技术领域'].fillna(df['行业']).fillna(df['应用行业名称']).fillna('') df['年度'] = df['年度'].fillna(df['成果分布年份']).fillna('') df['项目简介'] = df['项目简介'].fillna(df['成果简介_x']).fillna(df['成果简介_y']).fillna('') # 删除原有的列 df.drop(columns=['单位名称', '完成单位', '主要人员', '完成人', '行业', '应用行业名称', '年度', '成果分布年份', '成果简介_y', '成果简介_x'], inplace=True) # 将处理后的数据保存为CSV文件 df.to_csv('all.csv', index=False)
需添加字段√
1.3天津科技成果表中不存在年度字段,则直接添加年度维度字段确定为2015年
#1.3天津科技成果表添加年度字段全部置为2015 import pandas as pd # 读取CSV文件 df = pd.read_csv('cg_天津科技成果.csv') # 添加名为“年度”的列,并将所有值置为2015 df['年度'] = 2015 # 将处理后的数据保存为CSV文件 df.to_csv('2015_天津科技成果.csv', index=False)
添加地域
3、数据同步√
4、数据清洗
检查是否存在重复的数据√
5、利用高德接口添加省份和行政区划编码√
import pandas as pd import requests # 读取CSV文件 df = pd.read_csv('new_all.csv', encoding='utf-8') # 提取第六列的所有信息 sixth_column_data = df.iloc[:, 1] # 假设第六列的索引为5,如果不是,请替换为正确的索引值 # 打印提取的数据 print("提取的第二列数据:") print(sixth_column_data) amap_api_key = '' # Amap API请求函数 # Amap API请求函数 def get_amap_code(api_key, address): base_url = 'https://restapi.amap.com/v3/geocode/geo' params = { 'key': api_key, 'address': address, } try: response = requests.get(base_url, params=params) result = response.json() if result['status'] == '1' and int(result['count']) > 0: geocodes = result['geocodes'][0] adcode = geocodes.get('adcode', '') # 使用.get()方法获取adcode,如果不存在则返回空字符串 province = geocodes.get('province', '') # 使用.get()方法获取province,如果不存在则返回空字符串 city = geocodes.get('city', '') # 使用.get()方法获取city,如果不存在则返回空字符串 district = geocodes.get('district', '') # 使用.get()方法获取district,如果不存在则返回空字符串 formatted_address_parts = [part for part in [province, city, district] if part] # 过滤掉空字符串 formatted_address = ''.join(formatted_address_parts) # 拼接地址字符串 return adcode, formatted_address else: return None, None except requests.exceptions.RequestException as e: print(f"请求出错: {e}") return None, None adcodes = [] formatted_addresses = [] # 用于存储地址 total_queries = len(sixth_column_data) # 处理全部数据 for i, address in enumerate(sixth_column_data): print(f"正在查询第 {i+1}/{total_queries} 条数据...") adcode, formatted_address = get_amap_code(amap_api_key, address) adcodes.append(adcode) formatted_addresses.append(formatted_address) # 保存地址 print(f"查询结果: 行政编码 - {adcode}, 地址 - {formatted_address}") temp_df = pd.DataFrame({ 'Original Address': [address], 'Formatted Address': [formatted_address], 'Adcode': [adcode] }) temp_df.to_csv('new_results_file02.csv', mode='a', header=False, index=False)
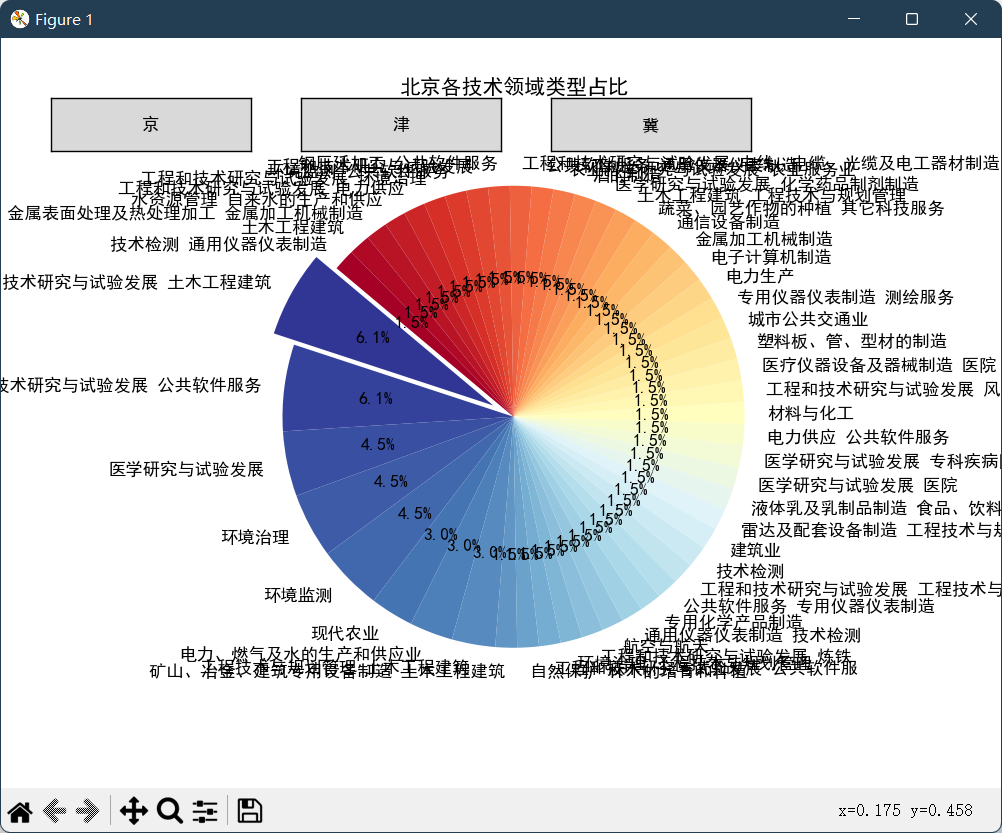
6、使用机器学习算法提取关键字
1.1表中有较为完整的关键字、应用行业字段、行业代码
1.2表中有行业字段,缺少关键字和行业代码
1.3表中所属技术领域与行业相似,但并不是国家规范标准
第一步从项目简介中提取关键字
import pandas as pd import jieba.analyse import csv try: # 尝试读取 CSV 文件 df = pd.read_csv('new_all_with_keywords.csv', quoting=csv.QUOTE_NONE) except Exception as e: print("Error:", e) print("Skipping error lines...") # 使用更通用的方式重新读取 CSV 文件,跳过错误行 lines = [] with open('new_all.csv', 'r', encoding='utf-8') as file: csv_reader = csv.reader(file) for line in csv_reader: if len(line) > 0: lines.append(line) # 通过读取的有效行创建 DataFrame df = pd.DataFrame(lines[1:], columns=lines[0]) # 对'项目简介'列应用关键词提取函数 def extract_keywords(text): # 使用 jieba 进行关键词提取,设置关键词数量最多为5个,允许多个字组成的关键字 keywords = jieba.analyse.textrank(text, topK=5, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v')) return " ".join(keywords) # 使用空格连接关键词 # 对'项目简介'列应用关键词提取函数 df['关键词'] = df['成果名称'].apply(extract_keywords) # 输出结果 print(df['关键词']) # 保存为新文件 df.to_csv('new_all_with_keywords.csv', index=False)
这里我使用百度api的关键字提取接口
然后以此类推就整理好了
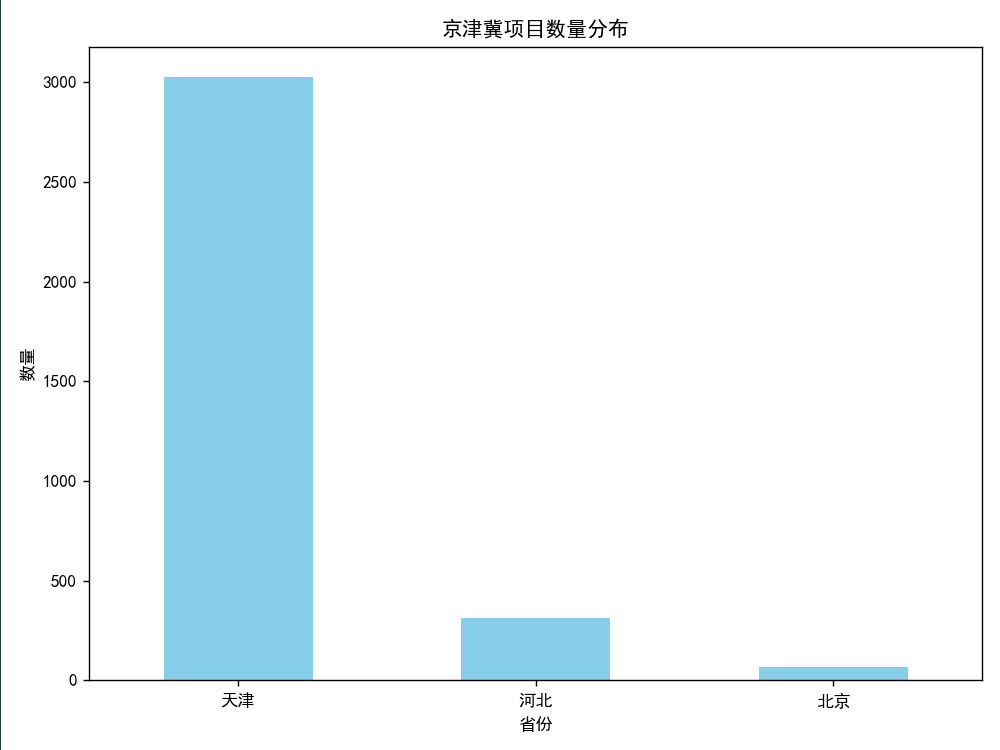
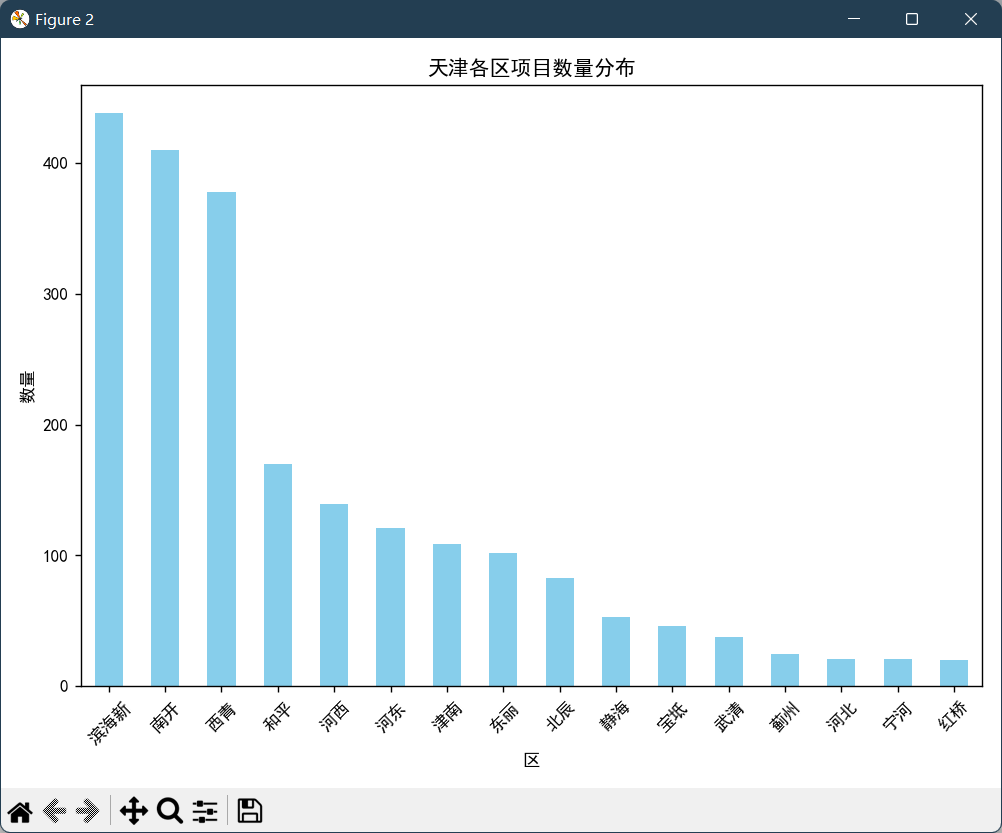
第二步对省市县进行分割然后数据下卷展示
如图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号