
UNIX环境高级编程 学习笔记 第二十章 数据库函数库
20世纪80年代早期,UNIX系统被认为不适合运行多用户数据库系统,因为早期的系统(如V7)没有提供任何形式的IPC机制(除了半双工管道),也没有提供任何形式的字节范围锁机制。但现在这些缺陷大多已得到纠正,到20世纪80年代后期,UNIX系统已为运行可靠的、多用户的数据库系统提供了一个适合的环境,从那时以来,很多商业公司都已提供这种数据库系统。
dbm是一个在UNIX系统中很流行的数据库函数库,它由Ken Thompson开发,使用了动态散列结构,最初,它是V7提供的,并出现在所有BSD版本中(BSD系统是基于V7系统的一个分支和演化),也包含在SVR4的BSD兼容函数库中。BSD的开发者扩充了dbm函数库,并将它称为ndbm。ndbm函数库包含在BSD和SVR4中。ndbm中的函数是SUS的XSI扩展的一部分。
dbm的所有实现的限制是不支持多个进程对数据库的并发更新(包括dbm函数库和GNU版本的gdbm),它们都没有提供并发控制(如记录锁机制)。
4.4 BSD提供了一个新的库db,它支持3种不同访问模式:面向记录、散列、B树。但db也没有提供并发控制。
Oracle提供了几个版本的db函数库,它们支持并发访问、锁机制和事务。
大部分商用的数据库函数库提供并发控制以使多进程同时更新数据库,这些系统一般都使用建议记录锁机制,但它们也常常实现自己的锁原语,以避免为获得一把无竞争锁而需的系统调用开销。这些商用系统通常用B+树或某种动态散列技术,如线性散列或可扩展的散列来实现数据库。
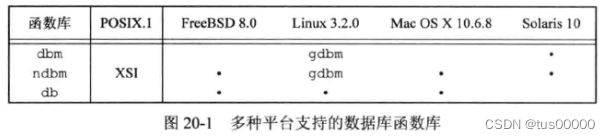
上图中,Linux上的gdbm库既支持dbm库,也支持ndbm库。
本章开发的函数库类似ndbm函数库,但增加了并发控制机制,从而允许多进程同时更新同一数据库,以下介绍本章要开发的数据库的C语言接口。
当打开一个数据库时,通过返回值得到一个代表数据库的句柄,将用此句柄作为参数来调用其他数据库函数:

如果db_open函数成功返回,表示两个文件已创建:pathname.idx和pathname.dat,pathname.idx是索引文件,pathname.dat是数据文件。参数oflag作为传递给open函数的第二个参数,来指定这些文件的打开模式(只读、读写、如果文件不存在则创建等)。如果需要建立新的数据库,mode参数作为第三个参数传递给open函数(作为文件访问权限)。
不再使用数据库时,调用db_close来关闭数据库,db_close函数将关闭索引文件和数据文件,并释放数据库使用过程中分配到的用于内部缓冲区的存储空间。
当向数据库中存入一条新记录时,必须提供一个此记录的键,以及与此键相关联的数据。实现要求每条记录的键必须是唯一的:

key和data参数是由null字符终止的字符串,它们可以包含除null字符外的任何字符,如换行符。flag参数只能是DB_INSERT(插入一条新记录)、DB_REPLACE(替换一条已有记录)、DB_STORE(插入一条新记录或替换一条已有记录)。如果使用DB_REPLACE,而记录不存在,则将errno设为ENOENT,并返回-1,且不加入新记录。如果使用DB_INSERT而记录已存在,则不插入新记录,并返回1。
通过指定键参数key可从数据库中获取一条记录:

如果找到了记录,返回指向参数key关联的数据的指针。
通过参数key也可在数据库中删除一条记录:

为逐条记录地访问数据库,首先调用db_rewind回滚到数据库的第一条记录,然后在每一次循环中调用db_nextrec,顺序地读每条记录:

如果db_nextrec函数的key参数是非空指针,db_nextrec会将数据存放在key参数表示的指针指向的内存,并返回参数key。
db_nextrec函数不保证其返回记录的顺序,只保证对数据库中的每条记录只读取一次,返回顺序由数据库的实现决定。
访问数据库的函数库通常使用两个文件来存储信息,一个索引文件和一个数据文件。索引文件包括实际的索引值(即键)和一个指向数据文件中对应数据记录的指针,有多种方式组织索引文件以提高按键查询的速度和效率,散列表和B+树是两种常用技术,我们采用固定大小的散列表来组织索引文件结构,并采用链表法解决散列冲突。
我们将键和索引以null结尾的字符串形式存储,它们不能包含任意的二进制数据。有些数据库系统用二进制形式存储数值数据(如用1个、2个或4个字节存储一个整数)以节省存储空间,这样会使函数复杂化,也使数据库文件在不同平台间移植比较困难,如网络上有两个系统使用不同的二进制格式存储整数,如果想要这两个系统都能访问数据库,必须解决不同存储格式的问题。按字符串存储所有记录,包括键和数据,能简化它,但需要更多磁盘空间,但降低了获得可移植性需要付出的代价。
db_store函数要求对每个键只有一条对应记录,而有些数据库系统允许多条记录使用同样的键,并提供方法访问与一个键相关的所有记录。由于我们只有一个索引文件,因此每个数据记录只能有一个键(不支持辅助索引)。有些数据库允许一条记录拥有多个键,且对每一个键使用一个索引文件,当插入或删除一条记录时,要对所有索引文件进行修改。
数据库实现的基本结构:
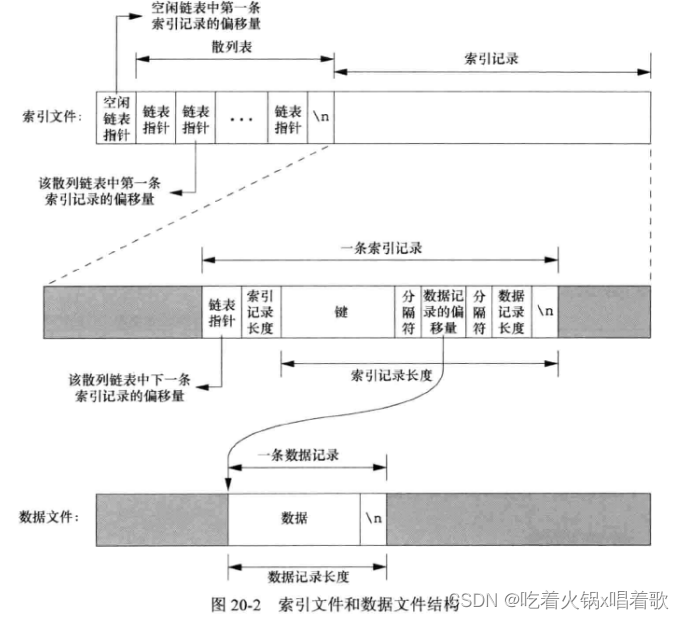
索引文件由3部分组成:空闲链表指针、散列表、索引记录。上图中所有指针字段实际存储的是ASCII码数字形式的文件偏移量。
给定一个键在数据库中寻找一条记录时,db_fetch函数根据该键计算散列值,由此散列值可确定一条散列链(链表指针字段可以为0,表示一条空的散列链),沿着这条散列链,可以找到所有具有这一散列值的索引记录,当遇到一个索引记录的链表指针字段为0时,表示到达了此散列链的末尾。
用以下程序向数据库中写入3条记录:
#include "apue.h"
#include "apue_db.h"
#include <fcntl.h>
int main(void) {
DBHANDLE db;
if ((db = db_open("db4", O_RDWR | O_CREAT | O_TRUNC, FILE_MODE)) == NULL) {
err_sys("db_open error");
exit(1);
}
if (db_store(db, "Alpha", "data1", DB_INSERT) != 0) {
err_quit("db_store error for alpha");
}
if (db_store(db, "beta", "Data for beta", DB_INSERT) != 0) {
err_quit("db_store error for beta");
}
if (db_store(db, "gamma", "record3", DB_INSERT) != 0) {
err_quit("db_store error for gamma");
}
db_close(db);
exit(0);
}
由于所有的字段都以ASCII字符形式存储在数据库中,所以可以直接查看索引文件和数据文件,在插入以上三条数据后:


为了使上例紧凑,每个指针字段的大小设为4个ASCII字符,散列链的数量设为3条。由于每一个指针中记录的是一个文件偏移量,所以4个ASCII字符限制了一个索引文件或数据文件的大小最多只能为10000字节。
索引文件的第一行分别表示空闲链表指针(0表示空闲链表为空)和3个散列链的指针。
索引文件第二行显示了一条索引记录的结构,第一个4字符字段(0+3个空字符)为链表指针,表示这一条记录是此散列链的最后一条。第二个4字符字段(10+2个空字符)为索引记录长度,表示此索引记录剩余部分的长度。可用两个read函数来读取一条索引记录:第一个read函数读取前两条固定长度的字段(链表指针和索引记录长度),然后再根据索引记录长度来读取后面的不定长部分。剩下3个字段为键、数据记录的偏移量、数据记录的长度,这3个字段用分隔符隔开,此处使用的分隔符是冒号,由于这3个字段都是不定长的,所以需要一个分隔符,且这个分隔符不能出现在键中。最后用换行符\n结束这一条索引记录,因为在索引记录长度字段中已经有了记录的长度,所以这个换行符不是必需的,加上换行符的目的是用cat查看索引文件时把各条索引记录分开,看起来更清晰。键字段是将记录写入数据库时指定的值。该索引记录对应的数据记录在数据文件中的偏移量为0,长度为6,从数据文件中确实看到数据记录从0开始,长度为6字节(6字节中包含一个换行符以更清晰地使用cat查看,db_fetch函数返回此条数据记录时,不将换行符作为数据返回)。
上例中,第一条散列链上第一条记录的偏移量是53,这条链上下一条记录的偏移量是17且是这条链上最后一条记录。第二条散列链上的第一条记录的偏移量是35且此链上只有一条记录。第三条散列链为空。
上例中,索引文件中键的顺序与调用db_store将它们插入数据库的顺序相同。由于调用db_open时使用了O_TRUNC标志,因此索引文件和数据文件都被截断了,相当于初始化了整个数据库,之后db_store函数将新的索引记录和数据记录追加到对应的文件末尾。db_store函数还可以重复使用这两个文件中已删除记录使用过的空间。
使用固定大小的散列表作为索引是一个妥协,当每个散列链都不太长时,能保证快速访问,我们的目的是能快速查找任一键,同时又不使用太复杂的数据结构,如B树和动态散列表。动态散列表的优点是保证仅用两次磁盘存取就能找到数据记录。B树能用键的顺序遍历数据库(采用散列表的db_nextrec函数做不到这一点)。
有多个进程访问同一数据库时,有两种方法实现库函数:
1.集中式:由一个进程作为数据库管理者,所有数据库访问工作由此进程完成,其他进程通过IPC机制与此进程联系。
2.非集中式:每个库函数使用要求的并发控制(加锁),然后发起自己的IO函数调用。
使用这两种技术的数据库系统都有,如果有适当的加锁例程,因为避免了使用IPC,非集中式方法一般要更快。本章采用非集中式方法。
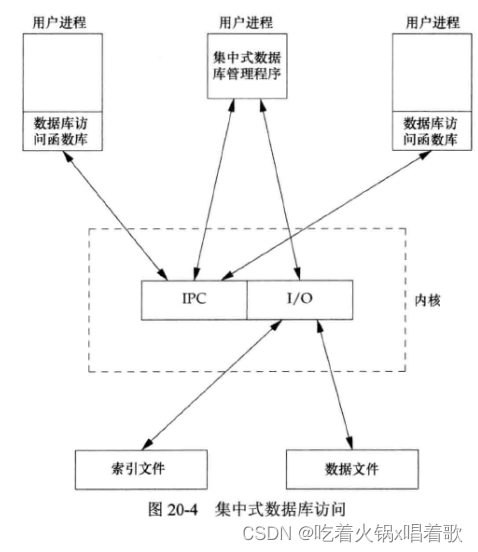
上图表示出IPC像绝大多数UNIX系统的消息传递一样需要经过操作系统内核(共享存储不需要经过这种内核的复制)。集中方式下,中心控制进程将记录读出,然后通过IPC机制将数据传递给请求进程,这是这种设计的不足之处。集中式数据库管理进程是唯一对数据库文件进行IO操作的进程。
集中式的优点是能根据需要对操作模式进行调整,如可通过中心进程给不同进程赋予不同优先级,从而影响中心进程对IO操作的调度,非集中式方法则很难做到这一点。非集中方法对IO的调度只能依赖于操作系统内核的磁盘IO调度策略和加锁策略(如3个进程同时等待一个即将可用的锁时,我们无法确定哪个进程将得到这个锁)。
集中式方法另一个优点是恢复比非集中式方法容易,在集中式方法中,所有状态信息都集中存放在一处,所以如果杀死了数据库进程,只需在该处查看以识别出需要解决的未完成事务,然后将数据库恢复到一致状态。
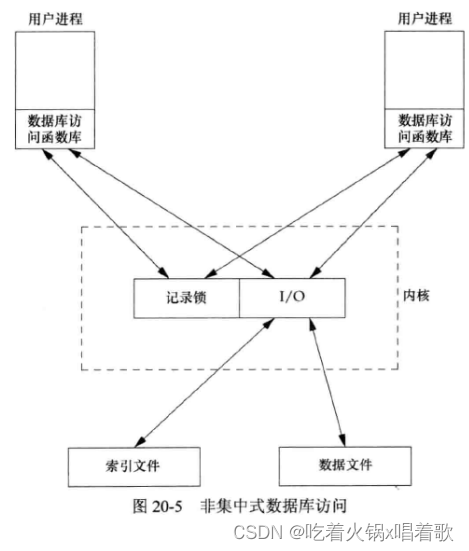
非集中式方法中,调用数据库库函数执行IO的用户进程是合作进程,它们使用字节范围记录锁机制来实现并发控制。
由于很多数据库系统的实现都采用两个文件(本章要实现的也是),这就要求能控制对两个文件的加锁,有以下方法可以用来对两个文件进行加锁:
1.粗粒度锁:最简单的加锁方法是将这两个文件中的一个作为整个数据库的锁,并要求调用者在对数据库进行操作前必须获得这个锁。如可以认为一个进程对索引文件的0字节加了读(写)锁后,才能读(写)整个数据库,锁可使用UNIX系统的字节范围锁机制,这样可以有多个读进程,只能有一个写进程。db_fetch和db_nextrec函数加读锁,db_delete、db_store、db_open加写锁(db_open函数加写锁的原因是如果要创建新文件,要在索引文件中建立空闲区链表和散列链表)。粗粒度锁限制了并发,当一个进程向一条散列链中添加一条记录时,其他进程无法访问另一条散列链上的记录。
2.细粒度锁:它改进了粗粒度锁,提供了更高的并发性。一个进程在读(写)一条记录前必须先获得此记录所在散列链的读(写)锁。一个写进程在访问空闲区链表(如db_delete、db_store)前,必须获得空闲区链表的写锁。当db_store函数向索引文件或数据文件末尾追加一条新记录时,必须获得对应文件相应区域的写锁。期望细粒度锁提供比粗粒度锁更高的并发性。在本章实现中,没有使用标准IO函数库,而是直接调用read、readv、write、writev,虽然标准IO库也可以使用字节范围锁,但需要非常复杂的缓冲管理,如标准IO缓冲区的数据5分钟前被另一个进程修改了,我们就不希望fgets函数返回的数据是十分钟前读入标准IO缓冲区中的数据。
我们的数据库函数库由两个文件构成,一个公用的C头文件和一个C源文件,可以用下列命令构造一个静态函数库:
gcc -I../include -Wall -c db.c
ar rsv libapue_db.a db.o
ar(Archive)命令是一个用于创建、修改和提取静态库(Archive)的命令行工具。静态库是一组预编译的目标文件的集合,可以供其他程序链接使用。
以上ar命令的各个选项含义:
1.r:表示替换或添加文件到静态库中。在这个命令中,它指示将 “db.o” 替换或添加到静态库libapue_db.a中。
2.s:表示创建索引表。索引表可以加速库的访问。
3.v:表示详细显示命令执行的过程。它会在控制台上显示添加的文件的信息。
我们希望与libapue_db.a相链接的应用程序也与libapue.a相链接,因为在数据库函数库中使用了一些我们自己的libapue.a库中的公共函数。
如果想构建数据库函数库的动态共享库版本,在带有GNU C编译器的Linux系统中可用下列命令:
gcc -I../include -Wall -fPIC -c db.c
gcc -shared -Wl,-soname,libapue_db.so.1 -o libapue_db.so.1 -L../lib -lapue -lc db.o
当使用gcc的-fPIC选项时,gcc编译器会生成位置独立的代码(Position Independent Code,PIC)。位置独立的代码是一种可在内存中的任何位置加载和执行的代码,而不受代码实际加载位置的影响。使用-fPIC选项的主要用途是创建共享库(Shared Library)。共享库是一种可被多个程序共享和重用的代码库,可以在运行时动态加载到内存中。使用-fPIC选项生成的代码,可以在内存中的任何位置加载,而不会发生地址冲突或位置相关的问题。这使得共享库在不同的进程空间和地址空间中可以安全地加载和执行。总结而言,-fPIC选项允许生成位置独立的代码,使得目标文件可以用于创建共享库,并能够在不同的内存位置加载和执行,提供了更好的移植性和灵活性。
gcc编译器的-shared选项表示生成一个共享库文件。
以上gcc命令中,-Wl,-soname,libapue_db.so.1部分的含义是,-Wl选项指示将后面的参数传递给链接器,传给链接器的-soname选项用于设置共享库的soname(Shared Object Name),它指定要生成的共享库的名称为 libapue_db.so.1。
以上gcc命令中,-o选项指定生成的共享库文件名为libapue_db.so.1。
以上gcc命令中,-L选项指定库文件的搜索路径。
以上gcc命令中,-l选项指定需要链接的库文件,上例中第一个-l选项的值为apue,因此会找名为libapue.so或libapue.a的库文件,其中lib是库的命名约定前缀,apue是指定的库名称,.so表示共享库(Shared Object),.a表示静态库(Static Library)。第二个-l选项的值要找的库文件为libc.so或libc.a,它是标准C库文件。
以上gcc命令中,db.o是一个需要被链接到最终共享库中的目标文件。
构建好的共享库libapue_db.so.1需放置在动态链接程序/载入程序(dynamic linker/loader)能找到的一个公用目录中。也可将共享库放置在一个私有目录中,然后修改LD_LIBRARY_PATH环境变量,使动态链接程序/载入程序的搜索路径包含该私有目录。
Dynamic linker/loader(动态链接器/装载器)是操作系统中的一个组件,用于在程序运行时加载和链接共享库(Shared Library)以及解析程序的符号引用。在编译时,程序通常会引用其他库中的函数和符号。这些库可以是静态库(Static Library)或共享库。对于静态库,这些函数和符号会被直接嵌入到可执行文件中,而对于共享库,只会在程序运行时进行链接和加载。动态链接器的主要任务是在程序启动时,将共享库加载到进程的内存空间,并解析程序中对这些库的符号引用。它负责将符号引用与相应的共享库中的实际符号地址进行关联,从而使程序能够调用这些函数和使用这些符号。通过动态链接器,多个程序可以共享同一个共享库,从而节省内存空间,并方便库的维护和更新。Dynamic linker和Dynamic loader是一个东西的两个名字。
对于用-Wl参数传递给链接器的-soname选项,它的作用是提供兼容性说明,当升级系统中的一个库时,如果新库和旧库的soname相同,那么使用新库也可以运行,它使得Linux中升级使用共享库的程序变得容易。另一方面,应用可以指定soname来获取相应的库版本,soname由库作者指定。
我们编写的数据库函数库的源代码和调用此函数库的所有应用都包含apue_db.h头文件。以下是apue_db.h头文件:
#ifndef _APUE_DB_H
#define _APUE_DB_H
typedef void * DBHANDLE;
// 以下是数据库公有函数的原型
// 由于使用数据库的应用会包括此头文件
// 因此数据库的私有函数原型不在此处声明
// 库的用户也就看不到私有函数了
DBHANDLE db_open(const char *, int, ...);
void db_close(DBHANDLE);
char *db_fetch(DBHANDLE, const char *);
int db_store(DBHANDLE, const char *, const char *, int);
int db_delete(DBHANDLE, const char *);
void db_rewind(DBHANDLE);
char *db_nextrec(DBHANDLE, char *);
/*
* Flags for db_store().
*/
#define DB_INSERT 1 /* insert new record only */
#define DB_REPLACE 2 /* replace existing record */
#define DB_STORE 3 /* replace or insert */
/*
* Implementation limits.
*/
#define IDXLEN_MIN 6 /* key, sep, start, sep, length, \n */
#define IDXLEN_MAX 1024 /* arbitrary(随意地选择了一个值作为上限) */
#define DATLEN_MIN 2 /* data byte, newline */
#define DATLEN_MAX 1024 /* arbitrary */
#endif /* _APUE_DB_H */
以上代码中,使用符号_APUE_DB_H以保证只包括该头文件一次。DBHANDLE类型表示对数据库的一个有效引用,用于隔离应用程序和数据库的实现细节,与标准IO库向应用提供的FILE结构作用类似。
最小索引记录长度是IDXLEN_MIN,结构为1字节键、1字节分隔符、1字节起始偏移量、1字节分隔符、1字节数据记录长度、1字节换行符。
db.c是库函数的C源文件,为简化起见,将所有函数都放在一个文件中,这样处理的优点是只要将私有函数声明为static的,就可以对外将它隐藏起来:
#include "apue_db.h"
#include <fcntl.h> /* open & db_open flags */
#include <stdarg.h>
#include <errno.h>
#include <sys/uio.h> /* struct iovec */
#include <unistd.h>
#include <stdio.h>
#include <stdarg.h> /* 由于要使用可变参数函数 */
/*
* Internal index file constants.
* These are used to construct records in the
* index file and data file.
*/
#define IDXLEN_SZ 4 /* index record lenth (ASCII chars),索引记录中索引记录长度字段的字节数 */
#define SEP ':' /* separator char in index record */
#define SPACE ' ' /* space character,删除一条记录时,会用空格符填充它 */
#define NEWLINE '\n' /* new line character */
/*
* The following definitions are for hash chains and free
* list chain in the index file.
*/
#define PTR_SZ 7 /* size of ptr field in hash chain(指针字段的字节数) */
#define PTR_MAX 999999 /* max file offset = 10**PTR_SZ - 1 */
#define NHASH_DEF 137 /* default hash table size */
// 更好的方法是让db_open函数的调用者根据预期的数据库大小通过参数来设置这个值
// 然后将该值存在索引文件最前面,但会使实现复杂一些
// 此处该值取137,是一个素数,素数散列通常能提供良好的分布特性
#define FREE_OFF 0 /* free list offset in index file */
#define HASH_OFF PTR_SZ /* hash table offset in index file */
typedef unsigned long DBHASH; /* hash values */
typedef unsigned long COUNT; /* unsigned counter */
/*
* Library's private representation of the database.
*/
typedef struct {
int idxfd; /* fd for index file */
int datfd; /* fd for data file */
char *idxbuf; /* malloc'ed buffer for index record */
char *datbuf; /* malloc'ed buffer for data record */
char *name; /* name db was opened under */
off_t idxoff; /* offset in index file of index record */
/* key is at (idxoff + PTR_SZ + IDXLEN_SZ) */
size_t idxlen; /* length of index record */
/* excludes IDXLEN_SZ bytes at front of record */
/* includes newline at end of index record */
off_t datoff; /* offset in data file of data record */
size_t datlen; /* length of data record */
/* includes new line at end */
off_t ptrval; /* contents of chain ptr in index record */
off_t ptroff; /* chain ptr offset pointing to this idx record */
off_t chainoff; /* offset of hash chain for this index record */
off_t hashoff; /* offset in index file of hash table */
DBHASH nhash; /* current hash table size */
COUNT cnt_delok; /* delete OK */
COUNT cnt_delerr; /* delete error */
COUNT cnt_fetchok; /* fetch OK */
COUNT cnt_fetcherr; /* fetch error */
COUNT cnt_nextrec; /* nextrec */
COUNT cnt_stor1; /* store:DB_INSERT, no empty, appended */
COUNT cnt_stor2; /* store:DB_INSERT, found empty, reused */
COUNT cnt_stor3; /* store:DB_REPLACE, diff len, appended */
COUNT cnt_stor4; /* store:DB_REPLACE, same len, overwrote */
COUNT cnt_storerr; /* store error */
} DB;
// DB结构中记录一个打开数据库的所有信息
// db_open函数返回的DBHANDLE指针指向DB结构,此结构用于其他数据库库函数,不面向调用者
// 在数据库里使用ASCII形式存放指针和长度,但这些值将转换为数字值存放在DB结构中
// DB结构中也存放散列表长度,一般这是定长的,但有可能为改进数据库,允许调用者在创建数据库时指定该长度
// DB结构最后10个字段对成功和不成功的操作进行计数,可用于分析数据库性能。
/*
* Internal functions.
*/
static DB *_db_alloc(int);
static void _db_dodelete(DB *);
static int _db_find_and_lock(DB *, const char *, int);
static int _db_findfree(DB *, int, int);
static void _db_free(DB *);
static DBHASH _db_hash(DB *, const char *);
static char *_db_readdat(DB *);
static off_t _db_readidx(DB *, off_t);
static off_t _db_readptr(DB *, off_t);
static void _db_writedat(DB *, const char *, off_t, int);
static void _db_writeidx(DB *, const char *, off_t, int, off_t);
static void _db_writeptr(DB *, off_t, off_t);
// 使用db_开头来命名用户可调用的函数,_db_开头来命名内部函数
// 公有函数在函数库头文件apue_db.h中声明
// 内部函数声明为static,只有同一文件中的其他函数才能调用它们
/*
* Open or create a database. Same arguments as open.
*/
// 如果调用者想要创建数据库,使用可选的第三个参数指定文件权限
// 该函数可用来打开索引文件和数据文件,在必要时初始化索引文件
// 该函数调用_db_alloc来为DB结构分配空间,并初始化此结构
DBHANDLE db_open(const char *pathname, int oflag, ...) {
DB *db;
int len, mode;
size_t i;
char asciiptr[PTR_SZ + 1],
hash[(NHASH_DEF + 1) * PTR_SZ + 2];
/* +2 for newline and null */
/* +1 for free list ptr */
struct stat statbuff;
/*
* Allocate a DB structure, and the buffers it needs.
*/
len = strlen(pathname);
if ((db = _db_alloc(len)) == NULL) {
err_dump("db_open:_db_alloc error for DB\n");
exit(1);
}
db->nhash = NHASH_DEF; /* hash table size */
db->hashoff = HASH_OFF; /* offset in index file of hash table */
strcpy(db->name, pathname); // 把调用者传入的路径名作为数据库文件名的前缀
strcat(db->name, ".idx"); // 追加后缀.idx构成数据库索引文件的名字
if (oflag & O_CREAT) {
va_list ap;
// va_start函数必须用在va_arg和va_end函数前
// va_start函数的第二个参数是省略号之前的参数
// va_start函数的第一个参数是一个va_list类型的未初始化对象,其中包
// 含va_arg函数获取可变参数时所需要的信息
// 如果ap参数之前已经被传递给过va_start或va_copy函数
// 再将其传递给va_start函数前,应先对其调用va_end
va_start(ap, oflag);
// 如果函数A在某作用域调用了va_start,函数A在退出该作用域前应调用一次va_end
// va_arg宏会展开为类型为第二个参数(此例为int)的表达式
// 每次调用va_arg都会改变ap参数的状态,从而使下次调用va_arg时返回下一个参数
// va_arg函数本身不清楚它要返回的可变参数的类型,它仅仅将第二个参数当作返回值的类型
// va_arg不会判断当前是否取到最后一个参数或尾后参数
// 参数数量需要我们用已经读到的可变参数或固定参数来确定
mode = va_arg(ap, int);
// 必须在调用了va_start或va_copy的作用域退出前调用va_end
// va_end函数执行一些清理工作,以确保资源的正确释放
// 如果你没有调用va_end,是未定义行为,可能会导致资源泄漏或内存错误
va_end(ap);
/*
* Open index file and data file.由于有O_CREAT标志,因此调用open时需要3个参数
*/
db->idxfd = open(db->name, oflag, mode);
strcpy(db->name + len, ".dat");
db->datfd = open(db->name, oflag, mode);
} else {
/*
* Open index file and data file.
*/
db->idxfd = open(db->name, oflag);
strcpy(db->name + len, ".dat");
db->datfd = open(db->name, oflag);
}
if (db->idxfd < 0 || db->datfd < 0) {
_db_free(db);
return NULL;
}
if ((oflag & (O_CREAT | O_TRUNC)) == (O_CREAT | O_TRUNC)) {
/*
* If the database was created, we have to initialize
* it. Write lock the entire file so that we can stat
* it, check its size, and initialize it, atomically.
*/
// writew_lock函数获取写文件锁,如果不能获取锁,则会休眠等待到能获取锁
// 锁的起始偏移为0,范围也为0(此时会从起始偏移加锁直到文件结束)
// 此处加锁可以避免以下情况:进程1从fstat函数返回后被内核阻塞,之后进程2也从fstat函数返回
// 然后进程2发现文件长度为0,并初始化散列链表和空闲链表,然后向数据库插入一条数据,之后进程2被内核阻塞
// 然后进程1开始运行,发现文件长度为0,又初始化一次散列链表和空闲链表,从而覆盖了进程2写入的数据
if (writew_lock(db->idxfd, 0, SEEK_SET, 0) < 0) {
printf("db_open: writew_lock error\n");
exit(1);
}
if (fstat(db->idxfd, &statbuff) < 0) {
printf("db_open: fstat error\n");
exit(1);
}
if (statbuff.st_size == 0) {
/*
* We have to build a list of (NHASH_DEF + 1) chain
* ptrs with a value of 0. The +1 is for the free
* list pointer that precedes the hash table.
*/
// %*d会读取一个整数(PTR_SZ)作为字符串的宽度,结果存放在asciiptr处
// 转换后有PTR_SZ位字符,左边用空格填充,转换后为" 0"
sprintf(asciiptr, "%*d", PTR_SZ, 0);
hash[0] = 0;
for (i = 0; i < NHASH_DEF + 1; ++i) {
strcat(hash, asciiptr);
}
strcat(hash, "\n");
i = strlen(hash);
if (write(db->idxfd, hash, i) != i) {
printf("db_open: index file init write error\n");
exit(1);
}
}
if (un_lock(db->idxfd, 0, SEEK_SET, 0) < 0) {
printf("db_open: un_lock error\n");
exit(1);
}
}
db_rewind(db);
return db;
}
/*
* Allocate & initialize a DB structure and its buffers.
*/
static DB *_db_alloc(int namelen) {
DB *db;
/*
* Use calloc, to initialize the structure to zero.
*/
if ((db = calloc(1, sizeof(DB))) == NULL) {
printf("_db_alloc: calloc error for DB\n");
exit(1);
}
/* descriptors,有效文件描述符的下限为0,因此设为-1表示无效文件描述符 */
db->idxfd = db->datfd = -1;
/*
* Allocate room for the name.
* +5 for .idx or .dat plus null at end.
*/
if ((db->name = malloc(namelen + 5)) == NULL) {
printf("_db_alloc: malloc error for name\n");
exit(1);
}
/*
* Allocate an index buffer and a data buffer.
* +2 for newline and null at end.
* IDX_MAX和DATLEN_MAX在apue_db.h中定义
* 这里可改为让这些缓冲区按需动态扩张以增强数据库函数库
* 方法可以是记录这两个缓冲区大小,然后在需要更大缓冲区时调用realloc
*/
if ((db->idxbuf = malloc(IDXLEN_MAX + 2)) == NULL) {
printf("_db_alloc: malloc error for index buffer\n");
exit(1);
}
if ((db->datbuf = malloc(DATLEN_MAX + 2)) == NULL) {
printf("_db_alloc: malloc error for data buffer\n");
exit(1);
}
return db;
}
/*
* Relinquish access to the database.
*/
void db_close(DBHANDLE h) {
_db_free((DB *)h); /* closes fds, free buffers & struct */
}
/*
* Free up a DB structure, and all the malloc'ed buffers it
* may point to. Alse close the file descriptors if still open.
* 调用db_open时,如果打开索引文件或数据文件时发生错误,则会调用_db_free
* 应用程序结束对数据库的使用后,会调用db_close,其中也会调用_db_free
*/
static void _db_free(DB *db) {
if (db->idxfd >= 0) {
close(db->idxfd);
}
if (db->datfd >= 0) {
close(db->datfd);
}
// 虽然可以安全地将空指针传给free函数,但只释放已分配的对象是一种较好的编程风格
// 并且并非所有释放程序都像free函数那样容忍差错
if (db->idxbuf != NULL) {
free(db->idxbuf);
}
if (db->datbuf != NULL) {
free(db->datbuf);
}
if (db->name != NULL) {
free(db->name);
}
free(db);
}
/*
* Fetch a record. Return a pointer to the null-terminated data.
*/
char *db_fetch(DBHANDLE h, const char *key) {
DB *db = h;
char *ptr;
if (_db_find_and_lock(db, key, 0) < 0) {
ptr = NULL; /* error, record not found, return NULL */
db->cnt_fetcherr++;
} else {
ptr = _db_readdat(db); /* return pointer to data */
db->cnt_fetchok++;
}
/*
* Unlock the hash chain that _db_find_and_lock lokced.
*/
if (un_lock(db->idxfd, db->chainoff, SEEK_SET, 1) < 0) {
printf("db_fetch: un_lock error\n");
exit(1);
}
return ptr;
}
/*
* Find the specified record. Called by db_delete, db_fetch,
* and db_store. Returns with the hash chain locked.
* 如果想加写锁,则writelock参数传非0值;如果想加读锁,则传0
*/
static int _db_find_and_lock(DB *db, const char *key, int writelock) {
off_t offset, nextoffset;
/*
* Calculate the hash value for this key, then calculate the
* byte offset of corresponding chain ptr in hash table.
* This is where our search starts. First we calculate the
* offset in the hash table for this key.
*/
// 键对应的散列链的地址
db->chainoff = (_db_hash(db, key) * PTR_SZ) + db->hashoff;
db->ptroff = db->chainoff;
/*
* We lock the hash chain here. The caller must unlock it
* when done. Note we lock and unlock only the first byte.
* 只对散列链开始处的第一个字节加锁
* 这种方式允许多个进程同时搜索不同散列链,增加了并发性
*/
if (writelock) {
// 默认如果对指定文件的指定位置加写锁时该位置已被加读、写锁,则fcntl函数会直接返回
// writew_lock函数是fcntl函数的接口函数,如果该位置已被加读、写锁,该函数会一直等待
if (writew_lock(db->idxfd, db->chainoff, SEEK_SET, 1) < 0) {
printf("_db_find_and_lock: writew_lock error\n");
exit(1);
}
} else {
if (readw_lock(db->idxfd, db->chainoff, SEEK_SET, 1) < 0) {
printf("_db_find_and_lock: readw_lock error\n");
exit(1);
}
}
/*
* Get the offset in the index file of first record
* on the hash chain (can be 0).
* 散列链为空时,_db_readptr函数返回0
*/
offset = _db_readptr(db, db->ptroff);
while (offset != 0) {
// 读取索引记录,然后将其填入db.idxbuf,如果返回0,说明已到达散列链的最后一项
nextoffset = _db_readidx(db, offset);
if (strcmp(db->idxbuf, key) == 0) {
break; /* found a match */
}
// 如果找到了目标键,db->ptroff指向目标键之前索引记录的地址
// 这样做在删除一条记录时很有用,因为删除时要修改前一条记录的链指针
db->ptroff = offset; /* offset of this (unequal) record */
offset = nextoffset; /* next one to compare */
}
/*
* offset == 0 on error (record not found).
*/
return offset == 0 ? -1 : 0;
// 在返回时,如果找到了匹配键:
// db->ptroff包含前一索引记录的地址
// db->datoff包含数据记录的地址
// db->datlen包含数据记录的长度
}
/*
* Calculate the hash value for a key.
* 它将key中的每一个ASCII字符乘这个字符在字符串中以1开始的索引号,
* 将这些结果加起来,除以散列表记录项数,余数作为这个键的散列值
*/
static DBHASH _db_hash(DB *db, const char *key) {
DBHASH hval = 0;
char c;
int i;
for (i = 1; (c = *key++) != 0; i++) {
hval += c * i; /* ascii char times its 1-based index */
}
return (hval % db->nhash);
}
/*
* 读以下三种链表指针中的任一种:
* 索引文件最开始处指向空闲链表中第一个索引记录的指针
* 散列表中指向散列链的第一条索引记录的指针
* 存在每条索引记录开始处,指向下一条记录的指针(此指针既可以处于一条散列链表中,也可以处于空闲链表中)
* 此函数不进行加锁操作,调用者应事先加好锁
*/
static off_t _db_readptr(DB *db, off_t offset) {
char asciiptr[PTR_SZ + 1];
if (lseek(db->idxfd, offset, SEEK_SET) == -1) {
printf("_db_readptr: lseek error to ptr field\n");
exit(1);
}
if (read(db->idxfd, asciiptr, PTR_SZ) != PTR_SZ) {
printf("_db_readptr: read error ofptr field\n");
exit(1);
}
asciiptr[PTR_SZ] = 0; /* null terminate */
// 返回前将指针从ASCII形式转换为长整型
return atol(asciiptr);
}
/*
* Read the next index record. We start at the specified offset
* in the index file. We read the index record into db->idxbuf
* and replace the separators with null bytes. If all is OK we
* set db->datoff and db->datlen to the offset and length of the
* corresponding data record in the data file.
*/
static off_t _db_readidx(DB *db, off_t offset) {
ssize_t i;
char *ptr1, *ptr2;
char asciiptr[PTR_SZ + 1], asciilen[IDXLEN_SZ + 1];
struct iovec iov[2];
/*
* Position index file and record the offset. db_nextrec
* calls us with offset==0, meaning read from current offset.
* We still need to call lseek to record the current offset.
* 按调用者提供的参数查找索引文件偏移量,在DB结构中记录该偏移量
* 由于索引记录绝不会放在偏移量为0处,因此可以放心使用0表示从当前偏移量处读
*/
if ((db->idxoff = lseek(db->idxfd, offset,
offset == 0 ? SEEK_CUR : SEEK_SET)) == -1) {
printf("_db_readidx: lseek error\n");
exit(1);
}
/*
* Read the ascii chain ptr and the ascii length at
* the front of the index record. This tells us the
* remaining size of the index record.
* 调用readv读在索引记录开始处的两个定长字段:
* 指向下一索引记录的链指针、该索引记录余下部分的长度
*/
iov[0].iov_base = asciiptr;
iov[0].iov_len = PTR_SZ;
iov[1].iov_base = asciilen;
iov[1].iov_len = IDXLEN_SZ;
if ((i = readv(db->idxfd, &iov[0], 2)) != PTR_SZ + IDXLEN_SZ) {
if (i == 0 && offset == 0) {
return -1; /* EOF for db_nextrec */
}
printf("_db_readidx: readv error of index record\n");
exit(1);
}
/*
* This is our return value; always >= 0.
*/
asciiptr[PTR_SZ] = 0; /* null terminate */
db->ptrval = atol(asciiptr); /* offset of next key in chain */
asciilen[IDXLEN_SZ] = 0; /* null terminate */
if ((db->idxlen = atoi(asciilen)) < IDXLEN_MIN ||
db->idxlen > IDXLEN_MAX) {
printf("_db_readidx: invalid length\n");
exit(1);
}
/*
* Now read the actual index record. We read it into the key
* buffer that we malloced when we opened the database.
* 将索引记录的变长部分读入DB.idxbuf字段
*/
if ((i = read(db->idxfd, db->idxbuf, db->idxlen)) != db->idxlen) {
printf("_db_readidx: read error of index record\n");
exit(1);
}
if (db->idxbuf[db->idxlen - 1] != NEWLINE) { /* sanity check,记录应以换行符结尾 */
printf("_db_readidx: missing new line\n");
exit(1);
}
db->idxbuf[db->idxlen - 1] = 0; /* replace new line with null */
/*
* Find the separators in the index record.
* 将索引记录变长部分分为3个字段:
* 键、对应数据记录的偏移量、数据记录长度
* 它们被SEP(本例中为冒号:)字符分隔
*/
if ((ptr1 = strchr(db->idxbuf, SEP)) == NULL) {
printf("_db_readidx: missing first separator\n");
exit(1);
}
*ptr1++ = 0; /* replace SEP with null */
if ((ptr2 = strchr(ptr1, SEP)) == NULL) {
printf("_db_readidx: missing second separator\n");
exit(1);
}
*ptr2++ = 0; /* replace SEP with null */
if (strchr(ptr2, SEP) != NULL) {
printf("_db_readidx: too many separators\n");
exit(1);
}
/*
* Get the starting offset and length of the data record.
*/
if ((db->datoff = atol(ptr1)) < 0) {
printf("_db_readidx: starting offset < 0\n");
exit(1);
}
if ((db->datlen = atol(ptr2)) <= 0 || db->datlen > DATLEN_MAX) {
printf("_db_readidx: invalid length\n");
exit(1);
}
return db->ptrval; /* return offset of next key in chain */
}
/*
* Read the current data record into the data buffer.
* Return a pointer to the null-terminated data buffer.
* 在datoff和datlen正确初始化后,_db_readdat函数将数据记录读入DB.datbuf字段指向的缓冲区
*/
static char *_db_readdat(DB *db) {
if (lseek(db->datfd, db->datoff, SEEK_SET) == -1) {
printf("_db_readdat: lseek error\n");
exit(1);
}
if (read(db->datfd, db->datbuf, db->datlen) != db->datlen) {
printf("_db_readdat: read error\n");
exit(1);
}
if (db->datbuf[db->datlen - 1] != NEWLINE) { /* sanity check */
printf("_db_readdat: missing newline\n");
exit(1);
}
db->datbuf[db->datlen - 1] = 0; /* replace newline with null */
return db->datbuf; /* return pointer to data record */
}
/*
* Delete the specified record.
*/
int db_delete(DBHANDLE h, const char *key) {
DB *db = h;
int rc = 0; /* assume record will be found */
// _db_find_and_lock函数的第三个参数为1表示对散列链加写锁
if (_db_find_and_lock(db, key, 1) == 0) {
_db_dodelete(db);
++db->cnt_delok;
} else {
rc = -1; /* not found */
++db->cnt_delerr;
}
// 不管是否找到了记录,都需要解锁,因为上锁的是散列链中第一个节点的第一个字节
if (un_lock(db->idxfd, db->chainoff, SEEK_SET, 1) < 0) {
printf("db_delete: un_lock error\n");
exit(1);
}
return rc;
}
/*
* Delete the current record specified by the DB structure.
* This function is called by db_delete and db_store, after
* the record has been located by _db_find_and_lock.
* 一条记录被删除后,将其键和数据记录设为空
*/
static void _db_dodelete(DB *db) {
int i;
char *ptr;
off_t freeptr, saveptr;
/*
* Set data buffer and key to all blanks.
*/
for (ptr = db->datbuf, i = 0; i < db->datlen - 1; ++i) {
*ptr++ = SPACE;
}
*ptr = 0; /* null terminate for _db_writedat */
ptr = db->idxbuf;
while (*ptr) {
*ptr++ = SPACE;
}
/*
* We have to lock the free list.
* 此处的加锁比较保守,可以在真正使用到空闲链表时再加锁
* 如放到_db_writedat函数调用后,先删除数据文件中内容,再加锁删除索引文件内容
* 这样可以获得更大的并发性
* 但不这么做的原因在于避免与db_nextrec函数发生竞争条件
* db_nextrec函数现在会先对空闲列表加锁,然后读入一个索引记录,判定该记录非空
* 接着读数据记录,但在它调用_db_readidx和_db_readdat之间
* 记录可能被不加锁的本函数版本删除
*/
if (writew_lock(db->idxfd, FREE_OFF, SEEK_SET, 1) < 0) {
printf("_db_dodelete: writew_lock error\n");
exit(1);
}
/*
* Write the data record with all blanks.
* 此时不对数据文件加写锁,因为db_delete函数已经对这条记录的散列链加了写锁
* 保证了不会有其他进程能读、写这条记录
*/
_db_writedat(db, db->datbuf, db->datoff, SEEK_SET);
/*
* Read the free list pointer. Its value bacomes the
* chain ptr field of the deleted index record. This means
* the deleted record becomes the head of the free list.
*/
freeptr = _db_readptr(db, FREE_OFF);
/*
* Save the contents of index record chain ptr,
* before it's rewritten by _db_writeidx.
*/
saveptr = db->ptrval;
/*
* Rewrite the index record. This also rewrites the length
* of the index record, the data offset, and the data length,
* none of which has changed, but that's OK.
* 把要删除的索引记录的下一索引记录指针字段设为当前空闲列表头节点
*/
_db_writeidx(db, db->idxbuf, db->idxoff, SEEK_SET, freeptr);
/*
* Write the new free list pointer.
* 把指向要删除的索引记录的指针写到空闲链表头
*/
_db_writeptr(db, FREE_OFF, db->idxoff);
/*
* Rewrite the chain ptr that pointed to this record being
* deleted. Recall that _db_find_and_lock sets db->ptroff to
* point to this chain ptr. We set this chain ptr to the
* contents of the deleted record's chain ptr, saveptr.
* 修改散列链中前一条记录的指针,使其指向正在删除记录之后的记录
*/
_db_writeptr(db, db->ptroff, saveptr);
if (un_lock(db->idxfd, FREE_OFF, SEEK_SET, 1) < 0) {
printf("_db_dodelete: un_lock error\n");
exit(1);
}
}
/*
* Write a data record. Called by _db_dodelete (to write
* the record with blanks) and db_store.
*/
static void _db_writedat(DB *db, const char *data, off_t offset, int whence) {
struct iovec iov[2];
static char newline = NEWLINE;
/*
* If we're appending, we have to lock before doing the lseek
* and write to make the two an atomic operation. If we're
* overwriting an existing record, we don't have to lock.
* 只有_db_dodelete和db_store函数会调用本函数
* 如果是前者,db_delete函数已经对这条记录的散列链加了写锁,保证不会有其他进程能读写此记录
* 如果是追加数据,锁住整个数据文件,这样不会影响其他读进程和写进程
*/
if (whence == SEEK_END) { /* we're appending, lock entire file */
if (writew_lock(db->datfd, 0, SEEK_SET, 0) < 0) {
printf("_db_writedat: writew_lock error\n");
abort();
}
}
if ((db->datoff = lseek(db->datfd, offset, whence)) == -1) {
printf("_db_writedat: lseek error\n");
abort();
}
db->datlen = strlen(data) + 1; /* datlen includes newline */
// 设置iov数组,不能想当然地认为调用者缓冲区尾端有空间可以追加换行符
// 换行符应写入另一缓冲区,然后再从该缓冲区写至数据记录
iov[0].iov_base = (char *)data;
iov[0].iov_len = db->datlen - 1;
iov[1].iov_base = &newline;
iov[1].iov_len = 1;
if (writev(db->datfd, &iov[0], 2) != db->datlen) {
printf("_db_writedat: writev error of data record\n");
abort();
}
if (whence == SEEK_END) {
if (un_lock(db->datfd, 0, SEEK_SET, 0) < 0) {
printf("_db_writedat: un_lock error\n");
abort();
}
}
}
/*
* Write an index record. _db_writedat is called before
* this function to set the datoff and datlen fields in the
* DB structure, which we need to write the index record.
*/
static void _db_writeidx(DB *db, const char *key, off_t offset, int whence, off_t ptrval) {
struct iovec iov[2];
char asciiptrlen[PTR_SZ + IDXLEN_SZ + 1];
int len;
// 验证散列链中下一个指针是否有效
if ((db->ptrval = ptrval) < 0 || ptrval > PTR_MAX) {
printf("_db_writeidx: invalid ptr: %d\n", ptrval);
exit(1);
}
// 把索引记录中下一记录指针字段之后的部分写到db->idxbuf中
sprintf(db->idxbuf, "%s%c%lld%c%ld\n", key, SEP, (long long)db->datoff,
SEP, (long)db->datlen);
len = strlen(db->idxbuf);
if (len < IDXLEN_MIN || len > IDXLEN_MAX) {
printf("_db_writeidx: invalid length\n");
abort();
}
// 把索引记录中前面的定长部分写到asciiptrlen中
// 通过指定宽度使ptrval和len的长度与索引记录的格式说明中的长度匹配,这样做的原因是:
// off_t和size_t字段长度随平台不同而不同,32位系统也能提供64位的文件偏移
// 所以不能假设off_t类型的长度
sprintf(asciiptrlen, "%*lld%*d", PTR_SZ, (long long)ptrval, IDXLEN_SZ, len);
/*
* If we're appending, we have to lock before doing the lseek
* and write to make the two an atomic operation. If we're
* overwriting an existing record, we don't have to lock.
* 只有追加一条索引记录才需要加锁
* 与_db_writedat函数一样,_db_dodelete函数调用此函数时调用者已经在散列链上加了写锁
* 追加时,写锁加在散列表的最后一个链表指针后的换行符到索引文件末尾,这不会影响其他进程的读写操作
* 因为它们是对散列链加锁,但如果其他进程也调用db_store追加数据,则会被锁住
* 这把锁使定位操作和写操作成为原子操作
* 这把锁需要是建议性锁,否则会阻塞除db_store函数外的读操作和写操作
* 本数据库函数库只有db_store函数会造成此处加锁
*/
if (whence == SEEK_END) { /* we're appending */
if (writew_lock(db->idxfd, ((db->nhash + 1) * PTR_SZ) + 1, SEEK_SET, 0) < 0) {
printf("_db_writeidx: writew_lock error\n");
abort();
}
}
/*
* Position the index file and record the offset.
*/
if ((db->idxoff = lseek(db->idxfd, offset, whence)) == -1) {
printf("_db_writeidx: lseek error\n");
abort();
}
iov[0].iov_base = asciiptrlen;
iov[0].iov_len = PTR_SZ + IDXLEN_SZ;
iov[1].iov_base = db->idxbuf;
iov[1].iov_len = len;
if (writev(db->idxfd, &iov[0], 2) != PTR_SZ + IDXLEN_SZ + len) {
printf("_db_writeidx: writev error of index record\n");
abort();
}
if (whence == SEEK_END) {
if (un_lock(db->idxfd, ((db->nhash + 1) * PTR_SZ) + 1, SEEK_SET, 0) < 0) {
printf("_db_writeidx: un_lock error\n");
abort();
}
}
}
/*
* Write a chain ptr field somewhere in the index file:
* the free list, the hash table, or in an index record.
*/
static void _db_writeptr(DB *db, off_t offset, off_t ptrval) {
char asciiptr[PTR_SZ + 1];
if (ptrval < 0 || ptrval > PTR_MAX) {
printf("_db_writeptr: invalid ptr: %d\n", ptrval);
exit(1);
}
sprintf(asciiptr, "%*lld", PTR_SZ, (long long)ptrval);
if (lseek(db->idxfd, offset, SEEK_SET) == -1) {
printf("_db_writeptr: lseek error to ptr field\n");
abort();
}
if (write(db->idxfd, asciiptr, PTR_SZ) != PTR_SZ) {
printf("_db_writeptr: write error of ptr field\n");
abort();
}
}
/*
* Store a record in the database. Return 0 if OK, 1 if record
* exists and DB_INSERT specified, -1 on error.
*/
int db_store(DBHANDLE h, const char *key, const char *data, int flag) {
DB *db = h;
int rc, keylen, datlen;
off_t ptrval;
if (flag != DB_INSERT && flag != DB_REPLACE && flag != DB_STORE) {
errno = EINVAL;
return -1;
}
keylen = strlen(key);
datlen = strlen(data) + 1; /* +1 for newline at end */
// 如果数据记录长度无效,生成core文件并终止
// 如果构造正式应用的函数库,最好返回出错状态,给应用程序一个恢复的机会
if (datlen < DATLEN_MIN || datlen > DATLEN_MAX) {
printf("db_store: invalid data length\n");
abort();
}
/*
* _db_find_and_lock calculates which hash table this new record
* goes into (db->chainoff), regardless of whether it already
* exists or not. The following calls to _db_writeptr change the
* hash table entry for this chain to point to the new record.
* The new record is added to the front of the hash chain.
* 因为db_store函数很可能改变散列链,因此调用_db_find_and_lock时第三个参数传1指明对散列链加写锁
*/
if (_db_find_and_lock(db, key, 1) < 0) { /* record not found */
if (flag == DB_REPLACE) {
rc = -1;
++db->cnt_storerr;
errno = ENOENT; /* error, record does not exist */
goto doreturn;
}
/*
* _db_find_and_lock locked the hash chain for us; read
* the chain ptr to the first index record on hash chain.
*/
ptrval = _db_readptr(db, db->chainoff);
// _db_findfree函数在空闲链表中搜索一条已删除的记录
// 该被删除的记录的键长度和数据长度与参数keylen和datlen相同
// 情况1:_db_findfree函数没有找到一条键长度和数据长度与参数keylen和datlen相同的已删除记录
if (_db_findfree(db, keylen, datlen) < 0) {
/*
* Can't find an empty record big enough. Append the
* new record to the ends of the index and data files.
* 先写数据部分和索引部分
*/
_db_writedat(db, data, 0, SEEK_END);
// 把索引记录写到索引文件,新的索引记录的下一条索引指针是ptrval参数
// 相当于把新的索引记录放到hash链的最前面
_db_writeidx(db, key, 0, SEEK_END, ptrval);
/*
* db->idxoff was set by _db_writeidx. The new
* record goes to the front of the hash chain.
* 将新记录添加到对应的散列表头部
*/
_db_writeptr(db, db->chainoff, db->idxoff);
++db->cnt_stor1;
// 情况2:_db_findfree函数找到对应大小的空记录,并将空记录从空闲链表中移除
} else {
/*
* Reuse an empty record. _db_findfree removed it from
* the free list and set both db->datoff and db->idxoff.
* Reused record goes to the front of the hash chain.
*/
_db_writedat(db, data, db->datoff, SEEK_SET);
_db_writeidx(db, key, db->idxoff, SEEK_SET, ptrval);
_db_writeptr(db, db->chainoff, db->idxoff);
db->cnt_stor2++;
}
} else { /* record found */
if (flag == DB_INSERT) {
rc = 1; /* error, record already in db */
++db->cnt_storerr;
goto doreturn;
}
/*
* We are replacing an existing record. We know the new
* key equals the existing key, but we need to check if
* the data records are the same size.
* 情况3:替换一条已有记录时,新数据记录长度与已有记录长度不同
* 此时删除原有记录,将该删除记录放在空闲链表头部(_db_dodelete函数中实现)
* 然后将新记录加入索引文件和数据文件的末尾
* 也可用其他方法,如再找找是否有数据大小正好的已删除记录项
*/
if (datlen != db->datlen) {
/* delete the existing record,删除已有记录,并将其放在空闲链表头部 */
_db_dodelete(db);
/*
* Reread the chain ptr in the hash table
* (it may change with the deltion).
* 如果被删除的记录是哈希表中相应位置的第一个链表节点
* 则删除操作后,需要更新ptrval的值
*/
ptrval = _db_readptr(db, db->chainoff);
/*
* Append new index and data records to end of files.
*/
_db_writedat(db, data, 0, SEEK_END);
_db_writeidx(db, key, 0, SEEK_END, ptrval);
/*
* New record goes to the front of the hash chain.
*/
_db_writeptr(db, db->chainoff, db->idxoff);
++db->cnt_stor3;
} else {
/*
* Same size data, just replace data record.
* 情况4:替换一条已有记录,新记录长度与已有记录的长度一样,重写数据记录即可
*/
_db_writedat(db, data, db->datoff, SEEK_SET);
++db->cnt_stor4;
}
}
rc = 0; /* OK */
doreturn: /* unlock hash chain locked by _db_find_and_lock */
if (un_lock(db->idxfd, db->chainoff, SEEK_SET, 1) < 0) {
printf("db_store: un_lock error\n");
abort();
}
return rc;
}
/*
* Try to find a free index record and accompanying data record
* of the correct sizes. We're only called by db_store.
* 试图找到一个指定大小的空闲索引记录和相关联的数据记录
*/
static int _db_findfree(DB *db, int keylen, int datlen) {
int rc;
off_t offset, nextoffset, saveoffset;
/*
* Lock the free list.
*/
if (writew_lock(db->idxfd, FREE_OFF, SEEK_SET, 1) < 0) {
printf("_db_findfree: writew_lock error\n");
abort();
}
/*
* Read the free list pointer.
*/
saveoffset = FREE_OFF;
offset = _db_readptr(db, saveoffset);
while (offset != 0) {
nextoffset = _db_readidx(db, offset);
// 只有一个已删除记录的键长度和数据长度与要插入的新记录的
// 键长度及数据长度一样时才重用已删除记录的空间
// 还有其他更好的算法,但复杂度会增加
if (strlen(db->idxbuf) == keylen && db->datlen == datlen) {
break; /* found a match */
}
saveoffset = offset;
offset = nextoffset;
}
if (offset == 0) {
rc = -1; /* not match found */
} else {
/*
* Found a free record with matching sizes.
* The index record was read in by _db_readidx above,
* which sets db->ptrval. Also, saveoffset points to
* the chain ptr that pointed to this empty record on
* the free list. We set this chain ptr to db->ptrval,
* which removes the empty record from the free list.
* saveoffset是目标空闲索引记录的上一条索引的偏移
* db->ptrval是目标空闲索引记录的下一条索引的偏移
* 把目标空闲索引记录的下一个链指针写到前一记录的链表指针
* 就从空闲链表中移除了该记录
* 这条命令在saveoffset处开始写(上一条记录的开头,即指向下一条记录的指针字段处)
* 写的内容是目标索引记录的下一条索引的偏移
*/
_db_writeptr(db, saveoffset, db->ptrval);
rc = 0;
/*
* Notice also that _db_readidx set both db->idxoff
* and db->datoff. This is used by the caller, db_store,
* to write the new index record and data record.
*/
}
/*
* Unlock the free list.
*/
if (un_lock(db->idxfd, FREE_OFF, SEEK_SET, 1) < 0) {
printf("_db_findfree: un_lock error\n");
abort();
}
return rc;
}
/*
* Rewind the index file for db_nextrec.
* Automatically called by db_open.
* Must be called before first db_nextrec.
* 此函数用于把索引文件的文件偏移量设置为指向第一条索引记录(紧跟在散列表之后的那条)
*/
void db_rewind(DBHANDLE h) {
DB *db = h;
off_t offset;
offset = (db->nhash + 1) * PTR_SZ; /* +1 for free list ptr */
/*
* We're just setting the file offset for this process
* to the start of the index records; no need to lock.
* +1 below for newline at end of hash table.
*/
if ((db->idxoff = lseek(db->idxfd, offset + 1, SEEK_SET)) == -1) {
printf("db_rewind: lseek error\n");
abort();
}
}
/*
* Return the next sequential record.
* We just step our way through the index file, ignoring deleted
* records. db_rewind must be called before this function is
* called the first time.
* 此函数的返回值是指向数据缓冲区的指针
* 如果调用者提供的key参数非空,将相应键复制到该缓冲区中
* 调用者负责分配可以存放键的足够大的缓冲区
* 大小为IDXLEN_MAX字节的缓冲区足够存放任意键
*/
char *db_nextrec(DBHANDLE h, char *key) {
DB *db = h;
char c;
char *ptr;
/*
* We read lock the free list so that we don't read
* a record in the middle of its being deleted.
* 因为取下一条记录时不使用任何散列链表,也不能判断每条记录属于哪条散列链
* 因此可能在读取一条记录时其索引记录正在被删除,为防止这种情况,对空闲链表加读锁
* 这样可以避免与_db_dodelete和_db_findfree相互影响,这两个函数也会对空闲链表加锁
* 如果不对空闲链表加锁,则可能被读的记录正在被删除
* 从而导致返回的数据记录是空的或不正确的,发生过程如下:
* (1)本函数调用了_db_readidx后,将记录的键读入了索引缓冲区,然后本进程被内核调度进程暂停
* (2)另一个进程运行,此时它刚好删除了这条记录,使得索引文件和数据文件中对应部分被清空
* (3)当本进程恢复并继续调用_db_readdat时,返回的是空数据记录
* 以下对空闲链表加读锁使得对于其他操作同一数据库的合作进程而言
* 读入索引记录过程和读入数据记录过程是一个原子操作
*/
if (readw_lock(db->idxfd, FREE_OFF, SEEK_SET, 1) < 0) {
printf("db_nextrec: eradw_lock error\n");
abort();
}
do {
/*
* Read next sequential index record.
* 传给_db_readidx函数的第二个参数为0,表示从索引文件的当前偏移量继续读索引记录
*/
if (_db_readidx(db, 0) < 0) {
ptr = NULL; /* end of index file, EOF */
goto doreturn;
}
/*
* Check if key is all blank (empty record).
*/
ptr = db->idxbuf;
while ((c = *ptr++) != 0 && c == SPACE) {
/*
* skip until null byte or non blank
* _db_dodelete函数以设置全空格的方式清除键
* 索引记录db->idxbuf总是null结尾的
*/
}
} while (c == 0); /* loop until a nonblank key is found */
if (key != NULL) {
strcpy(key, db->idxbuf); /* return key */
}
ptr = _db_readdat(db); /* return pointer to data buffer */
++db->cnt_nextrec;
doreturn:
if (un_lock(db->idxfd, FREE_OFF, SEEK_SET, 1) < 0) {
printf("db_nextrec: un_lock error\n");
abort();
}
return ptr;
}
/*
* 通常在以下形式的循环中使用db_rewind和db_nextrec函数
* db_rewind(db);
* while ((ptr = db_nextrec(db, key))!= NULL) {
* // process record
* }
* 以上循环过程中可能会发生以下情况:
* 1.刚返回一条记录,记录就被删除了
* 2.刚跳过一条已删除记录,这条记录的空间就被一条新记录重用
* 因此如想通过以上过程获得数据库的一份准确的快照,则这段时间内不应该做插入和删除操作
*/
为测试以上数据库函数库性能,编写了一个测试程序,该程序接受两个命令行参数:要创建的子进程个数和每个子进程向数据库写的记录条数nrec。程序首先会创建一个空数据库,然后通过fork函数创建指定数目的子进程,等待所有子进程结束。每个子进程执行以下步骤:
1.向数据库写nrec条记录。
2.通过键值读回nrec条记录。
3.执行下面的循环nrec*5次:
(a)随机读一条记录。
(b)每循环37次,随机删除一条记录。
(c)每循环11次,随机插入一条记录并读取这条记录。
(d)每循环17次,随机替换一条记录为新记录,在连续两次替换中,一次用同样大小的记录替换,一次用比以前更长的记录替换。
4.将此子进程写的所有记录删除,每删除一条记录,随机查找10条记录。
DB结构的cnt_xxx变量记录对数据库进行的操作数,每个子进程的各个操作数一般会与其他子进程的对应操作数不一样,因为每个子进程用来选择记录的随机数生成器是根据其进程ID来初始化的(可能会找不到指定的随机记录等),每个子进程操作的典型计数值如下:
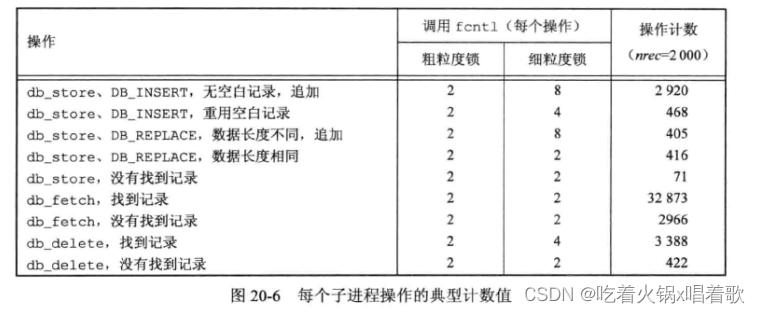
读取的次数大约是存储和删除的10倍,这可能是许多数据库应用程序的典型情况。
每个子进程只对该子进程所写的记录执行读取、存储、删除操作,由于所有子进程对同一个数据库进行操作,所以会有并发控制。数据库中的记录总数与子进程数成比例。
通过运行程序的3个不同版本来比较加粗粒度锁和加细粒度锁提供的并发,且比较3种不同的加锁方式(不加锁、建议性锁、强制性锁)。细粒度锁版本是以上代码版本;粗粒度锁版本是访问数据库时就对整个数据库加读写锁;不加锁版本把加锁例程全部去掉,这样可以计算出加锁的开销。通过改变数据库文件的权限标志位,可以使加锁版本使用建议性锁或强制性锁。
以下测试在一台运行Linux 3.2.0的Intel Core-i5系统上运行,此系统拥有4个内核,因此可以允许至多4个进程并发运行。
以下是单进程的运行结果:
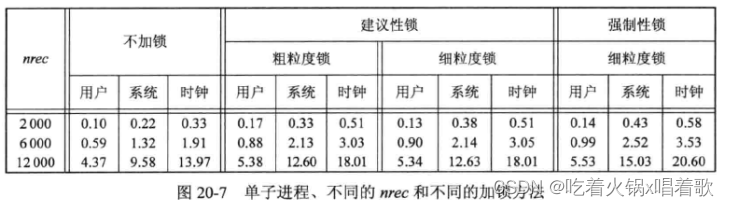
以上时间单位为秒。在所有情况下,用户CPU时间加上系统CPU时间都基本等于时钟时间,说明这组测试受CPU限制而非磁盘操作限制。
加建议性锁时,粗粒度锁和细粒度锁结果基本一样,这是因为对于单进程来说两种锁并没有区别,除了细粒度锁的额外的fcntl函数调用。
比较不加锁和加建议性锁,加锁调用在系统CPU时间上增加了32%~73%,即使这些锁实际并没有使用过(因为只有一个进程运行)。用户CPU时间对4种不同加锁方法基本一样,因为用户代码基本是一样的(除了调用fcntl的次数不同)。
对多个子进程的不加锁程序测试发现,结果是随机的错误,错误情况包括:添加到数据库中的记录找不到、测试程序异常退出等。几乎每次运行测试程序,都有不同错误发生,这是典型的竞争条件,多个进程在没有任何加锁的情况下修改同一个文件,错误情况不可预测。
以下是多进程的测试结果,这组测试的主要目的是比较粗粒度锁和细粒度锁的不同,由于加细粒度锁时数据库的各个部分被锁住的时间比加粗粒度少,所以从直觉上说,加细粒度锁应该能提供更好的并发性:
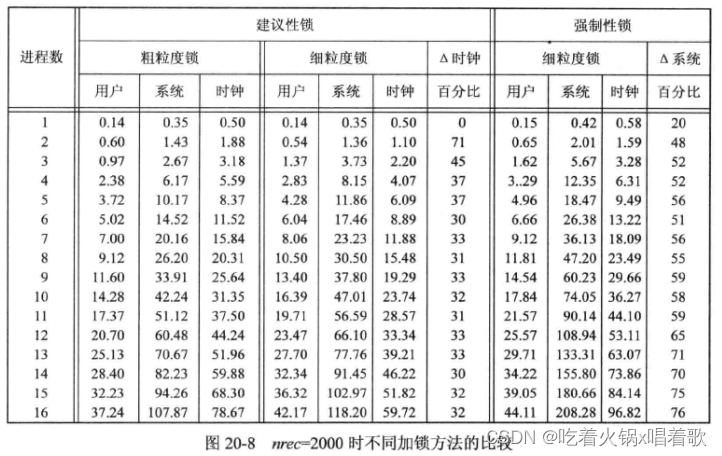
上图中时间单位均为秒,所有这些时间均是父进程与所有子进程的总和。
上图中,使用多进程时,用户时间和系统时间之和超过了时钟时间,这乍看起来有点奇怪,但当采用多核时是正常的,此时,显示的CPU处理时间是程序运行的所有核运转的时间之和,因为可以并发多个进程(每个核运行一个进程)所以CPU处理时间会超过时钟时间。
上图中的△时钟列是从加建议性细粒度锁到加建议性粗粒度锁的时钟时间百分比增量,从中可以知道使用细粒度锁得到了多大的并发性。对于多进程,使用粗粒度锁的时间消耗会增大约30%。
我们期望从粗粒度锁到细粒度锁时钟时间会减少,结果也确实如此。我们也预期当对任意数量的进程使用细粒度锁时系统时间仍然会保持较高值,因为使用细粒度锁会发出更多fcntl调用。如将图20-6中的fcntl调用次数加在一起,会发现对于粗粒度锁其平均值为87858,对于细粒度锁其平均值为115520,基于此,我们认为由于增加了31%的fcntl调用,所以会增加细粒度锁的系统时间,然而在测试中,两个进程时,加细粒度锁的两个进程其系统时间减少了,超过两个进程的系统时间只有小幅增加,这让人困惑。出现这种情况有两个原因,首先,单进程测试结果显示,当没有对锁进行竞争时,粗粒度锁和细粒度锁的时间之间没有显著的差别,这说明对于额外的fcntl调用所引起的CPU负载没有影响测试程序的性能;其次,使用粗粒度锁时,持有锁的时间较长,这增加了其他进程因等待该锁而陷入阻塞的可能性,而使用细粒度锁时,加锁的时间较短,进程被阻塞的可能性就降低了,正是这些粗粒度锁需要休眠和唤醒进程的额外时间增加了系统时间,最终降低了两种锁的系统时间差异。
上图中△系统列是从加建议性细粒度锁到加强制性细粒度锁的系统CPU时间百分比增量,随着并发数增加,强制性锁显著增加了系统时间(20%~76%)。
由于所有这些测试的数据库库代码几乎一样,因此期望对每一行的用户CPU时间基本一样。
当第一次运行以上测试时,测试显示对于多进程使用锁,其粗粒度锁的用户时间几乎是细粒度锁的两倍,因为两个数据库版本是相同的,除了调用fcntl的次数不同,因此这说不通,调查研究后发现,使用粗粒度锁时会有更多竞争,进程也会等待更久,操作系统于是就决定降低CPU时钟频率来节约电量,在使用细粒度锁时,会有更多活动,于是系统提高了CPU时钟频率。在禁用系统频率调整特性后,测试结果就没有这些偏差了,用户时间的差别也小多了。
下图是多进程测试中,加建议性细粒度锁的数据图:
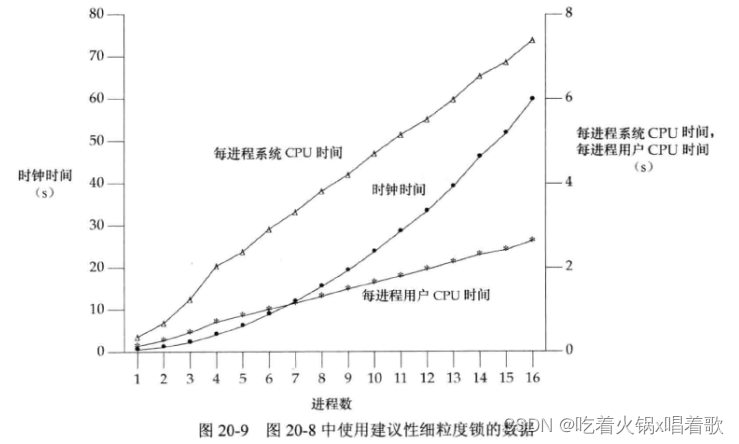
上图显示,每进程系统CPU时间和每进程用户CPU时间都是线性的,但时钟时间是非线性的,可能的原因为:当进程数增大时,操作系统用于进程切换的CPU时间增多,操作系统的开销会增加时钟时间,但不会影响单个进程的CPU时间。
每进程用户CPU时间随进程数增加的原因可能是因为数据库中有了更多记录,每一条散列链更长,所以_db_find_and_lock函数平均要运行更长时间来找到一条记录。
本章数据库库代码中,可以在插入数据时先写数据记录再写索引记录,如果进程先写索引记录,而在写数据记录前被杀死,那么会得到一个有效的索引记录,但指向一个无效的数据记录。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号