

2023数据采集与融合技术实践作业四
作业①
实验内容
要求
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
输出信息
MYSQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
序号 股票代码 股票名称 最新报价 涨跌幅 涨跌额 成交量 振幅 最高 最低 今开 昨收
1 688093 N世华 28.47 10.92 26.13万 7.6亿 22.34 32.0 28.08 30.20 17.55
Gitee文件夹链接
代码
def getdata(url):
browser = webdriver.Chrome()
browser.get(url)
browser.maximize_window()
for page in range(1, 3):
if (page == 2):
browser.find_element(By.XPATH, '//*[@id="main-table_paginate"]/span[1]/a[2]').click() # 第二页
time.sleep(3)
i = 1 # 行数
element = browser.find_element(By.ID, "table_wrapper-table")
trlist = element.find_elements(By.TAG_NAME, "tr") # 获得行
string1 = '//*[@id="table_wrapper-table"]/tbody/tr['
string2 = ']/td[3]/a'
for tr in trlist[i:]:
tdlist = tr.find_elements(By.TAG_NAME, "td") # 获得列
name = tdlist[2].text
string = string1 + str(i) + string2
browser.find_element(By.XPATH, string).click()
current_window = browser.window_handles
browser.switch_to.window(current_window[1]) # 获取当前页面页柄
browser.find_element(By.XPATH, '//*[@id="zjl_box"]/div[1]/ul/li[2]/h3/a').click() # 到达每个公司财务报表
time.sleep(2)
current_window = browser.window_handles
browser.switch_to.window(current_window[2])
browser.find_element(By.XPATH, '//*[@id="zyzbTab"]/li[2]').click() # 主要指标按年度
time.sleep(2)
table = browser.find_element(By.CLASS_NAME, "needScroll") # 主要指标
datalist = []
trlist = table.find_elements(By.TAG_NAME, "tr")
for item in trlist:
tdlist = item.find_elements(By.TAG_NAME, "td")
if len(tdlist) == 0:
tdlist = item.find_elements(By.TAG_NAME, "th")
cell = []
for it in tdlist:
cell.append(it.text)
datalist.append(cell)
browser.find_element(By.XPATH, '/html/body/div[1]/div[2]/div[6]/div[2]/div[1]/ul/li[2]').click() # 资产负债表按年度
time.sleep(1)
table_zcfzb = browser.find_element(By.ID, 'report_zcfzb_table') # 资产负债表
datalist_zcfzb = []
trlist_zcfzb = table_zcfzb.find_elements(By.TAG_NAME, "tr")
for item in trlist_zcfzb:
if (item.is_displayed() == False): # 跳过隐藏标签
continue
tdlist_zcfzb = item.find_elements(By.TAG_NAME, "td")
if len(tdlist_zcfzb) == 0:
tdlist_zcfzb = item.find_elements(By.TAG_NAME, "th")
cell_zcfzb = []
for it in tdlist_zcfzb:
if (it.text == "审计意见(境内)"): # 跳过审计意见
break
cell_zcfzb.append(it.text)
datalist_zcfzb.append(cell_zcfzb)
# for item in datalist_zcfzb:
# print(item)
browser.find_element(By.XPATH, '/html/body/div[1]/div[2]/div[7]/div[2]/div[1]/ul/li[2]').click() # 利润表按年度
time.sleep(1)
table_lrb = browser.find_element(By.XPATH, "//*[@id='report_lrb_table']") # 利润表
datalist_lrb = []
trlist_lrb = table_lrb.find_elements(By.TAG_NAME, "tr")
for item in trlist_lrb:
if (item.is_displayed() == False): # 跳过隐藏标签
continue
tdlist_lrb = item.find_elements(By.TAG_NAME, "td")
if len(tdlist_lrb) == 0:
tdlist_lrb = item.find_elements(By.TAG_NAME, "th")
cell_lrb = []
for it in tdlist_lrb:
if (it.text == "审计意见(境内)"): # 跳过审计意见
break
cell_lrb.append(it.text)
datalist_lrb.append(cell_lrb)
browser.find_element(By.XPATH, '/html/body/div[1]/div[2]/div[8]/div[2]/div[1]/ul/li[2]').click() # 现金流量表按年度
time.sleep(1)
table_xjllb = browser.find_element(By.XPATH, "//*[@id='report_xjllb_table']") # 现金流量表
datalist_xjllb = []
trlist_xjllb = table_xjllb.find_elements(By.TAG_NAME, "tr")
for item in trlist_xjllb:
if (item.is_displayed() == False): # 跳过隐藏标签
continue
tdlist_xjllb = item.find_elements(By.TAG_NAME, "td")
if len(tdlist_xjllb) == 0:
tdlist_xjllb = item.find_elements(By.TAG_NAME, "th")
cell_xjllb = []
for it in tdlist_xjllb:
if (it.text == "审计意见(境内)"): # 跳过审计意见
break
cell_xjllb.append(it.text)
datalist_xjllb.append(cell_xjllb)
# for item in datalist_zcfzb:
# print(item)
saveData(name, datalist, datalist_zcfzb, datalist_lrb, datalist_xjllb)
browser.close()
browser.switch_to.window(current_window[1])
browser.close()
browser.switch_to.window((current_window[0]))
i = i + 1
browser.close()
def saveData(name, datalist, datalist_zcfzb, datalist_lrb, datalist_xjllb):
# file_str = './liquor_data/'+name+'_指标'+'.xls'
workbook = xlwt.Workbook()
worksheet = workbook.add_sheet('主要指标')
worksheet_zcfzb = workbook.add_sheet('资产负债表')
worksheet_lrb = workbook.add_sheet('利润表')
worksheet_xjllb = workbook.add_sheet('现金流量表')
n_row = len(datalist)
n_col = len(datalist[0])
for l in range(n_row):
for m in range(n_col):
worksheet.write(l, m, datalist[l][m])
n_row_1 = len(datalist_zcfzb)
n_col_1 = len(datalist_zcfzb[0])
for l in range(n_row_1 - 1):
for m in range(n_col_1):
worksheet_zcfzb.write(l, m, datalist_zcfzb[l][m])
n_row_2 = len(datalist_lrb)
for l in range(n_row_2 - 1):
for m in range(len(datalist_lrb[0])):
worksheet_lrb.write(l, m, datalist_lrb[l][m])
n_row_3 = len(datalist_xjllb)
n_col_3 = len(datalist_xjllb[0])
for l in range(n_row_3 - 1):
for m in range(n_col_3):
worksheet_xjllb.write(l, m, datalist_xjllb[l][m])
# workbook.save(file_str)
workbook.save(name + "财报" + ".xls")
结果

实验心得
在使用Selenium来爬取网页数据时,Selenium提供了强大的工具来查找HTML元素,这使得我们可以精确地获取我们想要的数据。此外,通过爬取Ajax网页数据,我们可以获取到动态加载的内容,这对于许多现代网站来说是非常重要的。在使用Selenium时,需要等待HTML元素。很多时候,网页需要一些时间来加载所有元素,特别是那些动态加载的元素。通过使用Selenium的等待功能,我们可以确保在获取元素之前,该元素已经完全加载
作业②
实验内容
要求
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
候选网站:中国mooc网:https://www.icourse163.org
输出信息
MYSQL数据库存储和输出格式
Id cCourse cCollege cTeacher cTeam cCount cProcess cBrief
1 Python数据分析与展示 北京理工大学 嵩天 嵩天 470 2020年11月17日 ~ 2020年12月29日 “我们正步入一个数据或许比软件更重要的新时代。——Tim O'Reilly” ……
Gitee文件夹链接
代码
if __name__ == '__main__':
# writer = pd.ExcelWriter("./mooc课程评论.xls") # 设置保存Excel 路径
driver = webdriver.Chrome() # 设置chrome驱动
url = 'https://www.icourse163.org/course/BIT-268001' # 设置要爬取的课程链接
# ["用户","内容","时间","点赞数","第几次课程"] 待爬取的内容
driver.get(url)
cont = driver.page_source
soup = BeautifulSoup(cont, 'html.parser')
ele = driver.find_element(By.ID, "review-tag-button") # 点击 课程评价
ele.click()
xyy = driver.find_element(By.CLASS_NAME, "ux-pager_btn__next") # 翻页功能
connt = driver.page_source
soup = BeautifulSoup(connt, 'html.parser') # 得到网页源代码
all_table = [] # 保存所需数据
all_table.append(["用户", "内容", "时间", "点赞数", "第几次课程"])
for i in range(1374): # 共1373页
xyy.click()
connt = driver.page_source
soup = BeautifulSoup(connt, 'html.parser')
content = soup.find_all('div', {
'class': 'ux-mooc-comment-course-comment_comment-list_item_body'}) # 全部评论
for ctt in content:
# 获取用户名
user_name = ctt.find("a", {
"class": "primary-link ux-mooc-comment-course-comment_comment-list_item_body_user-info_name"})
user_name = user_name.text
print(user_name)
# 发布时间
publish_time = ctt.find('div', {
'class': 'ux-mooc-comment-course-comment_comment-list_item_body_comment-info_time'})
publish_time = publish_time.text
publish_time = publish_time[4:]
print(publish_time)
# 第几次课程
course_nums = ctt.find('div', {
'class': 'ux-mooc-comment-course-comment_comment-list_item_body_comment-info_term-sign'})
course_nums = course_nums.text
course_nums = course_nums.replace(" ", "")
course_nums = course_nums.replace("\n", "")
print(course_nums)
scontent = []
aspan = ctt.find_all('span')
for span in aspan:
scontent.append(span.string)
# 点赞数
like = scontent[5]
# 课程内容
scontent = scontent[1]
print(scontent)
all_table.append([user_name, scontent, publish_time, like, course_nums])
结果

心得体会
首先,使用Selenium的WebDriver功能来打开中国mooc网的网站,并使用XPath和CSS选择器来查找和定位需要的HTML元素。然后,通过模拟用户登录的过程,实现了对中国mooc网的爬取。这个过程中,使用了Selenium的wait功能来等待网页元素的加载,特别是那些需要Ajax加载的元素。同时,深入理解了如何通过Selenium来模拟用户的行为,如点击按钮、输入文本等。
作业③
实验内容
要求
掌握大数据相关服务,熟悉Xshell的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
输出信息
实验关键步骤或结果截图。
结果
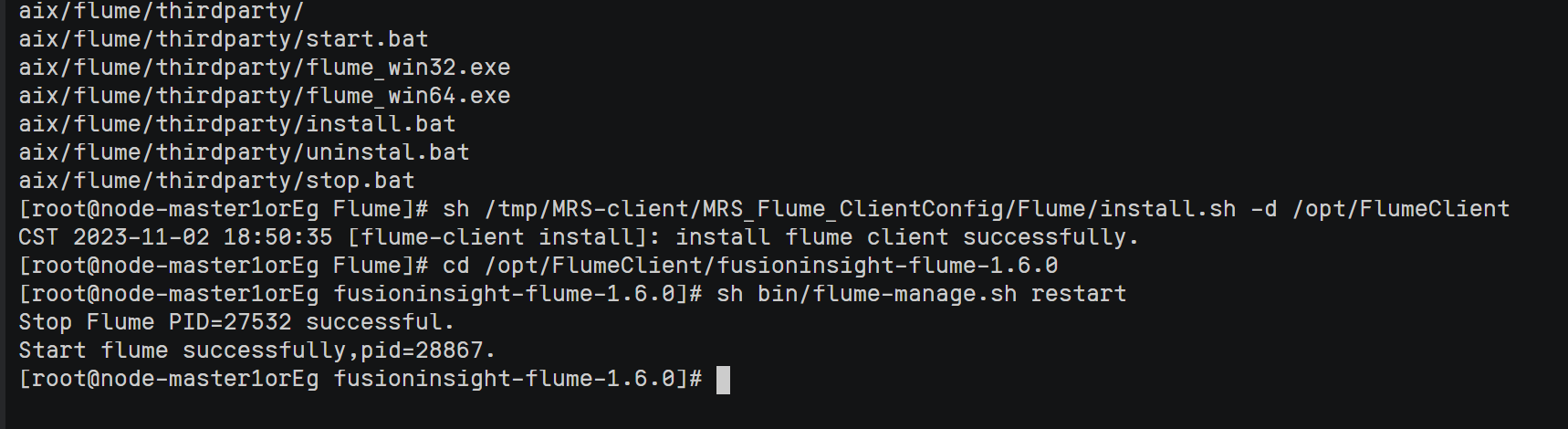
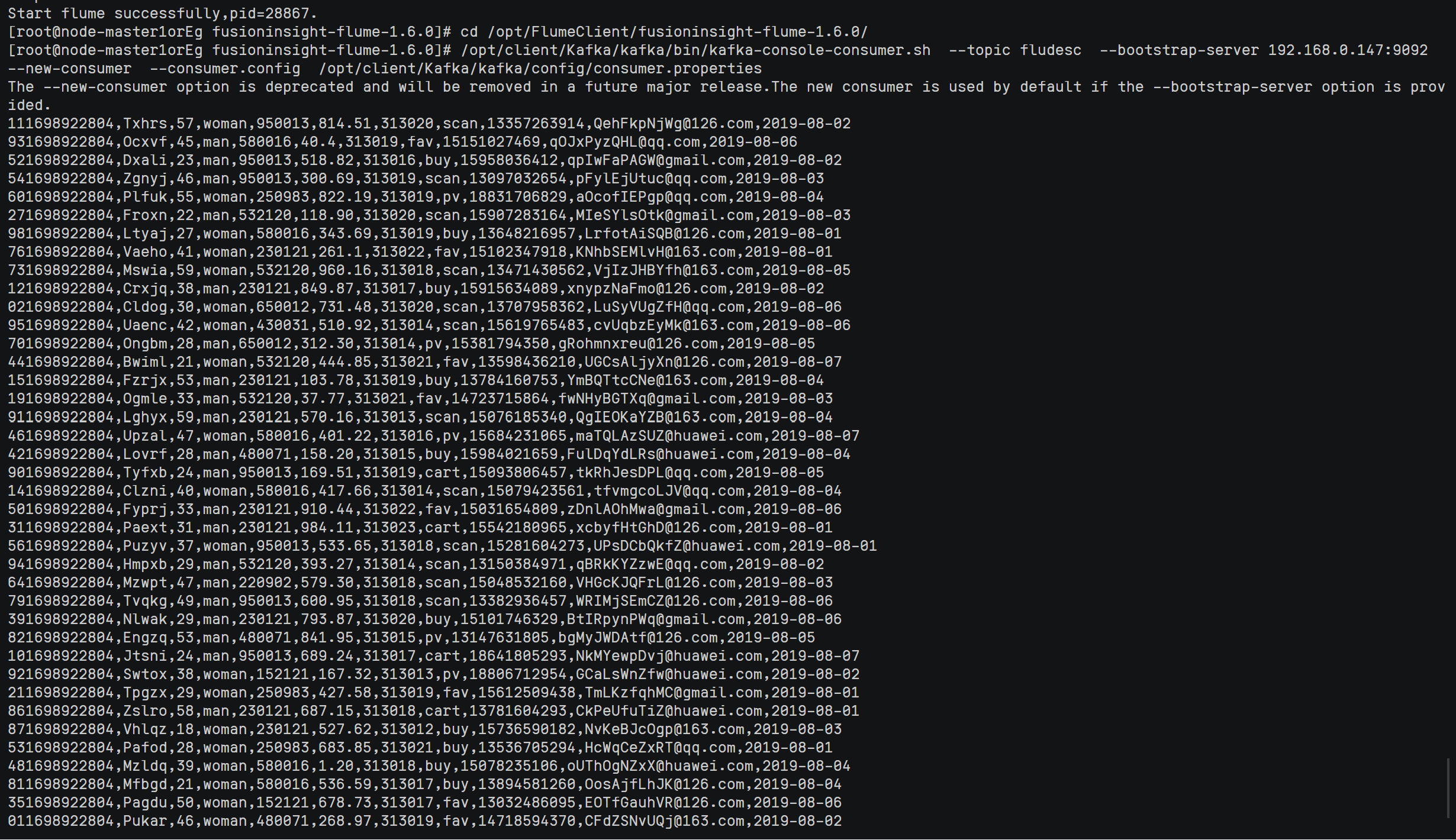
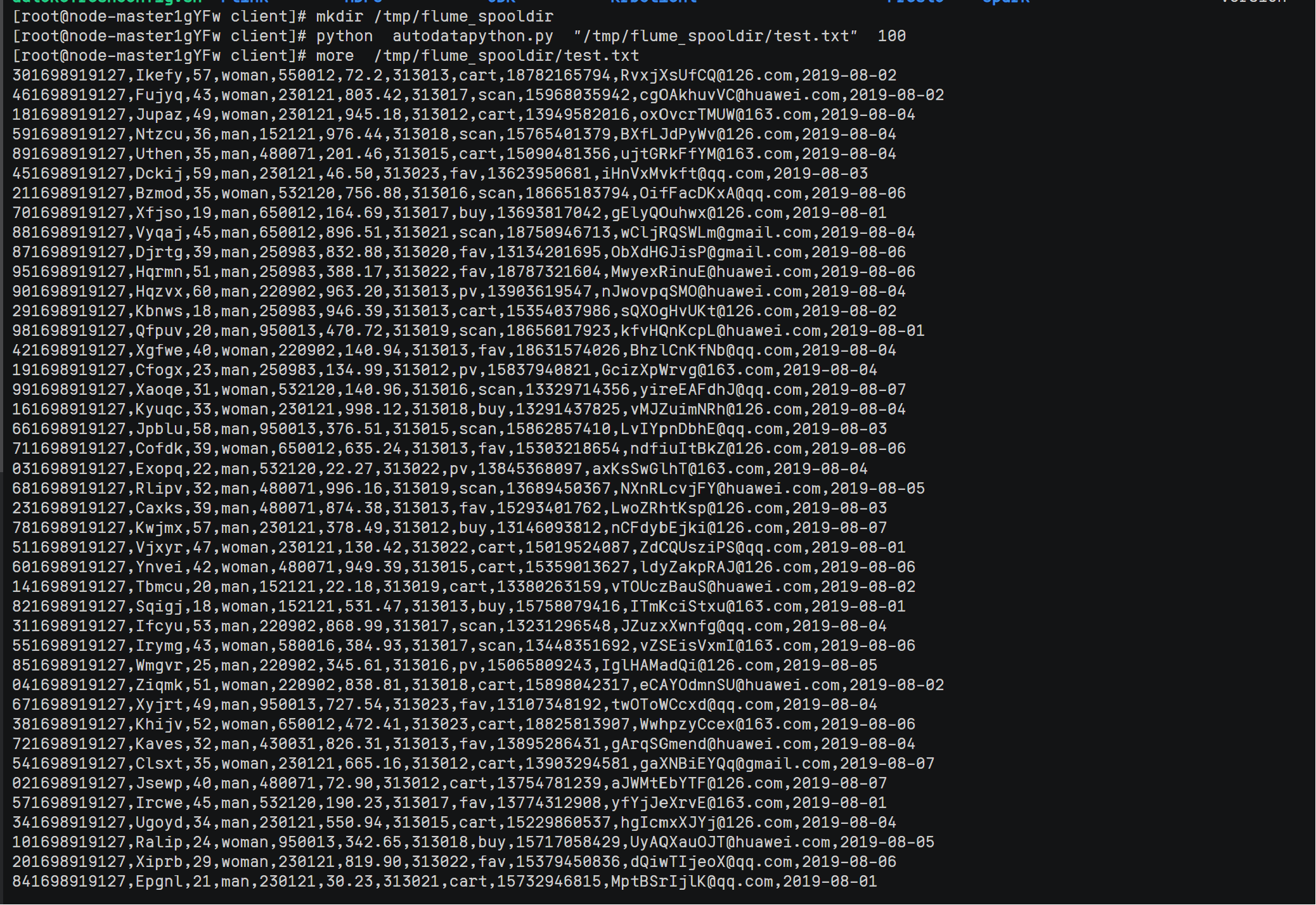
心得体会
第一次接触到华为云相关的资源,学习了华为云集群的部署和Flume1日志的使用。
