2023数据采集与融合技术实践作业三
作业①:
要求:
指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
输出信息:
将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
Gitee文件夹链接
关键代码
items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class pics(scrapy.Item):
url = scrapy.Field()
pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
class DemoPipeline:
def open_spider(self,spider):
self.conut = 0
def process_item(self, item, spider):
import requests
path = r"D:\大三上\数据采集与融合技术\实践3\images_1"
url = item['url']
resp = requests.get(url) # 获取指定图片的二进制文本
img = resp.content
with open(path + '\\image%d_' % (self.conut+1) + '.jpg', 'wb') as f:
f.write(img)
print("第%d张图片下载成功" % (self.conut+1))
self.conut += 1
mySpider.py
# This package will contain the spiders of your Scrapy project
#
# Please refer to the documentation for information on how to create and manage
# your spiders.
import scrapy
from items import pics
name = 'mySpider'
allowed_domains = ['p.weather.com.cn']
start_urls = ['http://p.weather.com.cn/tqxc/index.shtml']
def parse(self, response):
# 用XML文档构建Selector对象
data = response.body.decode()
selector = scrapy.Selector(text=data)
# 获取子网页链接
links = selector.xpath("//div[@class='oi']/div[@class ='tu']/a/@href")
srcs_str = []
for i in range(len(links)):
count = 0
link=links[i].extract()
yield scrapy.Request(url=link, callback=self.parse1)
def parse1(self,response):
# 用XML文档构建Selector对象
data = response.body.decode()
selector = scrapy.Selector(text=data)
# 获取图片路径
pics_url=selector.xpath("//li[@class='child']/a[@class='img_back']/img/@src")
for i in pics_url:
url=i.extract()
print(url)
item = pics()
item['url']=url
yield item
单线程
# 单线程保存图片到指定路径
path = r"D:\大三上\数据采集与融合技术\实践3\images_1"
cnt = 1
for url in srcs_str:
resp = requests.get(url) # 获取指定图片的二进制文本
img = resp.content
with open(path + '\\image%d_' % cnt + '.jpg', 'wb') as f:
f.write(img)
print("第%d张图片下载成功" % cnt)
if cnt == 149:
break
cnt += 1
多线程
try:
threads=[]
c=0
for i in range(22):
#构建soup对象
count = 0
pic_url = links[2 * i]["href"]
rp = requests.get(pic_url)
rp.encoding = 'utf-8'
do = rp.text
sp = BeautifulSoup(do, "lxml")
pics = sp.select('img[src$=".jpg"]')
for pic in pics:
print(pic["src"])
url=pic["src"]
count += 1
if count == 5:
break
# 新建下载线程下载图像
path = r"D:\大三上\数据采集与融合技术\实践3\images_2"
if c < 149:
t = threading.Thread(target=Download,args=(path,url,c))
t.setDaemon(False)
# 设置为前台进程
t.start()
threads.append(t)
c += 1
else:
break
for thread in threads:
thread.join()
except Exception as err:
print(err)
结果
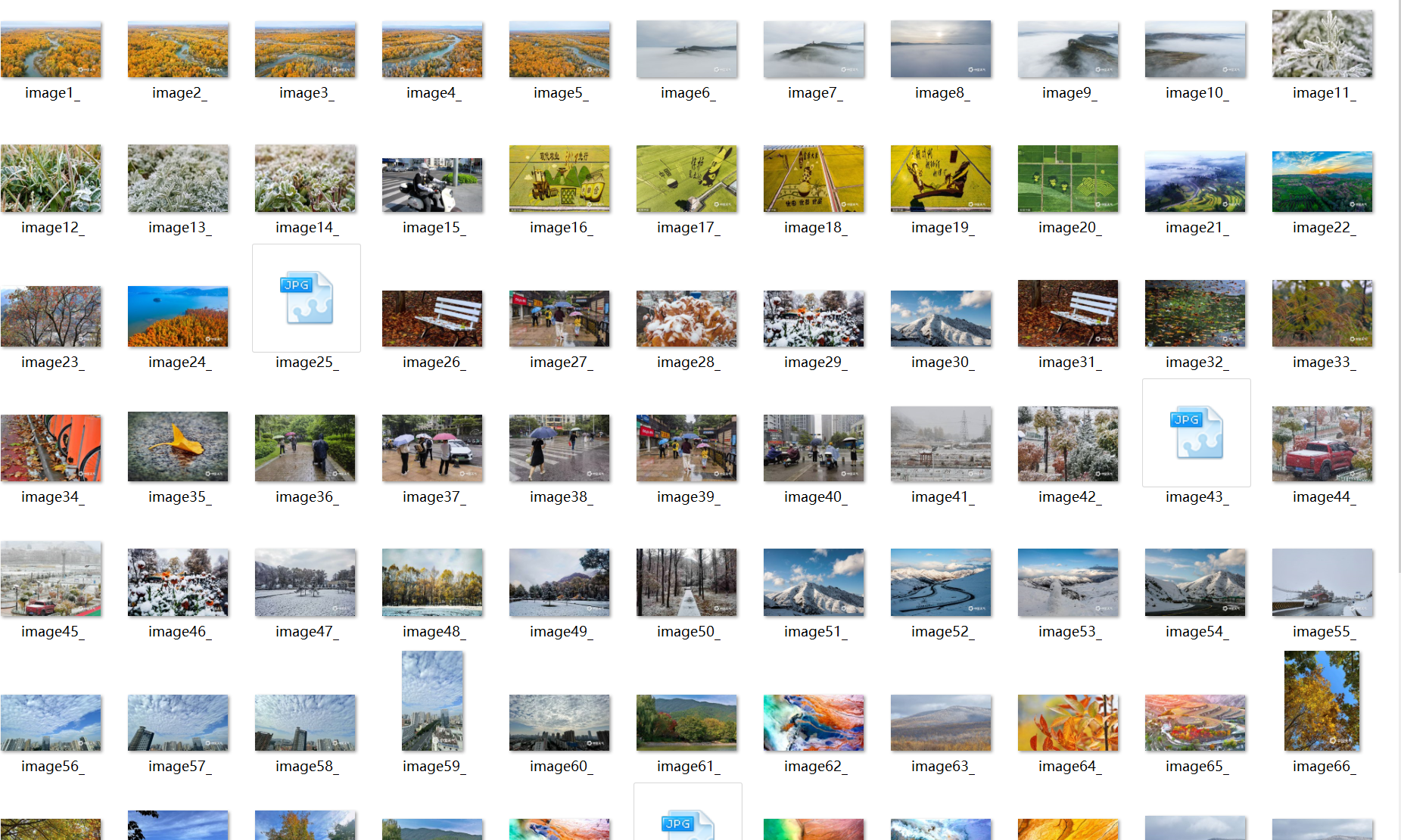
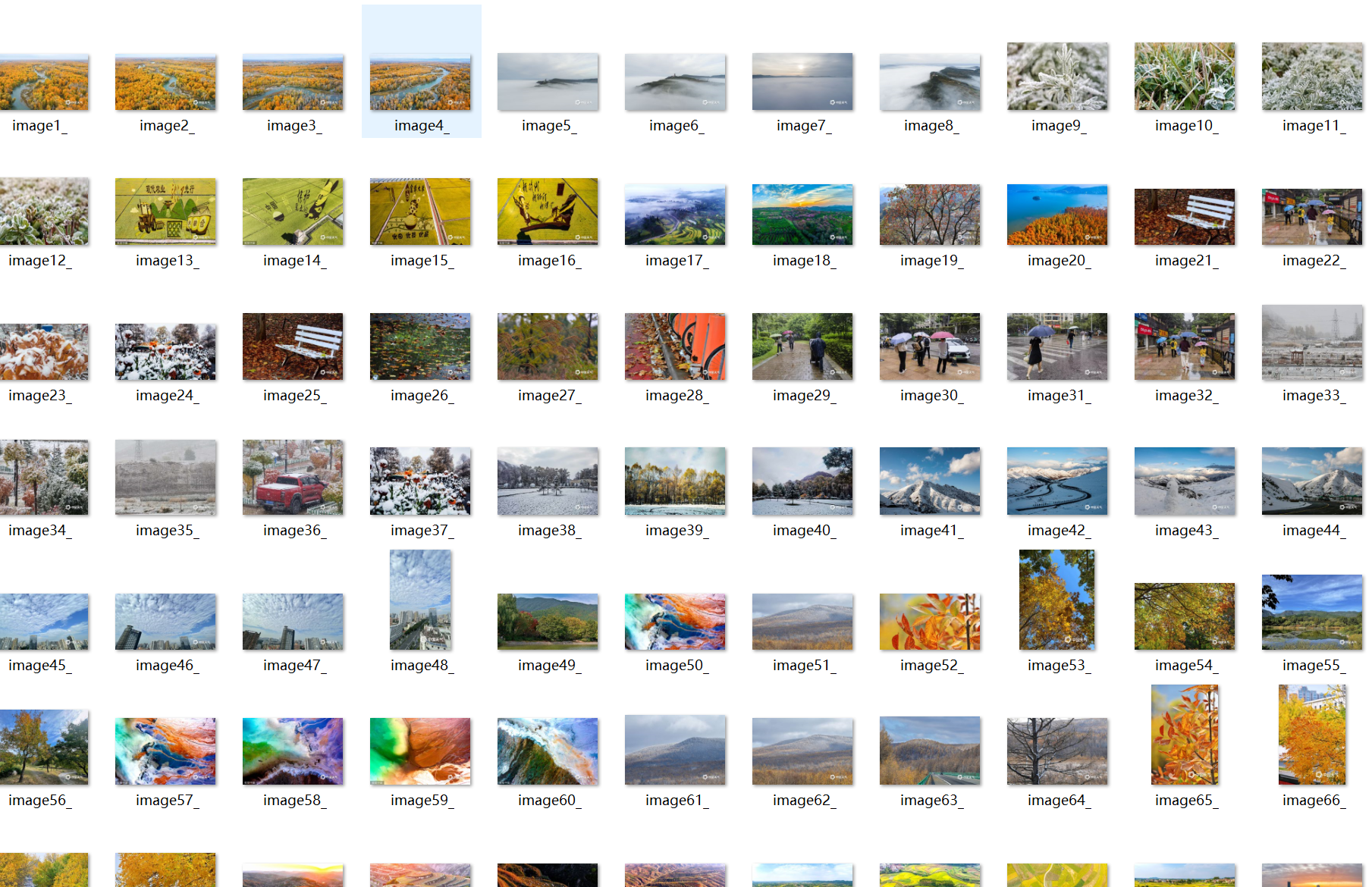
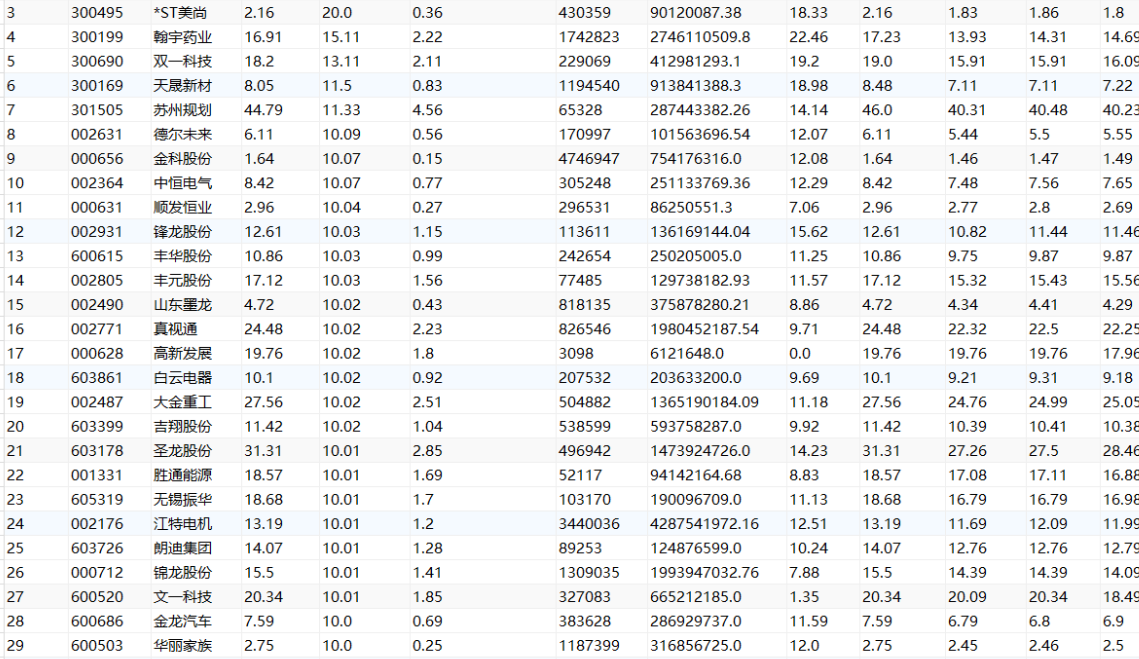
作业②
要求:
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
输出信息:
MySQL数据库存储和输出格式如下:
表头英文命名例如:序号id,股票代码:bStock
Gitee文件夹链接
关键代码
items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class GupiaoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Transaction_date = scrapy.Field() # 交易日期
Opening_price = scrapy.Field() # 开盘价
Number_of_transactions = scrapy.Field() # 成交数量
Closing_price = scrapy.Field() # 收盘价
minimum_price = scrapy.Field() # 最低价
Highest_price = scrapy.Field() # 最高价
Securities_code = scrapy.Field() # 证券代码
Securities_abbreviation = scrapy.Field() # 证券简称
pass
pipelines.py
class BaidustocksInfoPipeline(object):
def process_item(self, item, spider):
return item
class BaidustocksInfoPipeline(object):
# 当爬虫被调用时
def open_spider(self, spider):
self.f = open('gupiao.txt', 'w')
# 当爬虫关闭时
def close_spider(self, spider):
self.f.close()
# 对每一个item处理时
def process_item(self, item, spider):
try:
line = str(dict(item)) + '\n'
self.f.write(line)
except:
pass
return item
mySpider.py
import scrapy
import re
class StocksSpider(scrapy.Spider):
name = 'stocks'
start_urls = ['http://quote.eastmoney.com/stock_list.html']
def parse(self, response):
# 循环获取列表中a标签的链接信息
for href in response.css('a::attr(href)').extract():
try:
# 通过正则表达式获取链接中想要的信息
stock = re.findall(r"[s][hz]\d{6}", href)[0]
# 生成百度股票对应的链接信息
url = 'http://gu.qq.com/' + stock + '/gp'
# yield是生成器
# 将新的URL重新提交到scrapy框架
# callback给出了处理这个响应的处理函数为parse_stock
yield scrapy.Request(url, callback=self.parse_stock)
except:
continue
# 定义如何存百度的单个页面中提取信息的方法
def parse_stock(self, response):
# 因为每个页面返回 的是一个字典类型,所以定义一个空字典
infoDict = {}
stockName = response.css('.title_bg')
stockInfo = response.css('.col-2.fr')
name = stockName.css('.col-1-1').extract()[0]
code = stockName.css('.col-1-2').extract()[0]
info = stockInfo.css('li').extract()
# 将提取的信息保存到字典中
for i in info[:13]:
key = re.findall('>.*?<', i)[1][1:-1]
key = key.replace('\u2003', '')
key = key.replace('\xa0', '')
try:
val = re.findall('>.*?<', i)[3][1:-1]
except:
val = '--'
infoDict[key] = val
# 对股票的名称进行更新
infoDict.update({'股票名称': re.findall('\>.*\<', name)[0][1:-1] + \
re.findall('\>.*\<', code)[0][1:-1]})
yield infoDict
结果
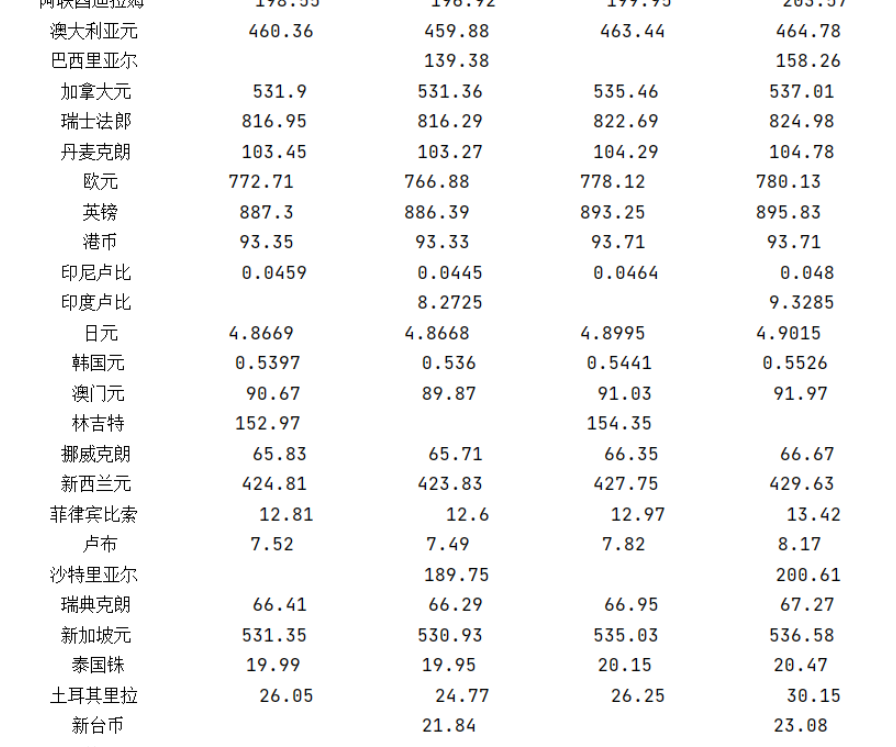
作业③:
要求:
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
Gitee文件夹链接
关键代码
items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class MoneyItem(scrapy.Item):
Currency = scrapy.Field()
TBP = scrapy.Field()
CBP = scrapy.Field()
TSP = scrapy.Field()
CSP = scrapy.Field()
Time = scrapy.Field()
pipelines.py
# Define your ite
import sqlite3
import requests
class MoneyDB:
def openDB(self):
self.con = sqlite3.connect("movies.db") #建立数据库链接,若没有对应数据库则创建
self.cursor = self.con.cursor() #建立游标
try:
self.cursor.execute("create table money "
"(mSeq int(4),mName varchar(16),"
"mDirector varchar(32),mActors varchar(64),"
"mQuote varchar(32),mScore varchar(8),mDyfm varchar(64))")
except:
self.cursor.execute("delete from movies")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, mSeq, mName, mDirector, mActors, mQuote, mScore, mDyfm):
try:
self.cursor.execute("insert into movies (mSeq,mName,mDirector,mActors,mQuote,mScore,mDyfm) values (?,?,?,?,?,?,?)",
(mSeq, mName, mDirector, mActors, mQuote, mScore, mDyfm))
except Exception as err:
print(err)
class Demo2Pipeline:
def open_spider(self,spider):
print("开始爬取")
self.count = 1
self.db = MoneyDB()
self.db.openDB()
def process_item(self, item, spider):
#下载图片
path=r"D:\大三上\数据采集与融合技术\实践3"
url = item['dyfm']
resp = requests.get(url) # 获取指定图片的二进制文本
img = resp.content
fm_path='imgs\image%d_' % self.count + '.jpg'
with open(path + '\\image%d_' % self.count + '.jpg', 'wb') as f:
f.write(img)
print("第%d张图片下载成功" % self.count)
self.count += 1
#保存到数据库
self.db.insert(item['seq'],item['name'],item['director'],item['actors'],item['quote'],item['score'],fm_path)
return item
def close_spider(self, spider):
self.db.closeDB()
print("结束爬取")
mySpider.py
import re
import scrapy
import main_items3
name = 'mySpider'
allowed_domains = ['boc.cn/sourcedb/whpj']
url = 'https://www.boc.cn/sourcedb/whpj/'
start_urls = []
for i in range(10):
if i == 0:
start_urls.append(url)
else:
start_urls.append(url+"?start="+str(i * 25))
def parse(self, response):
print(self.start_urls)
data = response.body.decode()
selector = scrapy.Selector(text=data)
print(selector)
moneys = selector.xpath('//div[@id="content"]//li')
cnt = 1
for money in moneys:
item = main_items3.MoneyItem()
item['Currency']=cnt
item['TBP'] = money.xpath('./div/div[@class="pic"]/a[@href]/img/@alt').extract_first()
text = money.xpath('./div/div[@class="info"]/div[@class="bd"]/p[@class]/text()').extract_first()
text = text.strip().replace('\xa0\xa0\xa0','')
item['CBP'] = re.split(r': |: ',text)[1]
item['TSP'] = re.split(r': |: ',text)[2]
item['CSP'] = money.xpath('./div/div[@class="info"]/div[@class="bd"]/p[@class="quote"]/span/text()').extract_first()
# item['score'] = money.xpath('./div/div[@class="info"]/div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()').extract_first()
item['Time'] = money.xpath('./div/div[@class="pic"]/a[@href]/img/@src').extract_first()
yield item
结果