


2023数据采集与融合技术实践二
作业①:
要求:
在中国气象网(http://www.weather.com.cn)给定城市集的 7日天气预报,并保存在数据库。
输出信息:
序号 地区 日期 天气信息 温度
1 北京 7日(今天) 晴间多云,北部山区有阵雨或雷阵雨转晴转多云 31℃/17℃
2 北京 8日(明天) 多云转晴,北部地区有分散阵雨或雷阵雨转晴 34℃/20℃
3 北京 9日(后台) 晴转多云 36℃/22℃
4 北京 10日(周六) 阴转阵雨 30℃/19℃
5 北京 11日(周日) 阵雨 27℃/18℃
6......
Gitee文件夹链接
代码
import requests
from bs4 import BeautifulSoup
import openpyxl
# 设置要保存的Excel文件名
filename = "7_day_weather.xlsx"
# 打开Excel文件,设置活动工作表为第一个工作表
wb = openpyxl.Workbook()
sheet = wb.active
# 设置要爬取的网页URL
url = "http://www.weather.com.cn/weather/101290101.html"
# 发送GET请求获取网页内容
response = requests.get(url)
# 使用BeautifulSoup解析网页内容
soup = BeautifulSoup(response.text, "html.parser")
# 在此我们假设天气预报在表格中,故选择表格标签
table = soup.find("table", {"class": "forecast-table"})
# 获取表格行数以及要爬取的行数(这里是7,即7天的天气预报)
num_rows = len(table.find_all("tr")) - 1 # 表格第一行是标题,所以减1
to_scrape = min(60, num_rows) # 如果表格行数小于60,则爬取所有行
# 设置Excel表头(第一行)
header = ["日期", "天气", "温度", "风力"]
sheet.append(header)
# 循环爬取并保存7天的天气预报
for i in range(1, to_scrape + 1):
row = table.find("tr", {"class": "forecast-climate"}) # 假设每行的样式为"forecast-climate"
for j in range(len(row.find_all("td"))): # 遍历表格中的每个单元格
cell = row.find_all("td")[j] # 获取当前单元格
if j == 0: # 日期
date = cell.text.strip()
elif j == 1: # 天气状况
weather = cell.text.strip()
elif j == 2: # 温度
temp = cell.text.strip()
elif j == 3: # 风力
wind = cell.text.strip()
sheet.append([date, weather, temp, wind]) # 将获取到的数据添加到Excel表中
# 保存Excel文件
wb.save(filename)
结果
心得体会
这次作业不同的是需要将结果传到数据库,在配置好mysql后,成功解决。
作业②:
要求:
用 requests 和 BeautifulSoup 库方法定向爬取股票相关信息,并存储在数据库中。
候选网站:
东方财富网:https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/
技巧:在谷歌浏览器中进入 F12 调试模式进行抓包,查找股票列表加载使用的 url,并分析 api 返回的值,并根据所要求的参数可适当更改api 的请求参数。根据 URL 可观察请求的参数 f1、f2 可获取不同的数值,根据情况可删减请求的参数。参考链接:https://zhuanlan.zhihu.com/p/50099084
Gitee文件夹链接
代码
import math
import requests
import json
import db
import time
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36"
}
def save_data(data):
# "股票代码,股票名称,最新价,涨跌幅,涨跌额,成交量(手),成交额,振幅,换手率,市盈率,量比,最高,最低,今开,昨收,市净率"
for i in data:
Code = i["f12"]
Name = i["f14"]
Close = i['f2'] if i["f2"] != "-" else None
ChangePercent = i["f3"] if i["f3"] != "-" else None
Change = i['f4'] if i["f4"] != "-" else None
Volume = i['f5'] if i["f5"] != "-" else None
Amount = i['f6'] if i["f6"] != "-" else None
Amplitude = i['f7'] if i["f7"] != "-" else None
TurnoverRate = i['f8'] if i["f8"] != "-" else None
PERation = i['f9'] if i["f9"] != "-" else None
VolumeRate = i['f10'] if i["f10"] != "-" else None
Hign = i['f15'] if i["f15"] != "-" else None
Low = i['f16'] if i["f16"] != "-" else None
Open = i['f17'] if i["f17"] != "-" else None
PreviousClose = i['f18'] if i["f18"] != "-" else None
PB = i['f23'] if i["f23"] != "-" else None
insert_sql =
insert t_stock_code_price(code, name, close, change_percent, `change`, volume, amount, amplitude, turnover_rate, peration, volume_rate, hign, low, open, previous_close, pb, create_time)
values (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
val = (Code, Name, Close, ChangePercent, Change, Volume, Amount, Amplitude,
TurnoverRate, PERation, VolumeRate, Hign, Low, Open, PreviousClose, PB, datetime.datetime.now().strftime('%F'))
db.insert_or_update_data(insert_sql, val)
print(Code, Name, Close, ChangePercent, Change, Volume, Amount, Amplitude,
TurnoverRate, PERation, VolumeRate, Hign, Low, Open, PreviousClose, PB)
def craw_data():
stock_data = []
json_url1 = "http://72.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112406903204148811937_1678420818118&pn=%s&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1678420818127" % str(
1)
res1 = requests.get(json_url1, headers=headers)
result1 = res1.text.split("jQuery112406903204148811937_1678420818118")[1].split("(")[1].split(");")[0]
result_json1 = json.loads(result1)
total_value = result_json1['data']['total']
maxn = math.ceil(total_value / 20)
for i in range(1, maxn + 1):
json_url = "http://72.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112406903204148811937_1678420818118&pn=%s&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1678420818127" % str(
i)
res = requests.get(json_url, headers=headers)
result = res.text.split("jQuery112406903204148811937_1678420818118")[1].split("(")[1].split(");")[0]
result_json = json.loads(result)
stock_data.extend(result_json['data']['diff'])
time.sleep(10)
return stock_data
def main():
stock_data = craw_data()
save_data(stock_data)
if __name__ == "__main__":
main()
结果

心得体会
首次用f12功能调试,通过此次作业也学会了一种新的爬虫方法。
作业③:
要求:
,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
技巧:分析该网站的发包情况,分析获取数据的api
Gitee文件夹链接
内容
import bs4
import pandas as pd
import mysql.connector
def main():
uinfo = []
url = 'https://www.shanghairanking.cn/_nuxt/static/1695811954/rankings/bcur/2021/payload.js'
header = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"
}
resp = requests.get(url, headers=header)
resp.raise_for_status()
resp.encoding = resp.apparent_encoding
html = resp.text
rname = 'univNameCn:"(.*?)"'
rscore = 'score:(.*?),'
rprovince = 'province:(.*?),'
runivCategory = 'univCategory:(.*?),'
namelist = re.findall(rname, html, re.S | re.M)
scorelist = re.findall(rscore, html, re.S | re.M)
provincelist = re.findall(rprovince, html, re.S | re.M)
univCategorylist = re.findall(runivCategory, html, re.S | re.M)
try:
res = requests.get(url)
res.raise_for_status()
res.encoding = res.apparent_encoding
html = res.text
except Exception as err:
print(err)
try:
req = urllib.request.Request(url)
html = urllib.request.urlopen(req).read.decode()
except Exception as err:
print(err)
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
a = tr('a')
tds = tr('td')
uinfo.append([tds[0].text.strip(), a[0].string.strip(), tds[2].text.strip(), tds[3].text.strip(),
tds[4].text.strip()])
tplt = "{0:^10}\t{1:^10}\t{2:^12}\t{3:^12}\t{4:^10}"
print(tplt.format("排名", "学校名称", "省份", "学校类型", "总分"))
df = pd.DataFrame(uinfo, columns=["排名", "学校名称", "省份", "学校类型", "总分"])
df.to_excel("rank.csv", index=False)
# 连接到MySQL数据库
mydb = mysql.connector.connect(
host="",
user="",
password="",
database=""
)
# 创建一个游标对象
mycursor = mydb.cursor()
# 定义SQL语句,将数据插入到数据库中
sql = "INSERT INTO university_ranking (rank, university, province, type, score) VALUES (%s, %s, %s, %s, %s)"
# 将提取的数据插入到数据库中
for row in data:
# 将文本类型的数据转换成整数类型
rank = int(row[0])
score = int(row[4])
# 执行SQL语句并提交到数据库
mycursor.execute(sql, (rank, row[1], row[2], row[3], score))
mydb.commit()
print(f"Inserted {rank} - {row[1]} - {row[2]} - {row[3]} - {score}")
if __name__ == '__main__':
main()
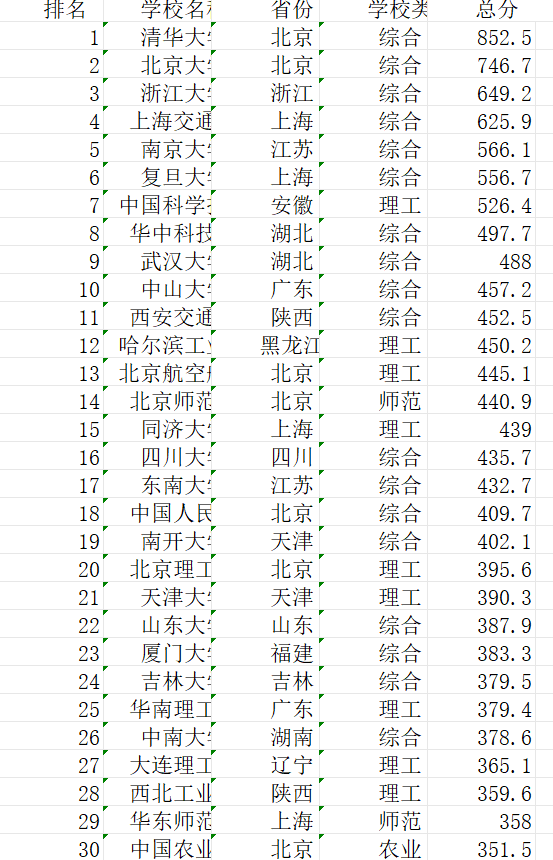
结果
心得体会
通过对网页f12的调试找到url,最终将数据库的数据输出到excel中。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具