《MySQL慢查询优化》之索引原理
1、前言
-
什么是索引?
在关系型数据库中(RDBMS),索引是种独立的对数据库表中的一列或多列的值进行排序的一种数据结构。索引类似于书籍的目录,可以根据目录中的页码(地址)快速查找书籍某页内容(数据)。
因此,索引是创建在列上的数据结构,是帮助MySQL高效获取数据的数据结构。在RDBMS(Relational Database Management System)中,索引存储在硬盘中。
-
什么是理想索引?
- 查询频繁
- 长度较小
- 区分度高
- 尽量能覆盖高频率查询字段
-
MySQL索引有哪些数据结构?
在MySQL中,主要有四种数据结构的索引,分别为: B-Tree 索引, Hash 索引, Fulltext 索引和 R-Tree 索引。其中,常见为HASH索引和BTREE索引。索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式是不同的,其中MyISAM和InnoDB两个存储引擎的索引默认实现方式均为BTREE索引,MEMORY默认使用哈希索引。
HASH索引顾名思义是由哈希算法实现,该索引存放在内存中,Hash冲突解决繁琐,并且对范围查询支持不友好,优点在于内存处理速度快。MySQL存储引擎MEMORY天然支持HASH索引(MEMORY是MySQL中一类特殊的存储引擎。它使用存储在内存中的内容来创建表,而且数据全部存储在内存中。),哈希索引查询速度比使用BTREE索引快。MySQL存储引擎InnoDB不能手动创建HASH索引,只能支持自适应HASH。
BTREE索引是由B+树数据结构实现。高版本的MySQL默认存储引擎为InnoDB,本文主要讨论InnoDB和MyISAM两种存储引擎的BTREE索引。
注意:
- 合理的建立索引能够加速数据读取效率,不合理的建立索引反而会拖慢数据库的响应速度。
- 索引越多,更新数据的速度越慢。
2、BTREE索引
-
B-Tree
B-Tree又称多路搜索树、多叉平衡查找树,解决了平衡二叉查找树(AVL树)的树高等缺陷,降低I/O成本。
数据结构:
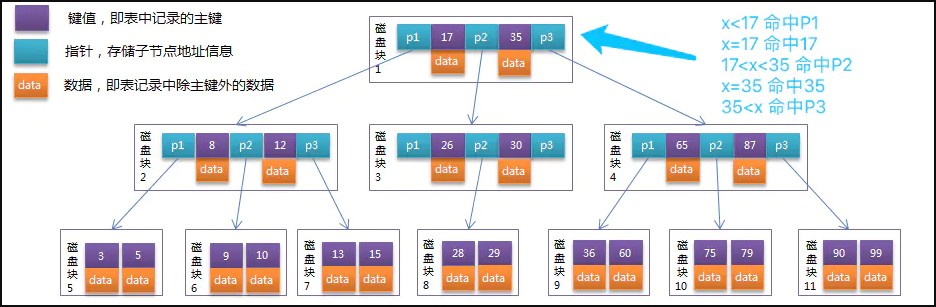
一棵m阶的B-Tree有如下特性:
。树中每个结点最多含有m个孩子(m>=2);
。除根结点和叶子结点外,其它每个结点至少有[ceil(m / 2)]个孩子(其中ceil(x)是一个取上限的函数);
。若根结点不是叶子结点,则至少有2个孩子;
。所有叶子结点都出现在同一层,叶子结点不包含任何关键字信息;
。每个非终端结点中包含有n个关键字信息: (P1,K1,P2,K2,P3,......,Kn,Pn+1)。其中:
a) Ki (i=1...n)为关键字,且关键字按顺序升序排序K(i-1)< Ki。
b) Pi为指向子树根的接点,且指针P(i)指向子树种所有结点的关键字均小于Ki,但都大于K(i-1)。
c) 关键字的个数n必须满足: [ceil(m / 2)-1]<= n <= m-1。
B树主要应用于文件系统以及部分数据库索引,如MongoDB。
-
B+Tree
B+Tree是在B-Tree基础上的一种优化,大部分关系型数据库主要索引都是使用B+树实现。
数据结构:
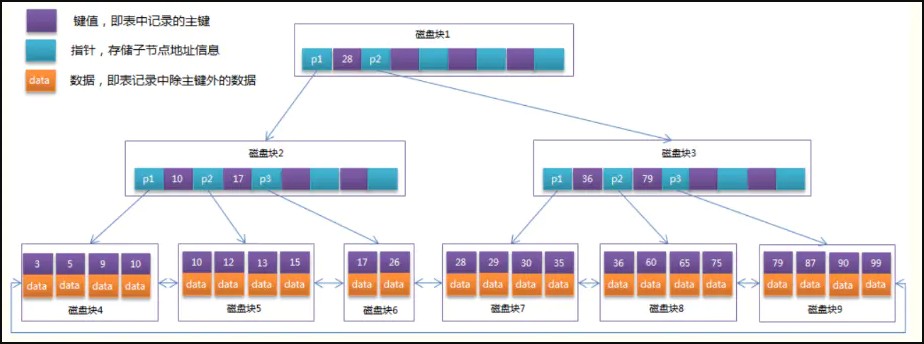
B+Tree相比于B-Tree特点:
。B+节点关键字搜索采用闭合区间。
。B+非叶节点不保存数据相关信息,只保存关键字和子节点的引用。
。B+关键字对应的数据保存在叶子节点中。(B+tree的叶子节点要存储所有的key-value)
。B+叶子节点是顺序排列的,所有叶子节点通过链指针连接,形成循环双向链表。因此,B+树友好支持范围查询。
B+Tree优点:
。B+树是B-树的变种(优化版),他拥有B-树的优势。(自平衡、树高低,I/O少)
。B+树扫库扫表能力更强。(叶子节点存放所有数据,并且是双向链表数据结构)
。B+树的磁盘读写能力更强。(非叶子节点不存放数据,磁盘块存放更多的索引信息,I/O更少)
。B+树的排序能力更强。(叶子节点顺序排列)
。B+树的查询效率更加稳定,I/O更加稳定。(数据都在叶子节点命中)
-
BTREE索引
在MySQL中,索引属于存储引擎级别的概念。其中,InnoDB和MyISAM两种存储引擎的大部分索引均采用B+Tree,但是具体实现细节截然不同。
MyISAM
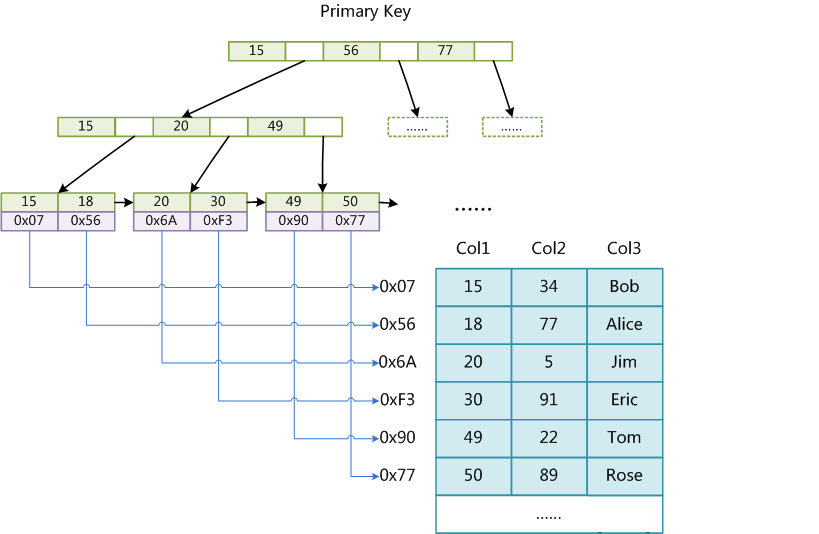
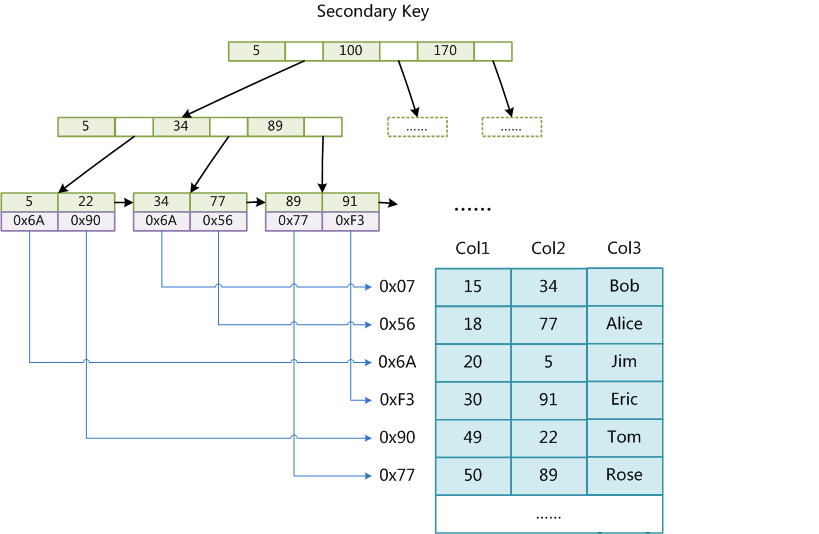
MyISAM引擎使用B+Tree作为索引结构,叶子节点的data域存储数据记录的地址,因此,MyISAM的索引文件仅仅保存数据记录的地址,MyISAM索引也归类为“非聚集”索引(索引文件和数据文件分离)。主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的(主键特质),而辅助索引的key可以重复。
主键索引(Primary key):(Col1为主键列)
辅助索引(Secondary key):(Col2为辅助索引列)
InnoDB
InnoDB索引属于聚簇型索引,也就是说索引和数据存放一起。InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),相比于MyISAM,有两大区别:
<1> 主键索引,InnoDB表数据文件本身就是主索引。换句话说,InnoDB表数据文件本身就是按B+Tree组织的主键索引文件,这棵树的叶节点data域保存了完整的数据记录,索引树的key是数据表的主键。
<2> 辅助索引(包括单列索引、联合索引),InnoDB辅助索引的data域存储相应数据记录的主键值而不是地址。换句话说,InnoDB的所有辅助索引都引用主键作为data域(辅助列+主键值)。采用辅助索引查询完整数据记录,必须先检索辅助索引获取记录主键,再回表检索主键索引获取数据记录。
主键索引(Primary key):(Col1为主键列)
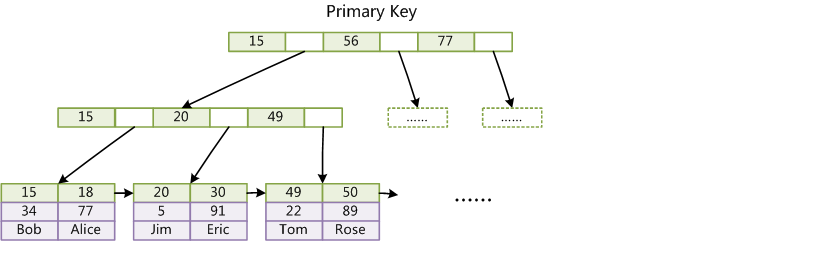
辅助索引(Secondary key):(Col2为辅助索引列)
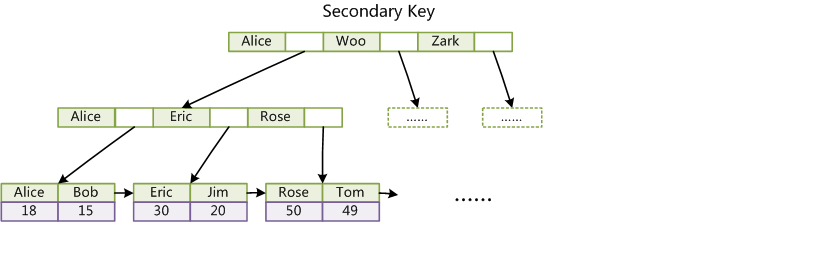
通过辅助索引检索完整记录数据流程:(回表操作)
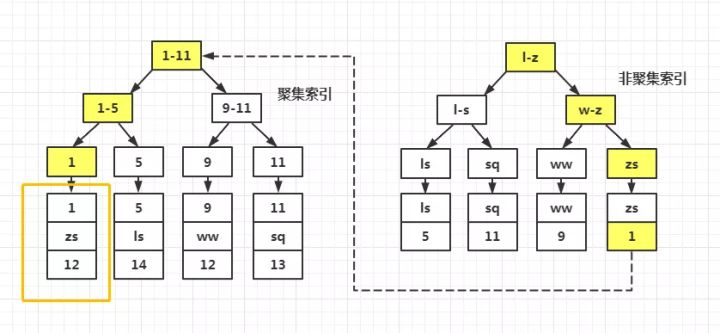
掌握了InnoDB的索引实现后,就很容易明白为什么不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。另外,优先考虑自增主键。因为InnoDB数据文件本身是一颗B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。
3、覆盖索引
-
定义
SQL执行只需通过检索索引树就能返回查询所需要的记录数据,而不必先通过检索辅助索引获取记录主键值,再去主键索引树检索完整记录数据(回表操作)。覆盖索引是SQL优化推崇的最优策略之一,实际上就是根据InnoDB索引实现原理,最优化使用索引。
由于辅助索引存储的数据比聚集索引少很多,大部分情况下,会落在内存中,聚集索引很可能数据在磁盘中,通过辅助索引进行覆盖索引,都不需要读磁盘,直接从内存取,这种情况下,一种是内存读,一种是磁盘读,速度差异很显著,几乎是数量级的差异。
本人另一篇博文《MySQL慢查询优化》之SQL语句及索引优化,对SQL优化以及索引策略详细进行介绍,现采用其中的一条SQL进行示例。
测试数据表:
show index from employees;

辅助索引:idx_empno_birthdate_gender(emp_no,birth_date,gender)(联合索引)。
EG:
EXPLAIN SELECT emp_no,birth_date,gender FROM employees WHERE gender ='M' ;

Using index:表示已经使用了覆盖索引。
4、联合索引
-
定义
联合索引又称复合索引,归类于辅助索引,是由表中若干列组合而成,类似于书籍的多级目录结构,遵循“最左前缀原则”。
InnoDB引擎中,根据辅助索引实现原理,叶子节点存放联合索引列(多列)和主键列数值,非叶子节点存储所有索引列数值,而不仅仅是索引第一列。
优化建议:建立联合索引时,通常区分度高的字段放在最前面。
示例:index(a,b,c)
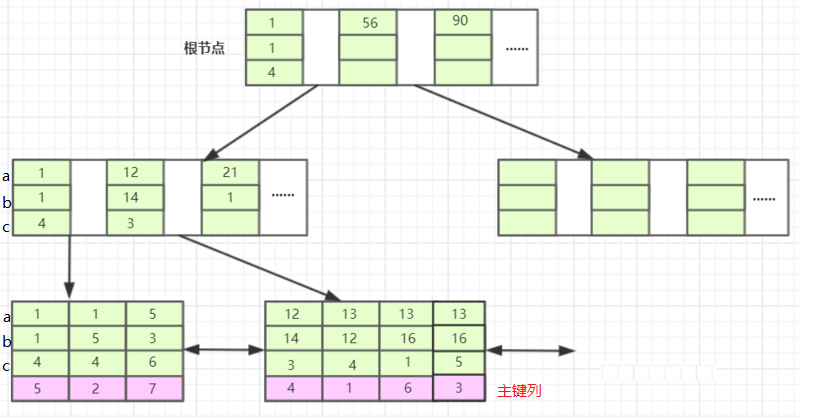
检索顺序:按照最左原则,从左列开始逐步向右列检索判断。
建议:联合索引一般不超过3个字段。
-
优势
。降低开销:创建一个多列的联合索引,相当于创建了多个子索引。
。覆盖索引:提供了覆盖索引的可能性。
。效率高效:检索过滤条件多,一次性筛选出更少的数据记录,避免不必要的回表、分页、排序等操作。
5、索引分类
MySQL目前根据使用场景,主要有以下几种索引类型:
- 普通索引
- 唯一索引
- 主键索引
- 组合索引
- 全文索引
另外,聚簇性索引(InnoDB索引)和非聚簇性索引(MyISAM索引)是根据索引实现原理分类。
6、索引操作
常用的索引操作:
| 索引操作 | DDL语句 |
| 创建 |
其中,length可以不指定,直接写列名。 修改表方式:ALERT TABLE table_name ADD INDEX (UNIQUE INDEX)... |
| 删除 | DROP INDEX index_name ON table_name; |
| 查看 | SHOW INDEX FROM table_name; |
建议:索引应该建在小字段上,大的数据字段(bit,image,text)不适用。
结束语
目前,本人并不是理论原理的创造者,只是通过相关书籍以及网络知识的学习,并结合自身的掌握与工作实践,整理编写了本文,希望能为更多的人提供帮助,文章中部分原理图来源于网络。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号