《MySQL慢查询优化》之SQL语句及索引优化
1、慢查询优化方式
-
服务器硬件升级优化
-
Mysql服务器软件优化
-
数据库表结构优化
-
SQL语句及索引优化
本文重点关注于SQL语句及索引优化,关于其他优化方式以及索引原理等,请关注本人《MySQL慢查询优化》系列博文。优化我个人遵循的原则:积小胜为大胜,以空间换时间。-《论持久战》
2、数据源
工欲善其事必先利其器,为了测试与验证的方便,数据库可以直接采用MySQL官方提供的测试数据库employees,该数据库关系复杂度适中以及数据量较大,适合做SQL语句及索引优化分析,引用官方instruction:
The database contains about 300,000 employee records with 2.8 million salary entries.
The export data is 167 MB, which is not huge, but heavy enough to be non-trivial for testing.
- 数据库获取方式:https://github.com/gavincoder/test_db
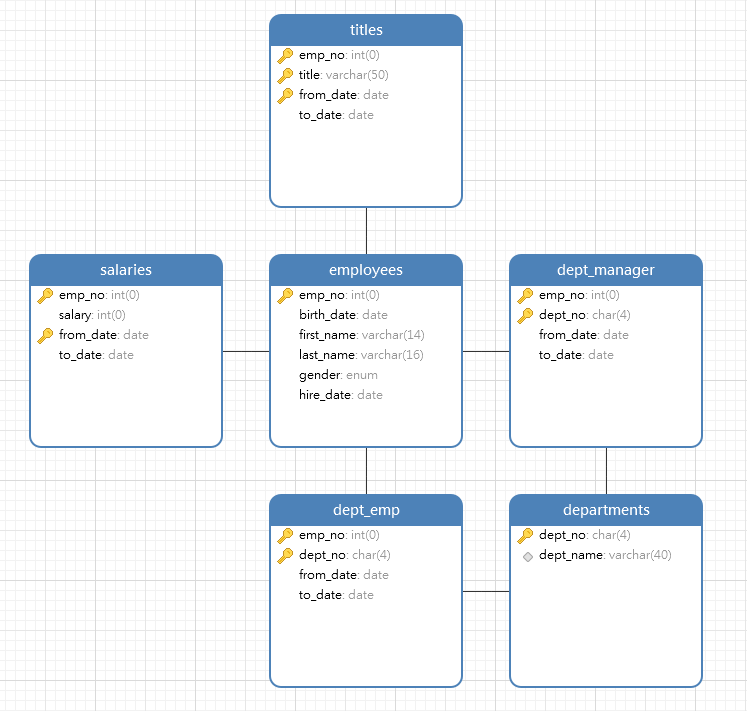
- 数据库E-R关系图:
3、分析工具
常用命令:
- explain命令
查看SQL执行计划。
-
show WARNINGS;
查看MySQL自行优化后,最终执行的SQL。
- profiling命令
查看SQL执行过程中的cpu/io/swap/memory等使用情况(定位性能瓶颈)以及每个过程执行时间消耗。(mysql可以通过profiling命令查看执行查询SQL消耗的时间)
explain命令
采用explain指令直接模拟Mysql优化器执行SQL语句,查看SQL语句的执行计划。
示例:
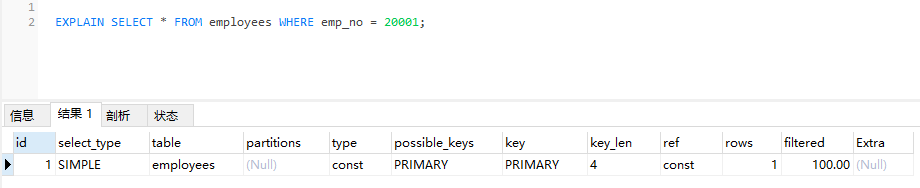
explain命令执行结果包括若干参数:id、select_type、table、type、possible_keys、key、key_len、ref、rows、Extra;重点关注type、possible_keys、key、key_len、extra 这五个参数。
- possible_keys:此次查询中可能会被选用的索引,注意这些索引不一定被查询使用到。
- key:此次查询中真正使用到的索引。当为复合索引时,不确定是否被充分使用。
- type:访问类型,表示MySQL在表中查找所需行的方式。常用的类型有: ALL, index, range, ref, eq_ref, const, system, NULL(性能从左到右逐步提升),其中:
| ALL | Full Table Scan, MySQL将遍历全表以找到匹配的行; |
| index | Full Index Scan,index与ALL区别为index类型只遍历索引树; |
| range | 只检索给定范围的行,使用一个索引来选择行; |
| ref | 表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值; |
| eq_ref | 类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,就是多表连接中使用primary key或者 unique key作为关联条件; |
|
const system |
当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于where列表中,MySQL就能将该查询转换为一个常量,system是const类型的特例,当查询的表只有一行的情况下,使用system; |
| NULL | MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成。 |
- key_len:表示索引中使用的字节数,用来计算索引是否被充分使用,不损失精确性的情况下,长度越短越好 ;
| key_len=字符长度*字节数+类型+是否允许为空 | ||||||
| 索引是否充分使用:复合索引每个列都需要计算,所有索引列都生效了才是充分利用。 | ||||||
|
计算规则: 。字节数相关:长度、字符编码、类型(int+0,char+0,varchar+2)、是否允许为空(空+1,非空+0); 。int类型字节数为4; 。char和varchar的长度是指字符数,一个字符在编码gbk为2个字节、utf-8为3个字节,需要:字符数*字节。 |
||||||
|
示例:
|
- extra:
| Using where说明:SQL使用了where条件过滤数据; |
| Using index说明:表示已经使用了覆盖索引。SQL所需要返回的所有列数据均在一棵索引树上,而无需访问实际的行记录。(聚簇型索引,innodb的主键索引) |
- REF列
表示哪些列或常量被用于查找索引列上的值
- ROWS列
表示MySQL通过索引统计信息,估算的所需读取的行数
ROWS值的大小是个统计抽样结果,并不十分准确
- FILTERED列
表示返回结果的行数占需读取行数的百分比
FILTERED列的值越大越好
依赖于统计信息
小结:
| 字段 | 含义 |
|---|---|
| id | select查询的***,是一组数字,表示的是查询中执行select子句或者是操作表的顺序。 |
| select_type | 表示 SELECT 的类型,常见的取值有 SIMPLE(简单表,即不使用表连接或者子查询)、PRIMARY(主查询,即外层的查询)、UNION(UNION 中的第二个或者后面的查询语句)、SUBQUERY(子查询中的第一个 SELECT)等 |
| table | 输出结果集的表 |
| type | 表示表的连接类型,性能由好到差的连接类型为( system —> const -----> eq_ref ------> ref-------> ref_or_null----> index_merge —> index_subquery -----> range -----> index ------>all ) |
| possible_keys | 表示查询时,可能使用的索引 |
| key | 表示实际使用的索引 |
| key_len | 索引字段的长度 |
| rows | 扫描行的数量 |
| extra | 执行情况的说明和描述 |
4、索引策略
索引策略是指创建使用索引所要遵循的规则,换句话说,违背了这些规则会导致索引失效或者查询效率降低。
| 策略1:尽量考虑覆盖索引 |
| 策略2:遵循最左前缀匹配 |
| 策略3:范围查询字段放最后 |
| 策略4:不对索引字段进行逻辑操作 |
| 策略5:尽量全值匹配 |
| 策略6:Like查询,左侧尽量不要加% |
| 策略7:注意null/not null 可能对索引有影响 |
| 策略8:尽量减少使用不等于 |
| 策略9:字符类型务必加上引号 |
| 策略10:OR关键字左右尽量都为索引列 |
测试数据表:
show index from employees;

策略1:尽量考虑覆盖索引
覆盖索引:SQL只需要通过遍历索引树就可以返回所需要查询的数据,而不必通过辅助索引查到主键值之后再去查询数据(回表操作)。回表操作的详细介绍可以参考本人《MySQL慢查询优化》系列博文之索引。
EG:
EXPLAIN SELECT emp_no,birth_date,gender FROM employees WHERE gender ='M' ;

Using index:表示已经使用了覆盖索引。
策略2:遵循最左前缀匹配
联合索引命中必须遵循“最左前缀法则”。即SQL查询Where条件字段必须从索引的最左前列开始匹配,不能跳过索引中的列。联合索引又称复合索引,类似于书籍的目录,多级的目录结构中子目录依赖于父级目录存在,也是遵循“最左前缀法则”。
联合索引结构分析,示例:
| 联合索引 |
INDEX idx_empno_birthdate_gender(emp_no,birth_date,gender) |
| 等价建立的索引 |
实际上联合索引idx_empno_birthdate_gender等价建立了三个索引:
|
| 联合索引命中的where条件字段列表 |
以上where子句查询条件联合索引idx_empno_birthdate_gender都会命中,只是使用的程度不一样(走的子索引不一样),因此,联合索引有“是否充分使用”衡量指标(key_len),当然使用最充分的条件是:所有字段都命中,即使用了index_3。 |
EXPLAIN SELECT * FROM employees WHERE birth_date = '1963-06-01' AND gender ='F';

注:表存在多个索引时,即使Where条件满足最左前缀规则,SQL执行时也未必一定会命中联合索引,根据性能可能直接使用了主键索引。
EG:
EXPLAIN SELECT * FROM employees WHERE emp_no = 10010 AND birth_date = '1963-06-01' AND gender ='F';

PRIMARY KEY (`emp_no`)
EG:
(a,b,c)组合索引,查询语句select...from...where a=.. and c=..走索引吗?
按最左前缀原则,a能走索引,c走不了,只能用到a部分索引。
注意:建立联合索引时,通常区分度高的字段放在最前面。
策略3:范围查询字段放最后
联合索引定义时,尽量将范围查询字段放在最后(放在最后联合索引使用最充分,放在中间联合索引使用不充分)。使用联合索引时范围列(当前范围列索引生效)后面的索引列无法生效,同时索引最多用于一个范围列,如果查询条件中有多个范围列,也只能用到一个范围列索引。
优化建议:尽量想办法把范围查询转换成in条件查询,效率更高。由于MySQL会将in条件查询会被转换成等值查询,可以命中索引。
EG1:
EXPLAIN SELECT emp_no,birth_date,gender FROM employees WHERE emp_no > 10015 AND gender ='F';

只是使用到了主键索引PRIMARY(emp_no),联合索引未生效idx_empno_birthdate_gender(emp_no,birth_date,gender);
删除idx_empno_birthdate_gender索引,新建联合索引idx_gender_birthdate_empno(gender,birth_date,emp_no);

EG2:
EXPLAIN SELECT emp_no,birth_date,gender FROM employees WHERE emp_no > 10015 AND birth_date = 1953-09-02 AND gender ='F';

策略4:不对索引字段进行逻辑操作
-对索引进行列运算(如,+、-、*、/),索引失效
在索引字段上进行计算、函数、类型转换(自动\手动)都会导致索引失效。
优化建议:不可以对索引列进行运算,可以在代码处理好,再传参进去。如果非要SQL运算操作,那么可以考虑可以把内置函数的运算逻辑转移到右边(列值)。
EG:
CREATE INDEX idx_first_name ON employees(first_name);
EXPLAIN SELECT * FROM employees WHERE LEFT(first_name,3) ='Geo';

策略5:尽量全值匹配
全值匹配也就是精确匹配不使用like查询(模糊匹配),使用like会使查询效率降低。
策略6:Like查询,左侧尽量不要加%
like 以%开头,当前列索引无效(当为联合索引时,当前列和后续列索引不生效,可能导致索引使用不充分);当like前缀没有%,后缀有%时,索引有效。
优化建议:
- 把%放后面
- 使用覆盖索引
EG1:
EXPLAIN SELECT * FROM employees WHERE first_name like'Geo%';

EG2:
EXPLAIN SELECT * FROM employees WHERE first_name like'%Geo%';

策略7:注意NULL/NOT NULL可能对索引有影响
在索引列上使用 IS NULL 或 IS NOT NULL条件,可能对索引有所影响。
- 字段定义默认为NULL时,NULL索引生效,NOT NULL索引不生效;
- 字段定义明确为NOT NULL ,不允许为空时,NULL/NOT NULL索引列,索引均失效;
列字段尽量设置为NOT NULL,MySQL难以对使用NULL的列进行查询优化,允许Null会使索引值以及索引统计更加复杂。允许NULL值的列需要更多的存储空间,还需要MySQL内部进行特殊处理。
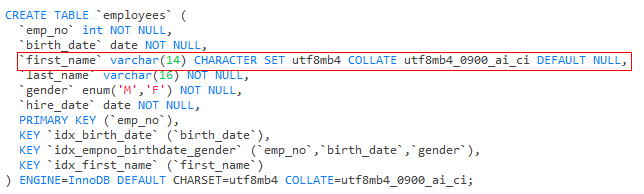
EG1:
EXPLAIN SELECT * FROM employees WHERE first_name IS NULL;

EG2:
EXPLAIN SELECT * FROM employees WHERE first_name IS NOT NULL;

EG3:
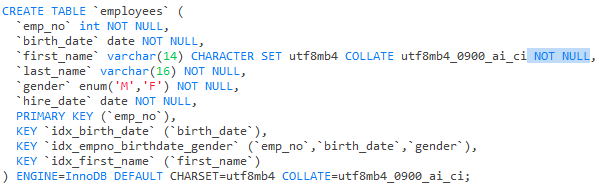
EXPLAIN SELECT * FROM employees WHERE first_name IS NOT NULL;

策略8:尽量减少使用不等于
不等于操作符是不会使用索引的。不等于操作符包括:not in,<>,!=。
其实这个是跟mySQL优化器有关,如果优化器觉得即使走了索引,还是需要扫描很多很多行,它觉得不划算,不如直接不走索引。
优化建议:数值型 key<>0 改为 key>0 or key<0。
EG:
EXPLAIN SELECT * FROM employees WHERE first_name != 'Georgi';

策略9:字符类型务必加上引号
若varchar类型字段值不加单引号,可能会发生数据类型隐式转化,自动转换为int型,使索引无效。
EG:
EXPLAIN SELECT * FROM employees WHERE first_name = 1;

策略10:OR关键字前后尽量都为索引列
当OR左右查询字段只有一个是索引,会使该索引失效,只有当OR左右查询字段均为索引列时,这些索引才会生效。OR改UNION效率高。
优化建议:遇到不走索引的时候,考虑拆开两条SQL。
EG1:
EXPLAIN SELECT * FROM employees WHERE first_name = 'Georgi' OR emp_no = 20001;

EG2:
EXPLAIN SELECT * FROM employees WHERE first_name = 'Georgi' OR last_name = 'Facello';

补充1.左右连接,关联的字段编码格式需要相同
做表关联时,注意一下关联字段的编码格式,不一样可能导致索引失效。
补充2.优化器选错了索引
MySQL 中一张表是可以支持多个索引的。你写SQL语句的时候,没有主动指定使用哪个索引的话,用哪个索引是由MySQL来确定的。
我们日常开发中,不断地删除历史数据和新增数据的场景,有可能会导致MySQL选错索引。那么有哪些解决方案呢?
- 使用force index 强行选择某个索引
delete from account where name in (select name from old_account);
- 修改你的SQl,引导它使用我们期望的索引
- 优化你的业务逻辑
- 优化你的索引,新建一个更合适的索引,或者删除误用的索引。
补充3.delete + in子查询不走索引
当delete遇到in子查询时,即使有索引,也是不走索引的。而对应的select + in子查询,却可以走索引。
为什么select + in子查询会走索引,delete + in子查询却不会走索引呢?
执行以下SQL:
explain select * from account where name in (select name from old_account); show WARNINGS; //可以查看优化后,最终执行的sql
执行结果:
select `test2`.`account`.`id` AS `id`,`test2`.`account`.`name` AS `name`,`test2`.`account`.`balance` AS `balance`,`test2`.`account`.`create_time` AS `create_time`,`test2`.`account`.`update_time` AS `update_time` from `test2`.`account` semi join (`test2`.`old_account`) where (`test2`.`account`.`name` = `test2`.`old_account`.`name`)
可以发现,实际执行的时候,MySQL对select in子查询做了优化,把子查询改成join的方式,所以可以走索引。但是很遗憾,对于delete in子查询,MySQL却没有对它做这个优化。
后续:
- 索引的创建需要参照具体的SQL实现。
- 当全表扫描速度比索引速度快时,MySQL会使用全表扫描,此时索引失效。
- 表中存在多个索引时,即使where条件满足某个索引策略,MySQL查询优化器也不一定会使用该索引,可能使用其他索引,取决于性能。另外,当某个索引没有命中也不一定会走全表扫描,可能走其他索引。
- 理论上索引对顺序是敏感的,也就是说where子句的字段列表需要讲究顺序,但是由于MySQL的查询优化器会自动调整where子句的条件顺序以匹配适合的索引,因此,允许我们不去刻意关注where子句的条件顺序。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号