elasticsearch中文分词器(ik)配置
elasticsearch默认的分词:http://localhost:9200/userinfo/_analyze?analyzer=standard&pretty=true&text=我是中国人 (或者不写analyzer=standard)
分词之后是:“我”“是”“中”“国”“人“,会将每一个词都拆开。
使用ik对中文分词 http://localhost:9200/userinfo/_analyze?analyzer=ik&pretty=true&text=我是中国人
分词之后是:“我”“中国人”“中国”“国人”
1.在github上下载ik分词器的源码
下载地址:https://github.com/medcl/elasticsearch-analysis-ik
下载时候注意对应的es的版本

选择源码版本方式:
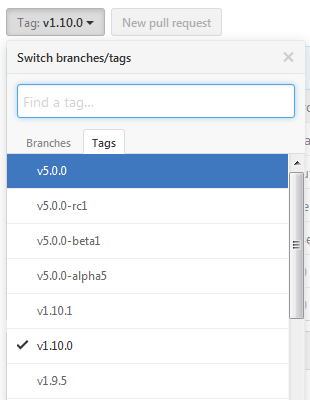
由于是maven工程,下载完成后将工程导入到eclipse中编译打包一下
2.将编译打包后的\target\releases\elasticsearch-analysis-ik-1.10.0.zip 解压后所有文件拷贝到 elasticsearch目录下的plugins\analysis-ik目录下
3.在elasticsearch的config/elasticsearch.yml 添加配置
index.analysis.analyzer.ik.type : "ik"
或者
index:
analysis:
analyzer:
ik:
alias: [ik_analyzer]
type: org.elasticsearch.index.analysis.IkAnalyzerProvider
ik_max_word:
type: ik
use_smart: false
ik_smart:
type: ik
use_smart: true
ik、ik_max_word、ik_smart
ik等同于ik_max_word,会将文本做最细粒度的拆分。例如“我”“中国人”“中国”,“国人”
而 ik_smart 会做最粗粒度的拆分。拆分结果则是“我”“中国人”。
4. elasticsearch 5.0及以上版本配置变动
1.移除名为 ik 的analyzer和tokenizer,请分别使用 ik_smart 和 ik_max_word
2.不需要在config/elasticsearch.yml 配置
参考网站:http://blog.csdn.net/liuzhenfeng/article/details/39404435
http://jack-boy.iteye.com/blog/2171853

 浙公网安备 33010602011771号
浙公网安备 33010602011771号