
18. 索引组织表
在InnoDB存储引擎中,Row都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表(index organized table),或者叫聚集索引(clustered index)
- 每张表必须有一个主键
- 根据主键的值构建一个B+树
- 这颗B+树的叶子节点存放所有记录
- 非叶子节点存放主键和指针(若干个{主键,指针}组成一个非页节点)
- 这里指针其实就是PageNumber,这个PageNumber就是下一层节点的PageNumber(这里不需要SpaceID,因为SpaceID对应的是ibd文件,我们现在是在ibd文件内部查找数据)
主键
如果创建表的时候没有显示指定主键,则InnoDB会按照如下方式选择或创建主键
- 判断表中是否有非空唯一索引,如果有,该列为主键
- 如果存在多个非空唯一索引,以创建表时第一个定义的非空唯一索引为准,而不是(columns)定义的顺序
- 如果上述条件都不符合,则InnoDB自动创建一个6字节大小的主键
主键实验
- 多个非空唯一键
root@mysqldb 13:35: [gavin]> create table test_key( -> a int, -- int类型 -> b int not null, -> c int not null, -> unique key(a), -> unique key(c), -- C列先定义 -> unique key(b) -> ); Query OK, 0 rows affected (3.01 sec) root@mysqldb 13:37: [gavin]> insert into test_key values(1,2,3),(4,5,6),(7,8,9); Query OK, 3 rows affected (0.00 sec) Records: 3 Duplicates: 0 Warnings: 0 root@mysqldb 13:38: [gavin]> select *, _rowid from test_key; +------+---+---+--------+ | a | b | c | _rowid | +------+---+---+--------+ | 1 | 2 | 3 | 3 | | 4 | 5 | 6 | 6 | | 7 | 8 | 9 | 9 | +------+---+---+--------+ 3 rows in set (0.00 sec) root@mysqldb 13:41: [gavin]> create table test_key_2 ( -> a varchar(8), -- 使用varchar类型 -> b varchar(8) not null, -> c varchar(8) not null, -> unique key(a), -> unique key(c), -> unique key(b) -> ); Query OK, 0 rows affected (0.01 sec) root@mysqldb 13:41: [gavin]> insert into test_key_2 values('a','b','c'),('d','e','f'),('g','h','i'); Query OK, 3 rows affected (0.00 sec) Records: 3 Duplicates: 0 Warnings: 0 root@mysqldb 13:41: [gavin]> select *, _rowid from test_key_2; -- _rowid只能是在key的类型为整型时才有效 ERROR 1054 (42S22): Unknown column '_rowid' in 'field list' -- 可以用下面的方法查看 -- 方法1 root@mysqldb 13:42: [information_schema]> select * from information_schema.COLUMNS where table_name='test_key_2' and column_key='PRI'\G *************************** 1. row *************************** TABLE_CATALOG: def TABLE_SCHEMA: gavin TABLE_NAME: test_key_2 COLUMN_NAME: c ORDINAL_POSITION: 3 COLUMN_DEFAULT: NULL IS_NULLABLE: NO DATA_TYPE: varchar CHARACTER_MAXIMUM_LENGTH: 8 CHARACTER_OCTET_LENGTH: 32 NUMERIC_PRECISION: NULL NUMERIC_SCALE: NULL DATETIME_PRECISION: NULL CHARACTER_SET_NAME: utf8mb4 COLLATION_NAME: utf8mb4_0900_ai_ci COLUMN_TYPE: varchar(8) COLUMN_KEY: PRI EXTRA: PRIVILEGES: select,insert,update,references COLUMN_COMMENT: GENERATION_EXPRESSION: SRS_ID: NULL 1 row in set (0.00 sec) -- 方法2 root@mysqldb 13:44: [gavin]> desc test_key_2; +-------+------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+------------+------+-----+---------+-------+ | a | varchar(8) | YES | UNI | NULL | | | b | varchar(8) | NO | UNI | NULL | | | c | varchar(8) | NO | PRI | NULL | | +-------+------------+------+-----+---------+-------+ 3 rows in set (0.00 sec)
- 系统定义主键
root@mysqldb 13:50: [gavin]> create table test_key_3( -> a int, -> b int, -> c int); Query OK, 0 rows affected (0.01 sec) root@mysqldb 13:51: [gavin]> insert into test_key_3 values(1,2,3),(4,5,6),(7,8,9); Query OK, 3 rows affected (0.01 sec) Records: 3 Duplicates: 0 Warnings: 0 root@mysqldb 13:51: [gavin]> select *,_rowid from test_key_3; -- 这里无法用_rowid查看,因为系统rowid对用户是透明的 ERROR 1054 (42S22): Unknown column '_rowid' in 'field list'
假设有a和b两张表都使用了系统定义的主键,则系统定义的主键的ID不是在表内进行单独递增的,而是全局递增 。
该系统的rowid是定义在ibdata1.ibd中的sys_rowid中,全局自增
6个字节表示的数据量为 2^48 ,通常意义上是够用的
注意:强烈建议自己显示定义主键
索引组织表与堆表
- 堆表
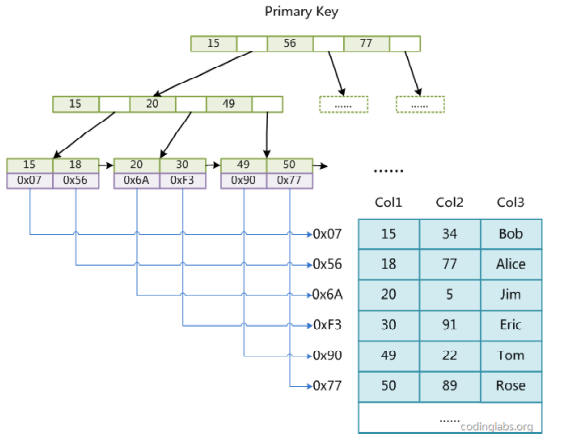
堆表将索引和数据分开(如MyISAM),索引中叶子节点存放的是数据的位置,而不是数据本身
- 索引组织表
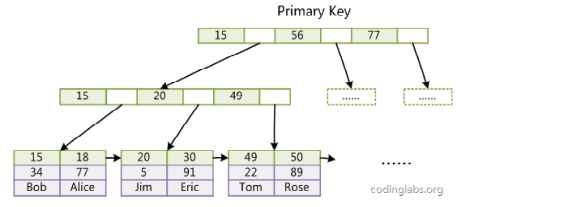
索引组织表将索引和数据放在了一起,索引的叶子节点(leaf page)存放了所有完整的记录(Row)。
索引即数据,数据即索引
注意:
1. 非叶子节点(Non-leaf page)中不会存放所有的数据(Row)的 {主键, PageNumber},而是从叶子节点(leaf page)中选出一个数据的主键,将这个主键和该页的PageNumber填入到非叶节点(Non-leaf page)中
2. 从逻辑上看,是一棵B+树,但是从物理上看都是每个页(非叶子节点和叶子节点)通过指针串在一起,使得逻辑有序。
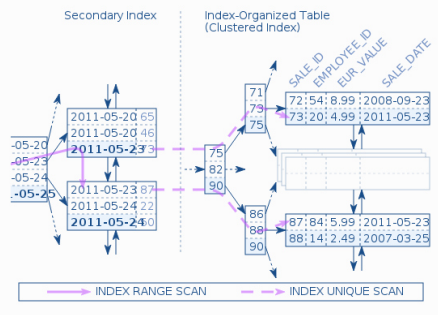
- 二级索引
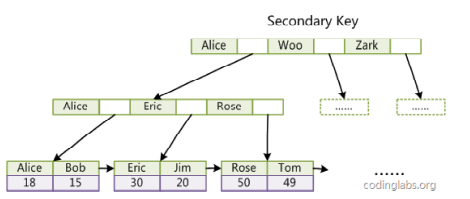
二级索引中的叶子节点不存放数据本身,而是存放主键
- 查询数据对比
- 堆表查询
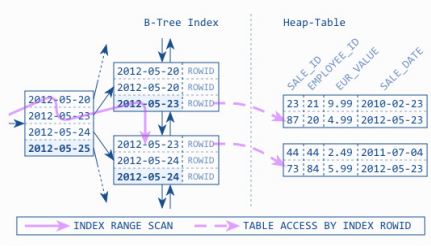
-
- 索引组织表及二级索引查询
Page的空间申请
- 叶子节点(leaf page) 由 leaf page segment 进行申请空间
- 非叶子节点(Non-leaf page) 由 Non-leaf page segment 进行申请空间
所以索引由两个段组成
- leaf page segment
- Non-leaf page segment
段(segment)是由区(extent)组成,申请空间就按照区(extent)进行申请(一般情况下一次申请4个区)

