
14. 磁盘
iostat
安装
apt-get install sysstat使用
iostat -xm 3 # x表示显示扩展统计信息,m表示以兆为单位显示,3表示每隔3秒显示
# 输出如下:
avg-cpu: %user %nice %system %iowait %steal %idle
0.58 0.00 0.33 0.00 0.00 99.08
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.00 0.00 0.67 0.00 0.00 8.00 0.00 2.00 0.00 2.00 1.00 0.07
sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00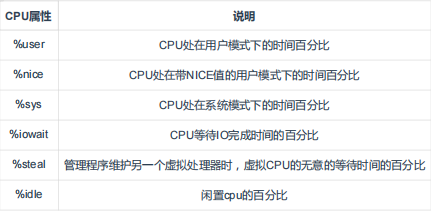
提示:
如果%iowait的值过高,表示硬盘存在I/O瓶颈;
如果%idle值高,表示CPU较空闲,如果%idle值高但系统响应慢时,有可能是CPU等待分配内存,此时应加大内存容量。
如果%idle值如果持续很低,那么系统的CPU处理能力相对较低,表明系统中最需要解决的资源是CPU。
提示:
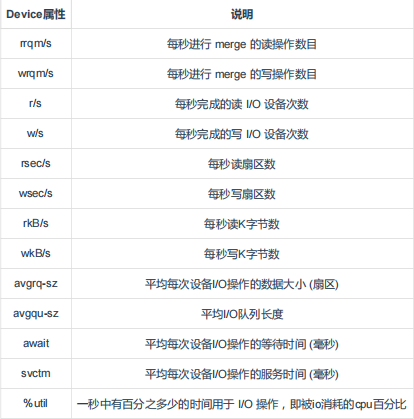
如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。
如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;
如果 await 远大于 svctm,说明I/O队列太长,io响应太慢,则需要进行必要优化。
如果avgqu-sz比较大,也表示有当量io在等待。
磁盘
磁盘的访问模式
- 顺序访问
- 顺序的访问磁盘上的块;
- 一般经过测试后,得到该值的单位是MB/s,表示为磁盘带宽,普通硬盘在50~ 100MB/s
- 随机访问
- 随机的访问磁盘上的块
- 也可以用MB/s进行表示,但是通常使用IOPS(每秒处理IO的能力),普通硬盘在100-200 IOPS
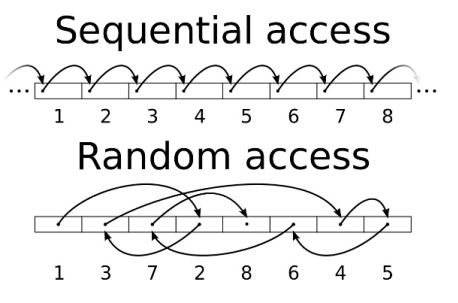
拷贝文件属于顺序访问, 数据库中访问数据属于随机访问 。
数据库对数据的访问做了优化,把随机访问转成顺序访问。
磁盘的分类
- HDD
- 盘片通过旋转,磁头进行定位,读取数据;
- 顺序性较好,随机性较差;
- 常见转速
- 笔记本硬盘:5400转/分钟;
- 桌面硬盘:7200转/分钟;
- 服务器硬盘:10000转/分钟、15000转/分钟;
- SATA:120 ~ 150 IOPS
- SAS :150 ~ 200 IOPS
从理论上讲,15000转/分钟,最高是15000/60约等于250 IOPS。由于机械盘片需要旋转,转速太高无法很好的散热
如果一个HDD对4K的块做随机访问是0.8MB/s,可通过 0.8 *(1 / 4)= 200 或者 (0.8 * 1000) / 4=200 得到 IOPS ,但是这个值存在部分干扰因素,如cache等
- SSD
- 纯电设备
- 由FLash Memory组成
- 没有读写磁头
- MLC闪存颗粒对一般企业的业务够用。目前SLC闪存颗粒价格较贵
- IOPS高
- 50000+ IOPS
- 读写速度非对称 以 INTEL SSD DC-S3500为例子:
- Random 4KB3 Reads: Up to 75,000 IOPS
- Random 4KB Writes: Up to 11,500 IOPS
- Random 8KB3 Reads: Up to 47,500 IOPS
- Random 8KB Writes: Up to 5,500 IOPS
- 当写入数据时,要先擦除老数据,再写入新数据
- 擦除数据需要擦除整个区域(128K or 256K)一起擦除(自动把部分有用的数据挪到别的区域)
对比发现4K性能要优于8K的性能,几乎是2倍的差距,当然16K就更明显,所以当使用SSD时,建议数据库页大小设置成4K或者是8K, innodb_page_size=8K )-- 设置为4k或者8k会不会导致索引树的高度增加?
上线以前,SSD需要经过严格的压力测试(一周时间),确保性能平稳
-
- Endurance Rating
- 表示该SSD的寿命是多少
- 比如450TBW,表示这个SSD可以反复写入的数据总量是450T(包括添加和更新)
- SSD线上参数设置
- 磁盘调度算法改为Deadline
- Endurance Rating
echo deadline > /sys/block/sda/queue/scheduler # deadline适用于数据库,HDD也建议改成Deadline-
- MySQL参数
- innodb_log_file_size=4G 该参数设置的尽可能大
- innodb_flush_neighbors=0
- MySQL参数
性能更平稳,且至少有15%的性能提升
磁盘调度算法
- CFQ
- CFQ把I/O请求按照进程分别放入进程对应的队列中,所以A进程和B进程发出的I/O请求会在两个队列中。而各个队列内部仍然采用合并和排序的方法,区别仅在于,每一个提交I/O请求的进程都有自己的I/O队列。
- CFQ的“公平”是针对进程而言的,它以时间片算法为前提,轮转调度队列,默认从当前队列中取4个请求处理,然后处理下一个队列的4个请求。这样就可以确保每个进程享有的I/O资源是均衡的。
- CFQ的缺点是先来的IO请求不一定能被及时满足,可能出现饥饿的情况。
- Deadline
- 同CFQ一样,除了维护一个拥有合并和排序功能的请求队列以外,还额外维护了两个队列,分别是读请求队列和写请求队列,它们都是带有超时的FIFO队列。当新来一个I/O请求时,会被同时插入普通队列和读/写队列,然后处理普通队列中的请求。当调度器发现读/写请求队列中的请求超时的时候,会优先处理这些请求,保证尽可能不产生请求饥饿。在DeadLine算法中,每个I/O请求都有一个超时时间,默认读请求是500ms ,写请求是5s。
- Noop
- Noop做的事情非常简单,它不会对I/O请求排序也不会进行任何其它优化(除了合并)。Noop除了对请求合并以外,不再进行任何处理,直接以类似FIFO的顺序提交I/O请求。
- Noop面向的不是普通的块设备,而是随机访问设备(例如SSD),对于这种设备,不存在传统的寻道时间,那么就没有必要去做那些多余的为了减少寻道时间而采取的事情了。
提升IOPS性能的手段
- 通过 RAID 技术
- 功耗较高
- IOPS在2000左右
- 通过购买共享存储设备
- 价格非常昂贵
- 但是比较稳定
- 底层还是通过RAID实现
- 直接使用SSD
- 性能较好的SSD可以达到 万级别的IOPS
- 建议可以用SSD + RAID5,RAID1+0太奢侈
文件系统和操作系统
- 文件系统
- XFS/EXT4
- noatime (不更新文件的atime标记,减少系统的IO访问)
- nobarrier (禁用barrier,可以提高性能,前提是使用write backup和使用BBU)
mount -o noatime,nobarrier /dev/sda1 /data
操作系统
- 推荐Linux
- 关闭SWAP

