
12. 索引/B+树/Explain
索引
索引的定义
索引是对记录按照一个或者多个字段进行排序的一种方式。对表中的某个字段建立索引会创建另一种数据结构,其中保存着字段的值,每个值又指向与它相关的记录。这种索引的数据结构是经过排序的,因而可以对其执行二分查找。且性能较高。
二叉树(Binary Tree)
二叉树的定义
- 每个节点至多只有二棵子树;
- 二叉树的子树有左右之分,次序不能颠倒;
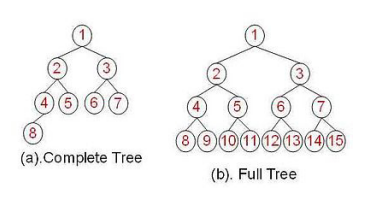
- 一棵深度为k,且有 2^k -1 个节点,称为满二叉树(Full Tree);
- 一棵深度为k,且root到k-1层的节点树都达到最大,第k层的所有节点都 连续集中 在最左边,此时为完全二叉树(Complete Tree)
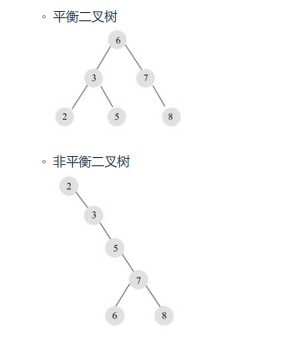
平衡二叉树
- 左子树和右子树都是平衡二叉树;
- 左子树和右子树的高度差绝对值不超过1;
- 平衡二叉树的遍历
以上面平衡二叉树的图例为样本,进行遍历:
-
- 前序 : 6 , 3, 2, 5, 7, 8(ROOT节点在开头, 中 -左-右 顺序)
- 中序 :2, 3, 5, 6 , 7, 8(中序遍历即为升序,左- 中 -右 顺序)
- 后序 :2, 5, 3, 8, 7, 6 (ROOT节点在结尾,左-右- 中 顺序)
-
- 可以通过 前序 和 中序 或者是 后序 和 中序 来推导出一个棵树
- 前序 或者 后序 用来得到ROOT节点, 中序 可以区分左右子树
- 平衡二叉树的旋转
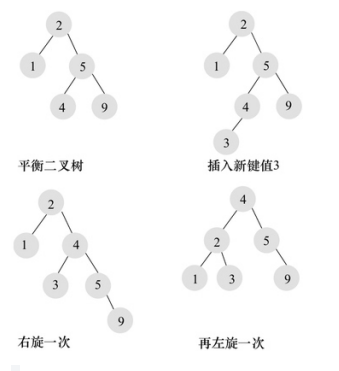
需要通过旋转(左旋,右旋)来维护平衡二叉树的平衡,在添加和删除的时候需要有额外的开销。
B树
- Balance Tree, 即为平衡树的意思,下图即是一颗B树
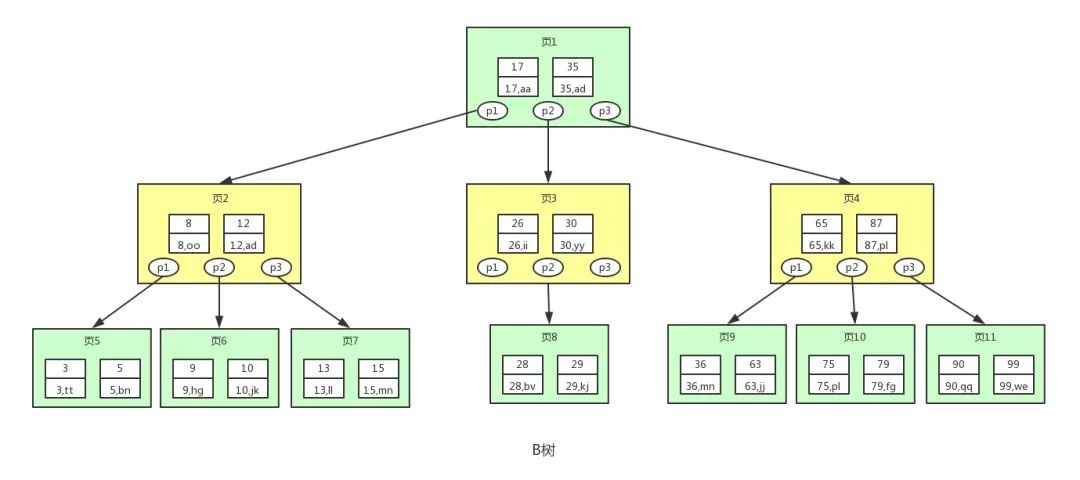
- 图中的p节点为指向子节点的指针,二叉树和平衡二叉树其实也有,因为图的美观性被省略了。
- 图中的每个节点称为页,页就是磁盘块,在MySQL中读取数据的基本单位都是页,所以我们这里叫做页更符合MySQL的底层数据结构
- B树相对平衡二叉树,每个节点存储了更多的键值(key)和数据(data),并且每个节点拥有更多的子节点
- 子节点的个数一般称为阶,上述图中的B树为3阶B树,高度也会很低。基于这个特性B树查找数据读取磁盘的次数将会很少,数据的查找效率也会比平衡二叉树高很多
假如我们要查找id等于28的用户信息,那么我们在上述B树中的查找流程如下:
- 先找到根节点也就是页1,判断28在键值17和35之间,我们那么我们根据页1中的指针p2找到页3。
- 将28和页3中的键值相比较,28在26和30之间,我们根据页3中的指针p2找到页8。
- 将28和页8中的键值相比较,发现有匹配的键值28,键值28对应的用户信息为(28,bv)。
B+树
B+树是对B树的进一步优化。下图为B+树的结构图
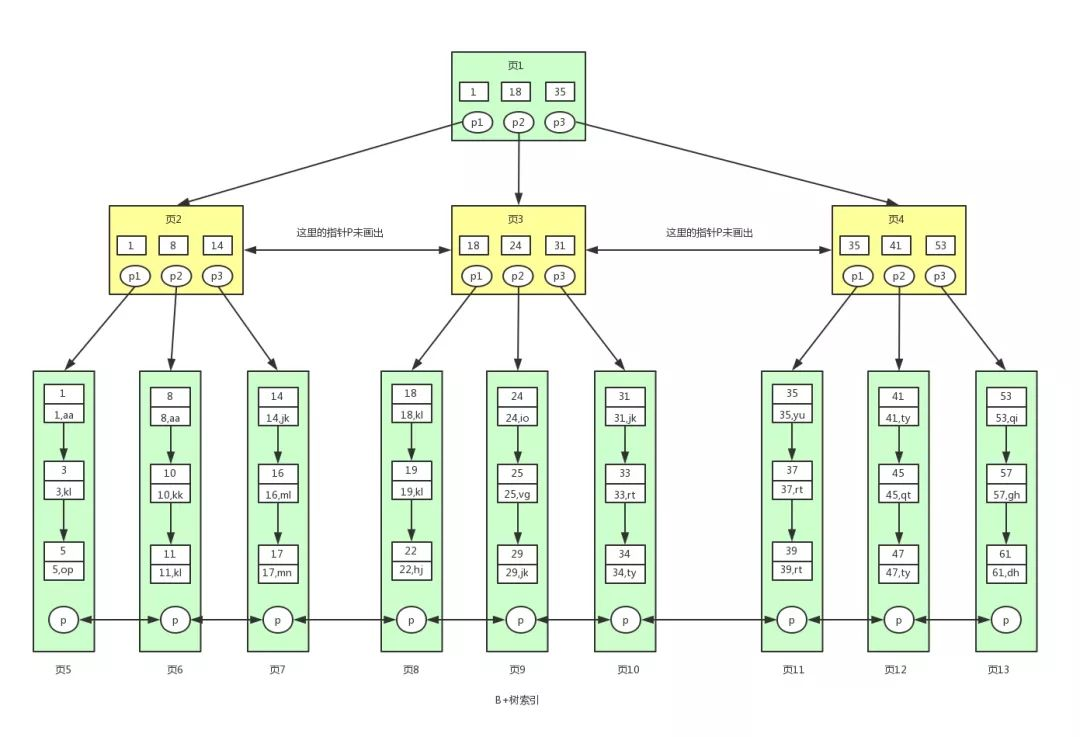
- 数据只存储在叶子节点上,非叶子节点只保存索引信息;
- 非叶子节点(索引节点)存储的只是一个Flag,不保存实际数据记录;
- 索引节点指示该节点的左子树比这个Flag小,而右子树大于等于这个Flag
- 叶子节点本身按照数据的升序排序进行链接(串联起来);
- 叶子节点中的数据在物理存储上是无序的,仅仅是在逻辑上有序 (通过指针串在一起);
- B+树含有非常高的扇出(fanout),通常超过100,在查找一个记录时,可以有效的减少IO操作;
B+树和B树的区别
- B+树非叶子节点不存储数据,只存储键值(key),而B树不仅存储键值也会存储数据。之所以这么做是因为数据库中页的大小是固定的,InnoDB中页的大小默认为16KB。如果不存储数据就能存储更多的键值,相应的树的阶数(节点的子节点数)就会更大,树就会更矮更胖。如此一来我们查找数据的磁盘IO次数就会再次减少,查询数据的效率也会更快。
- B树的阶数等于键值的数量,如果B+树一个节点可以存储1000个键值,那么3层B+树可以存储1000 * 1000 * 1000=10亿个数据。一般根节点是常驻内存的。所以一般我们查找10亿数据只需要两次磁盘的IO。
- B+树所有数据均存在于叶子节点,而且数据是顺序排列。所以B+树使得范围查找,顺序查找,分组查找以及去重查找变得异常简单。而B树因为数据分散在各个节点,要实现这一点很不容易。
- B+树各个页之间通过双向链表连接,叶子节点的数据通过单向链表连接。
B+树的操作
- B+树的插入
B+树的插入必须保证插入后叶子节点中的记录依然有序
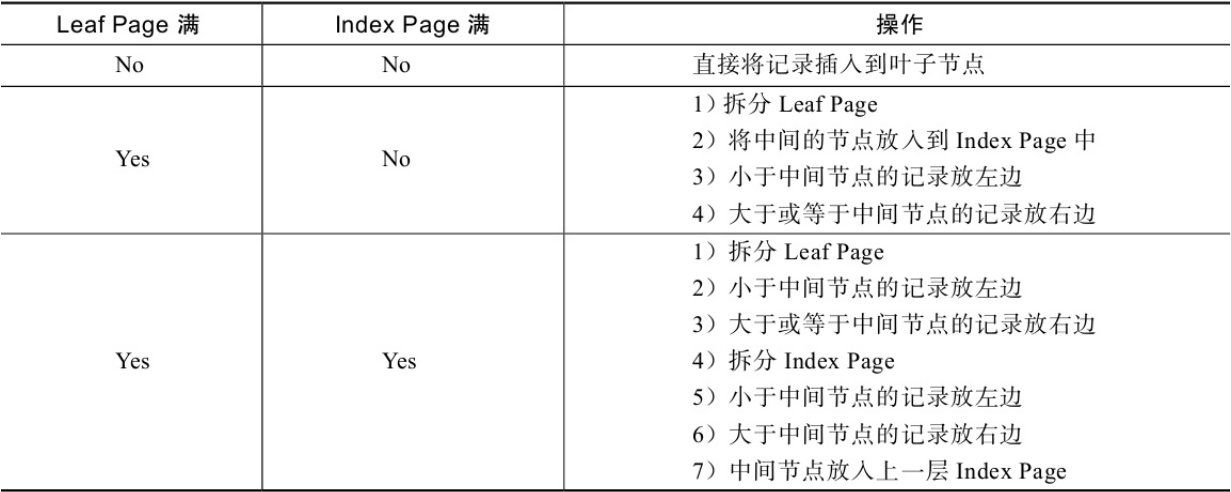
B+树总是会保持平衡。但是为了保持平衡对于新插入的键值可能需要做大量的拆分页(split)操作;部分情况下可以通过B+树的旋转来替代拆分页操作,进而达到平衡效果。
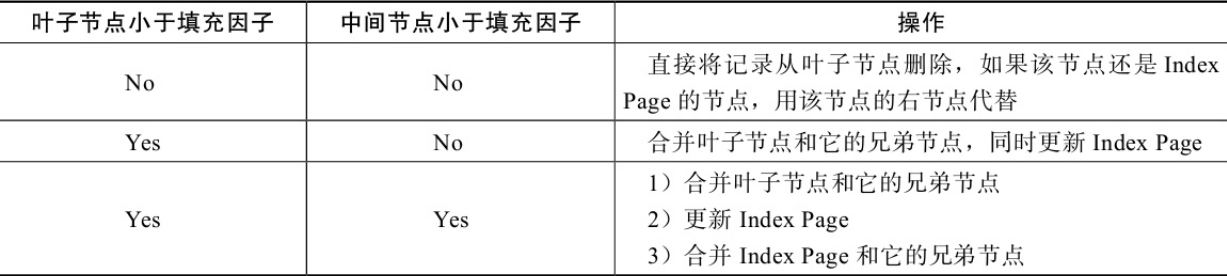
- B+树的删除
B+树使用填充因子(fill factor)来控制树的删除变化,50%是填充因子可设的最小值。B+树的删除操作同样必须保证删除后叶子节点中的记录依然排序。与插入不同的是,删除根据填充因子的变化来衡量。
B+树的扇出
- B+树图例
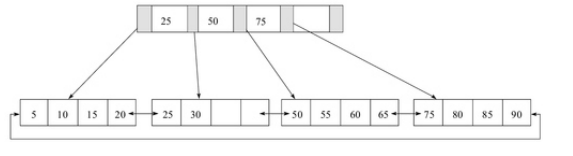
-
- 该 B+ 树高度为 2
- 每叶子页(LeafPage)4条记录
- 扇出数为5
- 叶子节点(LeafPage)由小到大(有序)串联在一起
- 扇出:每个索引节点(Non-LeafPage)指向每个叶子节点(LeafPage)的指针
- 扇出数 = 索引节点(Non-LeafPage)可存储的最大关键字个数 + 1
- 图例中的索引节点(Non-LeafPage)最大可以存放4个关键字,但实际使用了3个;
MySQL索引
索引类型(待补充)
创建索引
alter table test_index_1 add index idx_a (a); -- 给字段a添加索引。索引名为idx_a
查看索引
- desc table_name
- show create table table_name\G
- show index from table_name\G
root@mysqldb 13:59: [dbt3_s1]> show index from orders\G
*************************** 1. row ***************************
Table: orders
Non_unique: 0 -- 表示唯一的
Key_name: PRIMARY -- key的name是primary
Seq_in_index: 1
Column_name: o_orderkey
Collation: A
Cardinality: 1486533 -- 基数,这个列上不同值的记录数
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE -- 索引类型是BTree
Comment:
Index_comment:
Visible: YES
Expression: NULL
*************************** 2. row ***************************
Table: orders
Non_unique: 1 -- Non_unique为True,表示不唯一
Key_name: i_o_orderdate
Seq_in_index: 1
Column_name: o_orderDATE
Collation: A
Cardinality: 2462
Sub_part: NULL
Packed: NULL
Null: YES
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
*************************** 3. row ***************************
Table: orders
Non_unique: 1
Key_name: i_o_custkey
Seq_in_index: 1
Column_name: o_custkey
Collation: A
Cardinality: 100436
Sub_part: NULL
Packed: NULL
Null: YES
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
3 rows in set (0.01 sec)
root@mysqldb 13:59: [dbt3_s1]> select count(*) from orders;
+----------+
| count(*) |
+----------+
| 1500000 | -- orders中有150W条记录,和Cardinality 是不一致的
+----------+
1 row in set (0.42 sec)
Cardinality(基数)
Cardinality 表示该索引列上有多少不同的记录,这个是一个预估的值,是采样得到的(由InnoDB触发,采样20个页,进行预估),该值越大越好,即当Cardinality / RowNumber越接近1越好。表示该列是高选择性的 。
- 高选择性:身份证 、手机号码、姓名、订单号等
- 低选择性:性别、年龄等
即该列是否适合创建索引,就看该字段是否具有高选择性
root@mysqldb 14:02: [dbt3_s1]> show create table lineitem\G
*************************** 1. row ***************************
Table: lineitem
Create Table: CREATE TABLE `lineitem` (
`l_orderkey` int NOT NULL,
`l_partkey` int DEFAULT NULL,
`l_suppkey` int DEFAULT NULL,
`l_linenumber` int NOT NULL,
`l_quantity` double DEFAULT NULL,
`l_extendedprice` double DEFAULT NULL,
`l_discount` double DEFAULT NULL,
`l_tax` double DEFAULT NULL,
`l_returnflag` char(1) DEFAULT NULL,
`l_linestatus` char(1) DEFAULT NULL,
`l_shipDATE` date DEFAULT NULL,
`l_commitDATE` date DEFAULT NULL,
`l_receiptDATE` date DEFAULT NULL,
`l_shipinstruct` char(25) DEFAULT NULL,
`l_shipmode` char(10) DEFAULT NULL,
`l_comment` varchar(44) DEFAULT NULL,
PRIMARY KEY (`l_orderkey`,`l_linenumber`), -- 两个列作为primary
KEY `i_l_shipdate` (`l_shipDATE`),
KEY `i_l_suppkey_partkey` (`l_partkey`,`l_suppkey`),
KEY `i_l_partkey` (`l_partkey`),
KEY `i_l_suppkey` (`l_suppkey`),
KEY `i_l_receiptdate` (`l_receiptDATE`),
KEY `i_l_orderkey` (`l_orderkey`),
KEY `i_l_orderkey_quantity` (`l_orderkey`,`l_quantity`),
KEY `i_l_commitdate` (`l_commitDATE`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
1 row in set (0.00 sec)
root@mysqldb 14:02: [dbt3_s1]> show index from lineitem\G -- 省略其他输出,只看PRIMARY
*************************** 1. row ***************************
Table: lineitem
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1 -- 索引中的顺序,该列的顺序为1
Column_name: l_orderkey
Collation: A
Cardinality: 1338364 -- 约130W
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
*************************** 2. row ***************************
Table: lineitem
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 2 -- 索引中的顺序,该列的顺序为2
Column_name: l_linenumber
Collation: A
Cardinality: 5406960 -- 约540W
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
- 第一个索引(Seq_in_index = 1)的 Cardinality 的值表示 当前列(l_orderkey) 的不重复的值
- 第二个索引(Seq_in_index = 2)的 Cardinality 的值表示 前两列(l_orderkey)和(l_linenumber) 不重复的值
--
-- SQL-1
--
root@mysqldb 14:08: [dbt3_s1]> select * from lineitem limit 10;
+------------+-----------+-----------+--------------+------------+-----------------+------------+-------+--------------+--------------+------------+--------------+---------------+-------------------+------------+----------------------------------------+
| l_orderkey | l_partkey | l_suppkey | l_linenumber | l_quantity | l_extendedprice | l_discount | l_tax | l_returnflag | l_linestatus | l_shipDATE | l_commitDATE | l_receiptDATE | l_shipinstruct | l_shipmode | l_comment |
+------------+-----------+-----------+--------------+------------+-----------------+------------+-------+--------------+--------------+------------+--------------+---------------+-------------------+------------+----------------------------------------+
| 1 | 155190 | 7706 | 1 | 17 | 21168.23 | 0.04 | 0.02 | N | O | 1996-03-13 | 1996-02-12 | 1996-03-22 | DELIVER IN PERSON | TRUCK | blithely regular ideas caj |
| 1 | 67310 | 7311 | 2 | 36 | 45983.16 | 0.09 | 0.06 | N | O | 1996-04-12 | 1996-02-28 | 1996-04-20 | TAKE BACK RETURN | MAIL | slyly bold pinto beans detect s |
| 1 | 63700 | 3701 | 3 | 8 | 13309.6 | 0.1 | 0.02 | N | O | 1996-01-29 | 1996-03-05 | 1996-01-31 | TAKE BACK RETURN | REG AIR | deposits wake furiously dogged, |
| 1 | 2132 | 4633 | 4 | 28 | 28955.64 | 0.09 | 0.06 | N | O | 1996-04-21 | 1996-03-30 | 1996-05-16 | NONE | AIR | even ideas haggle. even, bold reque |
| 1 | 24027 | 1534 | 5 | 24 | 22824.48 | 0.1 | 0.04 | N | O | 1996-03-30 | 1996-03-14 | 1996-04-01 | NONE | FOB | carefully final gr |
| 1 | 15635 | 638 | 6 | 32 | 49620.16 | 0.07 | 0.02 | N | O | 1996-01-30 | 1996-02-07 | 1996-02-03 | DELIVER IN PERSON | MAIL | furiously regular accounts haggle bl |
| 2 | 106170 | 1191 | 1 | 38 | 44694.46 | 0 | 0.05 | N | O | 1997-01-28 | 1997-01-14 | 1997-02-02 | TAKE BACK RETURN | RAIL | carefully ironic platelets against t |
| 3 | 4297 | 1798 | 1 | 45 | 54058.05 | 0.06 | 0 | R | F | 1994-02-02 | 1994-01-04 | 1994-02-23 | NONE | AIR | blithely s |
| 3 | 19036 | 6540 | 2 | 49 | 46796.47 | 0.1 | 0 | R | F | 1993-11-09 | 1993-12-20 | 1993-11-24 | TAKE BACK RETURN | RAIL | final, regular pinto |
| 3 | 128449 | 3474 | 3 | 27 | 39890.88 | 0.06 | 0.07 | A | F | 1994-01-16 | 1993-11-22 | 1994-01-23 | DELIVER IN PERSON | SHIP | carefully silent pinto beans boost fur |
+------------+-----------+-----------+--------------+------------+-----------------+------------+-------+--------------+--------------+------------+--------------+---------------+-------------------+------------+----------------------------------------+
10 rows in set (0.00 sec)
--
-- SQL-2
--
root@mysqldb 14:08: [dbt3_s1]> select l_orderkey, l_linenumber from lineitem limit 10;
+------------+--------------+
| l_orderkey | l_linenumber |
+------------+--------------+
| 721220 | 2 |
| 842980 | 4 |
| 904677 | 1 |
| 990147 | 1 |
| 1054181 | 1 |
| 1111877 | 3 |
| 1332613 | 1 |
| 1552449 | 2 |
| 2167527 | 3 |
| 2184032 | 5 |
+------------+--------------+
10 rows in set (0.00 sec)
--- SQL-1和SQL-2其实都是在没有排序的情况下,取出前10条数据。但是结果不一样
--
-- SQL-3
--
root@mysqldb 14:08: [dbt3_s1]> select l_orderkey, l_linenumber from lineitem order by l_orderkey limit 10; -- 和上面的sql相比,多了一个order by的操作
+------------+--------------+
| l_orderkey | l_linenumber |
+------------+--------------+
| 1 | 1 | -- 看orderkey为1,对应的linenumber有6条,这就是orderkey的Cardinality仅为130W,而(orderkey + linenumber)就有540W
| 1 | 2 |
| 1 | 3 |
| 1 | 4 |
| 1 | 5 |
| 1 | 6 |
| 2 | 1 |
| 3 | 1 |
| 3 | 2 |
| 3 | 3 |
+------------+--------------+
10 rows in set (0.01 sec)
--- SQL-3 和SQL-2 不同的原因是 他们走了不同的索引
root@mysqldb 14:25: [dbt3_s1]> explain select l_orderkey, l_linenumber from lineitem\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: lineitem
partitions: NULL
type: index
possible_keys: NULL
key: i_l_shipdate -- 使用了shipdate进行了索引
key_len: 4
ref: NULL
rows: 5409258
filtered: 100.00
Extra: Using index
1 row in set, 1 warning (0.00 sec)
root@mysqldb 14:26: [dbt3_s1]> explain select l_orderkey, l_linenumber from lineitem order by l_orderkey limit 10\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: lineitem
partitions: NULL
type: index
possible_keys: NULL
key: i_l_orderkey -- 使用了orderkey进行了查询
key_len: 4
ref: NULL
rows: 10
filtered: 100.00
Extra: Using index
1 row in set, 1 warning (0.00 sec)
root@mysqldb 14:25: [dbt3_s1]> explain select * from lineitem limit 10\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: lineitem
partitions: NULL
type: ALL -- SQL-1进行了全表扫描
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 5409258
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
-- 所以,不使用order by取出的结果,可以理解为不是根据主键排序的结果。innodb_on_state = off
在MySQL5.5之前,执行 show create table 操作会触发采样,而5.5之后将该参数off后,需要主动执行 analyze table 才会去采样。采样不会锁表或者锁记录。
复合索引
root@mysqldb 13:12: [dbt3_s1]> show create table lineitem\G
*************************** 1. row ***************************
Table: lineitem
Create Table: CREATE TABLE `lineitem` (
`l_orderkey` int NOT NULL,
`l_partkey` int DEFAULT NULL,
`l_suppkey` int DEFAULT NULL,
`l_linenumber` int NOT NULL,
`l_quantity` double DEFAULT NULL,
`l_extendedprice` double DEFAULT NULL,
`l_discount` double DEFAULT NULL,
`l_tax` double DEFAULT NULL,
`l_returnflag` char(1) DEFAULT NULL,
`l_linestatus` char(1) DEFAULT NULL,
`l_shipDATE` date DEFAULT NULL,
`l_commitDATE` date DEFAULT NULL,
`l_receiptDATE` date DEFAULT NULL,
`l_shipinstruct` char(25) DEFAULT NULL,
`l_shipmode` char(10) DEFAULT NULL,
`l_comment` varchar(44) DEFAULT NULL,
PRIMARY KEY (`l_orderkey`,`l_linenumber`), -- 两个列作为primary,这个就是复合索引
KEY `i_l_shipdate` (`l_shipDATE`),
KEY `i_l_suppkey_partkey` (`l_partkey`,`l_suppkey`),
KEY `i_l_partkey` (`l_partkey`),
KEY `i_l_suppkey` (`l_suppkey`),
KEY `i_l_receiptdate` (`l_receiptDATE`),
KEY `i_l_orderkey` (`l_orderkey`),
KEY `i_l_orderkey_quantity` (`l_orderkey`,`l_quantity`),
KEY `i_l_commitdate` (`l_commitDATE`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
1 row in set (0.01 sec)- 例子
root@mysqldb 13:55: [gavin]> explain select * from test_index_2 where a = 1\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test_index_2
partitions: NULL
type: ref
possible_keys: idx_mul_ab
key: idx_mul_ab -- 符合最左前缀,走了索引
key_len: 5
ref: const
rows: 2
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.01 sec)
root@mysqldb 14:13: [gavin]> explain select * from test_index_2 where a = 1 and b = 2\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test_index_2
partitions: NULL
type: ref
possible_keys: idx_mul_ab
key: idx_mul_ab -- 符合最左前缀,走了索引
key_len: 10
ref: const,const
rows: 1
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
root@mysqldb 14:14: [gavin]> explain select * from test_index_2 where b = 2\G -- 只查询b
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test_index_2
partitions: NULL
type: ALL -- 不符合最左前缀,不走索引
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 6
filtered: 16.67
Extra: Using where
1 row in set, 1 warning (0.00 sec)
root@mysqldb 14:20: [gavin]> explain select * from test_index_2 where a=1 or b = 2\G -- 使用or,要求结果集是并集
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test_index_2
partitions: NULL
type: ALL -- 全表扫描,因为b上没有索引,所以需要全表扫描才能知道哪些行的值b = 2。
-- 既然已经全表扫描,a的值就一起过滤了,就没必要再查一次a的索引
possible_keys: idx_mul_ab
key: NULL
key_len: NULL
ref: NULL
rows: 6
filtered: 44.44
Extra: Using where
1 row in set, 1 warning (0.00 sec)
---- 还是只使用b列去做范围查询,走了索引,注意查询的是 count(*)
----
root@mysqldb 14:21: [gavin]> explain select count(*) from test_index_2 where b >1 and b < 3\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test_index_2
partitions: NULL
type: index
possible_keys: idx_mul_ab
key: idx_mul_ab
key_len: 10
ref: NULL
rows: 6
filtered: 16.67
Extra: Using where; Using index
1 row in set, 1 warning (0.00 sec)
-- 因为要求的是count(*), 要求所有的记录的和,那索引a是包含了全部的记录的,即扫描(a,b)的索引也是可以得到count(*)
-- 先根据索引找到所有的行,再根据where条件筛选出符合条件的行。所以Extra是: Using where; Using index
root@mysqldb 14:23: [gavin]> explain select * from test_index_2 where a = 1 and c = 10\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test_index_2
partitions: NULL
type: ref
possible_keys: idx_mul_ab
key: idx_mul_ab -- 如上同理。先根据联合索引筛选出所有的行,再根据c的条件判断
key_len: 5
ref: const
rows: 2
filtered: 16.67
Extra: Using where
1 row in set, 1 warning (0.00 sec)