
复制2-复制环境搭建
一. 复制环境搭建(基于MySQL 5.7.9-log)
1.1 创建一个复制用户
---
--- Master 节点
--
root@mysqldb 10:24: [(none)]> reset master; # 先将master设置成初始状态
mysql> create user 'repl'@'%' identified by '123456';
Query OK, 0 rows affected (0.01 sec)
mysql> grant replication slave on *.* to 'repl'@'%'; -- 需要replication和slave的权限,线上建议 限制成内网的网段
Query OK, 0 rows affected (0.01 sec)测试在slave上是否可以连接成功
[root@MySQL-Slave ~]# mysql -urepl -h 192.168.220.10 -p
1.2 备份数据
1.2.1 准备测试数据
create table test_1 ( a int not null auto_increment, b int, primary key(a) );
insert into test_1 values(NULL,1),(NULL,2),(NULL,3),(NULL,4)1.2.2 导出数据库
---
--- 导出数据并传到slave上
---
mysqldump -uroot -p --single-transaction --set-gtid-purged=OFF --all-databases --triggers --routines --events > all.sql
rsync all.sql root@192.168.220.11:/opt/mysql
2.3 还原数据
mysql < /opt/mysql/all.sql
2.4 CHANGE MASTER
change master to master_host='192.168.220.10',master_user='repl',master_password='123456',master_port=3306,master_log_file='binlog.000001',master_log_pos=1360;
2.5 Start slave
root@mysqldb 10:33: [(none)]> start slave;
Query OK, 0 rows affected, 1 warning (0.00 sec)
root@mysqldb 10:36: [(none)]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event -- IO 线程的状态
Master_Host: 192.168.220.10
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: binlog.000001 -- IO线程读取到的文件
Read_Master_Log_Pos: 2897 -- IO线程执行到的位置
Relay_Log_File: relay.000002
Relay_Log_Pos: 742
Relay_Master_Log_File: binlog.000001 -- SQL线程执行到的文件
Slave_IO_Running: Yes -- io thread 启动成功
Slave_SQL_Running: Yes -- sql thread 启动成功
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 2897 -- SQL线程执行到文件的位置
Relay_Log_Space: 939
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0 -- Slave 落后Master 的秒数
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0 -- (IO)如果这里有信息的话,就是错误提示信息,可以用来排错
Last_IO_Error:
Last_SQL_Errno: 0 -- (SQL)如果这里有信息的话,就是错误提示信息,可以用来排错
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 11
Master_UUID: 3c993697-f4b8-11ed-a315-000c2953dece
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set: 3c993697-f4b8-11ed-a315-000c2953dece:10-11
Executed_Gtid_Set: 3c993697-f4b8-11ed-a315-000c2953dece:10-11,
c3cb7908-f4b8-11ed-a7d9-000c299ea0a8:1-276
Auto_Position: 0
Replicate_Rewrite_DB:
Channel_Name:
1 row in set (0.00 sec)Slave_IO_Running 和 Slave_SQL_Running 这两个指标 都为YES ,表示目前的 复制 的状态是正常的
Slave上的线程状态
root@mysqldb 10:39: [(none)]> show processlist;
+----+-----------------+-----------+------+---------+------+--------------------------------------------------------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+-----------------+-----------+------+---------+------+--------------------------------------------------------+------------------+
| 1 | event_scheduler | localhost | NULL | Daemon | 3070 | Waiting on empty queue | NULL |
| 7 | system user | | NULL | Connect | 1309 | Waiting for master to send event | NULL |
| 8 | system user | | NULL | Connect | 1309 | Slave has read all relay log; waiting for more updates | NULL | -- SQL 线程
| 9 | system user | | NULL | Connect | 1858 | Waiting for an event from Coordinator | NULL | -- 开启了并行复制,则可以看到Coordinator线程
| 10 | system user | | NULL | Connect | 1309 | Waiting for an event from Coordinator | NULL |
| 11 | system user | | NULL | Connect | 1309 | Waiting for an event from Coordinator | NULL |
| 12 | system user | | NULL | Connect | 1309 | Waiting for an event from Coordinator | NULL |
| 14 | root | localhost | NULL | Query | 0 | starting | show processlist |
+----+-----------------+-----------+------+---------+------+--------------------------------------------------------+------------------+
8 rows in set (0.00 sec)- 并行复制参数
-
- slave-parallel-type = LOGICAL_CLOCK
- slave-parallel-workers = 4
- Relay_Log_File 和 Relay_Log_Pos 是中继日志(Relay_Log)信息
- 由于 IO线程 拉取数据的速度快于 SQL线程 回放数据的速度,所以 Relay_Log 可在两者之间起到一个 缓冲 的作用
- Relay_Log 的格式和 binlog 的 格式 是一样的,但是两者的内容是不一样的(不是和binlog一一对应的)
- Relay_Log 在 SQL线程 回放完成 后,(默认)就会被删除,而 binlog 不会(由expire_logs_days 控制)
- Relay_Log 可以通过设置 relay_log_purge=0 ,使得 Relay_Log 不被删除(MHA中不希望被Purge),需要通过外部的脚本进行删除
2.6 复制搭建总结
- Master和Slave上配置不同的server-id,且binlog_format设置为ROW格式
- 在Master上创建一个'repl'@'%'的用户(%替换为内网网段)
- 将Master的备份数据恢复到Slave上,注意记录master status信息(binlog_file和position)
- 在Slave上进行change master操作,注意master_log_file和master_log_pos要和备份中的master status一致
- 在Slave上进行start slave操作
- 在Slave上进行show slave status\G; 操作,确保Slave_IO_Running和Slave_SQL_Running均为YES
2.7 搭建真正的高可靠复制环境
2.7.1 重要的参数
- Master
-
- binlog-do-db = # 需要复制的库
- binlog-ignore-db = # 需要被忽略的库
- max_binlog_size = 2048M # 默认为1024M
- binlog_format = ROW # 必须为ROW
- transaction-isolation = READ-COMMITTED
- expire_logs_days = 7 # binlog保留多少天,看公司计划安排
- server-id = 11 # 必须和所有从机不一样,且从机之间也不一样
- binlog_cache_size = # binlog 缓存的大小,设置时要当心
- sync_binlog = 1 # 必须设置为1,默认为0
- innodb_flush_log_at_trx_commit = 1 # 提交事物的时候刷新日志
- innodb_support_xa = 1 #不知道是什么意思
- Slave
-
- log_slave_updates # 将SQL线程回放的数据写入到从机的binlog中去(用于级联复制)
- replicate-do-db = # 需要复制的库
- replicate-ignore-db = # 需要忽略的库
- replicate-do-table = # 需要复制的表
- replicate-ignore-table = 需要忽略的表
- server-id = 22 # 必须在一个复制集群环境中全局唯一
- relay-log-recover = 1 # I/O thread crash safe – IO线程安全
- relay_log_info_repository = TABLE # SQL thread crash safe – SQL线程安全
- master_info_repository = TABLE
- read_only = 1
2.7.2 SQL线程高可靠问题
- 如果将 relay_log_info_repository设置为FILE,MySQL会把回放信息记录在一个relay-info.log的文件中,其中包含SQL线程回放到的Relay_log_name和Relay_log_pos,以及对应的Master的Master_log_name和Master_log_pos。
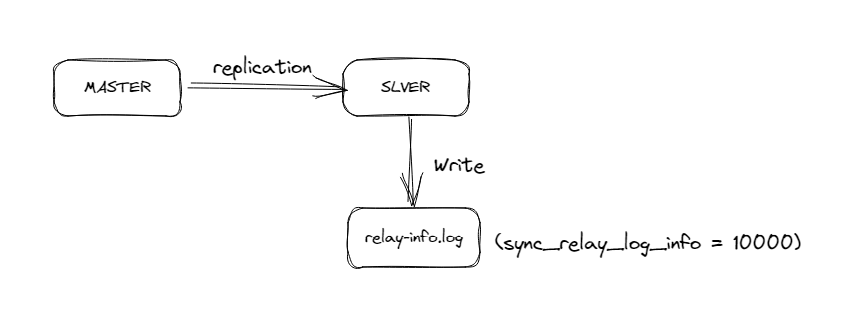
- SQL线程回放event
- 将回放到的binlog的文件名和位置写到relay-info.log文件
- 参数sync_relay_log_info = 10000(fsync)代表每回放10000个event,写一次relay-info.log
-
- 如果该参数设置为1,则表示每回放一个event,就写一次relay-info.log,那写入代价很大,且性能很差
- 设置为1后,即使性能上可以接受,还是会丢最后一次的操作,恢复起来后还是有1062的错误(重复执行event)
SQL线程的数据回放是写数据库操作,relay-info是写文件操作,这两个操作很难保证一致性
当一个Slave节点在复制数据时,可能发生如下情况, 数据2和数据3写入成功 (且已经落盘),但是relay-info.log中的记录还是数据1的位置(因为 sync_relay_log_info 的关系,此时还没有fsync,如下图所示:
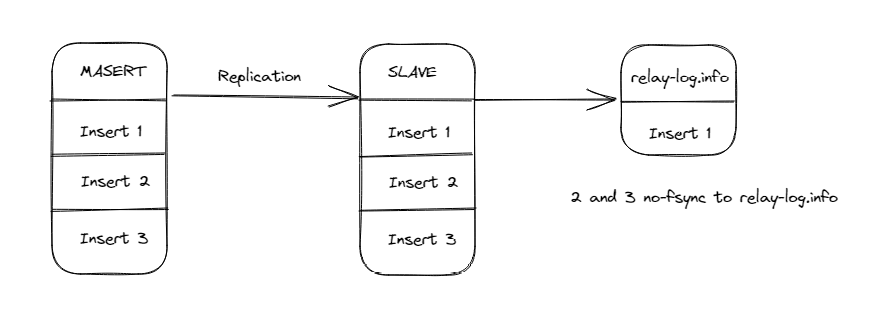
此时slave宕机,然后重启,便会产生如下的状况:
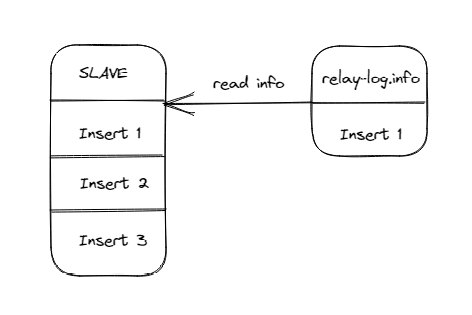
1. Slave的库中存在数据2和数据3
2. Slave读取relay-info.log中的Relay_log_name和Relay_log_pos,此时记录的是回放到数据1的位置
3. Slave从数据1开始回放,继续插入数据2和数据3
4. 但是,此时的数据库中存在数据2和数据3,于是发生了1062的错误(重复记录)
在MySQL5.6+以后,将relay_log_info_repository设置为TABLE,relay-info将写入到mysql.slave_relay_log_info这张表中
root@mysqldb 09:19: [(none)]> select * from mysql.slave_relay_log_info\G
*************************** 1. row ***************************
Number_of_lines: 7
Relay_log_name: ./relay.000009
Relay_log_pos: 317
Master_log_name: binlog.000002
Master_log_pos: 194
Sql_delay: 0
Number_of_workers: 4
Id: 1
Channel_name:
1 row in set (0.53 sec)设置为TABLE的原理为:将event的回放和relay-info的更新放在同一个事物里面,变成原子操作,从而保证一致性(要么都写入,要么都不写)。
每一次事物提交,都会写入mysql.slave_relay_log_info中,sync_relay_log_info=N将被忽略。官方参数解释
BEGIN;
apply log event;
apply log event;
UPDATE mysql.slave_relay_log_info
SET Master_log_pos = Exec_Master_Log_Pos,
Master_log_name = Relay_Master_Log_File,
Relay_log_name = Relay_Log_File,
Relay_log_pos = Relay_Log_Pos;
COMMIT;
2.7.3 I/O线程高可用
- IO线程也是接收一个个的event,将接收到的event,通过设置参数master_info_repository可以将master-info信息(IO线程接收到的位置,Master_log_name和Master_log_pos)写入到文件(FILE)或者数据库(TABLE)中。然后将接收到的event写入relay log file
- 参数sync_master_info=10000表示每接收10000个event,写一次master-info
- 这里同样存在这个问题,master-info.log和relay-log无法保证一致性。
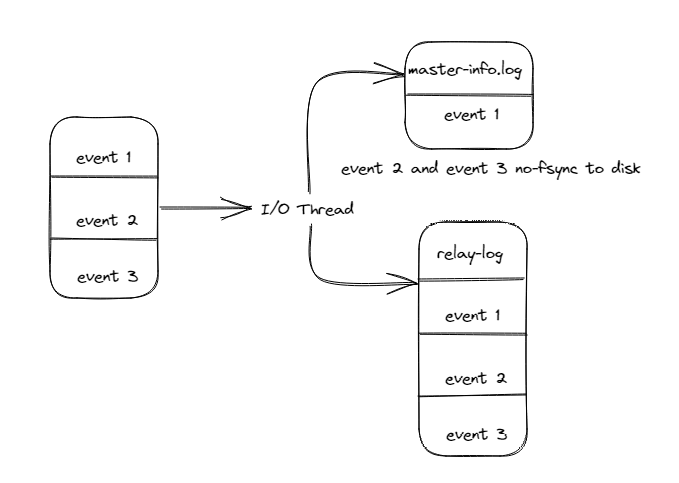
此时如果服务宕机后,MySQL重启,I/O线程会读取master-info.log的内容,读取到的位置为event1的位置,然后I/O线程会继续将event2和event3拉取过来,然后继续写入到relay-log中。
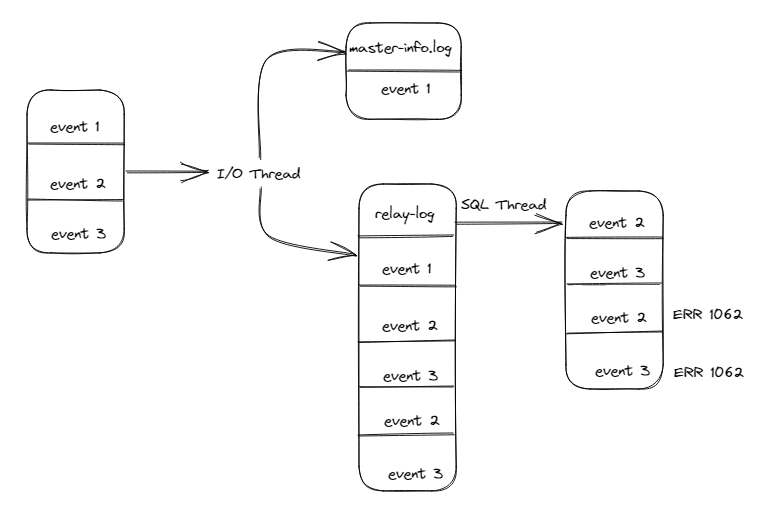
如上图所示,event2和event3被重复写入到了relay-log文件中,当SQL线程回放时,就会产生1062的错误(重复记录)
看到的现象还是IO线程正常,SQL线程报错
解决该问题的方法就是设置参数relay-log-recover = 1,该参数表示当前接收到的relay-log全部删除,然后从SQL线程回放到的位置重新拉取(SQL线程通过配置后是可靠的)
所以说,真正的MySQL复制的高可靠是从5.6版本开始的,通过设置
- relay-log-recover = 1
- relay_log_info_repository = TABLE
- master_info_repository = TABLE
这三个参数,可以确保整体复制的高可靠(换言之,之前的版本复制不可靠是正常的)。
注意:如果Slave落后Master的时间很多,超过了Master上binlog的保存时间,那Master上对应的binlog就会被删除,Slave的I/O Thread就拉不到数据了
注意监控主从落后的时间
2.7.4 master_info_repository设置
- master_info_repository设置为TABLE或者FILE对复制的可靠性是没有帮助的,因为设置relay-log-recover = 1后,会重新通过SQL线程回放到的位置进行拉取。
- 但是master_info_repository也一定要设置为TABLE,性能上比设置为FILE有很高的提升(官方BUG)
设置为TABLE后,master-info将信息保存到mysql.slave_master_info中
root@mysqldb 09:46: [(none)]> select * from mysql.slave_master_info\G
*************************** 1. row ***************************
Number_of_lines: 24
Master_log_name: binlog.000003
Master_log_pos: 194
Host: 192.168.220.10
User_name: repl
User_password: 123456
Port: 3306
Connect_retry: 60
Enabled_ssl: 0
Ssl_ca:
Ssl_capath:
Ssl_cert:
Ssl_cipher:
Ssl_key:
Ssl_verify_server_cert: 0
Heartbeat: 30
Bind:
Ignored_server_ids: 0
Uuid: 3c993697-f4b8-11ed-a315-000c2953dece
Retry_count: 86400
Ssl_crl:
Ssl_crlpath:
Enabled_auto_position: 0
Channel_name:
1 row in set (0.00 sec)
2.7.5 read_only与super_read_only
- 如果在Slave机器上对数据库进行修改或者删除,会导致主从的不一致,需要对Slave机器设置为 read_only = 1 ,让Slave提供 只读 操作。
- 注意: read_only 仅仅对 没有SUPER权限 的用户 有效 (即mysql.user表的Super_priv字段为Y),一般给 App 的权限是 不需要SUPER权限 的。
- 参数 super_read_only 可以将有 SUPER权限 的用户也设置为 只读 ,且该参数设置为 ON 后, read_only 也跟着 自动 设置为 ON ;


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律