
Python之re模块
re是一个使用频率很高的模块。
# python2 # -*- coding: utf-8 -*- import re str = 'ABC\\-001' print str str = r'ABC\-001' print str if re.match(r'\w{3}\\\-\d{3}', str): print 'good match' else: print 'bad match' src = 'hello\nworld' print src if re.match(r'hello\nworld', src): print 'good match' else: print 'bad match' if re.match(r'hello.world', src): print 'good match' else: print 'bad match' if re.match(r'hello.world', src, re.S): print 'good match' else: print 'bad match' src = r'hello\nworld' print src if re.match(r'hello\\nworld', src): print 'good match' else: print 'bad match'

这个例子想说明的是,Python中的字符串如果使用'r'前缀,字符串中的内容就是本身,没有转义。
re模块的常用函数:



一个常用的flag是:

如果一个正则表达式需要多次使用,可以预编译该表达式。


最后要说的是贪婪匹配和非贪婪匹配,看个例子:
str = r'102300' print re.match(r'^(\d+)(0*)$', str).groups() print re.match(r'^(\d+?)(0*)$', str).groups()
输出:
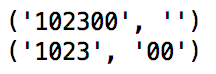
默认是贪婪匹配,通过加个?,可以使\d+执行非贪婪匹配。
查看匹配结果除了groups(),还有个group()。

参考资料:
https://docs.python.org/2/library/re.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号