
MIT-6.828-JOS-lab5:File system, Spawn and Shell
Lab 5: File system, Spawn and Shell
tags: mit-6.828 os
概述
本lab将实现JOS的文件系统,只要包括如下四部分:
- 引入一个文件系统进程(FS进程)的特殊进程,该进程提供文件操作的接口。
- 建立RPC机制,客户端进程向FS进程发送请求,FS进程真正执行文件操作,并将数据返回给客户端进程。
- 更高级的抽象,引入文件描述符。通过文件描述符这一层抽象就可以将控制台,pipe,普通文件,统统按照文件来对待。(文件描述符和pipe实现原理)
- 支持从磁盘加载程序并运行。
File system preliminaries
我们将要实现的文件系统会比真正的文件系统要简单,但是能满足基本的创建,读,写,删除文件的功能。但是不支持链接,符号链接,时间戳等特性。
On-Disk File System Structure
JOS的文件系统不使用inodes,所有文件的元数据都被存储在directory entry中。
文件和目录逻辑上都是由一系列数据blocks组成,这些blocks分散在磁盘中,文件系统屏蔽blocks分布的细节,提供一个可以顺序读写文件的接口。JOS文件系统允许用户读目录元数据,这就意味着用户可以扫描目录来像实现ls这种程序,UNIX没有采用这种方式的原因是,这种方式使得应用程序过度依赖目录元数据格式。
Sectors and Blocks
大部分磁盘都是以Sector为粒度进行读写,JOS中Sectors为512字节。文件系统以block为单位分配和使用磁盘。注意区别,sector size是磁盘的属性,block size是操作系统使用磁盘的粒度。JOS的文件系统的block size被定为4096字节。
Superblocks
文件系统使用一些特殊的block保存文件系统属性元数据,比如block size, disk size, 根目录位置等。这些特殊的block叫做superblocks。
我们的文件系统使用一个superblock,位于磁盘的block 1。block 0被用来保存boot loader和分区表。很多文件系统维护多个superblock,这样当一个损坏时,依然可以正常运行。
磁盘结构如下: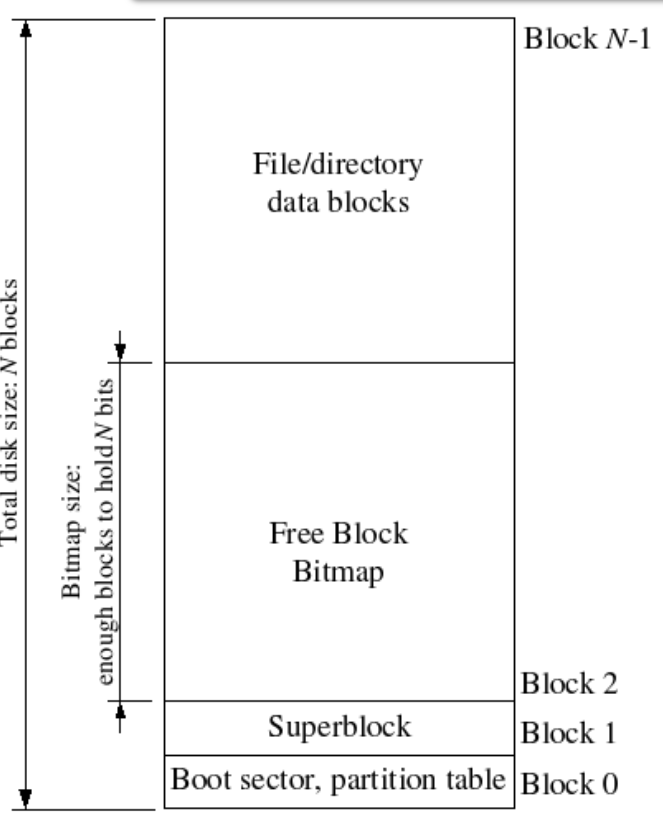
Super结构如下:
struct Super {
uint32_t s_magic; // Magic number: FS_MAGIC
uint32_t s_nblocks; // Total number of blocks on disk
struct File s_root; // Root directory node
};
File Meta-data
我们的文件系统使用struct File结构描述文件,该结构包含文件名,大小,类型,保存文件内容的block号。struct File结构的f_direct数组保存前NDIRECT(10)个block号,这样对于10*4096=40KB的文件不需要额外的空间来记录内容block号。对于更大的文件我们分配一个额外的block来保存4096/4=1024 block号。所以我们的文件系统允许文件最多拥有1034个block。File结构如下: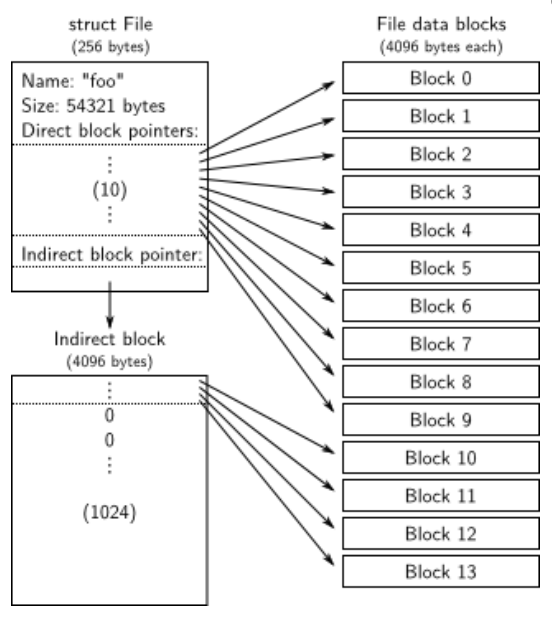
File结构定义在inc/fs.h中:
struct File {
char f_name[MAXNAMELEN]; // filename
off_t f_size; // file size in bytes
uint32_t f_type; // file type
// Block pointers.
// A block is allocated iff its value is != 0.
uint32_t f_direct[NDIRECT]; // direct blocks
uint32_t f_indirect; // indirect block
// Pad out to 256 bytes; must do arithmetic in case we're compiling
// fsformat on a 64-bit machine.
uint8_t f_pad[256 - MAXNAMELEN - 8 - 4*NDIRECT - 4];
} __attribute__((packed)); // required only on some 64-bit machines
Directories versus Regular Files
File结构既能代表文件也能代表目录,由type字段区分,文件系统以相同的方式管理文件和目录,只是目录文件的内容是一系列File结构,这些File结构描述了在该目录下的文件或者子目录。
超级块中包含一个File结构,代表文件系统的根目录。
The File System
Disk Access
到目前为止内核还没有访问磁盘的能力。JOS不像其他操作系统一样在内核添加磁盘驱动,然后提供系统调用。我们实现一个文件系统进程来作为磁盘驱动。
x86处理器使用EFLAGS寄存器的IOPL为来控制保护模式下代码是否能执行设备IO指令,比如in和out。我们希望文件系统进程能访问IO空间,其他进程不能。
Exercise 1
文件系统进程的type为ENV_TYPE_FS,需要修改env_create(),如果type是ENV_TYPE_FS,需要给该进程IO权限。
在env_create()中添加如下代码:
if (type == ENV_TYPE_FS) {
e->env_tf.tf_eflags |= FL_IOPL_MASK;
}
The Block Cache
我们的文件系统最大支持3GB,文件系统进程保留从0x10000000 (DISKMAP)到0xD0000000 (DISKMAP+DISKMAX)固定3GB的内存空间作为磁盘的缓存。比如block 0被映射到虚拟地址0x10000000,block 1被映射到虚拟地址0x10001000以此类推。
如果将整个磁盘全部读到内存将非常耗时,所以我们将实现按需加载,只有当访问某个bolck对应的内存地址时出现页错误,才将该block从磁盘加载到对应的内存区域,然后重新执行内存访问指令。
Exercise 2
实现bc_pgfault()和flush_block()。
bc_pgfault()是FS进程缺页处理函数,负责将数据从磁盘读取到对应的内存。可以回顾下lab4。
bc_pgfault(struct UTrapframe *utf)
{
void *addr = (void *) utf->utf_fault_va;
uint32_t blockno = ((uint32_t)addr - DISKMAP) / BLKSIZE;
int r;
// Check that the fault was within the block cache region
if (addr < (void*)DISKMAP || addr >= (void*)(DISKMAP + DISKSIZE))
panic("page fault in FS: eip %08x, va %08x, err %04x",
utf->utf_eip, addr, utf->utf_err);
// Sanity check the block number.
if (super && blockno >= super->s_nblocks)
panic("reading non-existent block %08x\n", blockno);
// Allocate a page in the disk map region, read the contents
// of the block from the disk into that page.
// Hint: first round addr to page boundary. fs/ide.c has code to read
// the disk.
//
// LAB 5: you code here:
addr = ROUNDDOWN(addr, PGSIZE);
sys_page_alloc(0, addr, PTE_W|PTE_U|PTE_P);
if ((r = ide_read(blockno * BLKSECTS, addr, BLKSECTS)) < 0)
panic("ide_read: %e", r);
// Clear the dirty bit for the disk block page since we just read the
// block from disk
if ((r = sys_page_map(0, addr, 0, addr, uvpt[PGNUM(addr)] & PTE_SYSCALL)) < 0)
panic("in bc_pgfault, sys_page_map: %e", r);
// Check that the block we read was allocated. (exercise for
// the reader: why do we do this *after* reading the block
// in?)
if (bitmap && block_is_free(blockno))
panic("reading free block %08x\n", blockno);
}
flush_block()将一个block写入磁盘。flush_block()不需要做任何操作,如果block没有在内存或者block没有被写过。可以通过PTE的PTE_D位判断该block有没有被写过。
void
flush_block(void *addr)
{
uint32_t blockno = ((uint32_t)addr - DISKMAP) / BLKSIZE;
int r;
if (addr < (void*)DISKMAP || addr >= (void*)(DISKMAP + DISKSIZE))
panic("flush_block of bad va %08x", addr);
// LAB 5: Your code here.
addr = ROUNDDOWN(addr, PGSIZE);
if (!va_is_mapped(addr) || !va_is_dirty(addr)) { //如果addr还没有映射过或者该页载入到内存后还没有被写过,不用做任何事
return;
}
if ((r = ide_write(blockno * BLKSECTS, addr, BLKSECTS)) < 0) { //写回到磁盘
panic("in flush_block, ide_write(): %e", r);
}
if ((r = sys_page_map(0, addr, 0, addr, uvpt[PGNUM(addr)] & PTE_SYSCALL)) < 0) //清空PTE_D位
panic("in bc_pgfault, sys_page_map: %e", r);
}
fs/fs.c中的fs_init()将会初始化super和bitmap全局指针变量。至此对于文件系统进程只要访问虚拟内存[DISKMAP, DISKMAP+DISKMAX]范围中的地址addr,就会访问到磁盘((uint32_t)addr - DISKMAP) / BLKSIZE block中的数据。如果block数据还没复制到内存物理页,bc_pgfault()缺页处理函数会将数据从磁盘拷贝到某个物理页,并且将addr映射到该物理页。这样FS进程只需要访问虚拟地址空间[DISKMAP, DISKMAP+DISKMAX]就能访问磁盘了。
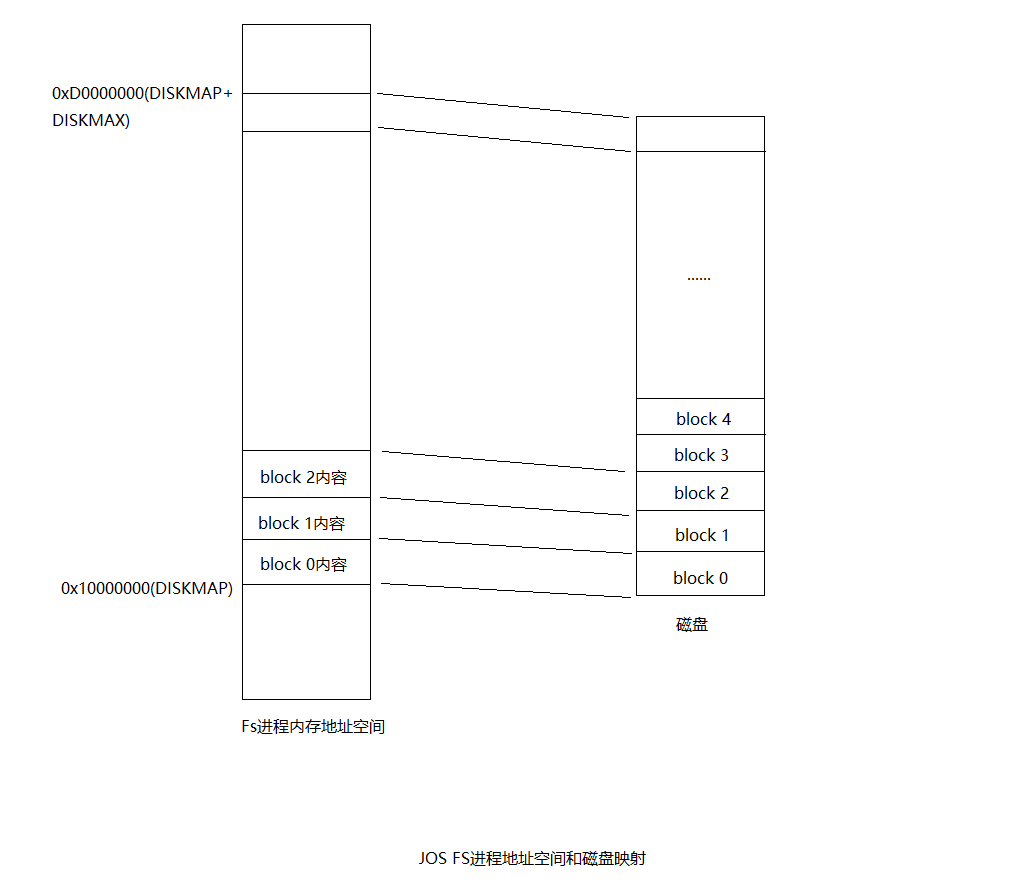
The Block Bitmap
fs_init()中已经初始化了bitmap,我们能通过bitmap访问磁盘的block 1,也就是位数组,每一位代表一个block,1表示该block未被使用,0表示已被使用。我们实现一系列管理函数来管理这个位数组。
Exercise 3
实现fs/fs.c中的alloc_block(),该函数搜索bitmap位数组,返回一个未使用的block,并将其标记为已使用。
alloc_block(void)
{
// The bitmap consists of one or more blocks. A single bitmap block
// contains the in-use bits for BLKBITSIZE blocks. There are
// super->s_nblocks blocks in the disk altogether.
// LAB 5: Your code here.
uint32_t bmpblock_start = 2;
for (uint32_t blockno = 0; blockno < super->s_nblocks; blockno++) {
if (block_is_free(blockno)) { //搜索free的block
bitmap[blockno / 32] &= ~(1 << (blockno % 32)); //标记为已使用
flush_block(diskaddr(bmpblock_start + (blockno / 32) / NINDIRECT)); //将刚刚修改的bitmap block写到磁盘中
return blockno;
}
}
return -E_NO_DISK;
}
File Operations
fs/fs.c文件提供了一系列函数用于管理File结构,扫描和管理目录文件,解析绝对路径。
基本的文件系统操作:
file_block_walk(struct File *f, uint32_t filebno, uint32_t **ppdiskbno, bool alloc):查找f指向文件结构的第filebno个block的存储地址,保存到ppdiskbno中。如果f->f_indirect还没有分配,且alloc为真,那么将分配要给新的block作为该文件的f->f_indirect。类比页表管理的pgdir_walk()。file_get_block(struct File *f, uint32_t filebno, char **blk):该函数查找文件第filebno个block对应的虚拟地址addr,将其保存到blk地址处。walk_path(const char *path, struct File **pdir, struct File **pf, char *lastelem):解析路径path,填充pdir和pf地址处的File结构。比如/aa/bb/cc.c那么pdir指向代表bb目录的File结构,pf指向代表cc.c文件的File结构。又比如/aa/bb/cc.c,但是cc.c此时还不存在,那么pdir依旧指向代表bb目录的File结构,但是pf地址处应该为0,lastelem指向的字符串应该是cc.c。dir_lookup(struct File *dir, const char *name, struct File **file):该函数查找dir指向的文件内容,寻找File.name为name的File结构,并保存到file地址处。dir_alloc_file(struct File *dir, struct File **file):在dir目录文件的内容中寻找一个未被使用的File结构,将其地址保存到file的地址处。
文件操作:
file_create(const char *path, struct File **pf):创建path,如果创建成功pf指向新创建的File指针。file_open(const char *path, struct File **pf):寻找path对应的File结构地址,保存到pf地址处。file_read(struct File *f, void *buf, size_t count, off_t offset):从文件f中的offset字节处读取count字节到buf处。file_write(struct File *f, const void *buf, size_t count, off_t offset):将buf处的count字节写到文件f的offset开始的位置。
Exercise 4
实现file_block_walk()和file_get_block()。
file_block_walk():
static int
file_block_walk(struct File *f, uint32_t filebno, uint32_t **ppdiskbno, bool alloc)
{
// LAB 5: Your code here.
int bn;
uint32_t *indirects;
if (filebno >= NDIRECT + NINDIRECT)
return -E_INVAL;
if (filebno < NDIRECT) {
*ppdiskbno = &(f->f_direct[filebno]);
} else {
if (f->f_indirect) {
indirects = diskaddr(f->f_indirect);
*ppdiskbno = &(indirects[filebno - NDIRECT]);
} else {
if (!alloc)
return -E_NOT_FOUND;
if ((bn = alloc_block()) < 0)
return bn;
f->f_indirect = bn;
flush_block(diskaddr(bn));
indirects = diskaddr(bn);
*ppdiskbno = &(indirects[filebno - NDIRECT]);
}
}
return 0;
}
file_get_block():
int
file_get_block(struct File *f, uint32_t filebno, char **blk)
{
// LAB 5: Your code here.
int r;
uint32_t *pdiskbno;
if ((r = file_block_walk(f, filebno, &pdiskbno, true)) < 0) {
return r;
}
int bn;
if (*pdiskbno == 0) { //此时*pdiskbno保存着文件f第filebno块block的索引
if ((bn = alloc_block()) < 0) {
return bn;
}
*pdiskbno = bn;
flush_block(diskaddr(bn));
}
*blk = diskaddr(*pdiskbno);
return 0;
}
踩坑记录
包括后面的Exercise 10都遇到相同的问题。
写完Exercise4后执行make grade,无法通过测试,提示"file_get_block returned wrong data"。在实验目录下搜索该字符串,发现是在fs/test.c文件中,
if ((r = file_open("/newmotd", &f)) < 0)
panic("file_open /newmotd: %e", r);
if ((r = file_get_block(f, 0, &blk)) < 0)
panic("file_get_block: %e", r);
if (strcmp(blk, msg) != 0)
panic("file_get_block returned wrong data");
也就是说只有当blk和msg指向的字符串不一样时才会报这个错,msg定义在fs/test.c中static char *msg = "This is the NEW message of the day!\n\n"。blk指向/newmotd文件的开头。/newmotd文件在fs/newmotd中,打开后发现内容也是"This is the NEW message of the day!"。照理来说应该没有问题啊。但是通过xxd fs/newmotd指令查看文件二进制发现如下:
1. 00000000: 5468 6973 2069 7320 7468 6520 4e45 5720 This is the NEW
2. 00000010: 6d65 7373 6167 6520 6f66 2074 6865 2064 message of the d
3. 00000020: 6179 210d 0a0d 0a ay!....
最后的两个换行符是0d0a 0d0a,也就是\r\n\r\n。但是msg中末尾却是\n\n。\r\n应该是windows上的换行符,不知道为什么fs/newmotd中的换行符居然是windows上的换行符。找到问题了所在,我们用vim打开fs/newmotd,然后使用命令set ff=unix,保存退出。现在再用xxd fs/newmotd指令查看文件二进制发现,换行符已经变成了\n(0x0a)。这样就可以通过该实验了。在Exercise 10中同样需要将fs文件夹下的lorem,script,testshell.sh文件中的换行符转成UNIX下的。
The file system interface
到目前为止,文件系统进程已经能提供各种操作文件的功能了,但是其他用户进程不能直接调用这些函数。我们通过进程间函数调用(RPC)对其它进程提供文件系统服务。RPC机制原理如下:
Regular env FS env
+---------------+ +---------------+
| read | | file_read |
| (lib/fd.c) | | (fs/fs.c) |
...|.......|.......|...|.......^.......|...............
| v | | | | RPC mechanism
| devfile_read | | serve_read |
| (lib/file.c) | | (fs/serv.c) |
| | | | ^ |
| v | | | |
| fsipc | | serve |
| (lib/file.c) | | (fs/serv.c) |
| | | | ^ |
| v | | | |
| ipc_send | | ipc_recv |
| | | | ^ |
+-------|-------+ +-------|-------+
| |
+-------------------+
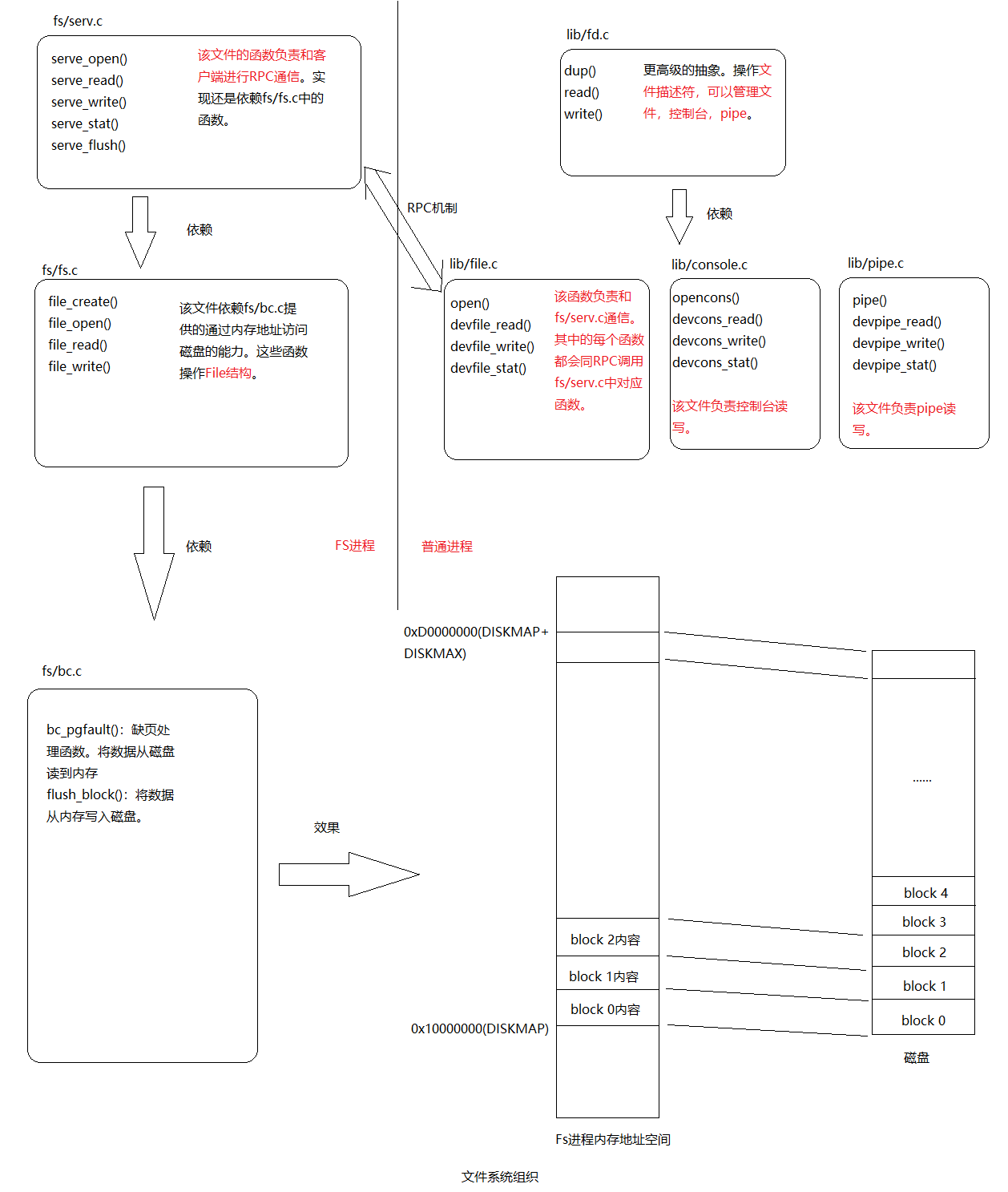
本质上RPC还是借助IPC机制实现的,普通进程通过IPC向FS进程间发送具体操作和操作数据,然后FS进程执行文件操作,最后又将结果通过IPC返回给普通进程。从上图中可以看到客户端的代码在lib/fd.c和lib/file.c两个文件中。服务端的代码在fs/fs.c和fs/serv.c两个文件中。
相关数据结构之间的关系可用下图来表示: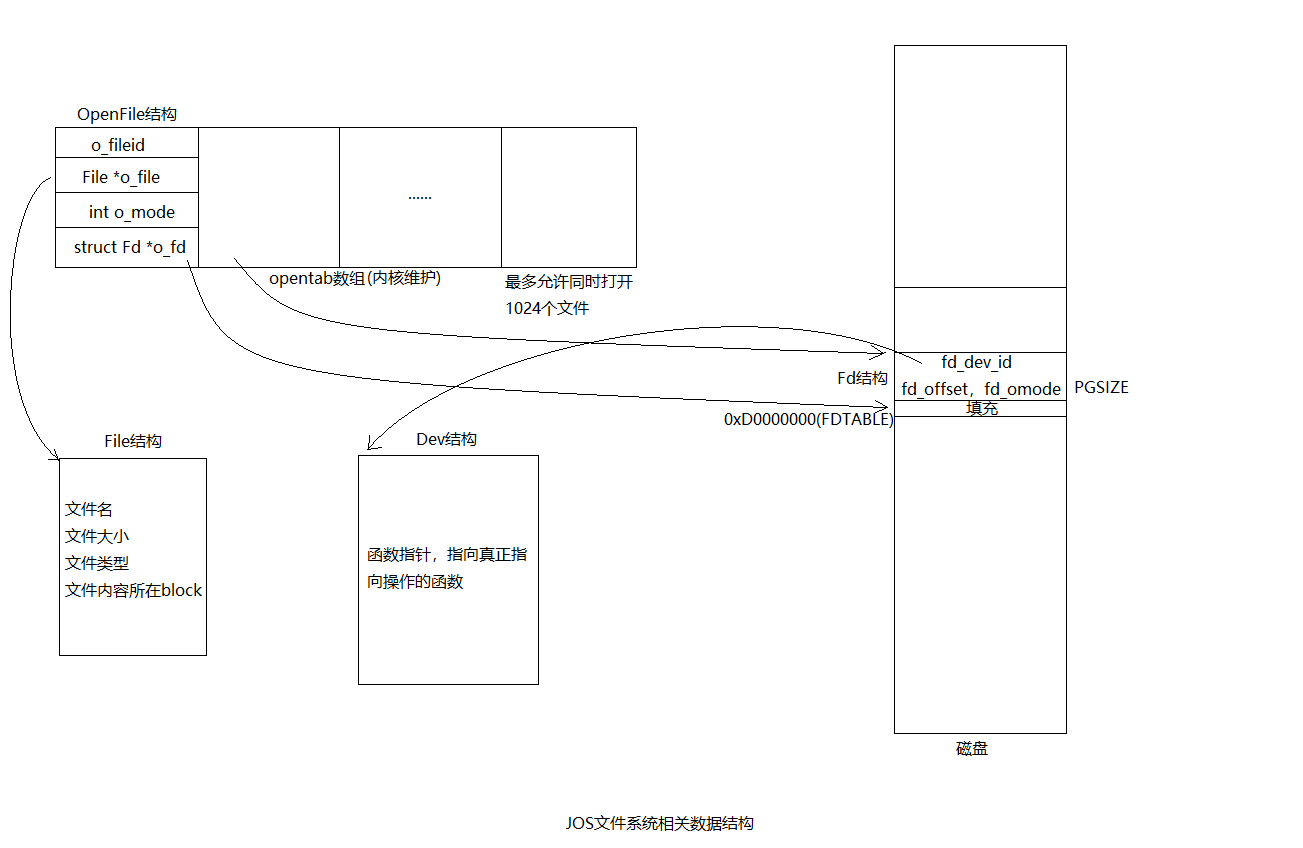
文件系统服务端代码在fs/serv.c中,serve()中有一个无限循环,接收IPC请求,将对应的请求分配到对应的处理函数,然后将结果通过IPC发送回去。
对于客户端来说:发送一个32位的值作为请求类型,发送一个Fsipc结构作为请求参数,该数据结构通过IPC的页共享发给FS进程,在FS进程可以通过访问fsreq(0x0ffff000)来访问客户进程发来的Fsipc结构。
对于服务端来说:FS进程返回一个32位的值作为返回码,对于FSREQ_READ和FSREQ_STAT这两种请求类型,还额外通过IPC返回一些数据。
Exercise 5
实现fs/serv.c中的serve_read()。这是服务端也就是FS进程中的函数。直接调用更底层的fs/fs.c中的函数来实现。
int
serve_read(envid_t envid, union Fsipc *ipc)
{
struct Fsreq_read *req = &ipc->read;
struct Fsret_read *ret = &ipc->readRet;
if (debug)
cprintf("serve_read %08x %08x %08x\n", envid, req->req_fileid, req->req_n);
// Lab 5: Your code here:
struct OpenFile *o;
int r;
r = openfile_lookup(envid, req->req_fileid, &o);
if (r < 0) //通过fileid找到Openfile结构
return r;
if ((r = file_read(o->o_file, ret->ret_buf, req->req_n, o->o_fd->fd_offset)) < 0) //调用fs.c中函数进行真正的读操作
return r;
o->o_fd->fd_offset += r;
return r;
}
Exercise 6
实现fs/serv.c中的serve_write()和lib/file.c中的devfile_write()。
serve_write():
int
serve_write(envid_t envid, struct Fsreq_write *req)
{
if (debug)
cprintf("serve_write %08x %08x %08x\n", envid, req->req_fileid, req->req_n);
// LAB 5: Your code here.
struct OpenFile *o;
int r;
if ((r = openfile_lookup(envid, req->req_fileid, &o)) < 0) {
return r;
}
int total = 0;
while (1) {
r = file_write(o->o_file, req->req_buf, req->req_n, o->o_fd->fd_offset);
if (r < 0) return r;
total += r;
o->o_fd->fd_offset += r;
if (req->req_n <= total)
break;
}
return total;
}
devfile_write():客户端进程函数,包装一下参数,直接调用fsipc()将参数发送给FS进程处理。
static ssize_t
devfile_write(struct Fd *fd, const void *buf, size_t n)
{
// Make an FSREQ_WRITE request to the file system server. Be
// careful: fsipcbuf.write.req_buf is only so large, but
// remember that write is always allowed to write *fewer*
// bytes than requested.
// LAB 5: Your code here
int r;
fsipcbuf.write.req_fileid = fd->fd_file.id;
fsipcbuf.write.req_n = n;
memmove(fsipcbuf.write.req_buf, buf, n);
return fsipc(FSREQ_WRITE, NULL);
}
库函数open()实现
以打开一个文件为例,看下整体过程,read(), write()类似。open()在linux中也要实现定义在头文件<fcntl.h>中,原型如下:
int open(const char *pathname, int flags);
在JOS中open()实现在lib/file.c中,
int
open(const char *path, int mode)
{
// Find an unused file descriptor page using fd_alloc.
// Then send a file-open request to the file server.
// Include 'path' and 'omode' in request,
// and map the returned file descriptor page
// at the appropriate fd address.
// FSREQ_OPEN returns 0 on success, < 0 on failure.
//
// (fd_alloc does not allocate a page, it just returns an
// unused fd address. Do you need to allocate a page?)
//
// Return the file descriptor index.
// If any step after fd_alloc fails, use fd_close to free the
// file descriptor.
int r;
struct Fd *fd;
if (strlen(path) >= MAXPATHLEN) //文件名不能超过指定长度
return -E_BAD_PATH;
if ((r = fd_alloc(&fd)) < 0) //搜索当前进程未被分配的文件描述符
return r;
strcpy(fsipcbuf.open.req_path, path);
fsipcbuf.open.req_omode = mode;
if ((r = fsipc(FSREQ_OPEN, fd)) < 0) { //通过fsipc()向FS进程发起RPC调用
fd_close(fd, 0);
return r;
}
return fd2num(fd);
}
static int
fsipc(unsigned type, void *dstva) //type, fsipcbuf是发送给fs进程的数据。dstava和fsipc()的返回值是从fs进程接收的值
{
static envid_t fsenv;
if (fsenv == 0)
fsenv = ipc_find_env(ENV_TYPE_FS);
static_assert(sizeof(fsipcbuf) == PGSIZE);
ipc_send(fsenv, type, &fsipcbuf, PTE_P | PTE_W | PTE_U); //向FS进程发送数据
return ipc_recv(NULL, dstva, NULL); //接收FS进程发送回来的数据
}
其中fd_alloc()定义在lib/fd.c中,
int
fd_alloc(struct Fd **fd_store)
{
int i;
struct Fd *fd;
for (i = 0; i < MAXFD; i++) { //从当前最小的未分配描述符开始
fd = INDEX2FD(i);
if ((uvpd[PDX(fd)] & PTE_P) == 0 || (uvpt[PGNUM(fd)] & PTE_P) == 0) {
*fd_store = fd;
return 0;
}
}
*fd_store = 0;
return -E_MAX_OPEN;
}
%E5%8E%9F%E7%90%86.png)
每个进程从虚拟地址0xD0000000开始,每一页对应一个Fd结构,也就是说文件描述符0对应的Fd结构地址为0xD0000000,文件描述符1对应的Fd描述符结构地址为0xD0000000+PGSIZE(被定义为4096),以此类推,。可以通过检查某个Fd结构的虚拟地址是否已经分配,来判断这个文件描述符是否被分配。如果一个文件描述符被分配了,那么该文件描述符对应的Fd结构开始的一页将被映射到和FS进程相同的物理地址处。
FS进程收到FSREQ_OPEN请求后,将调用serve_open(),该函数定义在fs/serv.c中。
int
serve_open(envid_t envid, struct Fsreq_open *req,
void **pg_store, int *perm_store)
{
char path[MAXPATHLEN];
struct File *f;
int fileid;
int r;
struct OpenFile *o;
if (debug)
cprintf("serve_open %08x %s 0x%x\n", envid, req->req_path, req->req_omode);
// Copy in the path, making sure it's null-terminated
memmove(path, req->req_path, MAXPATHLEN);
path[MAXPATHLEN-1] = 0;
// Find an open file ID
if ((r = openfile_alloc(&o)) < 0) { //从opentab数组中分配一个OpenFile结构
if (debug)
cprintf("openfile_alloc failed: %e", r);
return r;
}
fileid = r;
// Open the file
if (req->req_omode & O_CREAT) {
if ((r = file_create(path, &f)) < 0) { //根据path分配一个File结构
if (!(req->req_omode & O_EXCL) && r == -E_FILE_EXISTS)
goto try_open;
if (debug)
cprintf("file_create failed: %e", r);
return r;
}
} else {
try_open:
if ((r = file_open(path, &f)) < 0) {
if (debug)
cprintf("file_open failed: %e", r);
return r;
}
}
// Truncate
if (req->req_omode & O_TRUNC) {
if ((r = file_set_size(f, 0)) < 0) {
if (debug)
cprintf("file_set_size failed: %e", r);
return r;
}
}
if ((r = file_open(path, &f)) < 0) {
if (debug)
cprintf("file_open failed: %e", r);
return r;
}
// Save the file pointer
o->o_file = f; //保存File结构到OpenFile结构
// Fill out the Fd structure
o->o_fd->fd_file.id = o->o_fileid;
o->o_fd->fd_omode = req->req_omode & O_ACCMODE;
o->o_fd->fd_dev_id = devfile.dev_id;
o->o_mode = req->req_omode;
if (debug)
cprintf("sending success, page %08x\n", (uintptr_t) o->o_fd);
// Share the FD page with the caller by setting *pg_store,
// store its permission in *perm_store
*pg_store = o->o_fd;
*perm_store = PTE_P|PTE_U|PTE_W|PTE_SHARE;
return 0;
}
该函数首先从opentab这个OpenFile数组中寻找一个未被使用的OpenFile结构,上图中假设找到数据第一个OpenFile结构就是未使用的。如果open()中参数mode设置了O_CREAT选项,那么会调用fs/fs.c中的file_create()根据路径创建一个新的File结构,并保存到OpenFile结构的o_file字段中。
结束后,serve()会将OpenFile结构对应的Fd起始地址发送个客户端进程,所以客户进程从open()返回后,新分配的Fd和FS进程Fd共享相同的物理页。
Spawning Processes
lib/spawn.c中的spawn()创建一个新的进程,从文件系统加载用户程序,然后启动该进程来运行这个程序。spawn()就像UNIX中的fork()后面马上跟着exec()。
spawn(const char *prog, const char **argv)做如下一系列动作:
- 从文件系统打开prog程序文件
- 调用系统调用sys_exofork()创建一个新的Env结构
- 调用系统调用sys_env_set_trapframe(),设置新的Env结构的Trapframe字段(该字段包含寄存器信息)。
- 根据ELF文件中program herder,将用户程序以Segment读入内存,并映射到指定的线性地址处。
- 调用系统调用sys_env_set_status()设置新的Env结构状态为ENV_RUNNABLE。
Exercise 7
实现sys_env_set_trapframe()系统调用。
static int
sys_env_set_trapframe(envid_t envid, struct Trapframe *tf)
{
// LAB 5: Your code here.
// Remember to check whether the user has supplied us with a good
// address!
int r;
struct Env *e;
if ((r = envid2env(envid, &e, 1)) < 0) {
return r;
}
tf->tf_eflags = FL_IF;
tf->tf_eflags &= ~FL_IOPL_MASK; //普通进程不能有IO权限
tf->tf_cs = GD_UT | 3;
e->env_tf = *tf;
return 0;
}
Sharing library state across fork and spawn
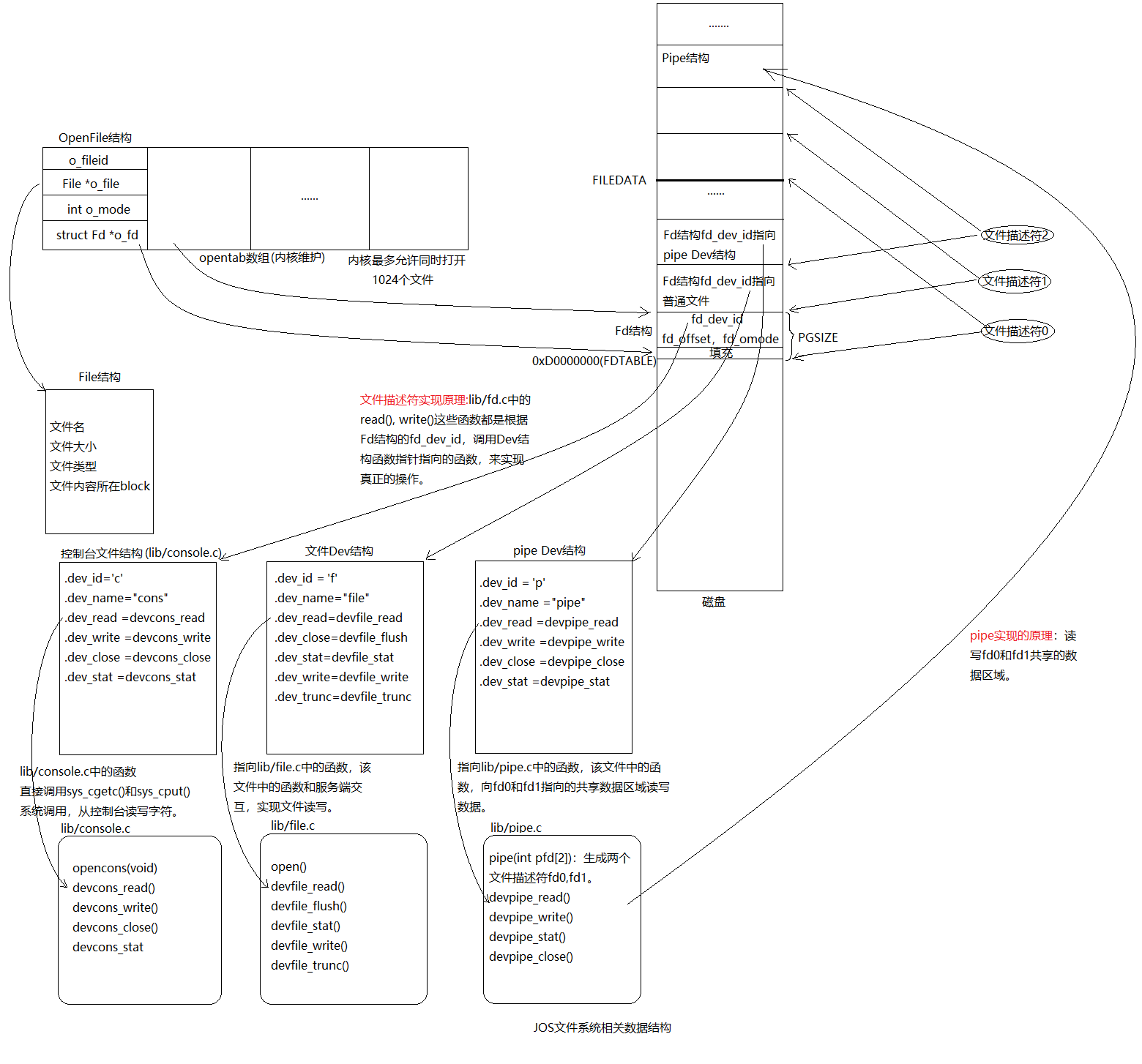
UNIX文件描述符是一个大的概念,包含pipe,控制台I/O。在JOS中每种设备对应一个struct Dev结构,该结构包含函数指针,指向真正实现读写操作的函数。
lib/fd.c文件实现了UNIX文件描述符接口,但大部分函数都是简单对struct Dev结构指向的函数的包装。
我们希望共享文件描述符,JOS中定义PTE新的标志位PTE_SHARE,如果有个页表条目的PTE_SHARE标志位为1,那么这个PTE在fork()和spawn()中将被直接拷贝到子进程页表,从而让父进程和子进程共享相同的页映射关系,从而达到父子进程共享文件描述符的目的。
Exercise 8
修改lib/fork.c中的duppage(),使之正确处理有PTE_SHARE标志的页表条目。同时实现lib/spawn.c中的copy_shared_pages()。
static int
duppage(envid_t envid, unsigned pn)
{
int r;
// LAB 4: Your code here.
void *addr = (void*) (pn * PGSIZE);
if (uvpt[pn] & PTE_SHARE) {
sys_page_map(0, addr, envid, addr, PTE_SYSCALL); //对于标识为PTE_SHARE的页,拷贝映射关系,并且两个进程都有读写权限
} else if ((uvpt[pn] & PTE_W) || (uvpt[pn] & PTE_COW)) { //对于UTOP以下的可写的或者写时拷贝的页,拷贝映射关系的同时,需要同时标记当前进程和子进程的页表项为PTE_COW
if ((r = sys_page_map(0, addr, envid, addr, PTE_COW|PTE_U|PTE_P)) < 0)
panic("sys_page_map:%e", r);
if ((r = sys_page_map(0, addr, 0, addr, PTE_COW|PTE_U|PTE_P)) < 0)
panic("sys_page_map:%e", r);
} else {
sys_page_map(0, addr, envid, addr, PTE_U|PTE_P); //对于只读的页,只需要拷贝映射关系即可
}
return 0;
}
copy_shared_pages()
static int
copy_shared_pages(envid_t child)
{
// LAB 5: Your code here.
uintptr_t addr;
for (addr = 0; addr < UTOP; addr += PGSIZE) {
if ((uvpd[PDX(addr)] & PTE_P) && (uvpt[PGNUM(addr)] & PTE_P) &&
(uvpt[PGNUM(addr)] & PTE_U) && (uvpt[PGNUM(addr)] & PTE_SHARE)) {
sys_page_map(0, (void*)addr, child, (void*)addr, (uvpt[PGNUM(addr)] & PTE_SYSCALL));
}
}
return 0;
}
The Shell
运行make run-icode,将会执行user/icode,user/icode又会执行inti,然后会spawn sh。然后就能运行如下指令:
echo hello world | cat
cat lorem |cat
cat lorem |num
cat lorem |num |num |num |num |num
lsfd
Exercise 10
目前shell还不支持IO重定向,修改user/sh.c,增加IO该功能。
runcmd(char* s) {
...
if ((fd = open(t, O_RDONLY)) < 0) {
cprintf("open %s for write: %e", t, fd);
exit();
}
if (fd != 0) {
dup(fd, 0);
close(fd);
}
...
}
总结回顾
- 构建文件系统:
- 引入一个文件系统进程的特殊进程,该进程提供文件操作的接口。具体实现在fs/bc.c,fs/fs.c,fs/serv.c中。
- 建立RPC机制,客户端进程向FS进程发送请求,FS进程真正执行文件操作。客户端进程的实现在lib/file.c,lib/fd.c中。客户端进程和FS进程交互可总结为下图:
![客户端进程和FS进程交互]()
- 更高级的抽象,引入文件描述符。通过文件描述符这一层抽象就可以将控制台,pipe,普通文件,统统按照文件来对待。文件描述符和pipe的原理总结如下:
![文件描述符和pipe原理]()
- 支持从磁盘加载程序并运行。实现spawn(),该函数创建一个新的进程,并从磁盘加载程序运行,类似UNIX中的fork()后执行exec()。
具体代码在:https://github.com/gatsbyd/mit_6.828_jos
如有错误,欢迎指正(_):
15313676365

 浙公网安备 33010602011771号
浙公网安备 33010602011771号