

LevelDb-基本数据结构
Slice
实现在slice.cc
class LEVELDB_EXPORT Slice {
...
void clear() {
data_ = "";
size_ = 0;
}
void remove_prefix(size_t n) {
assert(n <= size());
data_ += n;
size_ -= n;
}
private:
const char* data_;
size_t size_;
};
从Slice对外提供的接口看,Slice只是一个容器,不负责理解内容,具体data_对应的内存,释放完全有调用者处理。
使用默认拷贝构造,拷贝复制运算符。
Arena
实现在arena.cc
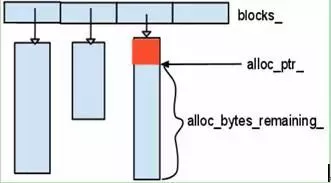
class Arena {
public;
char* Allocate(size_t bytes);
char* AllocateAligned(size_t bytes);
private:
char* alloc_ptr_;
size_t alloc_bytes_remaining_;
std::vector<char*> blocks_;
std::atomic<size_t> memory_usage_;
简单的内存池,分配的内存在析构函数中回收。对外提供两个内存分配接口,其中一个提供内存对齐能力。
skip list
实现在skiplist.cc
跳表提供的功能:
- 插入,删除,查找元素。
- 有序。支持按区间查找元素。
跳表本质
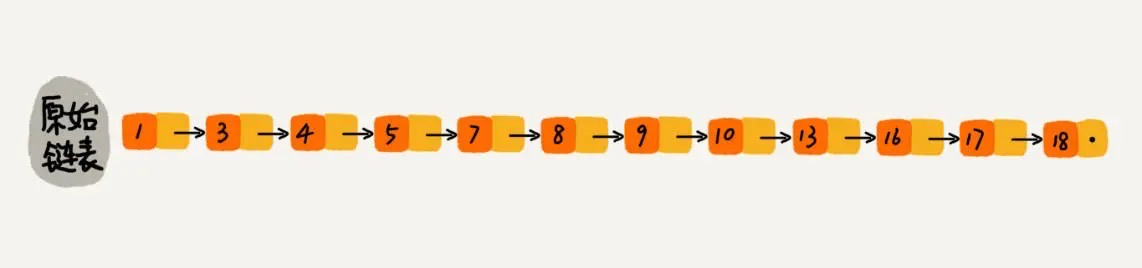
在链表上实现二分查找。因为不能想连续内存一样直接二分查找,增加索引信息。
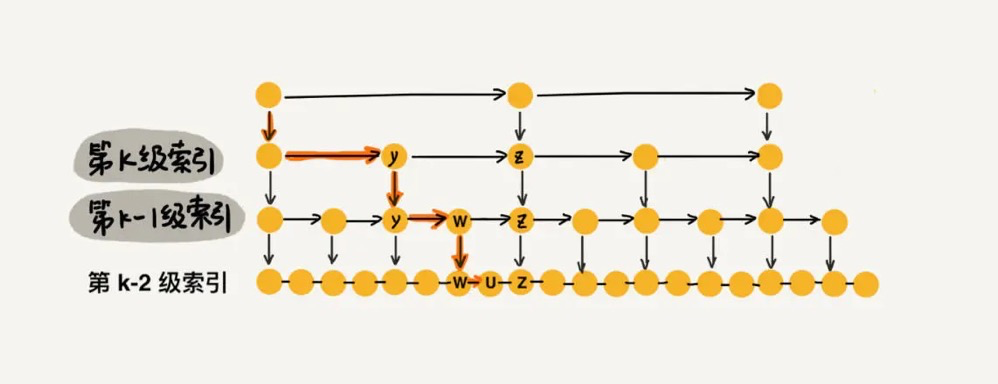
时空复杂度
每两个节点作为一个索引:
- 空间复杂度:索引高度O(logn)。跳表的索引高度 h = log2n,且每层索引最多遍历 3 个元素。所以跳表中查找一个元素的时间复杂度为 O(3*logn),省略常数即:O(logn)
- 空间复杂度:O(N)。假如原始链表包含 n 个元素,则一级索引元素个数为 n/2、二级索引元素个数为 n/4、三级索引元素个数为 n/8 以此类推。所以,索引节点的总和是:n/2 + n/4 + n/8 + … + 8 + 4 + 2 = n-2,空间复杂度是 O(n)。
插入,删除数据(如何维护索引)
极端情况分析:不维护索引
慢慢退化成链表
极端情况分析:每次插入都维护
每一级索引都要插入当前元素,时间复杂度O(logn)
插入效率和查找效率取舍
按概率插入到第n级及其以下级索引中。第一级索引概率1/2,第二级概率1/4,以此类推,越高级索引被更新概率越低。
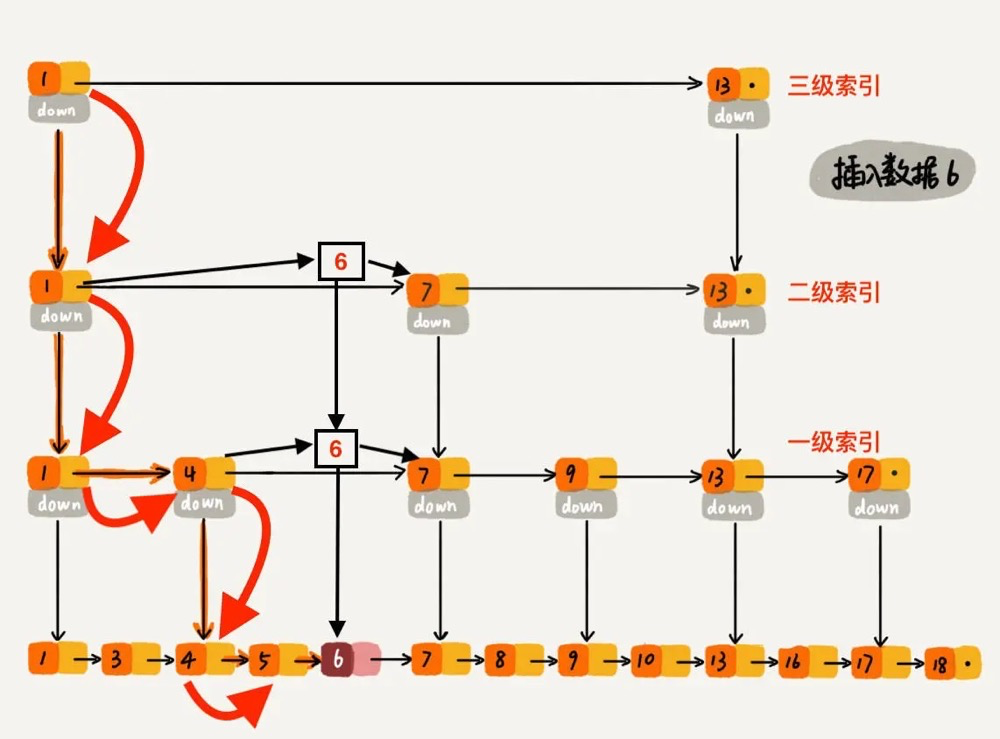
如上图,插入元素6,根据概率需要插入到第2级索引中,这样第3级索引就不用更新了。
删除
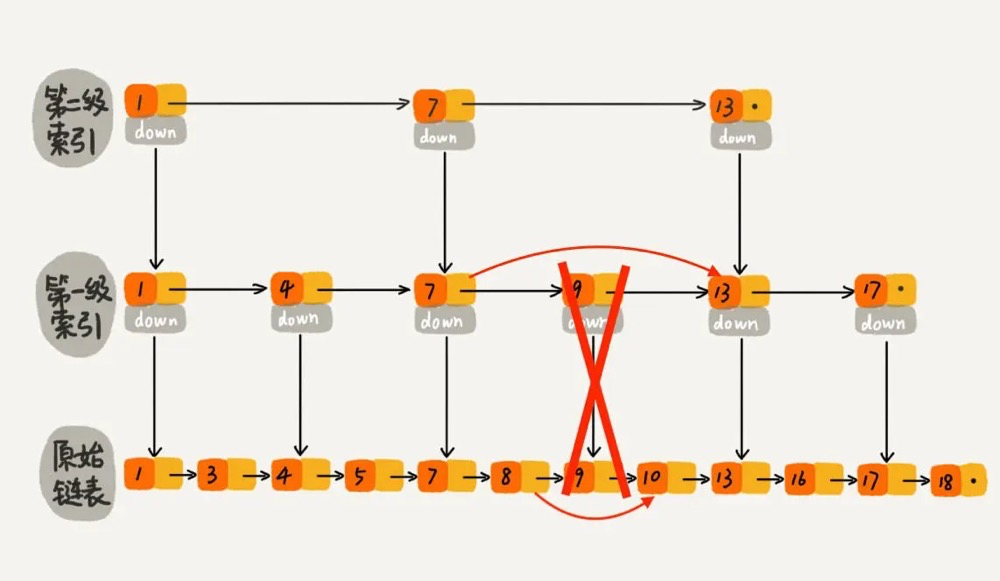
每一级索引如果有该元素,都需要删除。
对比红黑树的优势
- 实现简单
- 可以控制n个节点维护一个索引参数,从而做性能和空间trade-off
- 多线程环境下更友好
- 程序局部性更好(如何理解)
leveldb实现
Write:在修改跳表时,需要在用户代码侧加锁。
Read:在访问跳表(查找、遍历)时,只需保证跳表不被其他线程销毁即可,不必额外加锁。
插入
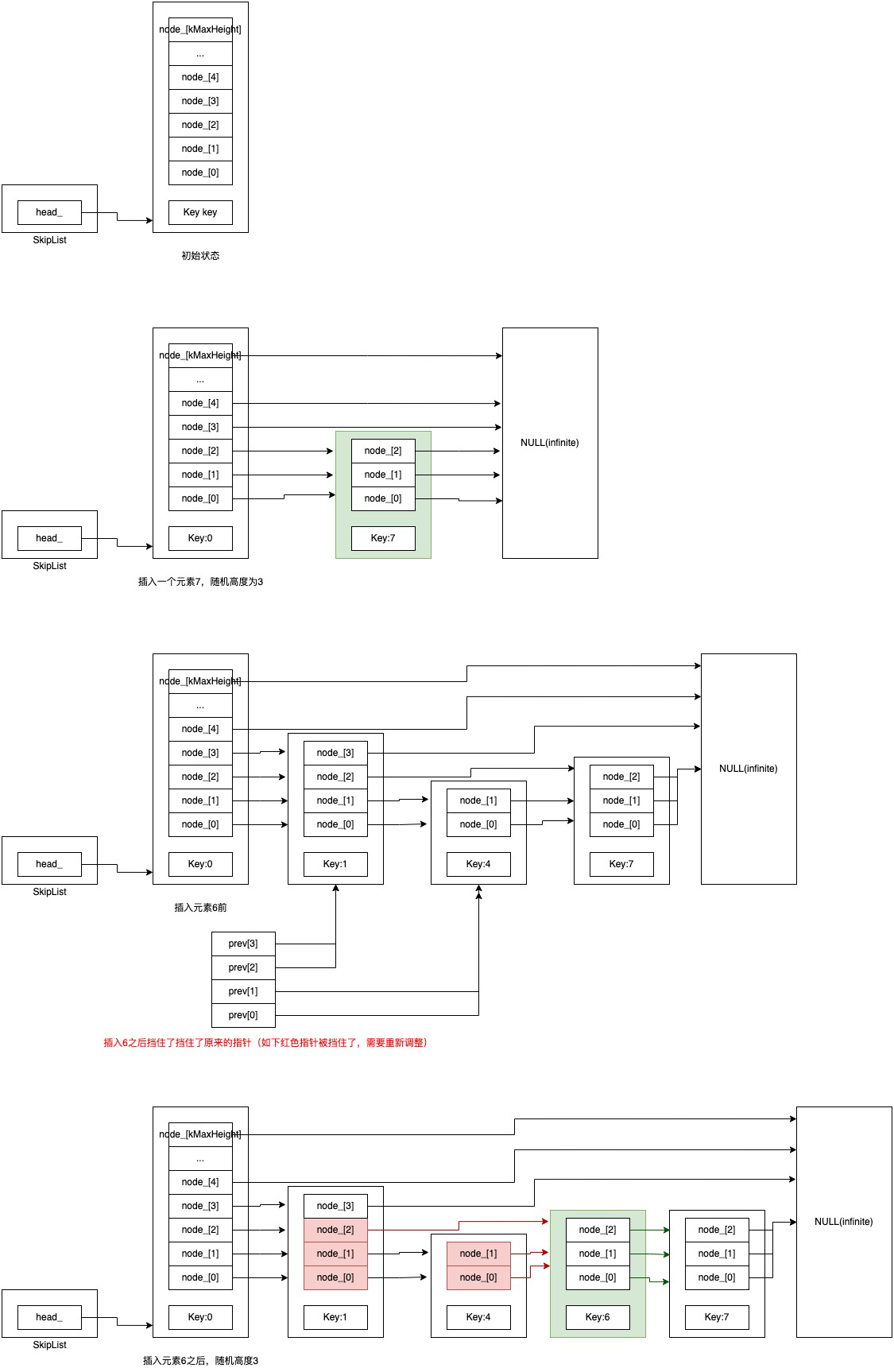
上图演示了两种情况:
- 初始状态,插入key=7的元素。
- 插入key=6的元素前后的状态变化。
对应的代码如下:
template <typename Key, class Comparator>
typename SkipList<Key, Comparator>::Node*
SkipList<Key, Comparator>::FindGreaterOrEqual(const Key& key,
Node** prev) const {
Node* x = head_;
int level = GetMaxHeight() - 1;
while (true) {
Node* next = x->Next(level);
if (KeyIsAfterNode(key, next)) {
// Keep searching in this list
x = next; //从左往右遍历
} else {
if (prev != nullptr) prev[level] = x;
if (level == 0) {
return next;
} else {
// Switch to next list
level--; //从上往下遍历
}
}
}
}
template <typename Key, class Comparator>
bool SkipList<Key, Comparator>::KeyIsAfterNode(const Key& key, Node* n) const {
// null n is considered infinite
return (n != nullptr) && (compare_(n->key, key) < 0);
}
总体的策略是:
- 两个指针,x指针指向当前节点,next指针指向下个要比较的节点。
- 从左往右遍历。什么情况下结束:遇到比当前key大的节点(NULL指针理解为无限大),对应KeyIsAfterNode方法。
- 从上往下遍历。
找到插入的位置后,需要调整指针:
- 原有节点。比如图中的红色的线。一句话总解就是:新插入节点挡住了原来哪些指针,被挡住的指针都需要调整,指向新插入的节点。
- 插入节点指针。图中绿色的线。
对应代码如下:
int height = RandomHeight();
if (height > GetMaxHeight()) {
for (int i = GetMaxHeight(); i < height; i++) {
prev[i] = head_;
}
// It is ok to mutate max_height_ without any synchronization
// with concurrent readers. A concurrent reader that observes
// the new value of max_height_ will see either the old value of
// new level pointers from head_ (nullptr), or a new value set in
// the loop below. In the former case the reader will
// immediately drop to the next level since nullptr sorts after all
// keys. In the latter case the reader will use the new node.
max_height_.store(height, std::memory_order_relaxed);
}
x = NewNode(key, height);
for (int i = 0; i < height; i++) {
// NoBarrier_SetNext() suffices since we will add a barrier when
// we publish a pointer to "x" in prev[i].
x->NoBarrier_SetNext(i, prev[i]->NoBarrier_Next(i));
prev[i]->SetNext(i, x);
}
并发处理
LevelDB的跳表实现支持单线程写、多线程读。
怎么理解支持单线程写、多线程读
还是以上面演示的为例,线程1插入key:6,同时线程2和线程3读key:6和key:7。在线程1将key:6完全插入前(指针索引建立完毕前),线程2查不到key:6,线程3能查到key:7。
如果有两个线程同时写数据,该类不保证行为符合预期。
TODO:
return new (node_memory) Node(key) 是什么用法?
为什么泛型变量key可以传0?
memory order
Relaxed ordering
只保证操作原子性(操作变量的指令不进行重排序),不能提供同步机制。
举个例子:
#include <vector>
#include <iostream>
#include <thread>
#include <atomic>
//std::atomic<int> cnt = {0};
int cnt = 0;
void f()
{
for (int n = 0; n < 1000; ++n) {
//cnt.fetch_add(1, std::memory_order_relaxed);
cnt++;
}
}
int main()
{
std::vector<std::thread> v;
for (int n = 0; n < 10; ++n) {
v.emplace_back(f);
}
for (auto& t : v) {
t.join();
}
std::cout << "Final counter value is " << cnt << '\n';
}
执行结果并非预期的10000,每次执行都不一样且小于等于10000。
问题在于i++,在高级语义看来是一个执行单元,但是cpu执行的时候i++是分成多步的。参考如下代码:
void test() {
int cnt = 0;
cnt++;
}
反汇编后
push rbp
mov rbp, rsp
mov dword ptr [rbp - 4], 0
mov eax, dword ptr [rbp - 4] //将cnt变量从内存拷贝到eax寄存器
add eax, 1 //对eax执行+1
mov dword ptr [rbp - 4], eax //将eax寄存器中的值重新拷贝到内存
pop rbp
ret
可以看到i++实际分为三步。在多线程环境下很可能出现如下情况:
thread A: thread B:
mov eax, dword ptr [rbp - 4]
add eax, 1 mov eax, dword ptr [rbp - 4]
mov dword ptr [rbp - 4], eax add eax, 1
mov dword ptr [rbp - 4], eax
假设cnt初值是0,线程A执行第二步add eax, 1后,寄存器eax中值为1,此时线程B开始执行了,将cnt从内存加载到寄存器eax,将线程A的+1后的结果覆盖了。所以最终cnt的值为1,而不是2。
使用std::memory_order_relaxed内存序可保证+1操作原子性。
#include <vector>
#include <iostream>
#include <thread>
#include <atomic>
std::atomic<int> cnt = {0};
//int cnt = 0;
void f()
{
for (int n = 0; n < 1000; ++n) {
cnt.fetch_add(1, std::memory_order_relaxed);
//cnt++;
}
}
int main()
{
std::vector<std::thread> v;
for (int n = 0; n < 10; ++n) {
v.emplace_back(f);
}
for (auto& t : v) {
t.join();
}
std::cout << "Final counter value is " << cnt << '\n';
}
Relaxed内存序不能保证同步,如下代码可能出现r1 == r2 == 42的情况。
// Thread 1:
r1 = y.load(std::memory_order_relaxed); // A
x.store(r1, std::memory_order_relaxed); // B
// Thread 2:
r2 = x.load(std::memory_order_relaxed); // C
y.store(42, std::memory_order_relaxed); // D
Release-Acquire ordering
CPU为了提高效率使用了指令重排技术,参考如下例子:
// 公共资源
int x = 0;
int y = 0;
int z = 0;
Thread_1: Thread_2:
x = 100; while (y != 200);
y = 200; print x
z = x + y;
x=100;和y=200;这两条指令完全有可能被CPU重排序,先执行y=200;,从线程1内部看没有什么影响,但是在线程2看来,如果未发生重排序x将打印100,如果发生了重排序,x将打印0。
release-acquire内存序可以实现线程间的同步机制。参考下面的例子:
#include <thread>
#include <atomic>
#include <cassert>
#include <string>
#include <iostream>
#include <chrono>
std::atomic<std::string*> ptr;
int data;
void producer()
{
std::string* p = new std::string("Hello"); #1
data = 42; #2
ptr.store(p, std::memory_order_release);
}
void consumer()
{
std::string* p2;
while (!(p2 = ptr.load(std::memory_order_acquire)))
;
assert(*p2 == "Hello"); // never fires #3
assert(data == 42); // never fires #4
}
int main()
{
std::thread t1(producer);
std::thread t2(consumer);
std::thread t3(consumer);
t1.join(); t2.join(); t3.join();
}
一旦consumer线程对ptr使用std::memory_order_acquire load完毕,那么consumer线程能看到producer线程ptr store之前所有写到内存的值(That is, once the atomic load is completed, thread B is guaranteed to see everything thread A wrote to memory)
如例子所示,store 使用 memory_order_release,load 使用memory_order_acquire,CPU 将保证如下两点:
- store 之前的语句不允许被重排序到 store 之后(例子中的 #1 和 #2 语句一定在 store 之前执行)
- load 之后的语句不允许被重排序到 load 之前(例子中的 #3 和 #4 一定在 load 之后执行)
同时 CPU 将保证 store 之前的语句比 load 之后的语句「先行发生」,即先执行 #1、#2,然后执行 #3、#4。这实际上就意味着线程 1 中 store 之前的读写操作对线程 2 中 load 执行后是可见的。
Release-Consume ordering
Release-Consume内存模型和Release-Acquire类似,比Release-Acquire要弱一些,但是更高效。
#include <thread>
#include <atomic>
#include <cassert>
#include <string>
std::atomic<std::string*> ptr;
int data;
void producer()
{
std::string* p = new std::string("Hello"); #1
data = 42; #2
ptr.store(p, std::memory_order_release);
}
void consumer()
{
std::string* p2;
while (!(p2 = ptr.load(std::memory_order_consume)))
;
assert(*p2 == "Hello"); // never fires: *p2 carries dependency from ptr #3
assert(data == 42); // may or may not fire: data does not carry dependency from ptr #4
}
int main()
{
std::thread t1(producer);
std::thread t2(consumer);
t1.join(); t2.join();
}
还是刚才的例子,只是换成了ptr.load(std::memory_order_consume),这时只能保证对ptr的访问#3不会重排序到ptr.load(std::memory_order_consume)之前,但是并不能保证对data的访问不会排序到ptr.load(std::memory_order_consume)之前,所以data不一定是42。
LevelDb中跳表的并发处理
涉及到并发处理一个地方是max_height_字段:
inline int GetMaxHeight() const {
return max_height_.load(std::memory_order_relaxed);
}
max_height_.store(height, std::memory_order_relaxed);
这里只用到了Relaxed内存序。也就是说读写线程没有任何同步机制。假设某个写线程更新了max_height_,分如下两种情况:
- 节点真正插入到链表中了。这种情况显然是正确的。
- 指针关系还没建立好,节点还未插入到链表中。这种情况读线程拿到的height对应的level指针是NULL,查找过程自然会跳过,所以也不影响。
第二个涉及并发处理的是建立索引关系的地方:
x = NewNode(key, height);
for (int i = 0; i < height; i++) {
// NoBarrier_SetNext() suffices since we will add a barrier when
// we publish a pointer to "x" in prev[i].
x->NoBarrier_SetNext(i, prev[i]->NoBarrier_Next(i)); #1
prev[i]->SetNext(i, x); #2
}
void SetNext(int n, Node* x) {
assert(n >= 0);
// Use a 'release store' so that anybody who reads through this
// pointer observes a fully initialized version of the inserted node.
next_[n].store(x, std::memory_order_release);
}
// Accessors/mutators for links. Wrapped in methods so we can
// add the appropriate barriers as necessary.
Node* Next(int n) {
assert(n >= 0);
// Use an 'acquire load' so that we observe a fully initialized
// version of the returned Node.
return next_[n].load(std::memory_order_acquire);
}
void NoBarrier_SetNext(int n, Node* x) {
assert(n >= 0);
next_[n].store(x, std::memory_order_relaxed);
}
Node* NoBarrier_Next(int n) {
assert(n >= 0);
return next_[n].load(std::memory_order_relaxed);
}
Node的SetNext和Next接口中访问各level指针是通过Release-Acquire内存序来实现的,NoBarrier_SetNext和NoBarrier_Next接口通过Relaxed内存序实现。为什么?
1和2分别对应下图更新红色指针,和绿色指针的地方。
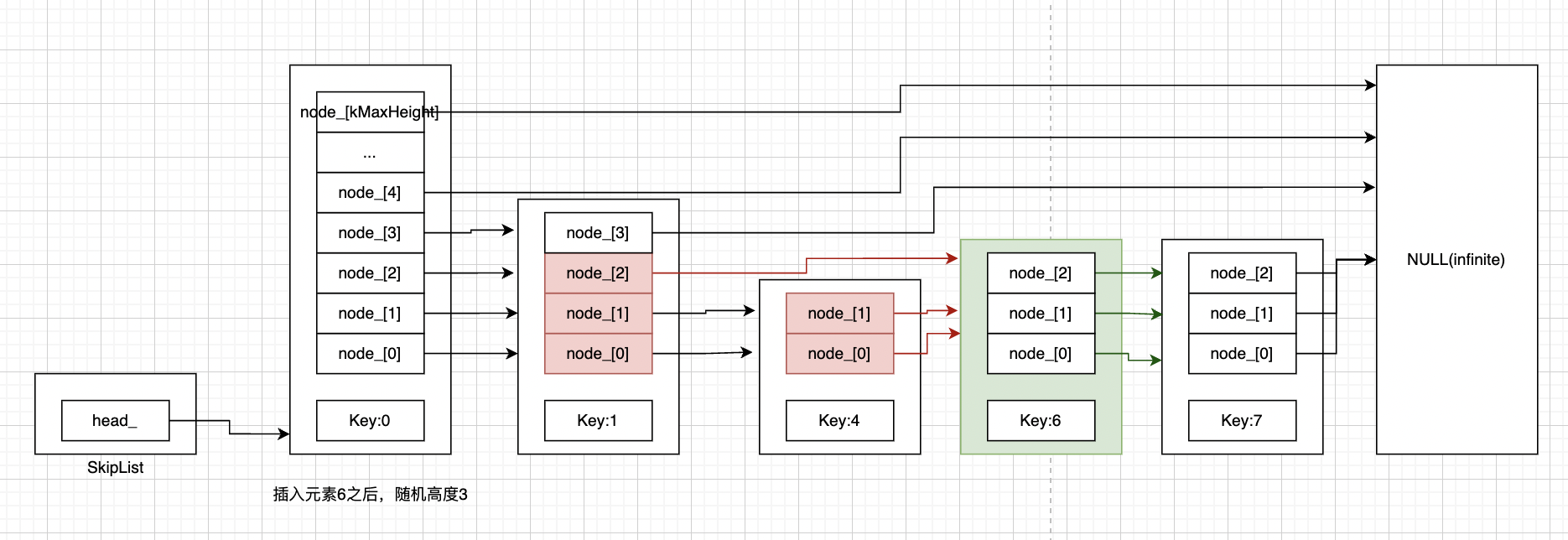
1处更新绿色指针,更新完后key:6的节点还没串到链表上,更新绿色指针的时候不被读线程读取到也没关系。
2处更新红色指针,更新完后key:6的节点将正式串到链表上,这个时候就需要让读线程能尽快感知到,所以用Release-Acquire内存序来实现。
参考资料:
skip list
memory_order

