
评分卡系列(四):泛化误差估计和模型调参
作者:JSong,时间:2017.10.21
本文大量引用了 jasonfreak 的系列文章,在此进行注明和感谢.
广义的偏差(bias)描述的是预测值和真实值之间的差异,方差(variance)描述的是不同样本下模型效果的离散程度。在《Understanding the Bias-Variance Tradeoff》当中有一副图形象地向我们展示了偏差和方差的关系:
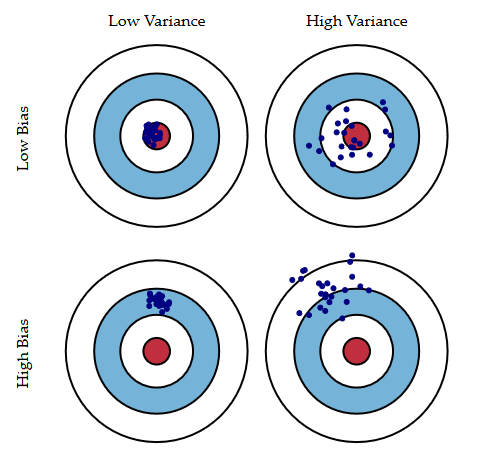
一、Bias-variance 分解
算法在不同训练集上学到的结果很可能不同,即便这些训练集来自于同一分布。对测试样本 x ,令 y_D 为 x 在数据集中的标记,y 为 x 的真实标记, f(x;D) 为训练集 D 上学的模型 f 在 x 上的预测输出。
在回归任务中,学习算法的期望输出为:
使用样本数相同的不同训练集产生的方差为:
噪声为
我们将期望输出与真实标记之间的差别称为偏差(bias):
为便于讨论,假定噪声期望为零,即
通过简单的多项式展开合并,对算法的期望泛化误差进行分解:
于是有
也就是说,泛化误差可分解为偏差、方差与噪声之和。
偏差和方差是有冲突的,下面是一个示意图。在训练不足(模型复杂度低)时,偏差主导了泛化误差率;随着训练程度的加深,方差逐渐主导了泛化误差率。
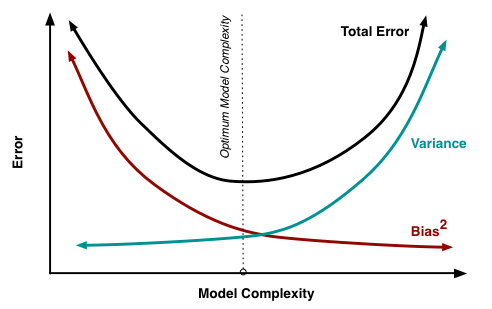
二、集成学习框架下的泛化误差分解
在 bagging 和 boosting 框架中,通过计算基模型的期望和方差,我们可以得到模型整体的期望和方差。为了简化模型,我们假设基模型的权重、方差及两两间的相关系数相等。由于bagging和boosting的基模型都是线性组成的,那么有:
和
2.1 bagging 的偏差和方差
对于bagging来说,每个基模型的权重等于 1/m 且期望近似相等(子训练集都是从原训练集中进行子抽样),故我们可以进一步化简得到:
和
根据上式我们可以看到,整体模型的期望近似于基模型的期望,这也就意味着整体模型的偏差和基模型的偏差近似。同时,整体模型的方差小于等于基模型的方差(当相关性为1时取等号),随着基模型数(m)的增多,整体模型的方差减少,从而防止过拟合的能力增强,模型的准确度得到提高。但是,模型的准确度一定会无限逼近于1吗?并不一定,当基模型数增加到一定程度时,方差公式第二项的改变对整体方差的作用很小,防止过拟合的能力达到极限,这便是准确度的极限了。另外,在此我们还知道了为什么bagging中的基模型一定要为强模型,否则就会导致整体模型的偏差度低,即准确度低。
Random Forest是典型的基于bagging框架的模型,其在bagging的基础上,进一步降低了模型的方差。Random Fores中基模型是树模型,在树的内部节点分裂过程中,不再是将所有特征,而是随机抽样一部分特征纳入分裂的候选项。这样一来,基模型之间的相关性降低,从而在方差公式中,第一项显著减少,第二项稍微增加,整体方差仍是减少。
2.2 boosting 的偏差和方差
对于boosting来说,基模型的训练集抽样是强相关的,那么模型的相关系数近似等于1,故我们也可以针对boosting化简公式为:
和
通过观察整体方差的表达式,我们容易发现,若基模型不是弱模型,其方差相对较大,这将导致整体模型的方差很大,即无法达到防止过拟合的效果。因此,boosting框架中的基模型必须为弱模型。
因为基模型为弱模型,导致了每个基模型的准确度都不是很高(因为其在训练集上的准确度不高)。随着基模型数的增多,整体模型的期望值增加,更接近真实值,因此,整体模型的准确度提高。但是准确度一定会无限逼近于1吗?仍然并不一定,因为训练过程中准确度的提高的主要功臣是整体模型在训练集上的准确度提高,而随着训练的进行,整体模型的方差变大,导致防止过拟合的能力变弱,最终导致了准确度反而有所下降。
基于boosting框架的 Gradient Tree Boosting 模型中基模型也为树模型,同 Random Forrest,我们也可以对特征进行随机抽样来使基模型间的相关性降低,从而达到减少方差的效果。
2.3 总结一下:bagging & boosting
调参的最终目的在于:模型在训练集上的准确度和防止过拟合能力的大和谐!
-
使用模型的偏差和方差来描述其在训练集上的准确度和防止过拟合的能力
-
对于bagging来说,整体模型的偏差和基模型近似,随着训练的进行,整体模型的方差降低
-
对于boosting来说,整体模型的初始偏差较高,方差较低,随着训练的进行,整体模型的偏差降低(虽然也不幸地伴随着方差增高),当训练过度时,因方差增高,整体模型的准确度反而降低.
-
整体模型的偏差和方差与基模型的偏差和方差息息相关
三、常见分类模型及其参数介绍
本文介绍的都是 scikit-learn 中的模型。
3.1 逻辑回归模型
在scikit-learn中,与逻辑回归有关的主要是这3个类。
logisticRegressionLogisticRegressionCVlogistic_regression_path
其中LogisticRegression和LogisticRegressionCV的主要区别是LogisticRegressionCV使用了交叉验证来选择正则化系数C。而LogisticRegression需要自己每次指定一个正则化系数。另外logistic_regression_path类则比较特殊,它拟合数据后,不能直接来做预测,只能为拟合数据选择合适逻辑回归的系数和正则化系数,主要是用在模型选择的时候,一般情况用不到这个类,所以后面不再讲述logistic_regression_path类。
LogisticRegression 的参数使用如下:
class sklearn.linear_model.LogisticRegression(penalty='l2', dual=False, tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver='liblinear', max_iter=100, multi_class='ovr', verbose=0, warm_start=False, n_jobs=1)
具体含义为:

3.2 集成学习模型
在scikit-learn中,与随机森林有关的有两个。
- RandomForestClassifier(): A random forest classifier.
- RandomForestRegressor(): A random forest regressor.
这里主要讲第一个,它的参数如下:
class sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=’auto’, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, bootstrap=True, oob_score=False, n_jobs=1, random_state=None, verbose=0, warm_start=False, class_weight=None)
与GBDT有关的也是两个。
- GradientBoostingClassifier([loss, …]): Gradient Boosting for classification.
- GradientBoostingRegressor([loss, …]): Gradient Boosting for regression.
其中分类模型的参数如下:
class sklearn.ensemble.GradientBoostingClassifier(loss=’deviance’, learning_rate=0.1, n_estimators=100, subsample=1.0, criterion=’friedman_mse’, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_depth=3, min_impurity_decrease=0.0, min_impurity_split=None, init=None, random_state=None, max_features=None, verbose=0, max_leaf_nodes=None, warm_start=False, presort=’auto’)
这两个模型参数的详细介绍如下:
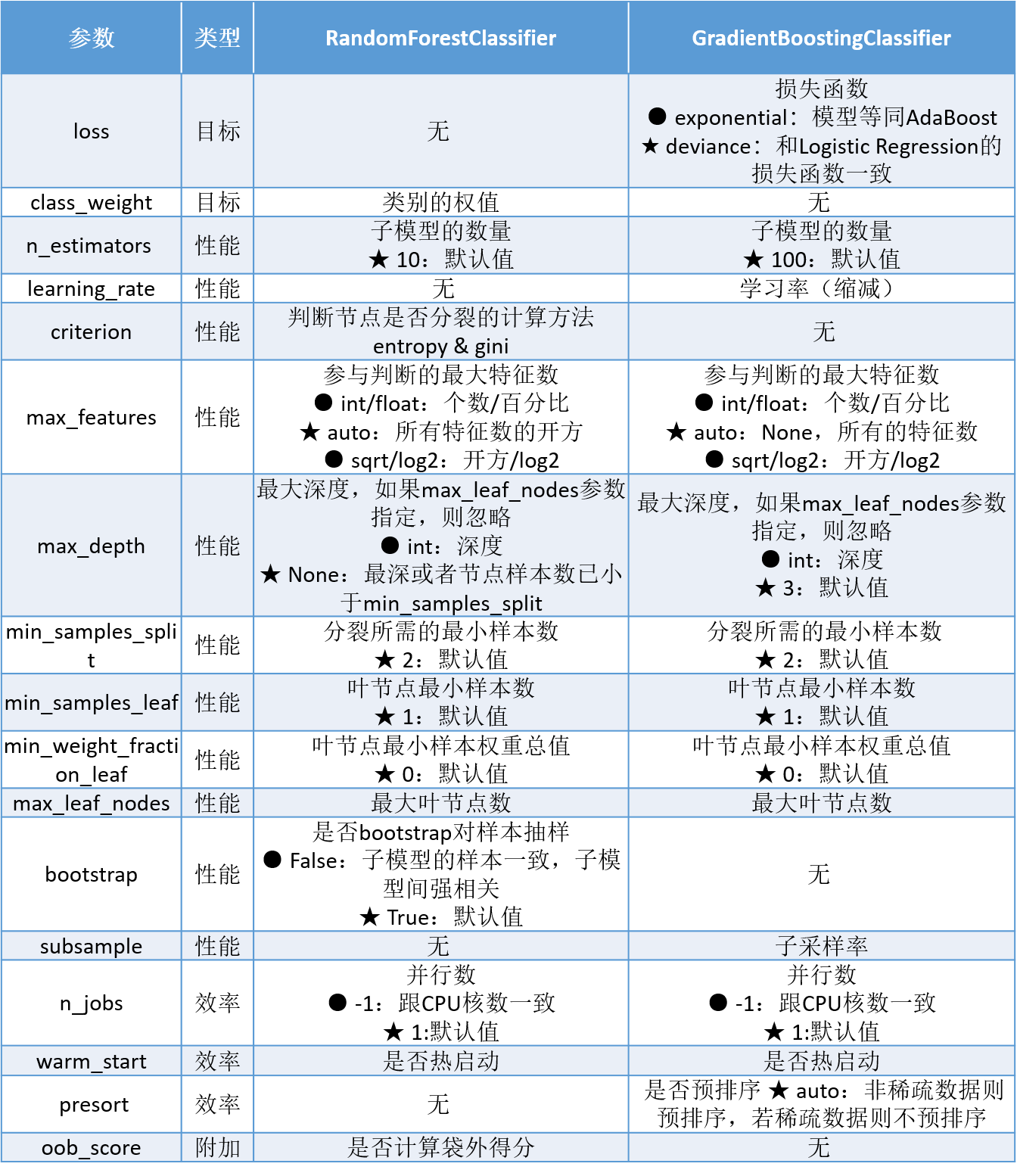
在上一节我们对bagging和boosting两种集成学习技术的泛化误差估计有了初步的了解。Random Forest的子模型都拥有较低的偏差,整体模型的训练过程旨在降低方差,故其需要较少的子模型(n_estimators默认值为10)且子模型不为弱模型(max_depth的默认值为None),同时,降低子模型间的相关度可以起到减少整体模型的方差的效果(max_features的默认值为auto)。
另一方面,Gradient Tree Boosting的子模型都拥有较低的方差,整体模型的训练过程旨在降低偏差,故其需要较多的子模型(n_estimators默认值为100)且子模型为弱模型(max_depth的默认值为3),但是降低子模型间的相关度不能显著减少整体模型的方差(max_features的默认值为None)。
四、分类模型的调参方法
调参是一个最优化问题。如果样本量不是非常大,计算资源也足够,那我们可以直接用网格搜索进行穷举。例如在随机森林算法中,可以用sklearn提供的GridSearchCV函数来调参。
param_test1 ={'n_estimators':range(10,71,10),'max_features':range(20,50,1)}
gsearch1= GridSearchCV(estimator =RandomForestClassifier(min_samples_split=100,
min_samples_leaf=20,max_depth=8,random_state=10),
param_grid =param_test1,scoring='roc_auc',cv=5)
gsearch1.fit(X,y)
gsearch1.grid_scores_, gsearch1.best_params_, gsearch1.best_score_
对于小数据集,我们还能这么任性,但是参数组合爆炸,在大数据集上,如果用网格搜索,那真的要下一个猴年马月才能看到结果了。而且实际上网格搜索也不一定能得到全局最优解,而另一些研究者从解优化问题的角度尝试解决调参问题。
坐标下降法是一类非梯度优化算法。算法在每次迭代中,在当前点处沿一个坐标方向进行一维搜索以求得一个函数的局部极小值。在整个过程中循环使用不同的坐标方向。对于不可拆分的函数而言,算法可能无法在较小的迭代步数中求得最优解。为了加速收敛,可以采用一个适当的坐标系,例如通过主成分分析获得一个坐标间尽可能不相互关联的新坐标系(如自适应坐标下降法)。
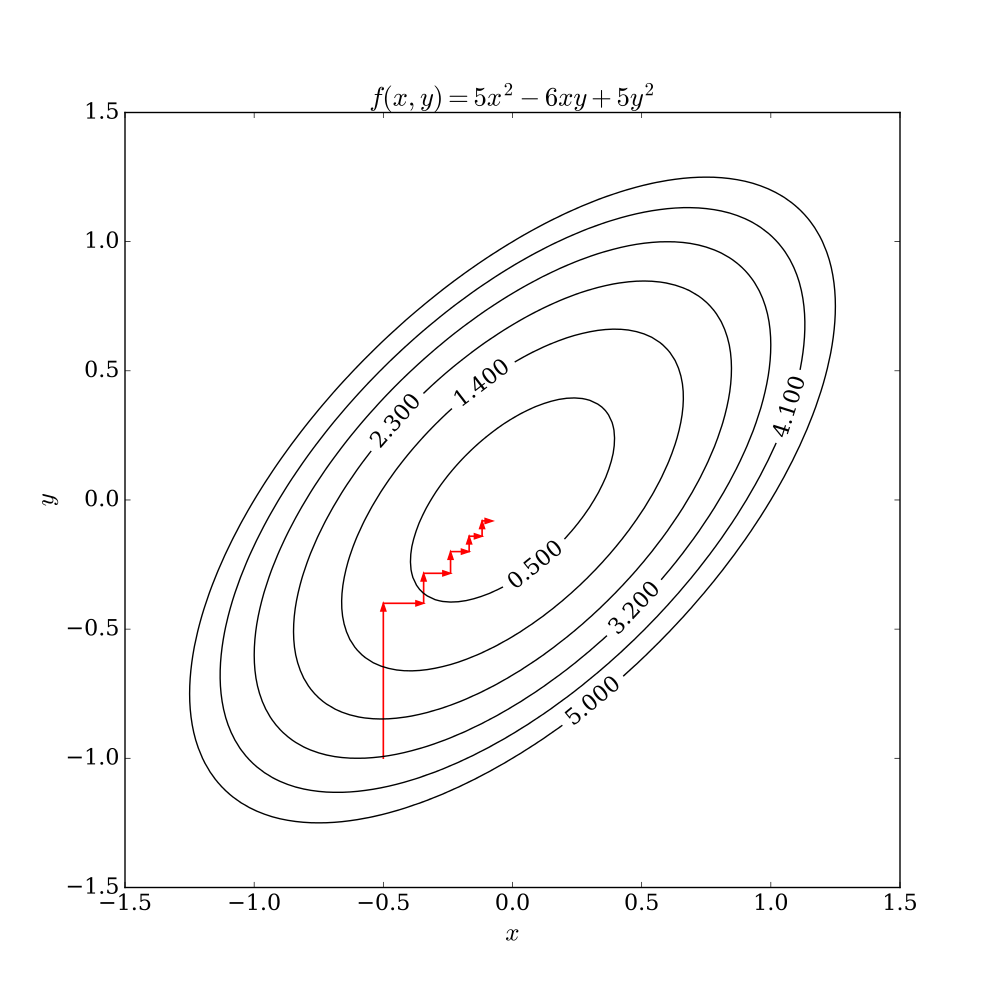
我们最容易想到一种特别朴实的类似于坐标下降法的方法,与坐标下降法不同的是,其不是循环使用各个参数进行调整,而是贪心地选取了对整体模型性能影响最大的参数。参数对整体模型性能的影响力是动态变化的,故每一轮坐标选取的过程中,这种方法在对每个坐标的下降方向进行一次直线搜索(line search)。首先,找到那些能够提升整体模型性能的参数,其次确保提升是单调或近似单调的。这意味着,我们筛选出来的参数是对整体模型性能有正影响的,且这种影响不是偶然性的,要知道,训练过程的随机性也会导致整体模型性能的细微区别,而这种区别是不具有单调性的。最后,在这些筛选出来的参数中,选取影响最大的参数进行调整即可。
另外无法对整体模型性能进行量化,也就谈不上去比较参数影响整体模型性能的程度。我们还没有一个准确的方法来量化整体模型性能,只能通过交叉验证来近似计算整体模型性能。然而交叉验证也存在随机性,假设我们以验证集上的平均准确度作为整体模型的准确度,我们还得关心在各个验证集上准确度的变异系数,如果变异系数过大,则平均值作为整体模型的准确度也是不合适的。
五、评分卡实践
这次我们与时俱进,用 Kaggle上的 Lending Club 数据来建模。大家可以到 Kaggle/Lending Club/ 上下载,在主页上还可以看到世界各地的人用各种姿势在玩这份数据。另外也可以关注我的公众号:JSong老师,后台回复 “数据集” 下载
同样第一步先导入数据,其包含了 Lending Club 从2007-2015年共887379个用户的借款数据。这份数据一共有75个字段,这些字段又分为五种类型:ID类、开卡前的数据、描述信用卡的数据、注销后的数据、欠款状态等。由于我们要在开卡前预测用户时候会欠款,所以这里只能使用 var_submission 中的数据。
data=pd.read_csv('.\\lending-club-loan-data\\loan.csv')
#data=data.sample(frac=0.1)
# Identifiers, etc. (we won't use them as predictors)
var_identifiers = ['id', 'member_id', 'url']
# Features available at a moment of credit application submission
var_submission = ['loan_amnt', 'term', 'int_rate', 'installment', 'grade', 'sub_grade',
'emp_title', 'emp_length', 'home_ownership', 'annual_inc',
'verification_status', 'desc', 'purpose', 'title', 'zip_code',
'addr_state', 'dti', 'delinq_2yrs', 'earliest_cr_line',
'inq_last_6mths', 'mths_since_last_delinq', 'mths_since_last_record',
'open_acc', 'pub_rec', 'total_acc', 'initial_list_status',
'collections_12_mths_ex_med', 'mths_since_last_major_derog',
'policy_code', 'application_type', 'annual_inc_joint', 'dti_joint',
'verification_status_joint', 'acc_now_delinq', 'tot_coll_amt',
'tot_cur_bal', 'open_acc_6m', 'open_il_6m', 'open_il_12m',
'open_il_24m', 'mths_since_rcnt_il', 'total_bal_il', 'il_util',
'open_rv_12m', 'open_rv_24m', 'max_bal_bc', 'all_util',
'total_rev_hi_lim', 'inq_fi', 'total_cu_tl', 'inq_last_12m']
# Features describing an open credit
var_open = ['funded_amnt', 'funded_amnt_inv', 'issue_d', 'pymnt_plan',
'revol_bal', 'revol_util', # revol_bal maybe available during the application
'out_prncp', 'out_prncp_inv', 'total_pymnt', 'total_pymnt_inv',
'total_rec_prncp', 'total_rec_int', 'total_rec_late_fee',
'last_pymnt_d', 'last_pymnt_amnt', 'next_pymnt_d',
'last_credit_pull_d']
# Features available after closing a credit
var_close = ['recoveries', 'collection_recovery_fee']
# Response variable
var_y = ['loan_status']
本系列最后一篇文章的目的在于讲解调参的方法,所以这次不再详细介绍数据清洗和特征变换的过程。这次我们主要采用集成学习相关算法来建模,所以特征工程中就直接用哑变量,有兴趣的童鞋可以自己用woe编码试试。
# 借款状态处理
statuses = data.loan_status.unique()
bad = ['Charged Off', 'Default',
'Does not meet the credit policy. Status:Charged Off',
'Late (31-120 days)']
good = ['Fully Paid','Does not meet the credit policy. Status:Fully Paid']
# current 的样本都不能用
current = ['Current', 'In Grace Period', 'Late (16-30 days)','Issued']
# Selecting relevant features and observations
data = data[var_submission+var_y]
data = data[data.loan_status.isin(bad+good)]
# Features per type of preprocessing required
data['loan_status']=data['loan_status'].map(lambda x: 1 if x in bad else 0)
# 去除缺失率大于60%的字段
data=data.dropna(thresh=len(data) * 0.6,axis=1)
nunique=data.apply(pd.Series.nunique)
data=data.loc[:,nunique!=1]
###### 特征变换
data['term'] = data['term'].str.split(' ').str[1].astype(float)
# extract numbers from emp_length and fill missing values with the median
data['emp_length'] = data['emp_length'].str.extract('(\d+)').astype(float)
data['emp_length'] = data['emp_length'].fillna(data.emp_length.median())
# 将日期转换成月份数,以最早的日期数为基准
tmp=pd.to_datetime('01-'+data['earliest_cr_line'])
data['earliest_cr_line']=(tmp-tmp.min()).map(lambda x:round(x.days/30) if pd.notnull(x) else np.nan)
data['earliest_cr_line']=data['earliest_cr_line'].fillna(data['earliest_cr_line'].median())
# drop 无意义ID和难以分析的文本变量
var_drop = ['emp_title','title','zip_code']
data=data.drop(var_drop,axis=1)
X=data.drop('loan_status',axis=1)
y=data['loan_status']
categorical_var=list(set(X.columns[X.apply(pd.Series.nunique)<30])|set(X.select_dtypes(include=['O']).columns))
continuous_var=list(set(X.columns)-set(categorical_var))
# 特征工程
tmp=pd.get_dummies(X[categorical_var].applymap(lambda x:'%s'%x),drop_first=True)
# 补缺
imputer=preprocessing.Imputer(strategy='median')
X[continuous_var]=imputer.fit_transform(X[continuous_var])
X[continuous_var]=preprocessing.MinMaxScaler().fit_transform(X[continuous_var])
X=pd.concat([tmp,X[continuous_var]],axis=1)
处理后一共还有 268530 个样本,212个变量。接下来我们开始建模和调参。首先看一下 bad 和 good 的占比:
| 0 ( good ) | 1 ( bad ) |
|---|---|
| 209711 (78.0959%) | 58819 (21.9041%) |
这是一个典型的样本不平衡问题,如果不做任何处理,建模得到的结果虽然auc和精确率都挺高,但召回率(坏瓜有多少被挑出)和F1分数都会相对偏低(f1只有0.11左右)。这里我们可以采用下采样和Smote算法,为了简单和充分利用到每个样本,我将直接用第二种方法。
# Balanced
from imblearn.over_sampling import SMOTE
index_split = int(len(X)*0.6)
X_train, y_train = SMOTE().fit_sample(X[0:index_split], y[0:index_split])
X_test, y_test = X[index_split:], y[index_split:]
此时训练集有26万,测试集有10万。接下来我们用逻辑回归、随机森林和GBDT三种算法来建模,而且都用默认的参数。
clfs={'LogisticRegression':LogisticRegressionCV(),
'RandomForest':RandomForestClassifier(),
'GradientBoosting':GradientBoostingClassifier()}
y_preds,y_probas={},{}
for clf in clfs:
clfs[clf].fit(X_train, y_train)
y_preds[clf] =clfs[clf].predict(X_test)
y_probas[clf] = clfs[clf].predict_proba(X_test)[:,1]
models_report,conf_matrix=Classifier_Report(y_test,y_preds,y_probas)
print(models_report)
模型结果如下:
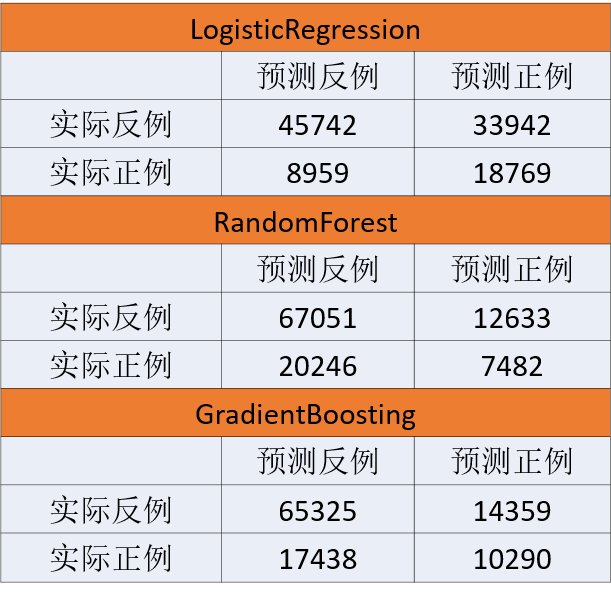
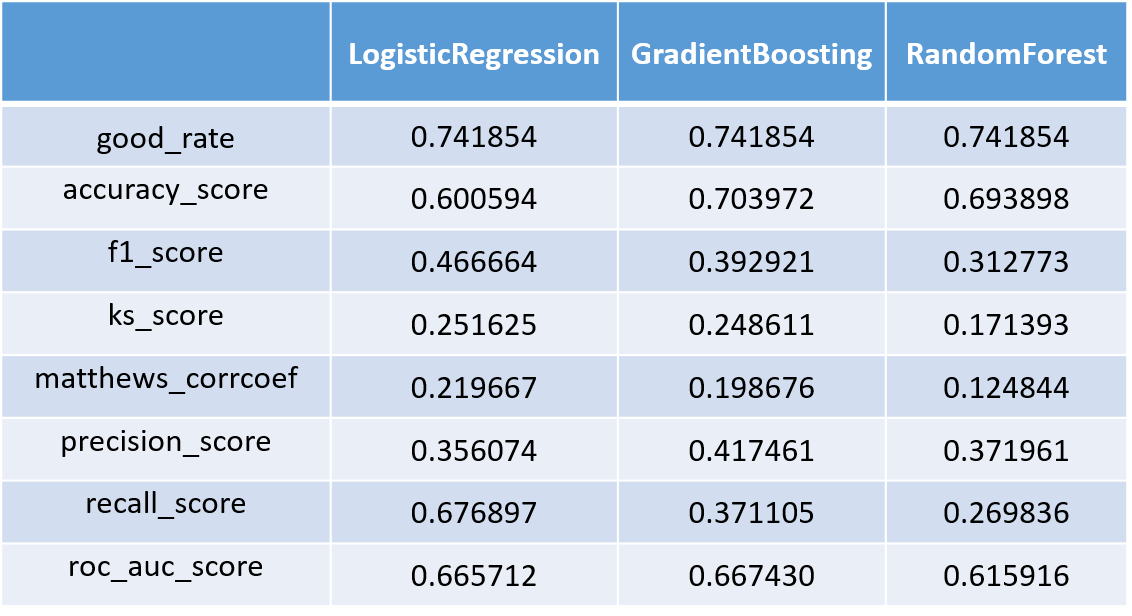

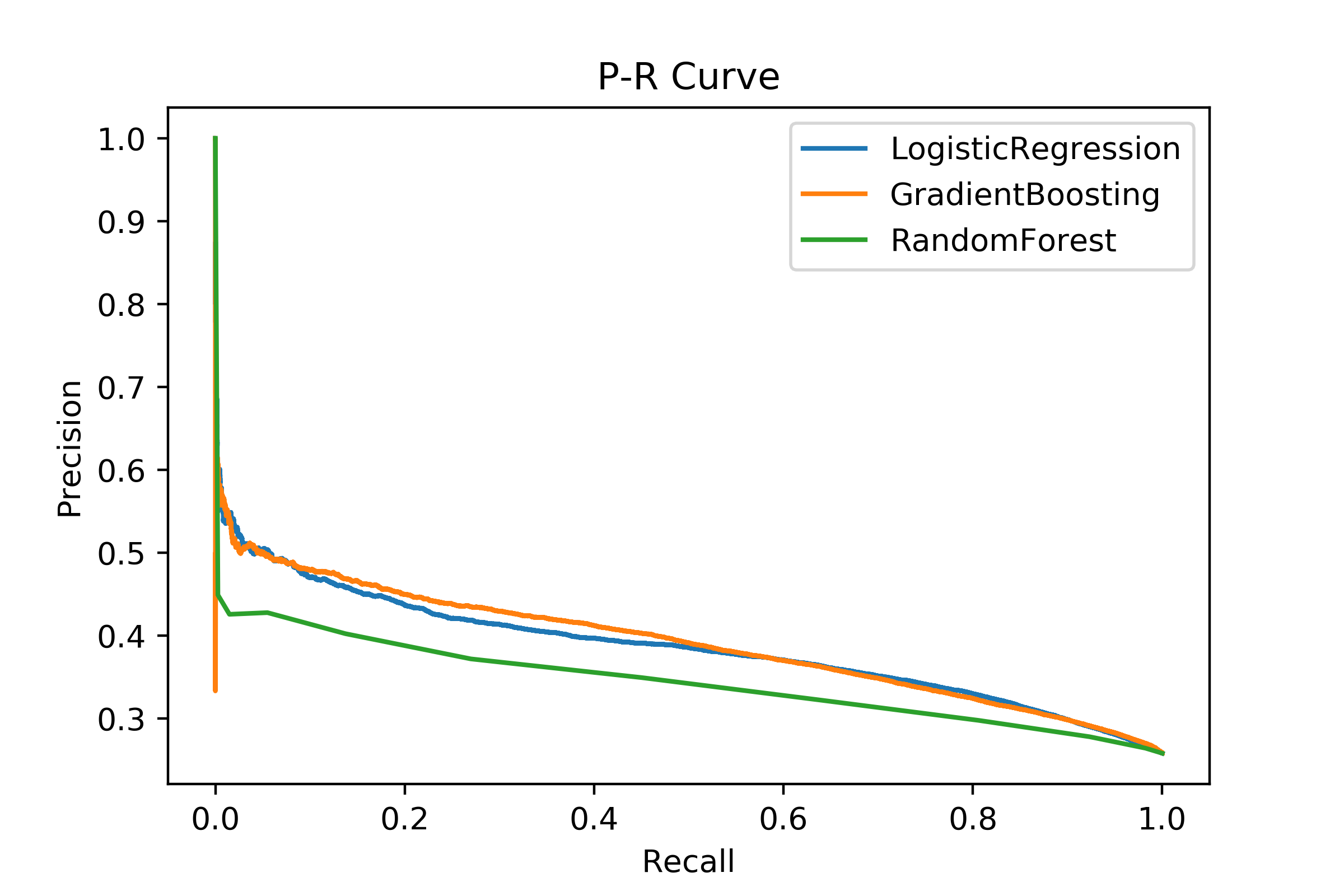
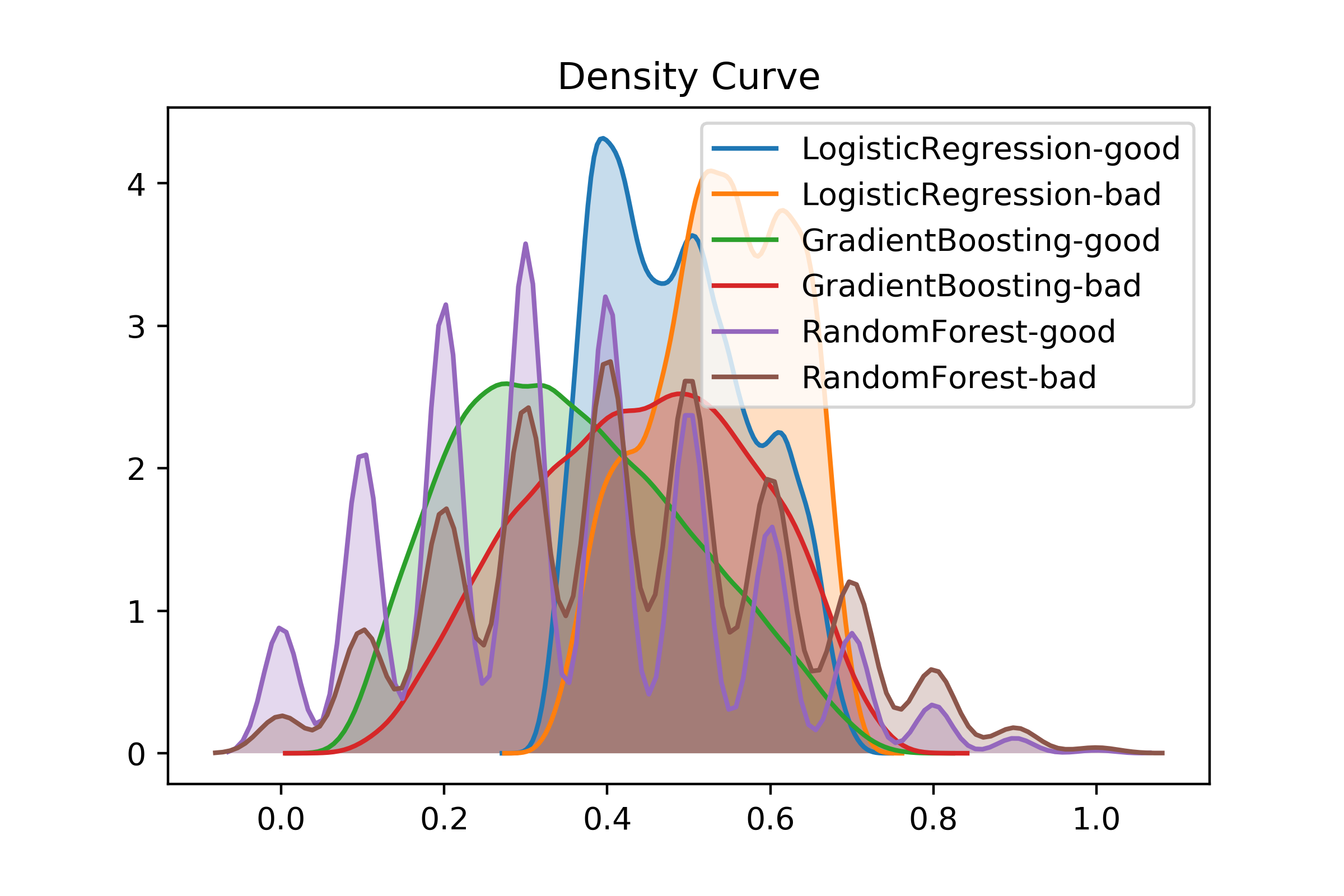
可以看到三个模型中随机森林的效果最差。另外逻辑回归的f1分数最大,但它的精确率有点低,密度曲线也不是很分散。
目前的样本量对于个人计算机而言,已经很大了,梦想用暴力网格搜索的话,还是算了。。。现在这两种算法中,GBDT的调参相对更复杂一些,所以我们以它为例。 GBDT算法的核心思路是每次迭代学习上一步迭代之后的模型残差,并且通过梯度下降的方法来求解参数。其过程影响类参数有“子模型数”(n_estimators)和“学习率”(learning_rate),这两个参数不能单独来讨论,需要一起优化。我们可以使用GridSearchCV找到关于这两个参数的最优解。
param_test ={'n_estimators':range(80,200,10),'learning_rate':[i/100 for i in range(1,25,2)]}
gb=GradientBoostingClassifier(random_state=10)
gsearch1= GridSearchCV(estimator = gb,param_grid =param_test,scoring='f1',n_jobs=4,cv=3)
gsearch1.fit(X_train, y_train)
gsearch1.grid_scores_, gsearch1.best_params_, gsearch1.best_score_
将调参的结果用图像展示如下,颜色越深,代表预测准确率越高:
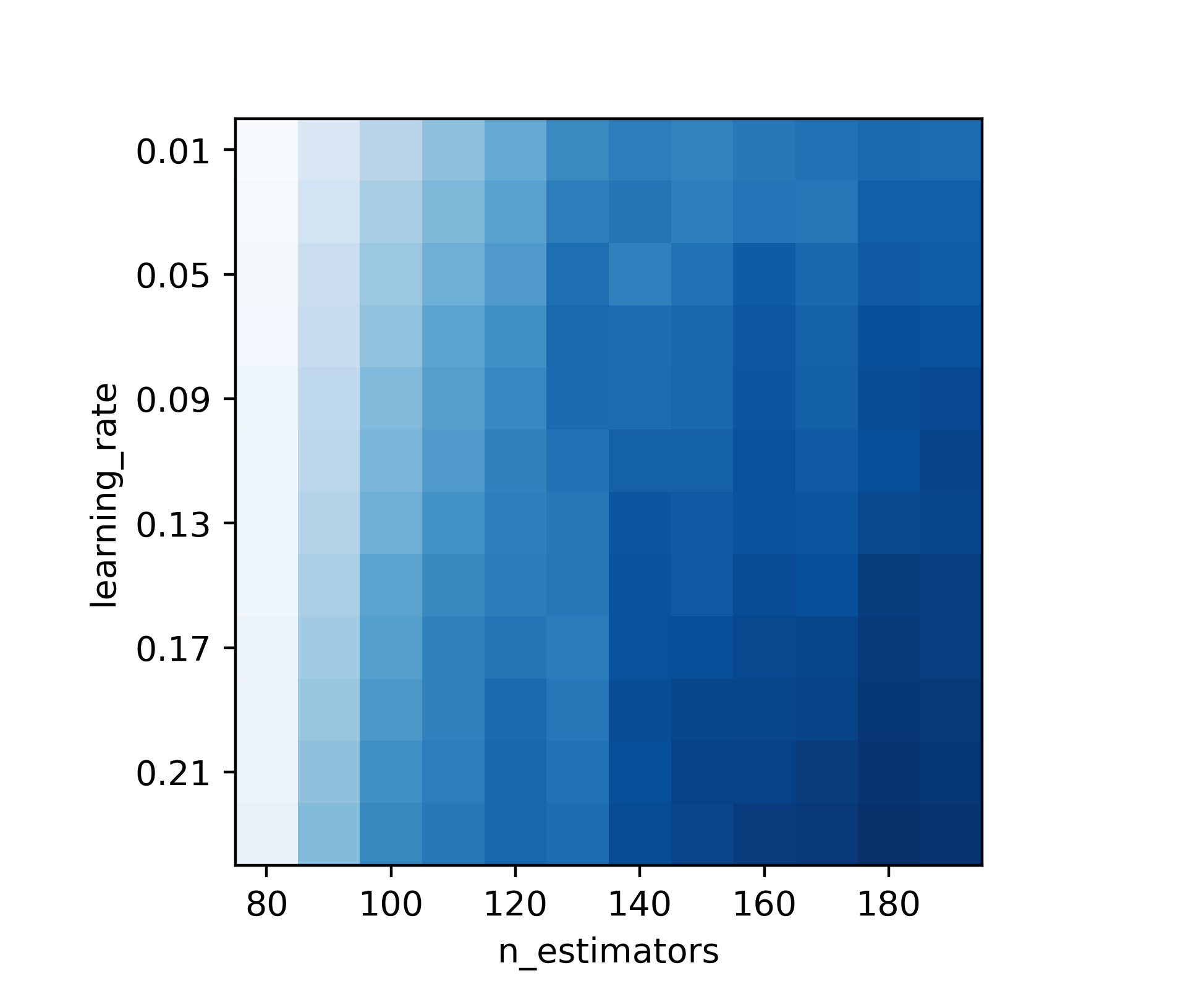
这里有一个很大的陷阱:“子模型数”和“学习率”带来的性能提升是不均衡的,在前期会比较高,在后期会比较低,如果一开始我们将这两个参数调成最优,这样很容易陷入一个“局部最优解”。在目标函数都不确定的情况下(如是否凸?),谈局部最优解就是耍流氓,本文中“局部最优解”指的是调整各参数都无明显性能提升的一种状态,所以打了引号。
这应该算是最优化理论中的 过犹不及经验 ,在学校时候老师曾告诉我,每个维度优化一点点,这样反而更容易达到最优。所以我在这里选择 n_estimators = 140, learning_rate = 0.17,不大不小。
另外细心的话会发现我在 GridSearchCV 中用的是 f1 分数,这是因为在样本不平衡问题中,p-r 曲线比 roc 曲线更好用。roc曲线利用的是正类和负类的概率分布函数,对样本不平衡不敏感。
接下来我们依次优化剩下的参数,代码如下:
param={
'min_samples_leaf':range(1,10,2),
'max_depth':range(3,8),
'subsample':[0.6+i*0.04 for i in range(11)],
'max_features':np.floor(np.sqrt(np.linspace(0.04,1,15))*X_train.shape[1]).astype(np.int)
}
gb=GradientBoostingClassifier(n_estimators=140,learning_rate=0.17,random_state=10)
trained_param={}
param_test={}
for k in param:
param_test.update({k:param[k]})
param_test.update(trained_param)
gsearch1= GridSearchCV(estimator = gb,param_grid =param_test,scoring='f1',n_jobs=4,cv=3)
gsearch1.fit(X_train, y_train)
best_params=gsearch1.best_params_
trained_param={k:[best_params[k]] for k in best_params}
print('优化后的参数:', gsearch1.best_params_)
得到的参数为:
| max_depth | max_features | min_samples_leaf | subsample |
|---|---|---|---|
| 4 | 180 | 5 | 0.76 |
事实上调参并没有结束,我们还需要杀几个回马枪,但这里我就不继续了(训练太慢了。。)。将优化后的模型用于测试集额预测,结果如下:
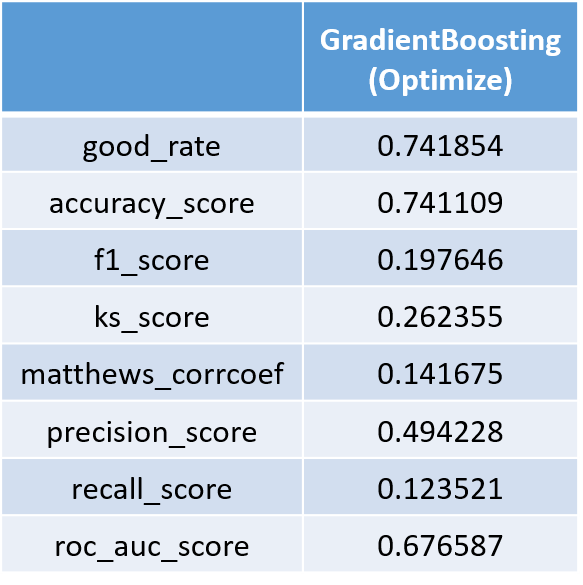
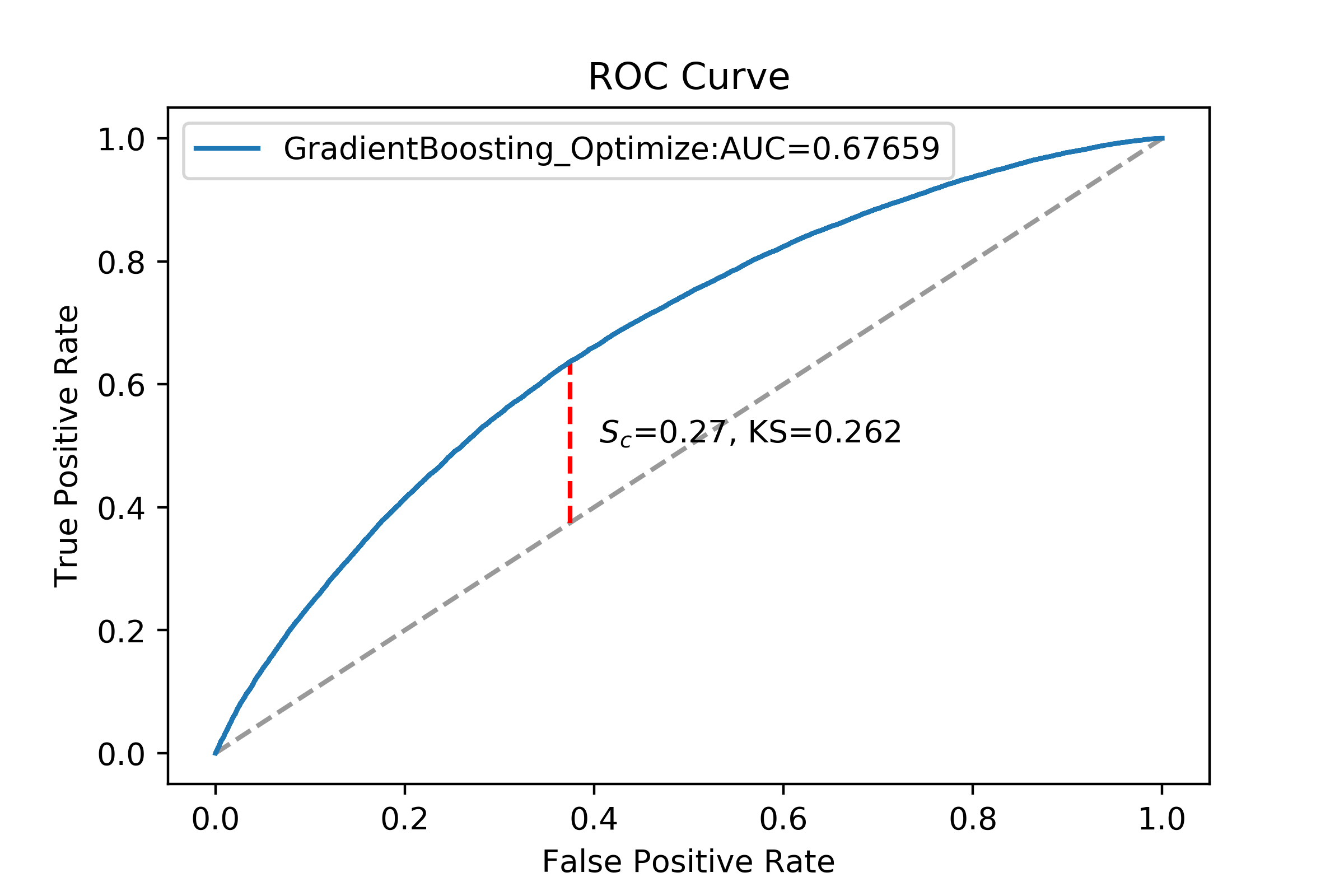
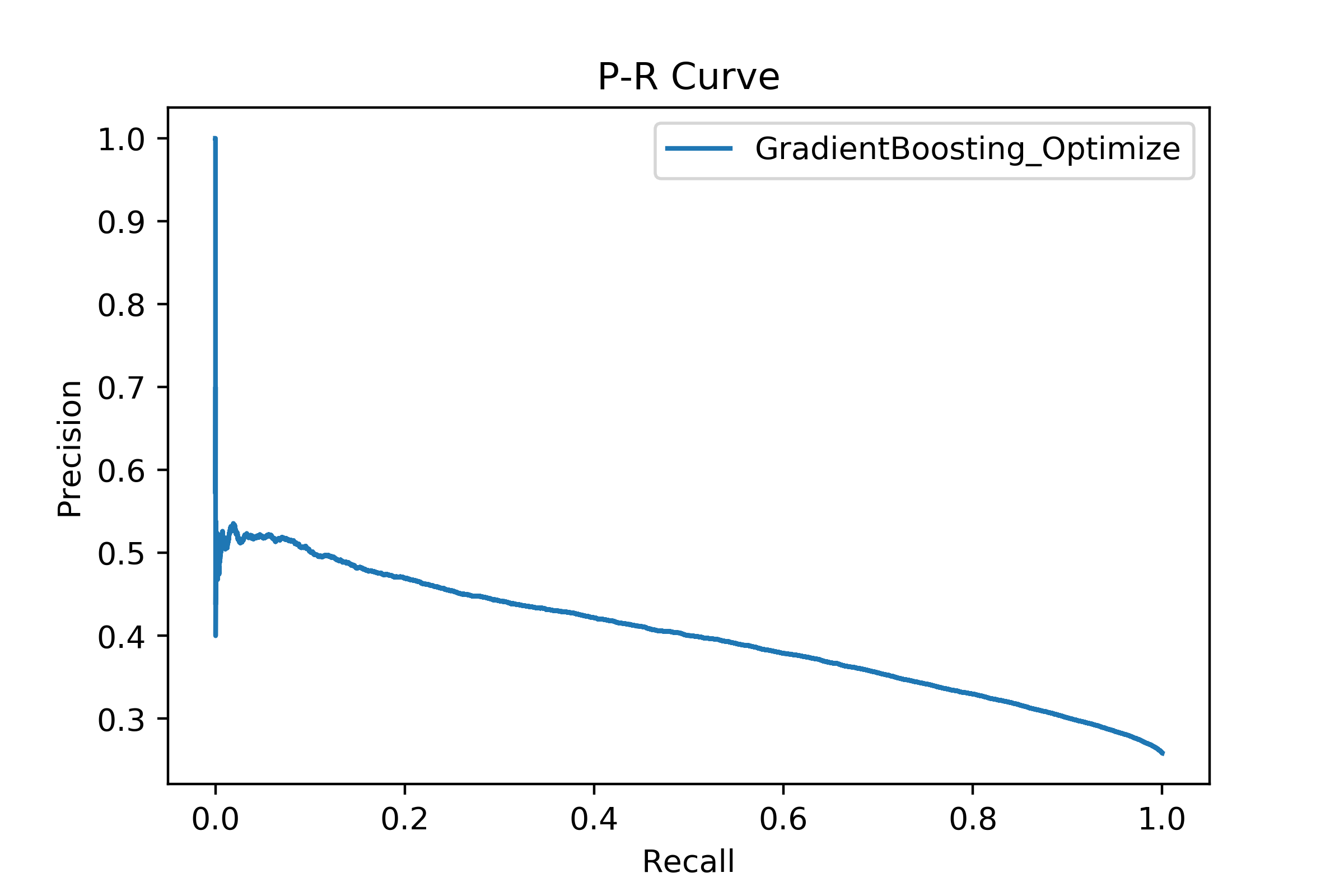
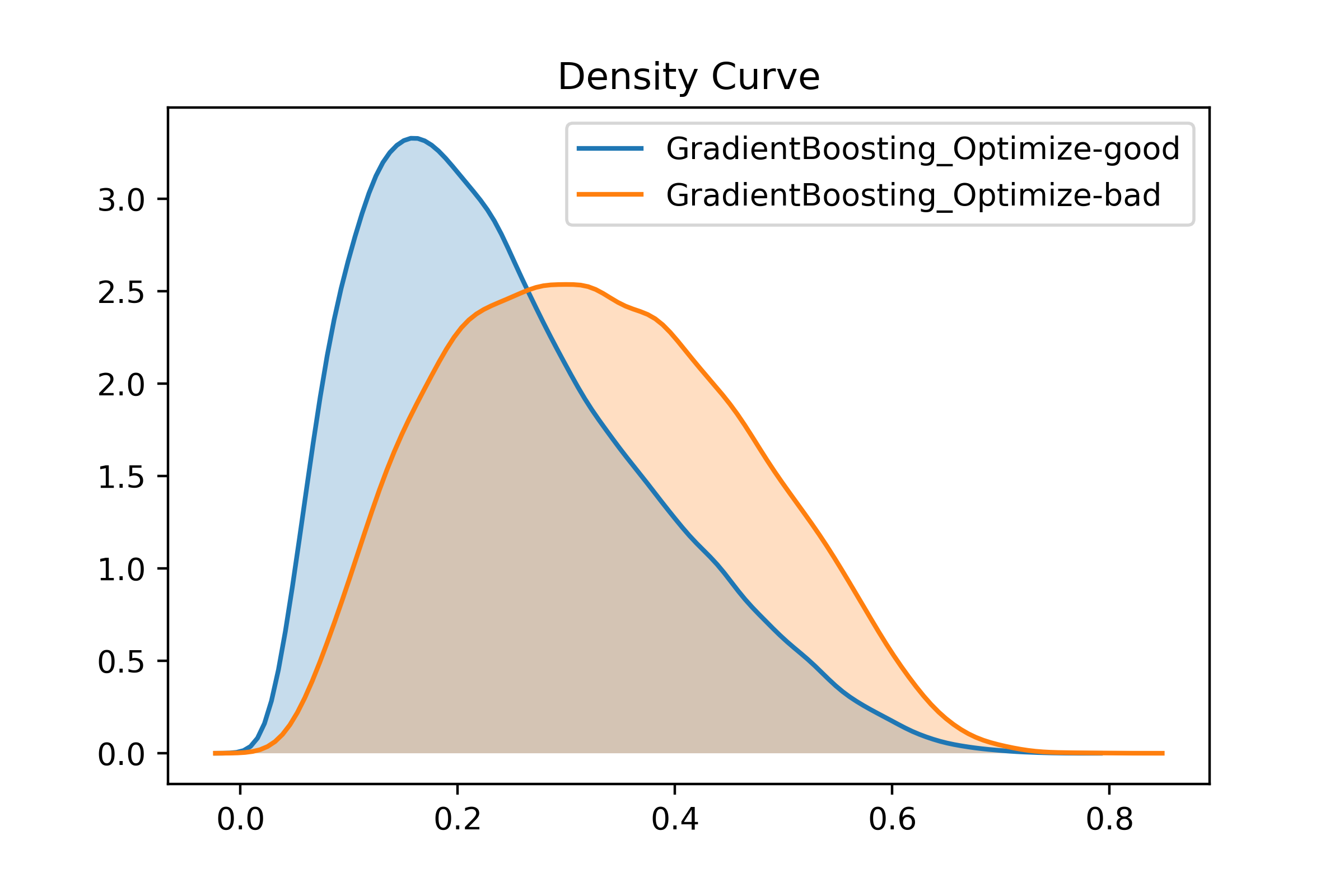
可以看到模型精确率从0.703972 提高到了0.741109,但f1分数下降了(暂时没想明白为什么) 。理论上肯定还有提升空间,这个样本量对于我的 surface 而言压力还是挺大的,每一个参数的调休都花了我一两个个多小时去训练模型,甚至在子模型数和学习率的调优过程中不得不对训练集进行采样。
整个调参过程其实能看得出并不严谨,但不管怎样,我还是放出来供大家一起参考和探讨(一些细节的讨论可以看 jasonfreak 的博客)。一个好的结果取决于对业务、模型理论等的理解程度,取决于好的数据、好的特征工程以及好的调参技巧。相关的代码都可以关注我的公众号,后台回复:“评分卡” 下载。
参考文献
[1]. Understanding the Bias-Variance Tradeoff
[2]. 使用sklearn进行集成学习——理论
[4]. GridSearch使用方法
[6]. 使用sklearn进行集成学习——实践
评分卡系列文章:
欢迎关注我的公众号,评分卡系列相关代码和数据都可在公众号中下载。


