Drf序列化组件 | Serializer | 模型类序列化器ModelSerializer具体使用
DRF序列化组件
# 作用:
1. 序列化,序列化器(类)会把模型对象(Book对象,Queryset对象)转换成字典,经过response以后变成json字符串
2. 反序列化,把客户端发送过来的数据,经过request以后变成字典(request.data),序列化器(类)可以把字典转成模型
3. 反序列化,完成数据校验功能
# 本质:
就是写一个类继承一个类
可以完成序列化,反序列化和数据校验
序列化之Serializer类的具体使用
准备:
# 因为他的目的就是序列化与反序列化,所以建议把它建立在一个单独的py文件下。
# 这里新建使用 serializer.py(见明知意)
具体使用:
models.py创建一个模型表
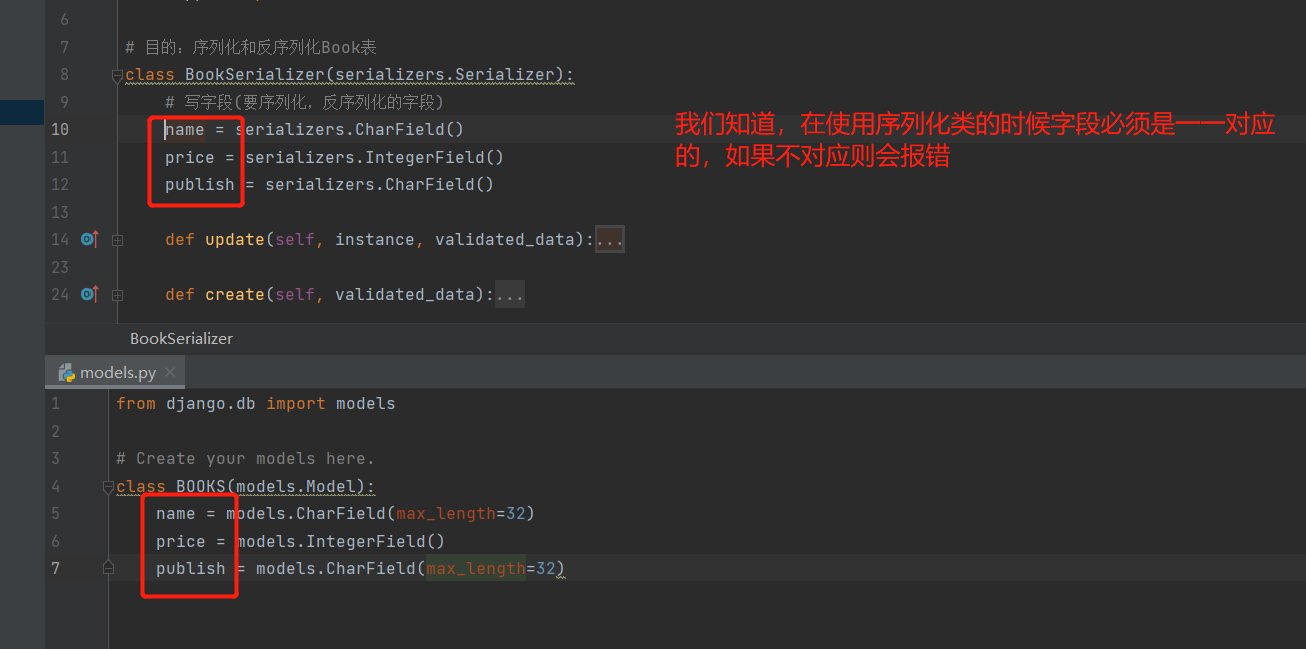
from django.db import models
class BOOKS(models.Model):
name = models.CharField(max_length=32)
price = models.IntegerField()
publish = models.CharField(max_length=32)
serializer.py序列化类
from rest_framework import serializers
# 创建序列化类继承Serializer,目的:序列化和反序列化Book表
class BookSerializer(serializers.Serializer):
# 对应字段(要序列化,反序列化的字段)
name = serializers.CharField(这里可以写校验数据校验规则(相当于forms组件))
price = serializers.IntegerField()
publish = serializers.CharField()
urls.py
urlpatterns = [
path('books/',views.BookAPIView.as_view()),
]
# 通过books/路由访问BookAPIView视图类
views.py
from rest_framework.views import APIView
from rest_framework.response import Response
from app01 import models
from .serializer import BookSerializer # 导入序列化类来使用
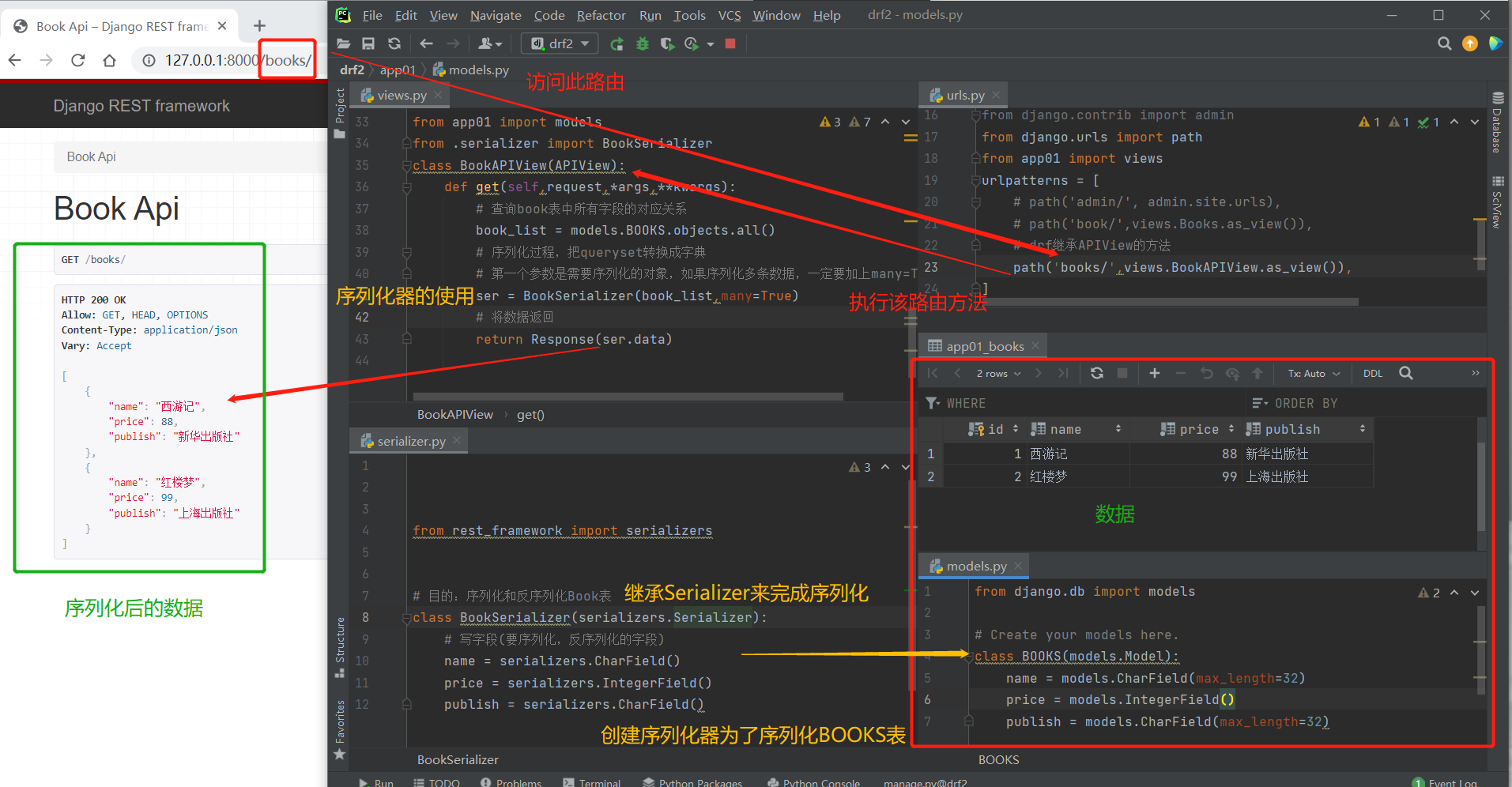
# 查询多个数据接口
class BookAPIView(APIView):
# 查询数据是get请求的结果
def get(self,request,*args,**kwargs):
# 查询book表中所有字段数据
book_list = models.BOOKS.objects.all()
# 序列化过程,把queryset转换成字典
# 第一个参数是需要序列化的对象,如果序列化多条数据,一定要加上many=True
ser = BookSerializer(instance=book_list,many=True) # 可使用关键字传参
# ser = BookSerializer(book_list,many=True) # 可使用位置传参
# 将数据返回(此时数据是字典形式,返回到前端则是json格式数据,这是Response帮我们完成的,serializer序列化是将queryset对象转换为字典的形式。)
return Response(ser.data)
操作单条数据:
需重写路由:
urlpatterns = [
path('books/',views.BookAPIView.as_view()),
# 操作单个数据(使用转换器传入pk值操作单条数据)
path('books/<int:pk>',views.BookDetailAPIView.as_view())
]
# 查询单个:
class BookDetailAPIView(APIView):
def get(self,request,pk):
book = models.BOOKS.objects.filter(pk=pk).first()
# 序列化单个数据就不需要添加many=True参数
ser = BookSerializer(book)
return Response(ser.data)
# 删除单个:
# 发送delete请求
class BookDetailAPIView(APIView):
def delete(self,request,pk):
# 删除数据无需序列化与反序列化直接删除即可
models.BOOKS.objects.filter(pk=pk).delete()
# 删除成功返回一个空,如果没删除成功会自己抛异常返回一个空
return Response()
# 修改单个:
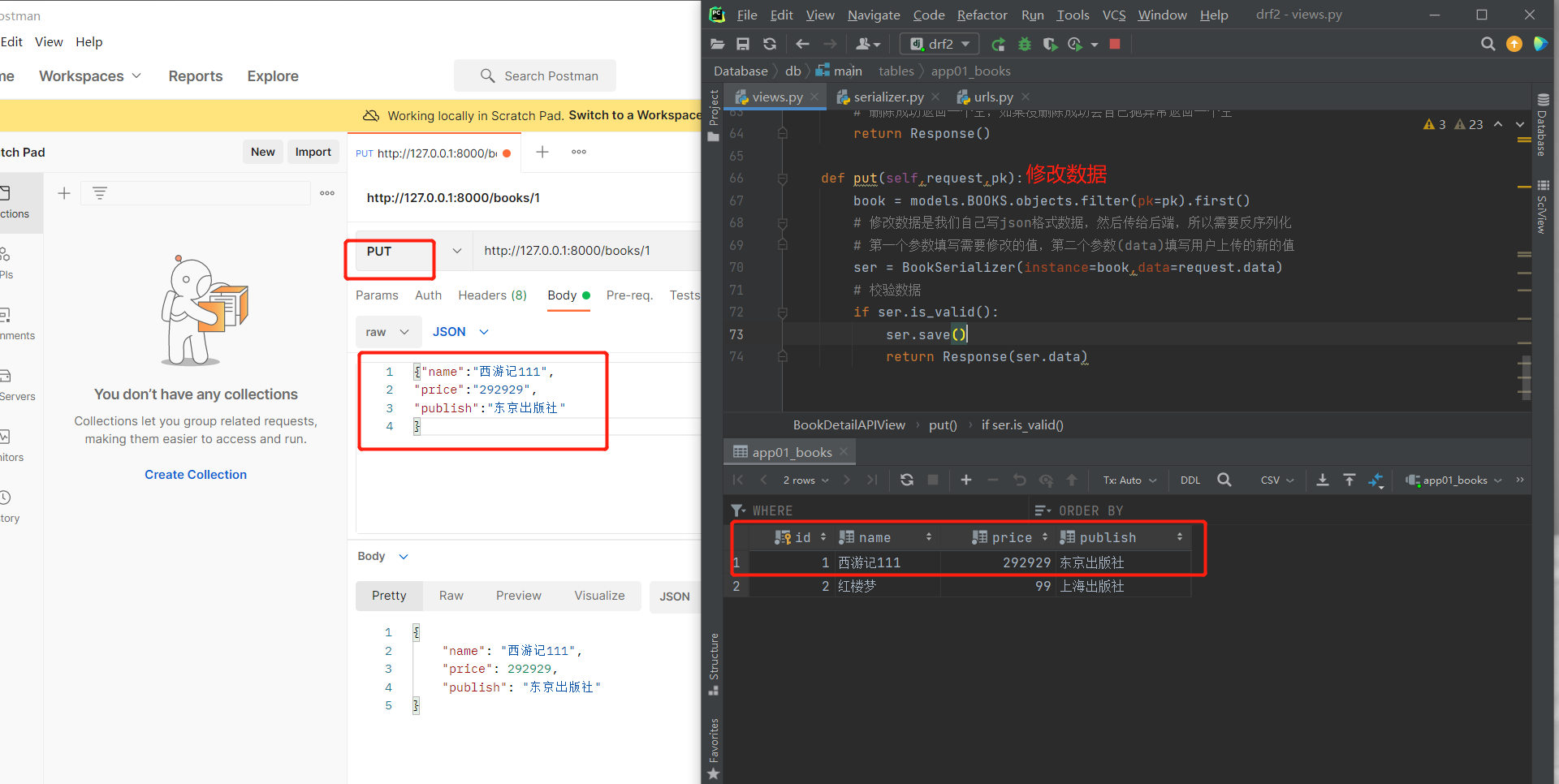
# 发送put请求
class BookDetailAPIView(APIView):
def put(self,request,pk):
book = models.BOOKS.objects.filter(pk=pk).first()
# 修改数据是我们自己写json格式数据,然后传给后端,所以需要反序列化
# 第一个参数填写需要修改的值,第二个参数(data)填写用户上传的新的值
ser = BookSerializer(instance=book,data=request.data)
# 校验数据
if ser.is_valid():
ser.save()
return Response(ser.data)
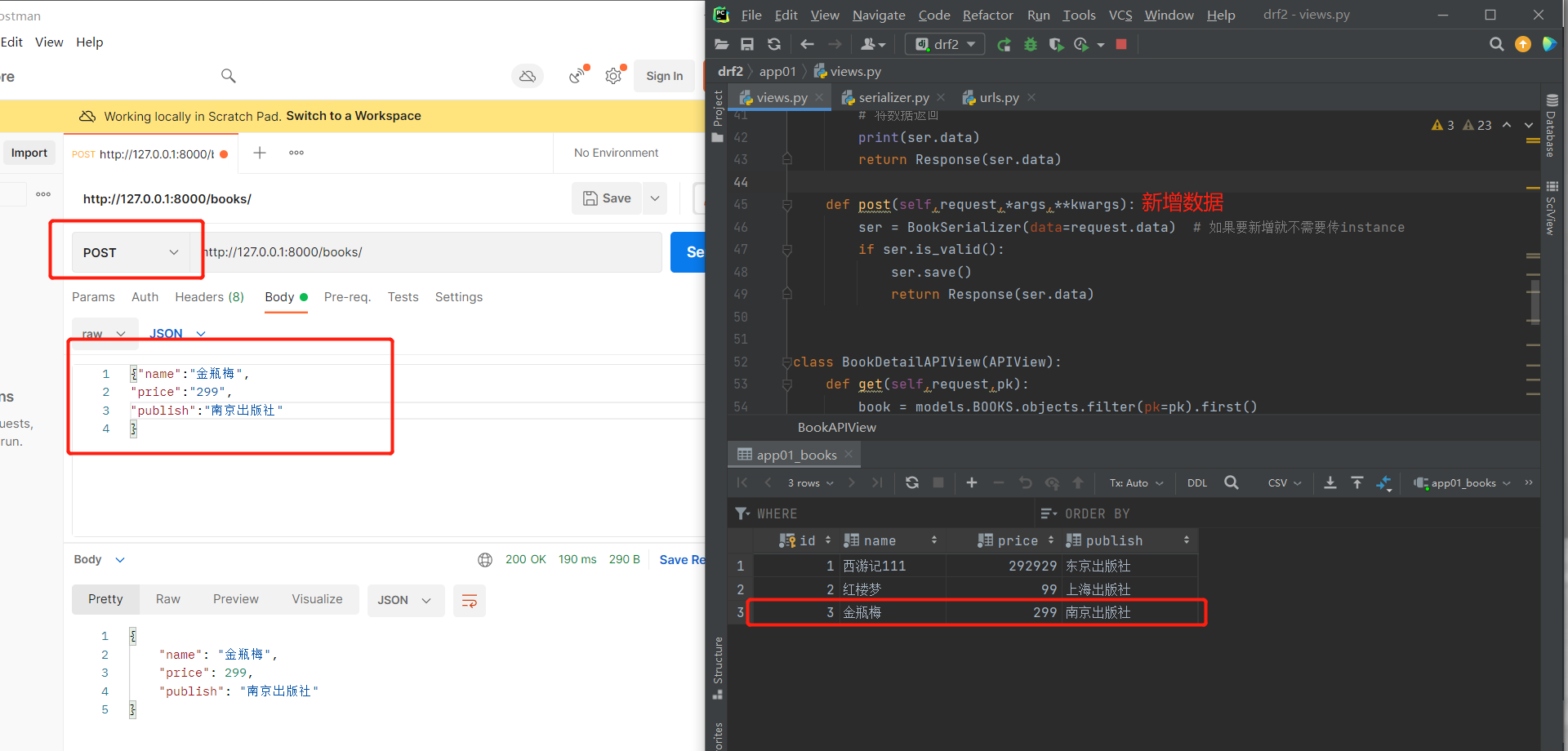
新增单个:
class BookAPIView(APIView):
def post(self,request,*args,**kwargs):
ser = BookSerializer(data=request.data) # 如果要新增就不需要传instance
if ser.is_valid():
ser.save()
return Response(ser.data)
特别注意:
修改和新增需要重写create与updata方法
# 在编写新增与修改功能的时需要在serializer的类中重写create()与updata()方法
# 不然会报错:因为不重写不知道保存在那张表中。
def update(self, instance, validated_data):
# instance就是book对象 validated_data校验通过的数据
instance.name = validated_data.get('name')
instance.price = validated_data.get('price')
instance.publish = validated_data.get('publish')
# 保存(book对象所有的save方法)
# 通过表对象保存,这样就知道了保存到那张表中
instance.save()
# 返回
return instance
def create(self, validated_data):
# validated_data为用户上传的数据
book = models.BOOKS.objects.create(**validated_data) # 打散保存
# 通过表对象保存,这样就知道了保存到那张表中
# 返回
return book
source
引子:
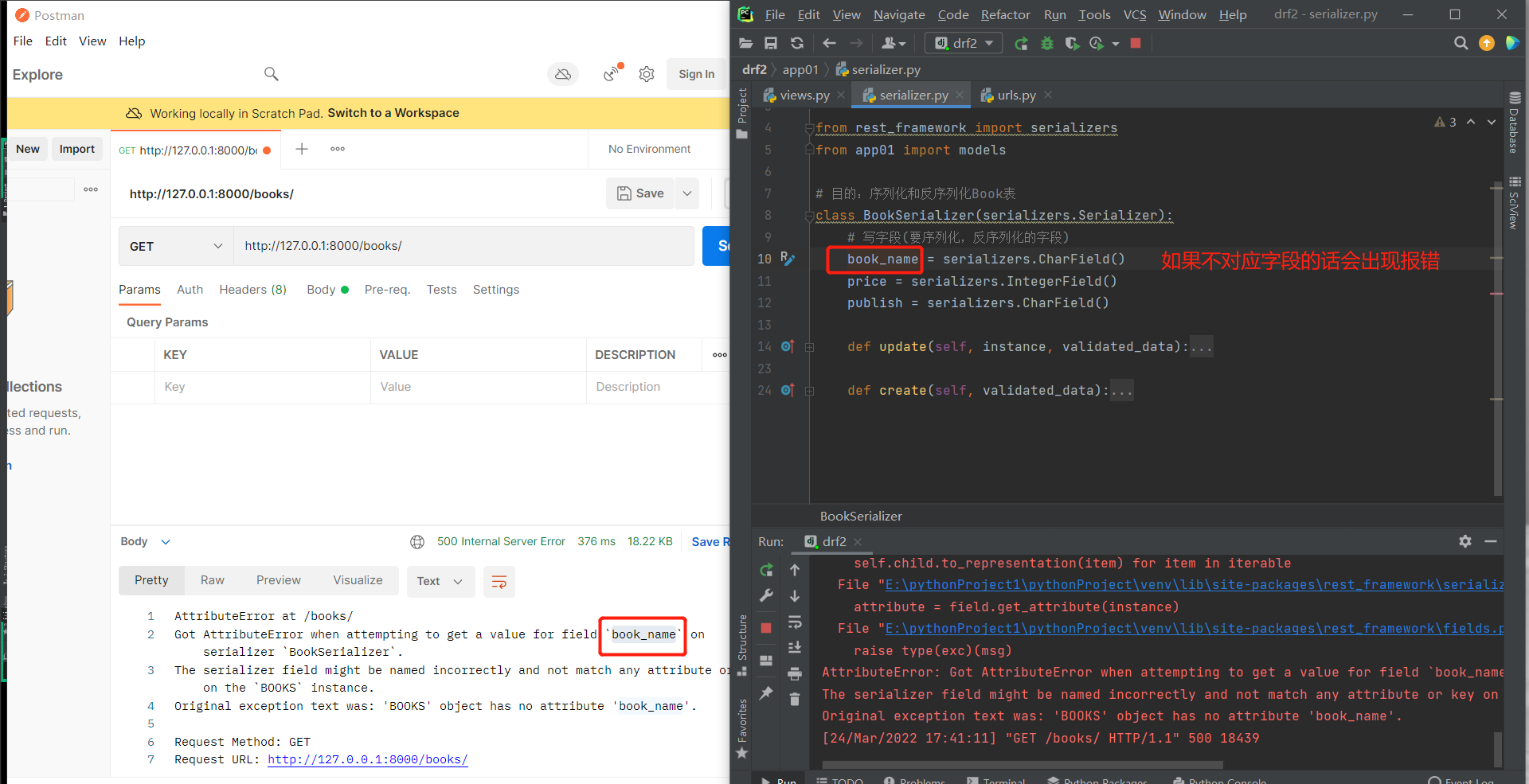
# 那么如果想要使用别的字段名,那么这里就需要使用到source
# source的作用:可以对应表模型的字段和方法(返回结果是什么,字段就是什么)
source基本使用:
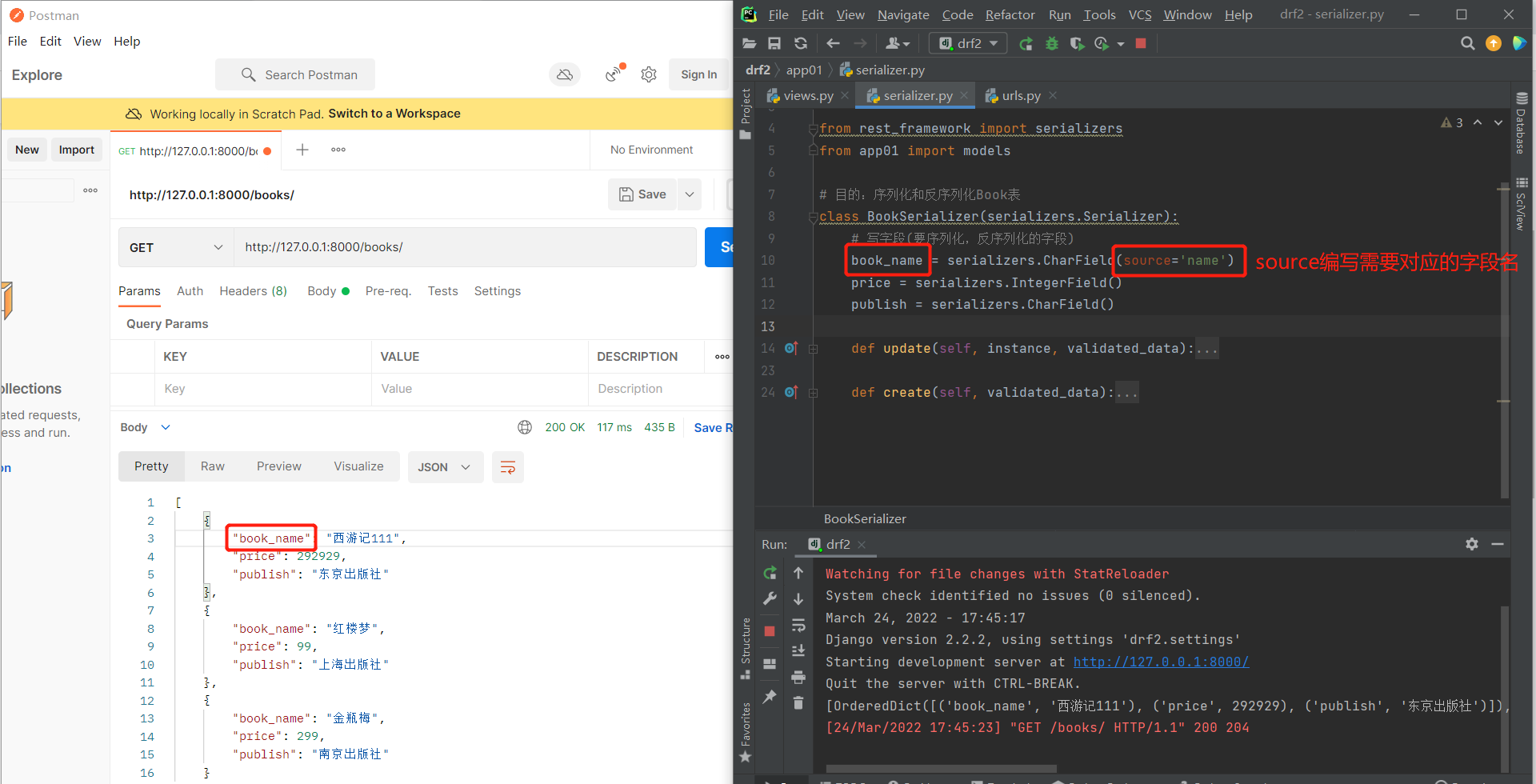
class BookSerializer(serializers.Serializer):
# source参数编写对应表模型的字段名(想与那个字段做对应)
book_name = serializers.CharField(source='name')
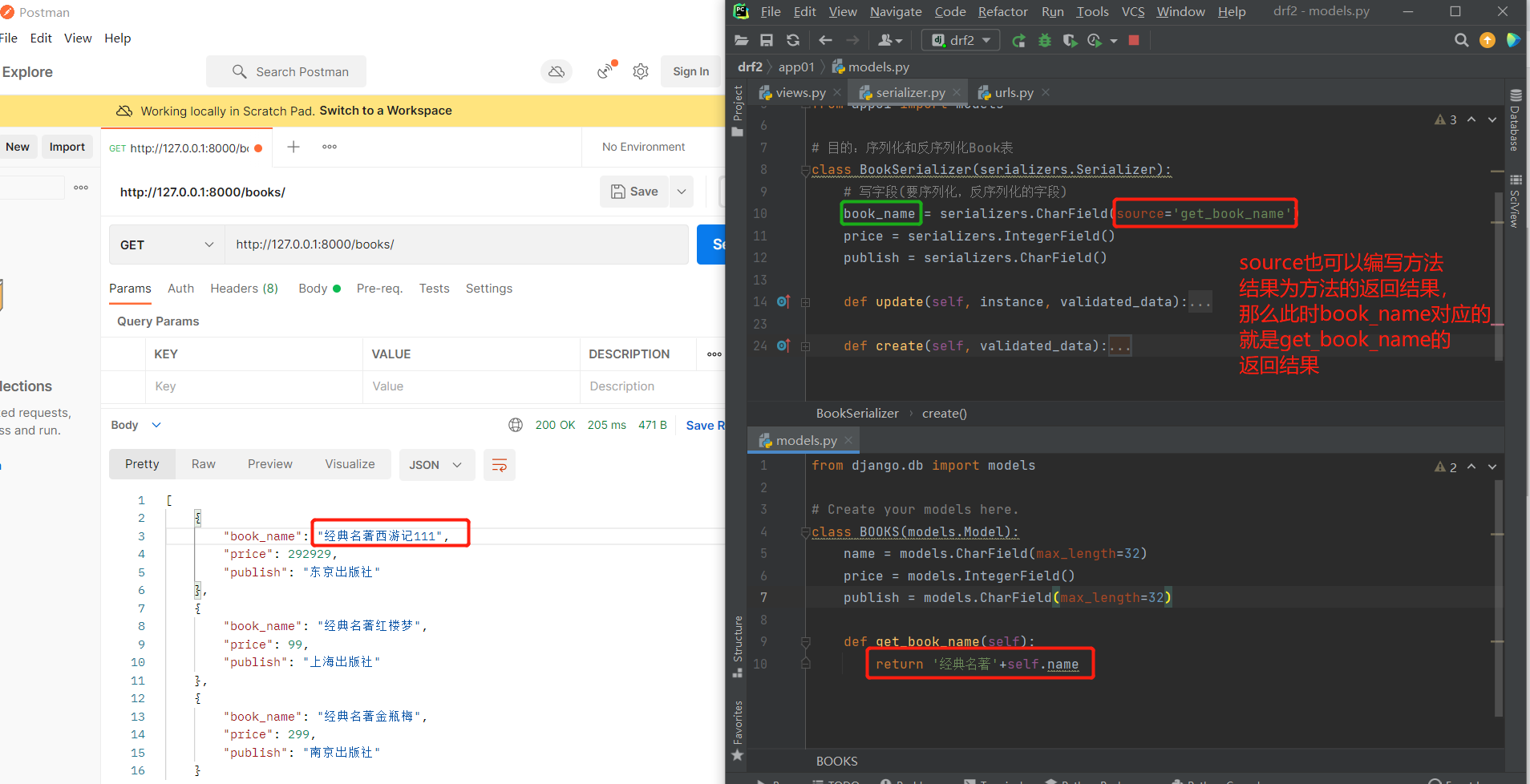
# source也可以对应表模型中的方法(方法的返回结果是什么,字段对应的结果就是什么)
class BOOKS(models.Model):
name = models.CharField(max_length=32)
price = models.IntegerField()
publish = models.CharField(max_length=32)
def get_book_name(self):
return '经典名著'+self.name
class BookSerializer(serializers.Serializer):
# source编写方法名,返回方法的返回结果
book_name = serializers.CharField(source='get_book_name')
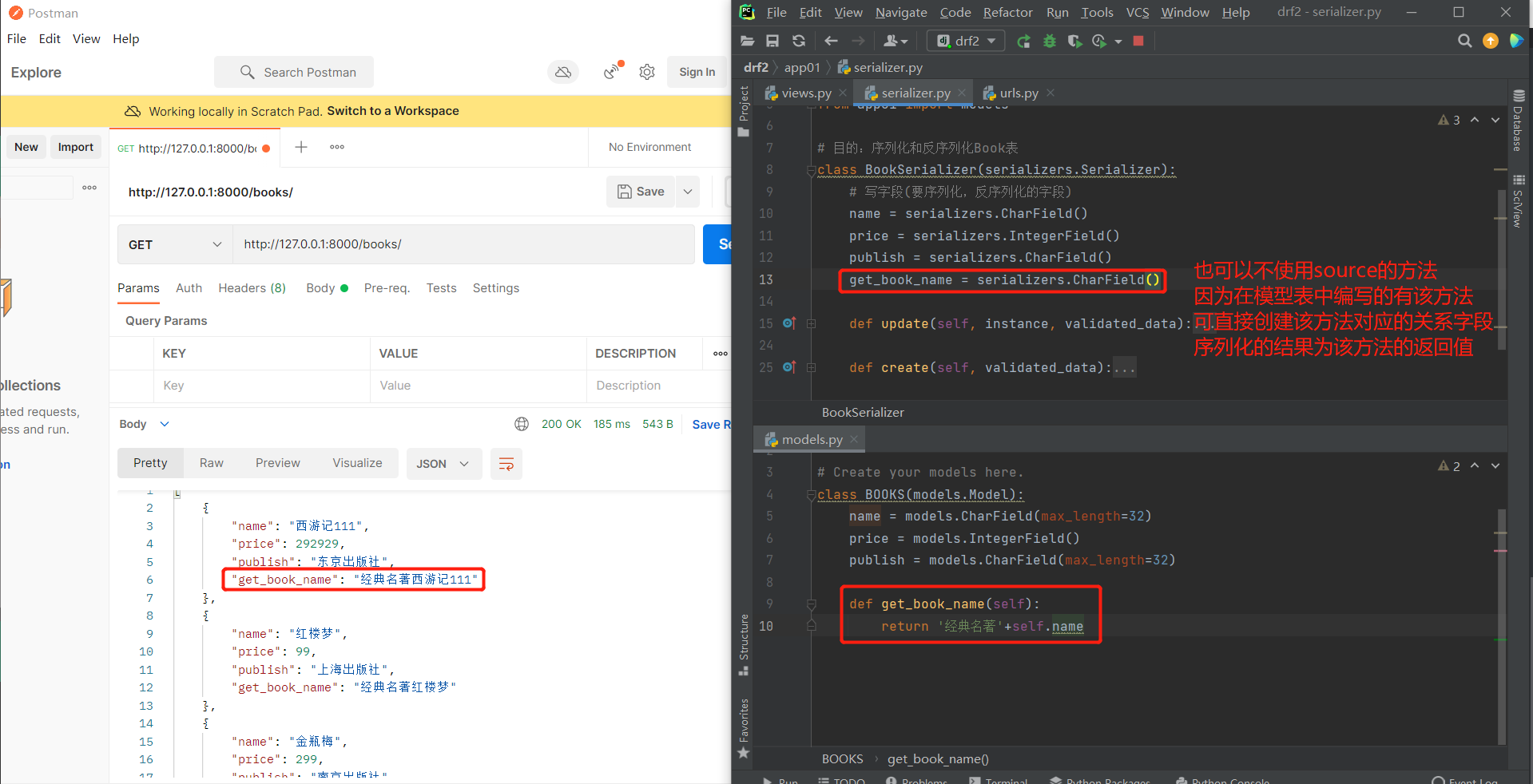
# 放法2:不使用source方法
class BookSerializer(serializers.Serializer):
get_book_name = serializers.CharField()
使用场景:
urls.py
path('books/',views.BookAPIView.as_view()),
models.py
class BOOKS(models.Model):
name = models.CharField(max_length=32)
price = models.IntegerField()
publish = models.ForeignKey(to='Publish',on_delete=models.DO_NOTHING)
class Publish(models.Model):
name = models.CharField(max_length=32)
addr = models.CharField(max_length=32)
serializer.py
from rest_framework import serializers
from app01 import models
class BookSerializer(serializers.Serializer):
# 写字段(要序列化,反序列化的字段)
name = serializers.CharField()
price = serializers.IntegerField()
publish = serializers.CharField()
views.py
from rest_framework.response import Response
from app01 import models
from .serializer import BookSerializer
class BookAPIView(APIView):
def get(self,request,*args,**kwargs):
# 查询book表中所有字段的对应关系
book_list = models.BOOKS.objects.all()
# 序列化过程,把queryset转换成字典
# 第一个参数是需要序列化的对象,如果序列化多条数据,一定要加上many=True
ser = BookSerializer(book_list,many=True)
# 将数据返回
print(ser.data)
return Response(ser.data)
运行结果:
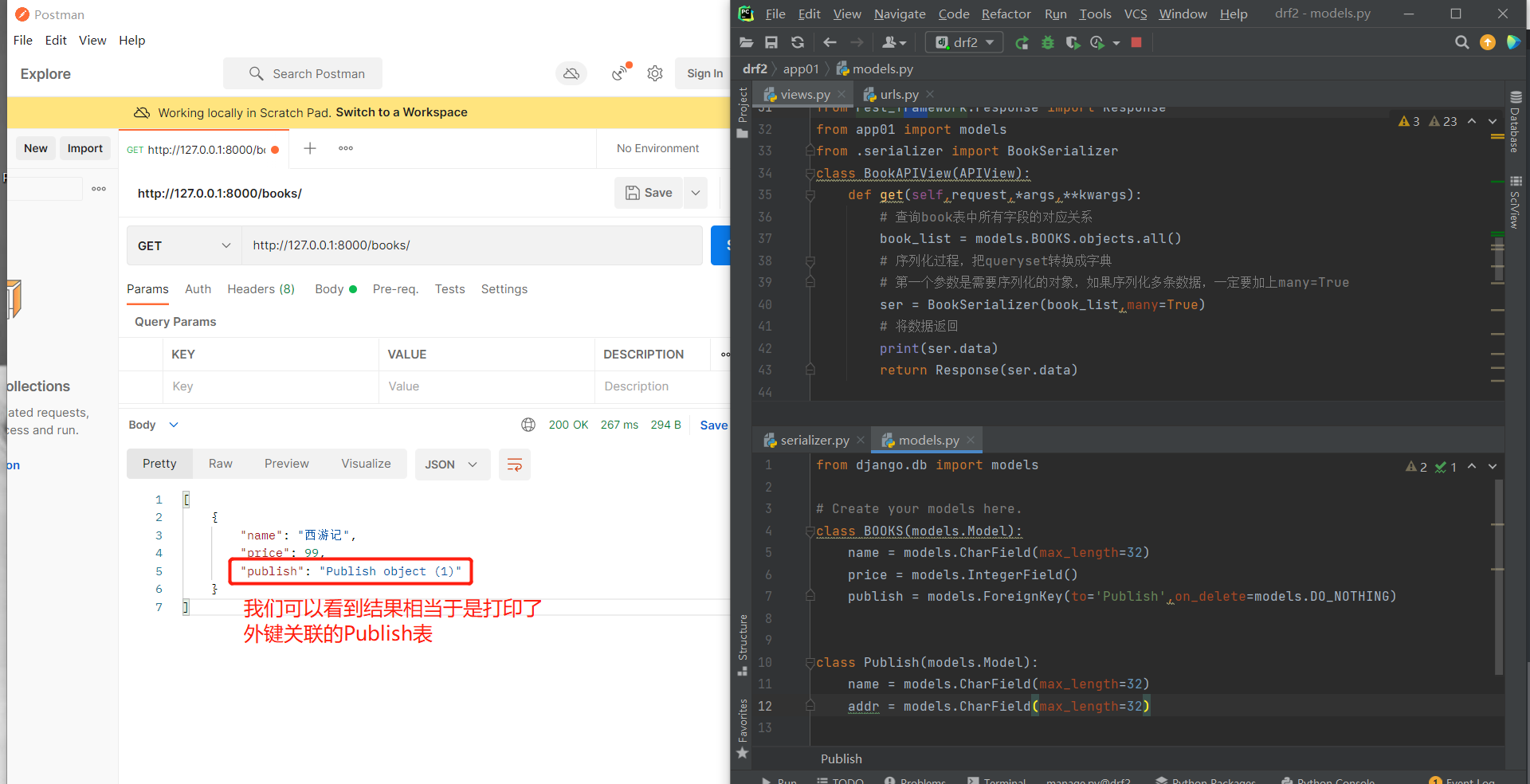
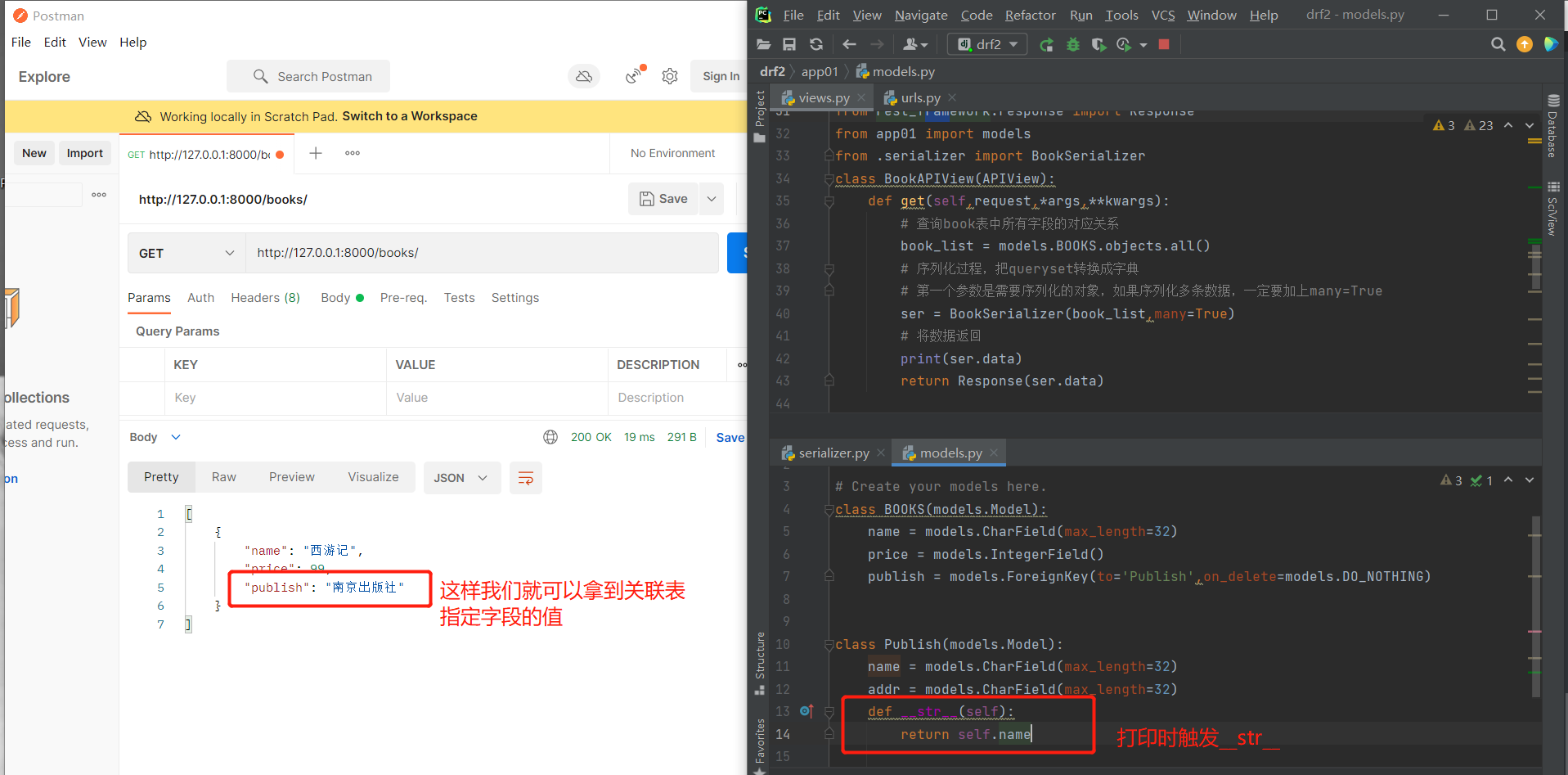
# 那么我们如何拿到关联表所有字段的值(拿到出版社的详细信息)呢?
# 方式一:我们也可以使用上述的方法
# 如下:我们可以看到该方法非常的古怪,没有人会这样使用。
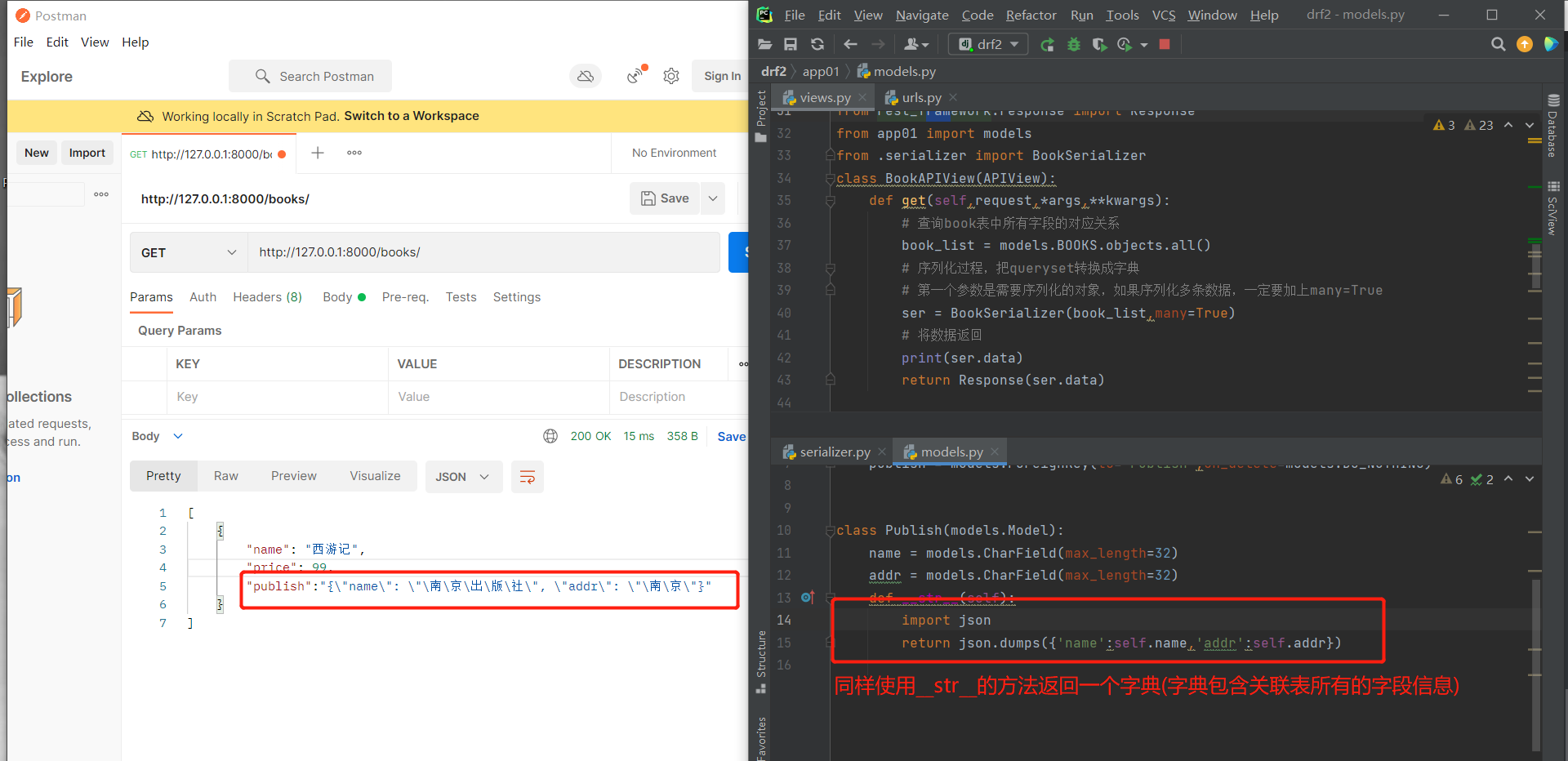
# 方式二:使用source方法实现
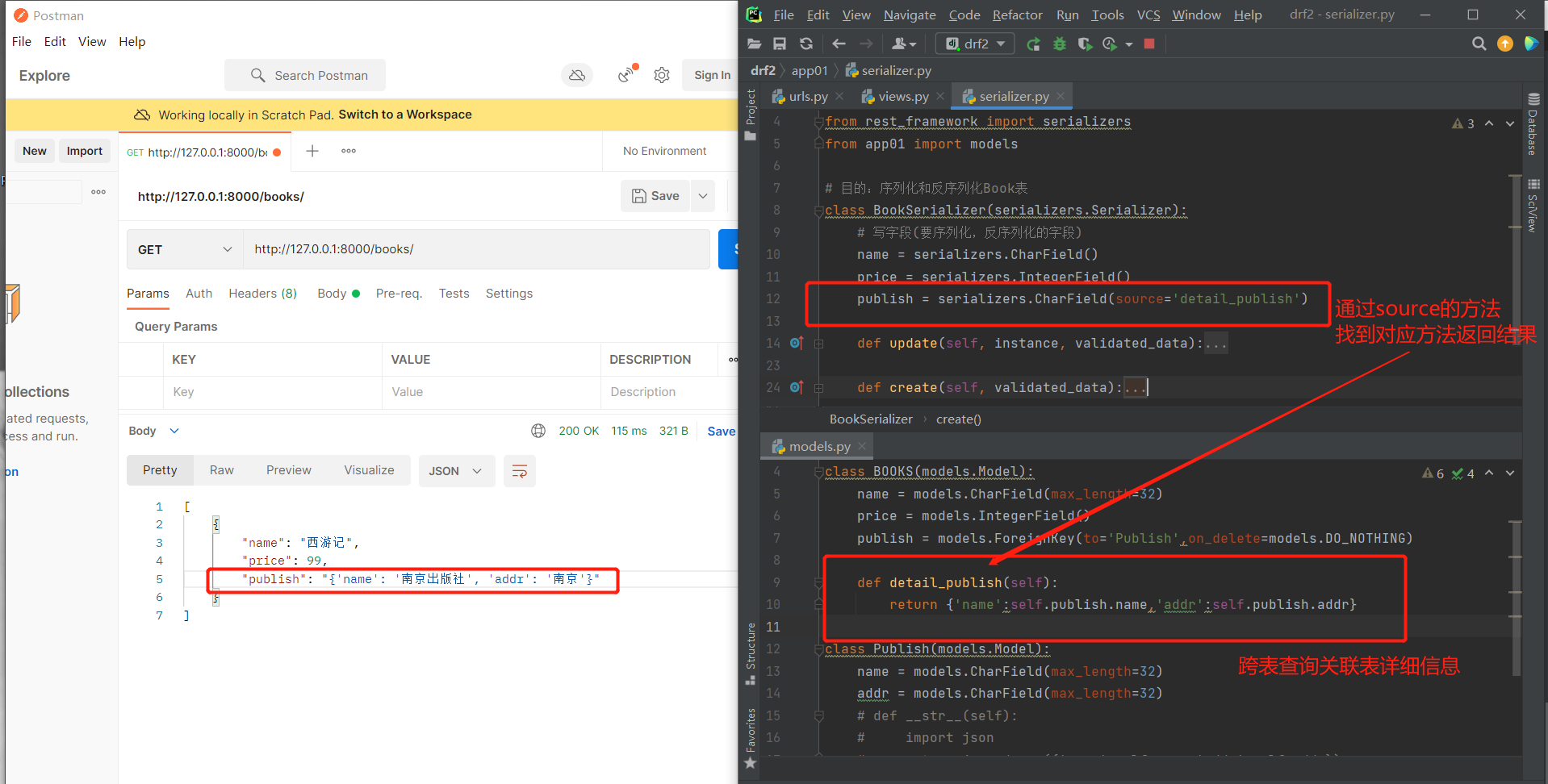
# 方式三:不使用source直接写对应方法名
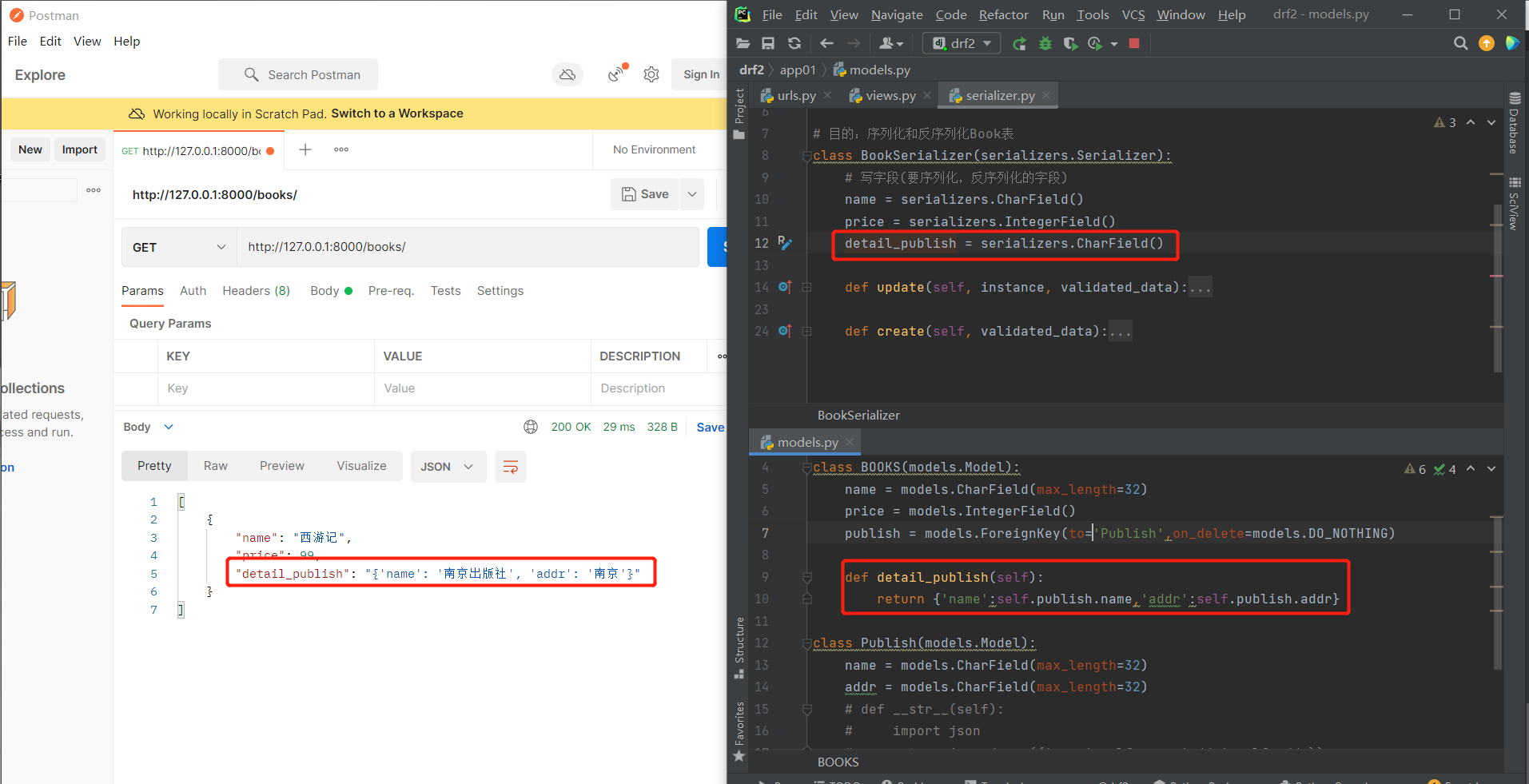
# 方式四:使用SerializerMethodField()方法不需要在表模型中写方法,在序列化类中编写
# 使用使用SerializerMethodField就必须指定一个get_字段名的方法
# 如果字段名不一致则报错
# 该字段名是SerializerMethodField方法需要序列化的字段
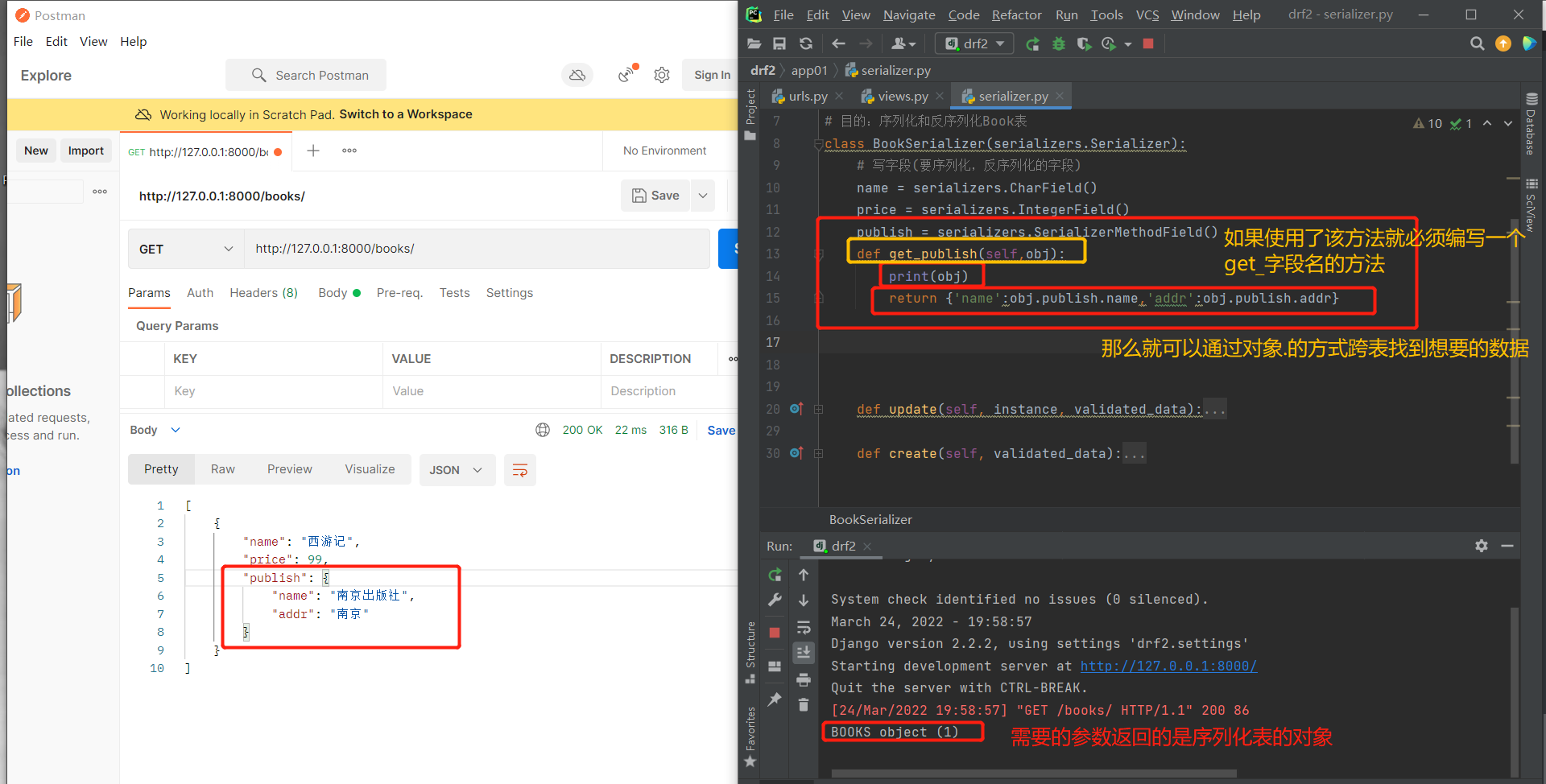
source主要作用:就是用来做一对多,多对多的字段返回。
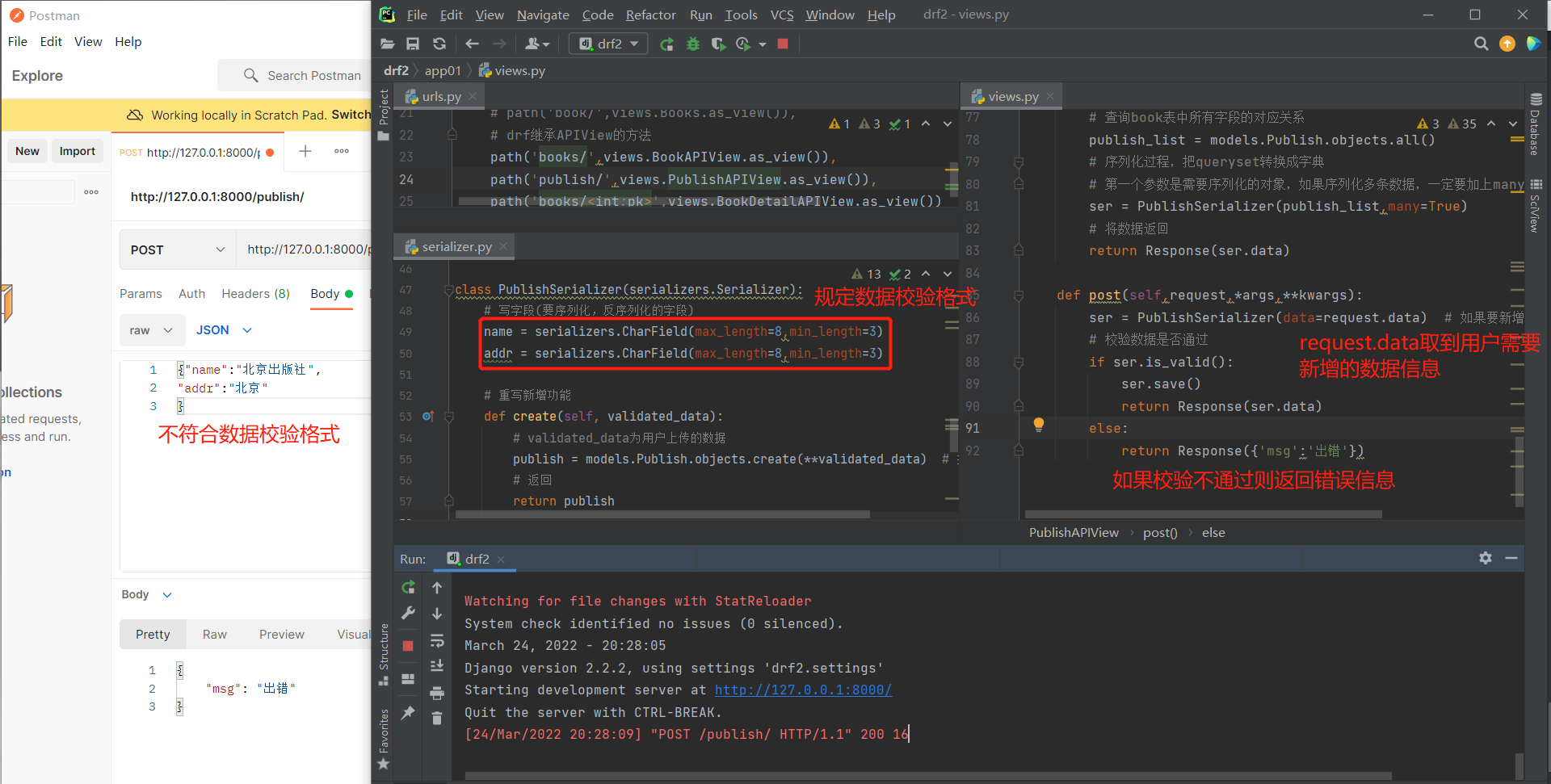
数据校验
# urls.py
path('publish/',views.PublishAPIView.as_view()),
# serializer.py
class PublishSerializer(serializers.Serializer):
# 写字段(要序列化,反序列化的字段)
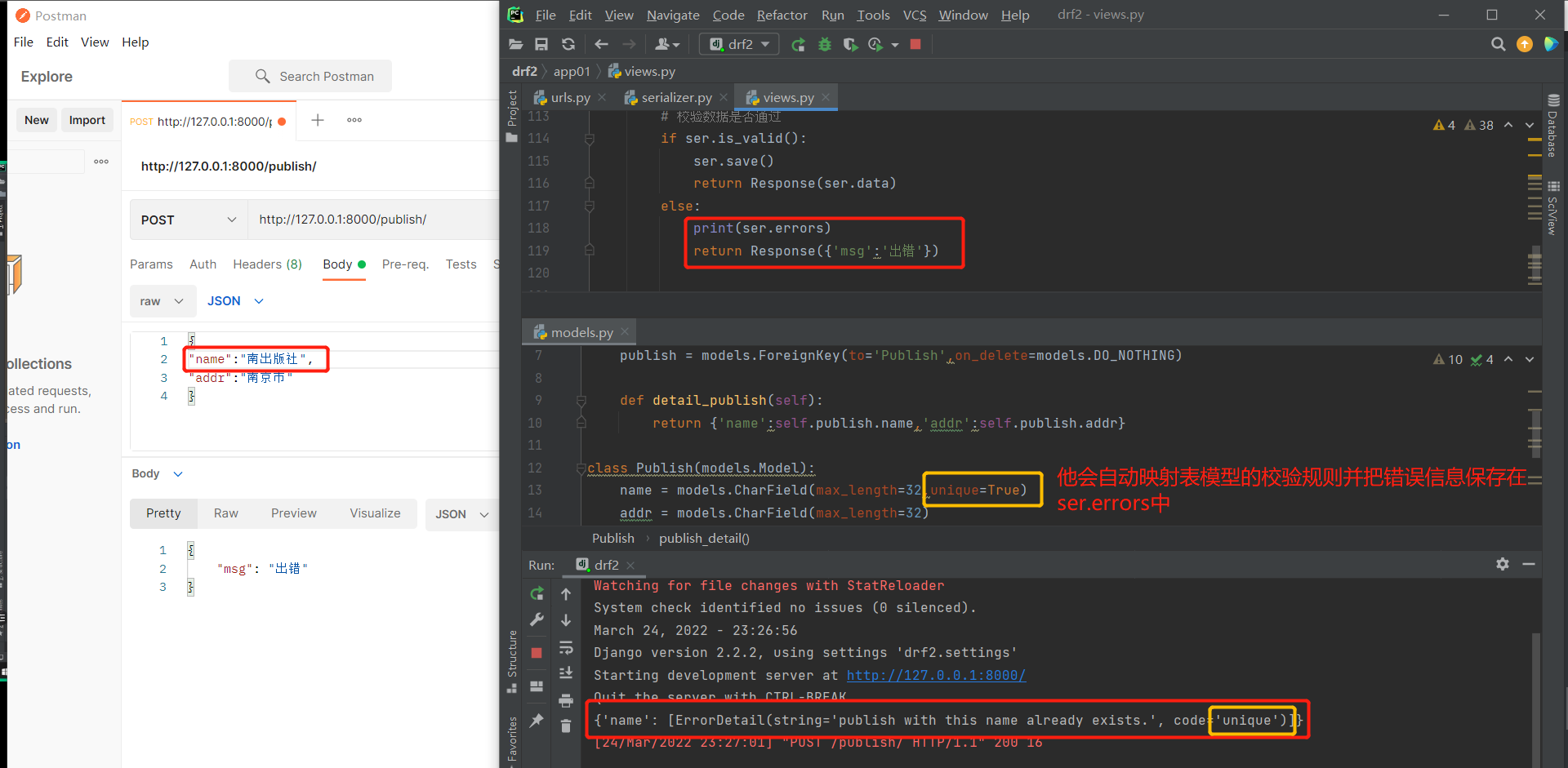
name = serializers.CharField(max_length=8,min_length=3) # 编写数据校验规范
addr = serializers.CharField(max_length=8,min_length=3)
# 重写新增功能
def create(self, validated_data):
# validated_data为用户上传的数据
publish = models.Publish.objects.create(**validated_data) # 打散保存
# 返回
return publish
# views.py
class PublishAPIView(APIView):
def get(self,request,*args,**kwargs):
# 查询book表中所有字段的对应关系
publish_list = models.Publish.objects.all()
# 序列化过程,把queryset转换成字典
# 第一个参数是需要序列化的对象,如果序列化多条数据,一定要加上many=True
ser = PublishSerializer(publish_list,many=True)
# 将数据返回
return Response(ser.data)
def post(self,request,*args,**kwargs):
ser = PublishSerializer(data=request.data) # 如果要新增就不需要传instance
# 校验数据是否通过
if ser.is_valid():
ser.save()
return Response(ser.data)
else:
return Response({'msg':'出错'})
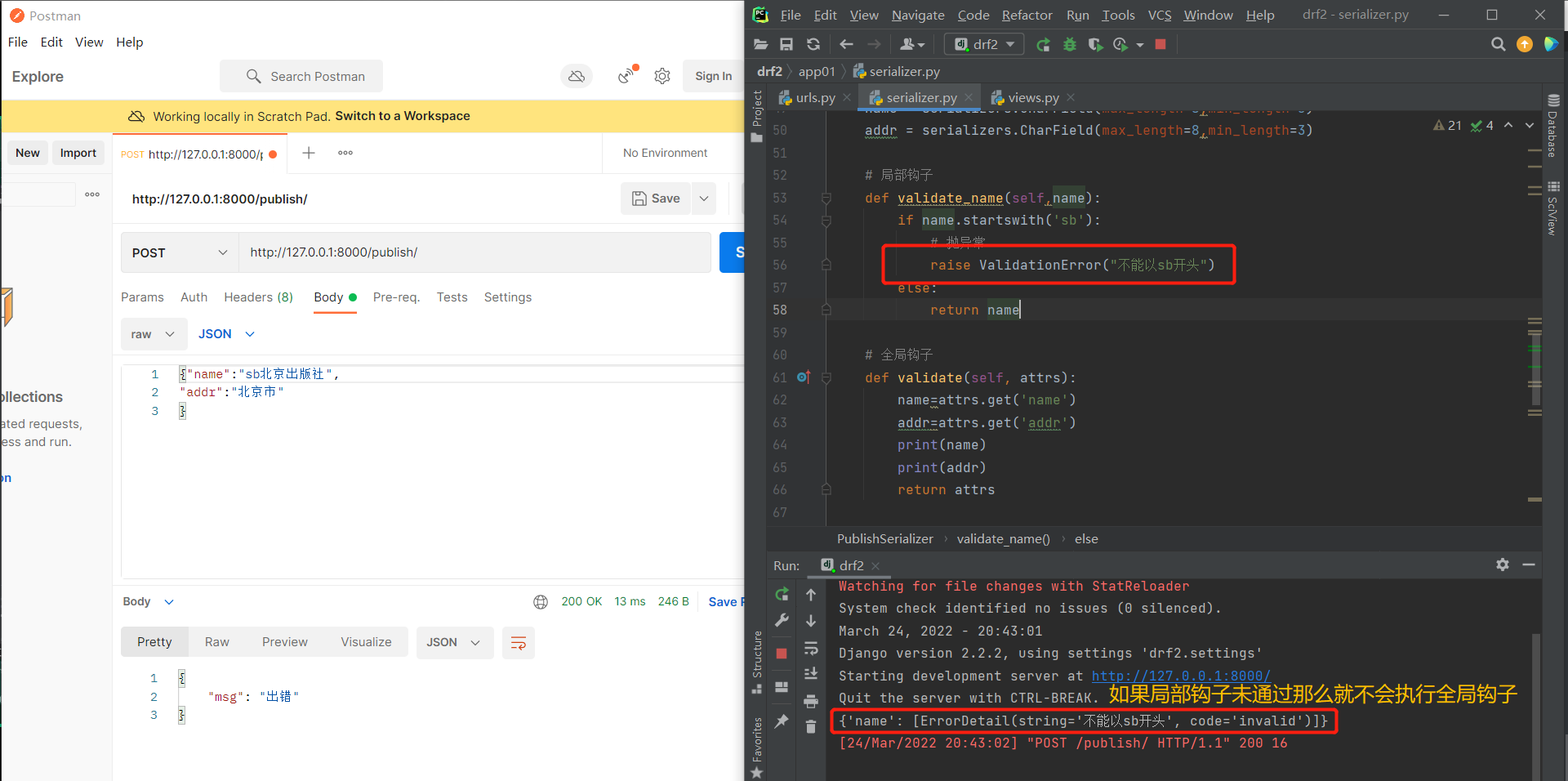
局部钩子
# 局部钩子
def validate_name(self,name):
if name.startswith('sb'):
# 抛异常
raise ValidationError("不能以sb开头")
else:
return name
全局钩子
# 全局钩子
def validate(self, attrs): # attrs存放的就是request.data的数据
name=attrs.get('name')
addr=attrs.get('addr')
return attrs
模型类序列化器
# 创建模型类序列化类需要继承 serializers.ModelSerializer
# 如果想要使用该序列化器记得修改views.py视图层函数
# create和update不需要重写,它帮我们封装好了
# 创建模型类序列化器
class PublishModelSerializer(serializers.ModelSerializer):
class Meta: # 这里就不需要写对应的字段,直接写对应的表即可
model = models.Publish # 对应Publish表
fields = ['id','name'] # 序列化哪些字段 (只序列化id,name字段)
fields = '__all__' # 序列化全部字段
fields = ['id','publish_detail'] # 也可序列化模型类中的方法
exclude = ['id'] # 除了id字段其他都序列化(但不会存在方法)
# 创建模型类序列化器
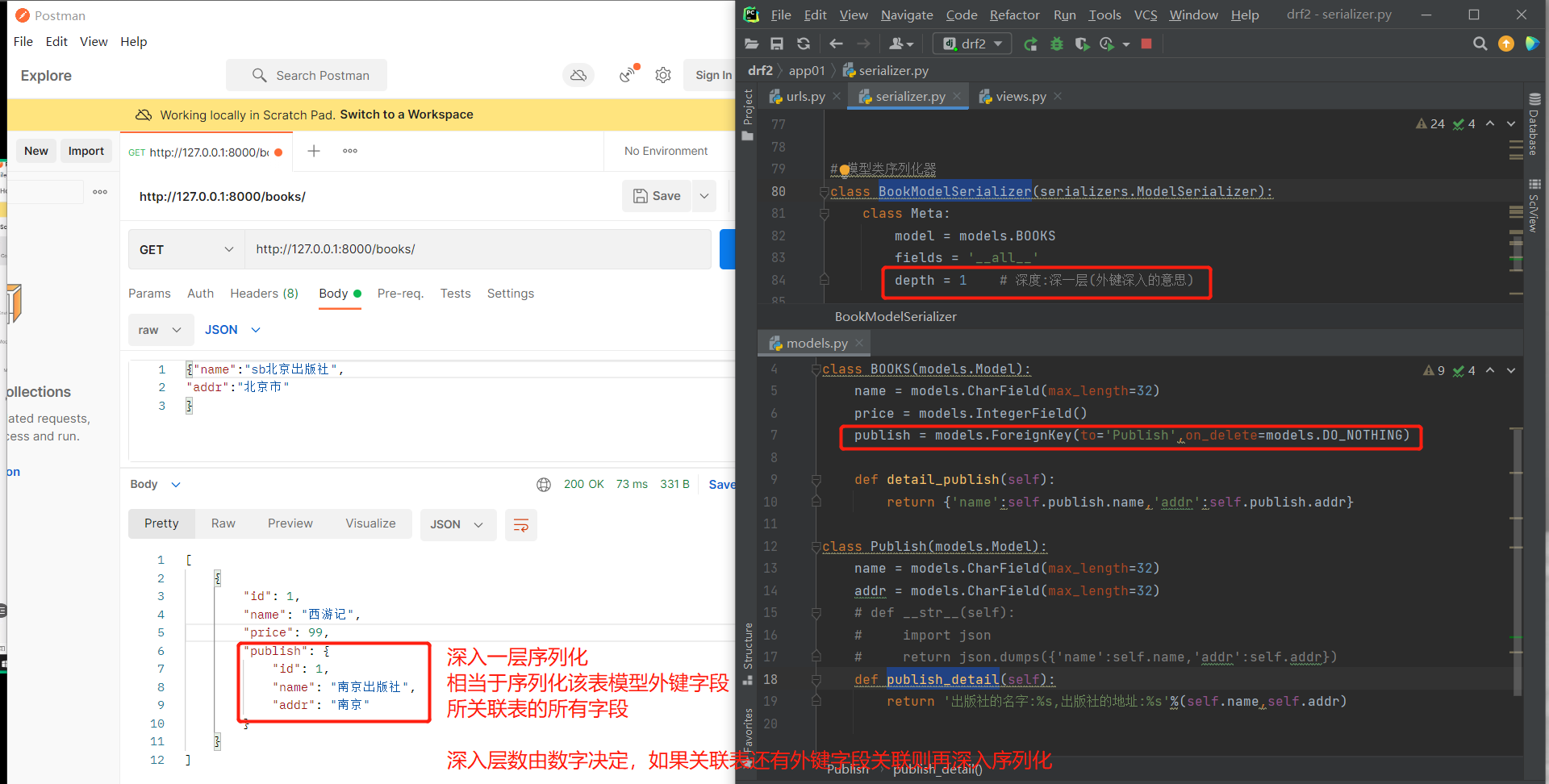
class BookModelSerializer(serializers.ModelSerializer):
class Meta:
model = models.BOOKS
fields = '__all__'
depth = 1 # 深度:深一层(外键深入的意思) 非常耗费效率,不能控制深入后想要查询的字段,不建议使用,写多层不会报错,有几层就深入几层
参数总结:
fields = ['id','name'] # 序列化哪些字段 (只序列化id,name字段)
fields = '__all__' # 序列化全部字段
fields = ['id','publish_detail'] # 也可序列化模型类中的方法
exclude = ['id'] # 除了id字段其他都序列化(但不会存在方法)
depth = 1 # 深度:深一层(外键深入的意思) 非常耗费效率,不能控制深入后想要查询的字段,不建议使用,写多层不会报错,有几层就深入几层
重写字段:
# 重写字段SerializerMethodField和初始序列化类使用方法一样
name = serializers.SerializerMethodField()
def get_name(self,obj):
return '出版社:'+obj.name
添加字段:
# 添加字段和初始化序列化类使用方法一样
publish_detail = serializers.CharField(source='publish_detail')
字段校验映射:
# 自己的字段校验规则:映射了表模型的规则(如果校验失败则同样会添加到ser.errors错误信息中)
局部钩子与全局钩子:
# 与初始序列化类使用方法完全一致
# 局部钩子
def validate_name(self,name):
if name.startswith('sb'):
# 抛异常
raise ValidationError("不能以sb开头")
else:
return name
# 全局钩子
def validate(self, attrs): # attrs存放的就是request.data的数据
name=attrs.get('name')
addr=attrs.get('addr')
return attrs
write_only()与read_only()方法
### write_only只写
反序列化时候使用,序列化的时候不用
### read_only只读
序列化的时候使用,反序列化的时候不用
# 使用场景
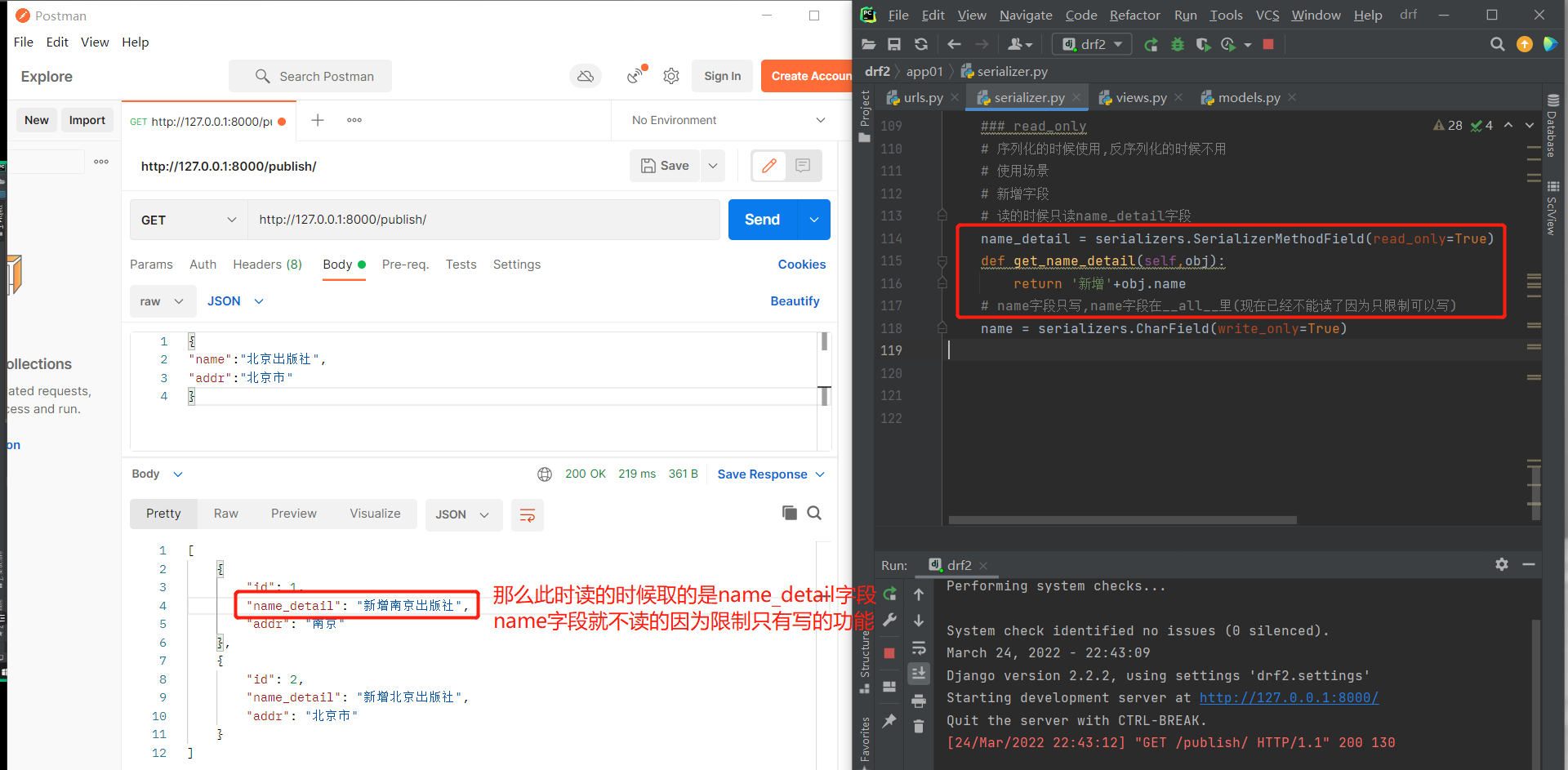
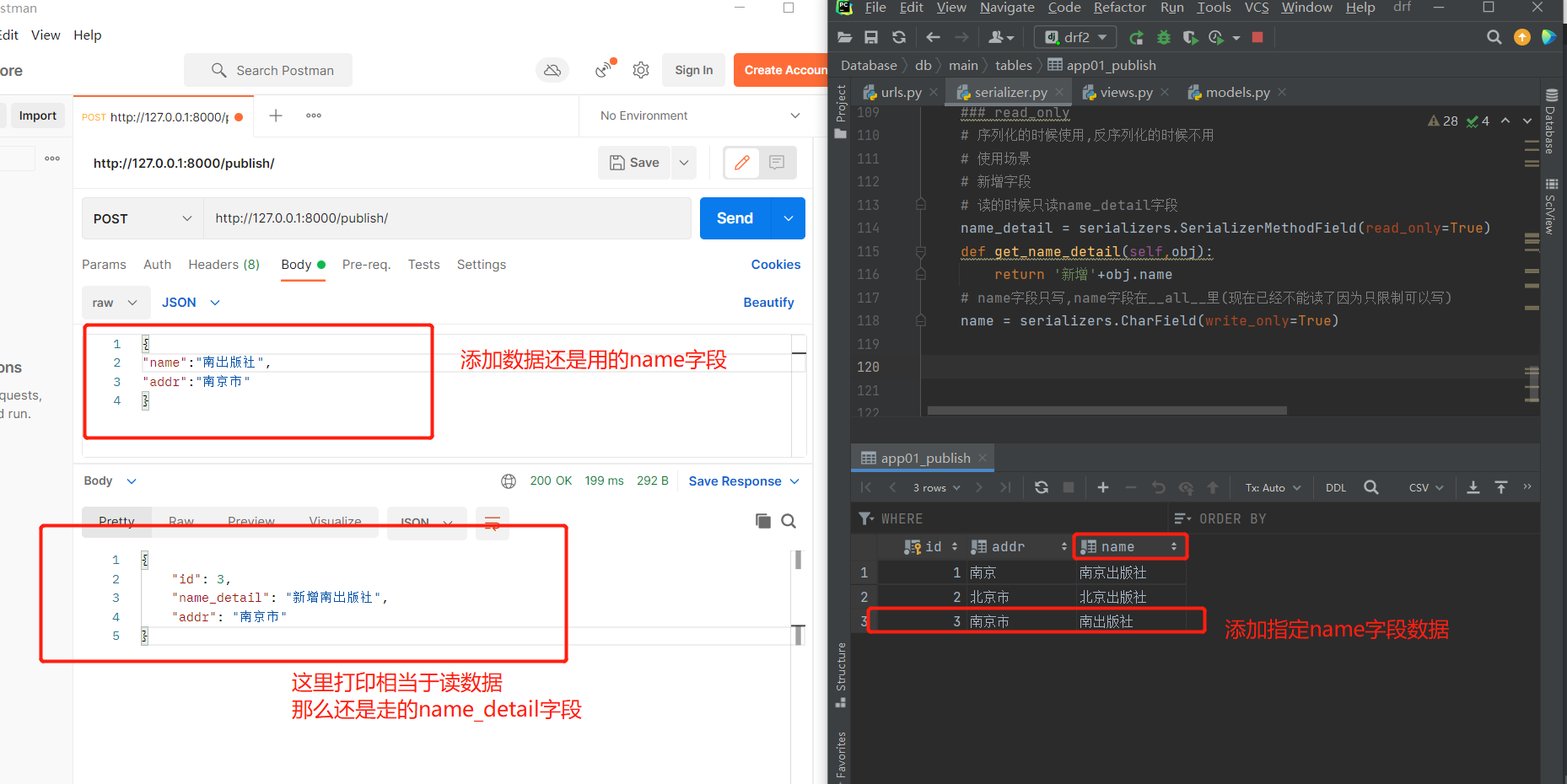
# 新增字段
# 读的时候只读name_detail字段
name_detail = serializers.SerializerMethodField(read_only=True)
def get_name_detail(self,obj):
return '新增'+obj.name
# name字段只写,此时的name字段在__all__里(现在已经不能读了因为只限制可以写)
name = serializers.CharField(write_only=True)
额外给字段添加参数:
# 上述这样如果有很多字段需要限制只读只写参数的话非常的麻烦
# 需要编写在class META:类中
# 额外给字段传递额外参数关键字:extra_kwargs
extra_kwargs = {'name': {'write_only': True}}
# 相当于:name = serializers.CharField(write_only=True)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号