Django | ORM数据库慢查询优化
数据库查询优化
引子:
准备工作:
settings.py添加该配置参数:
# 只要操作数据库那么就会打印sql语句
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
惰性查询特点
# 惰性查询:如果只是书写了orm语句,在后面根本没有用到该语句所查询出来的参数,那么orm会自动识别出来,直接不执行。
# 举例:
res = models.Book.objects.all() # 这时orm是不会走数据库的
print(res) # 只有当要用到的上述orm语句的结果时,才回去数据库查询。


# 我们下来做一个题目:
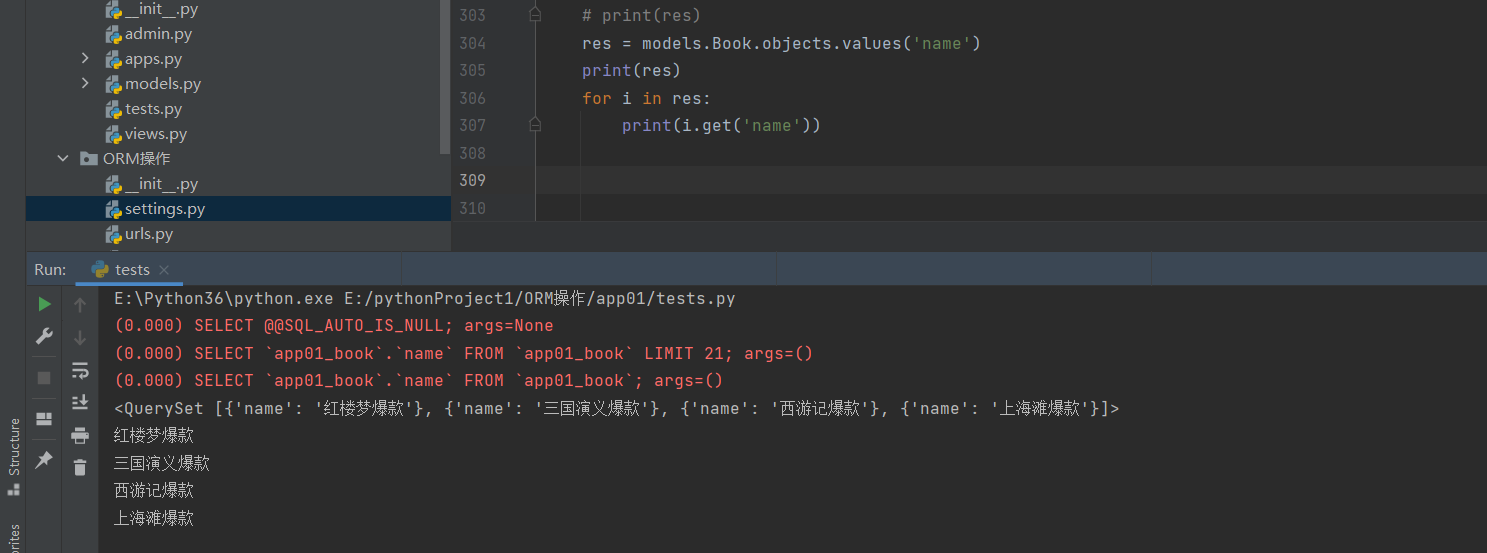
获取数据表中所有数的名字:
res = models.Book.objects.values('name')
print(res) # 拿到的是列表套字典的形式
for i in res:
print(i.get('name')) # for循环出字典,通过.get方法取出每个书的名字
# 那么如何实现获取到的是一个数据对象,然后点title就能够拿到书名,并且没有其他字段。
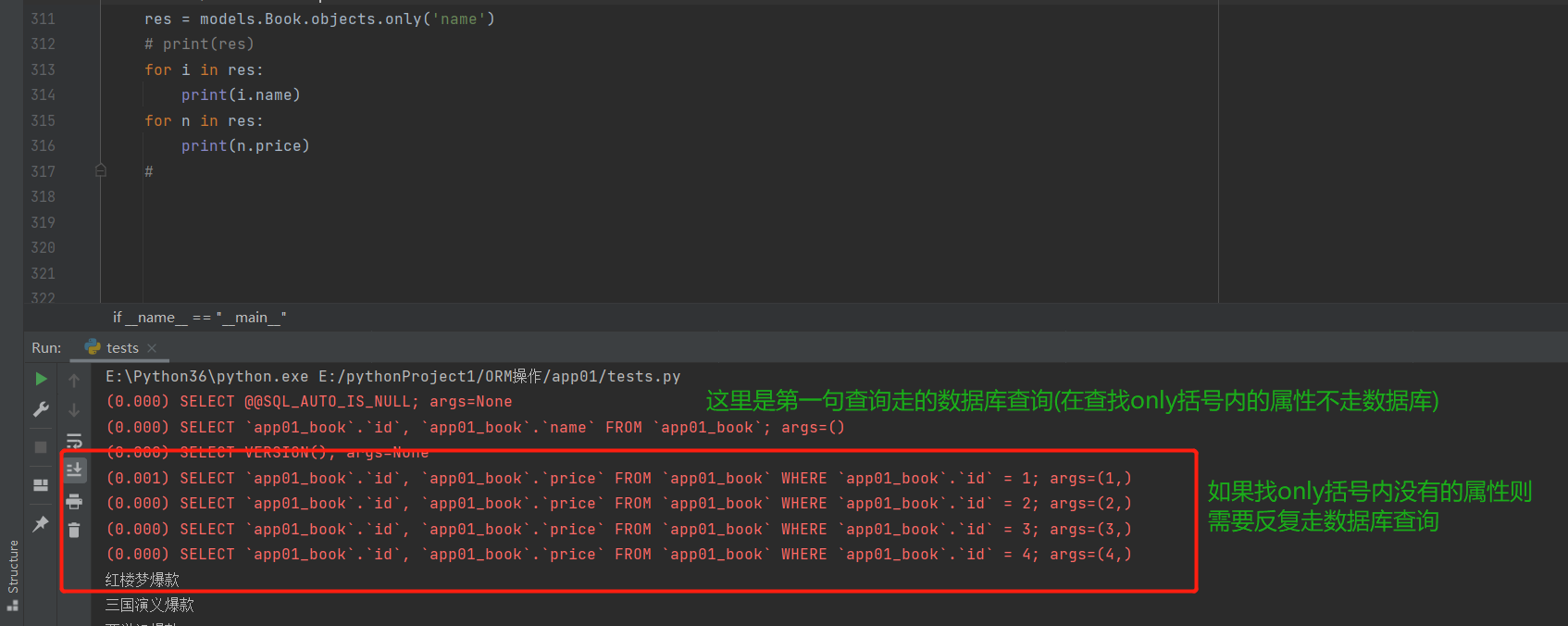
only用法:
res = models.Book.objects.only('name') # 对象只有name属性
print(res)
for i in res:
print(i.name) # 如果点(.)only括号内有的字段,不走数据库
print(i.price) # 如果点(.)only括号内没有的字段,那么会反复走数据库去查询(查询一个返回一个)而all()不需要
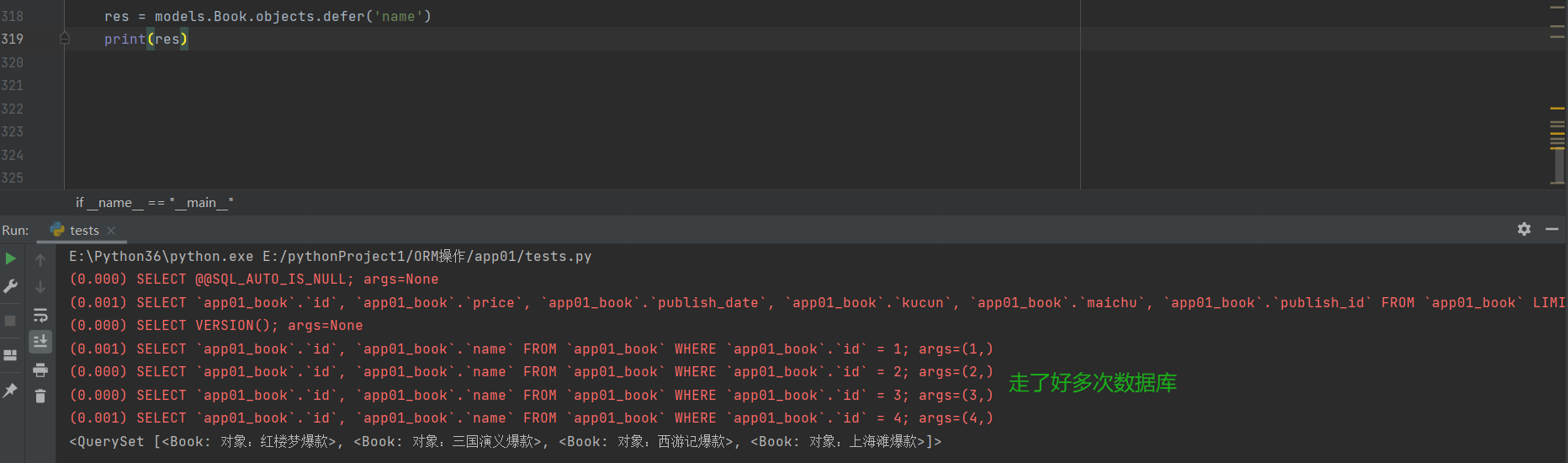
defer用法
res = models.Book.objects.defer('name') # 对象除了没有name属性之外其他的都有
for i in res:
print(i.price)
"""
defer与only刚好相反
defer括号内放的字段不在查询出来的对象里面 查询该字段需要重新走数据
而如果查询的是非括号内的字段 则不需要走数据库了
"""

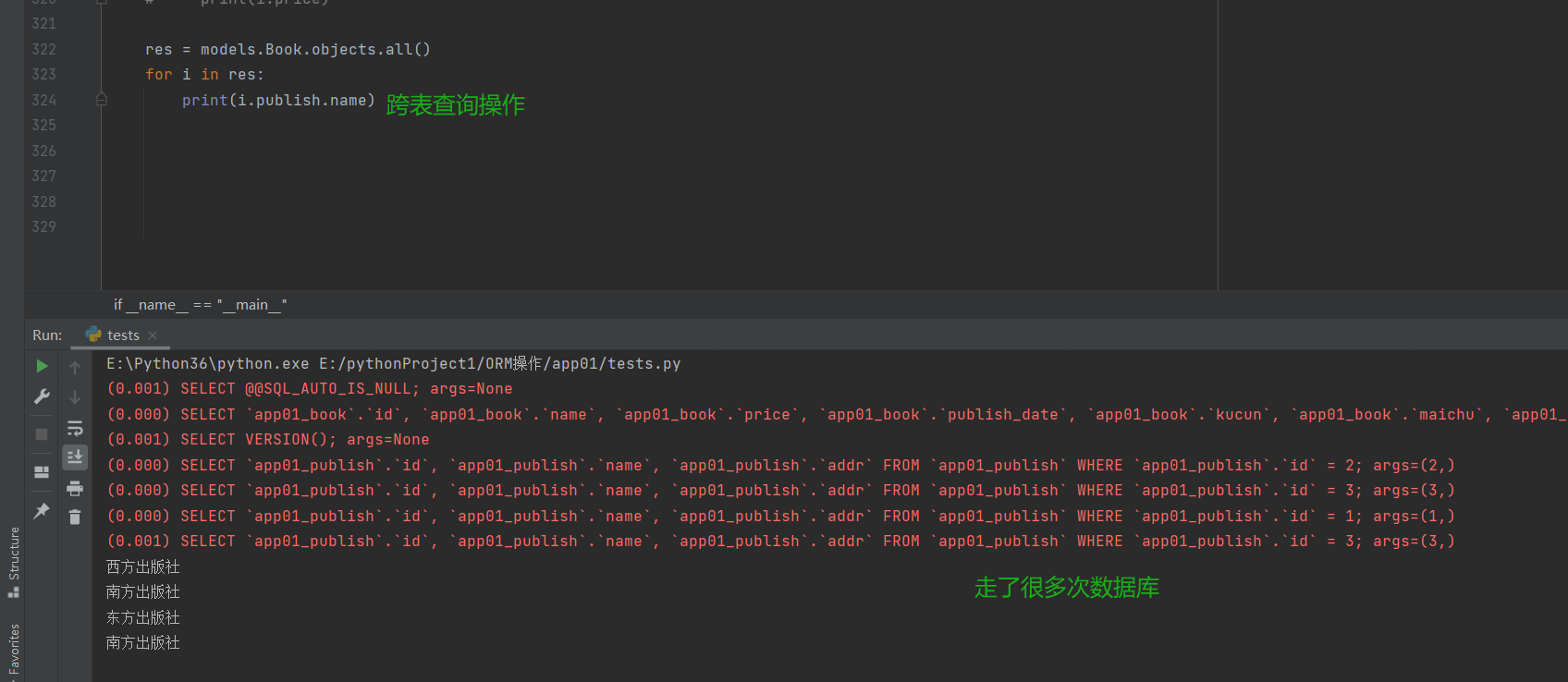
select_related联表操作
# 跟跨表操作有关
示例:
# 查询每本书的出版社名字
res = models.Book.objects.all()
for i in res:
print(i.publish.name)
# 使用all方法查询的时候,每一个对象都会去数据库查询数据
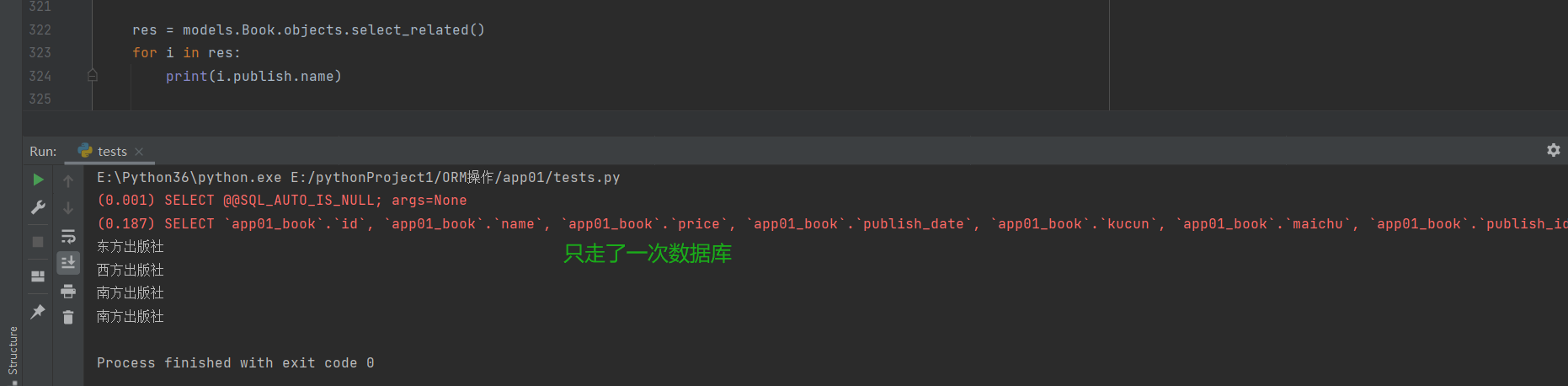
# 使用select_related()
res = models.Book.objects.select_related()
for i in res:
print(i.publish.name) # 直走一次数据库 INNER JOIN链表操作
"""
select_related内部直接先将book与publish连起来 然后一次性将大表里面的所有数据
全部封装给查询出来的对象
这个时候对象无论是点击book表的数据还是publish的数据都无需再走数据库查询了
select_related括号内只能放外键字段 一对多 一对一
多对多也不行
"""
# 这样就比all方法更加的优化一点,这样网络请求就少了,延迟就降低了,提高效率。
prefetch_related子查询
# 跟跨表操作有关
res = models.Book.objects.prefetch_related('publish') # 子查询
for i in res:
print(i.publish.name)
"""
prefetch_related该方法内部其实就是子查询
将子查询查询出来的所有结果也给你封装到对象中
给你的感觉好像也是一次性搞定的
"""

总结:
# prefetch_related对比select_related少了一次查询
# 到底孰优孰劣呢?
各有优缺点:如果表特别特别大的时候使用prefetch_related品表阶段就要耗费很长的时间,而select_related子查询虽然查询两次,但是操作两个表的时间非常短效率就会胜于联表查询prefetch_related

 浙公网安备 33010602011771号
浙公网安备 33010602011771号