Django | ORM操作(单表查询关键字操作)
djangoORM操作
测试脚本:
# 当我们只想操作django中某一个py文件内容时,那么可以不用书写前后端交互的形式来判断运行结果是否正确,我们可以直接写一个测试脚本即可。
在我们创建应用的时候,会自动创建一个tests.py文件,我们可以在这里编写测试脚本。
# 测试环境准备:去manage.py文件中拷贝下述代码到测试文件,然后自己配置两行,如下:
import os
# from app01 import models.py 不可以写在这里
if __name__ == "__main__":
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day64.settings")
import django
django.setup() # 这就相当于启动django
# 在这个代码块的下面就可以测试django里面的单个py文件了
# 注意:如果测试的脚本需要用到模块,必须写在配置好的环境下面,不可在最外层导入模块使用
eg:
from app01 import models.py
单表操作
# Django自带的SQlite3数据库对数据格式的数据不是很敏感,处理的时候也容易出错
补充:
# 1、存储时间格式数据:
models.DateField() # 日期字段:存储年月日
models.DateTimeField() # 日期字段:存储年月日时分秒
'参数':
auto_now : 每次更新操作数据的时候 该字段会自动将当前时间更新
auto_now_add : 在创建数据的时候会自动将当前创建时间记录下来,之后只要不人为的修改,那么时间就一直不变(比如用户的注册时间记录下来,到时间了会赠送一些礼品什么的)
# 2、pk关键字
作用:pk会自动查找到当前表的主键字段 指代的就是当前表的主键字段
优点:用了pk之后 你就不需要指代当前表的主键字段到底叫什么了(nid,pid,uid....)
# 3、.get()方法
作用:.get()方法可直接拿到当前用户对象
eg:
user_obj = models.User.objects.get(pk=1) # 直接拿到id=1的用户对象
相当于:
user_obj = models.User.objects.filter(pk=1).first()
# 但是不推荐使用get方法:因为一旦数据不存在那么使用该方法就会立刻报错
而使用filter方法如果数据不存在则返回空列表[]不会报错
表的增:
# 方式一:
res = models.User.objects.create(name='jack',age=19,register_time='2000-1-2')
print(res) # 返回值为当前被创建对象本身
# 方式二:
import datetime
ctime = datetime.datetime.now() # 当前时间
user_obj = models.User(name='tom',age=10,register_time=ctime) # 也可存入一个日期对象
user_obj.save()
表的删:
# 方式一:
res = models.User.objects.filter(pk=2).delete()
print(res) # 返回值为当前sql语句影响的行数(到底删了几行)
# 方式二:
user_obj = models.User.objects.filter(pk=1).first() # 拿到当前用户对象
user_obj.delete() # 用户对象也有delete方法
表的修改:
# 方式一:
models.User.objects.filter(pk=4).update(name='tom2222') # 匹配到id=4的记录并只修改name属性
# 方式二:
user_obj = models.User.objects.get(pk=4)
user_obj.name = 'tom3333'
user_obj.save()
orm查询方法(必知必会关键字):
补充:
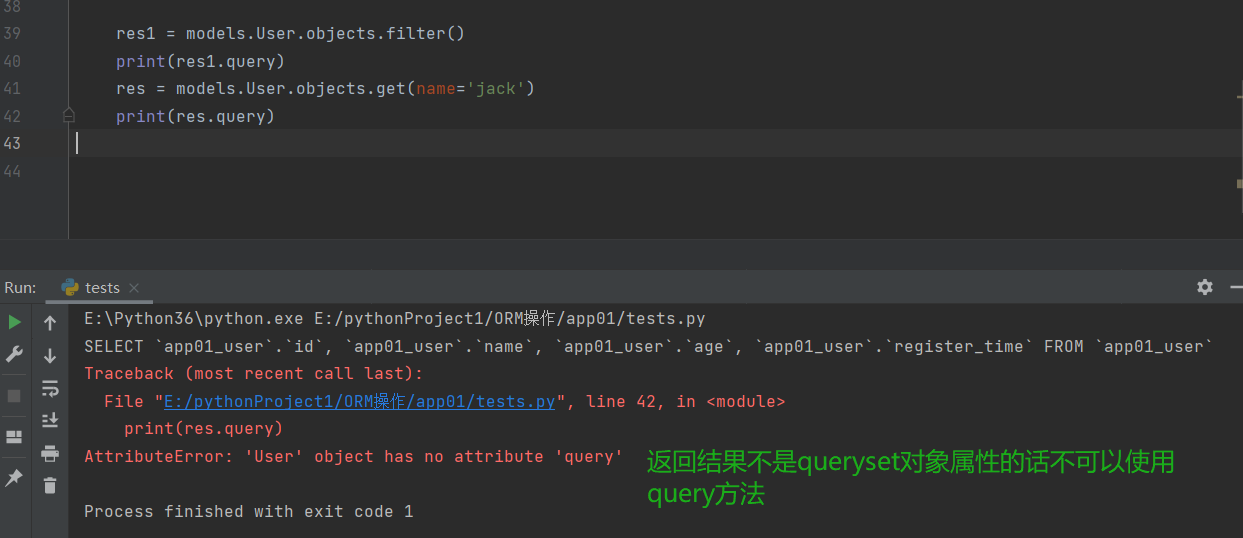
# .query方法
.query方法可查看内部封装的sql语句
但是使用该方法查看sql语句的方式,只能用于queryset对象属性
只有返回结果为queryset对象才能够使用
eg:
res1 = models.User.objects.filter()
print(res1.query)
res = models.User.objects.get(name='jack')
print(res.query)
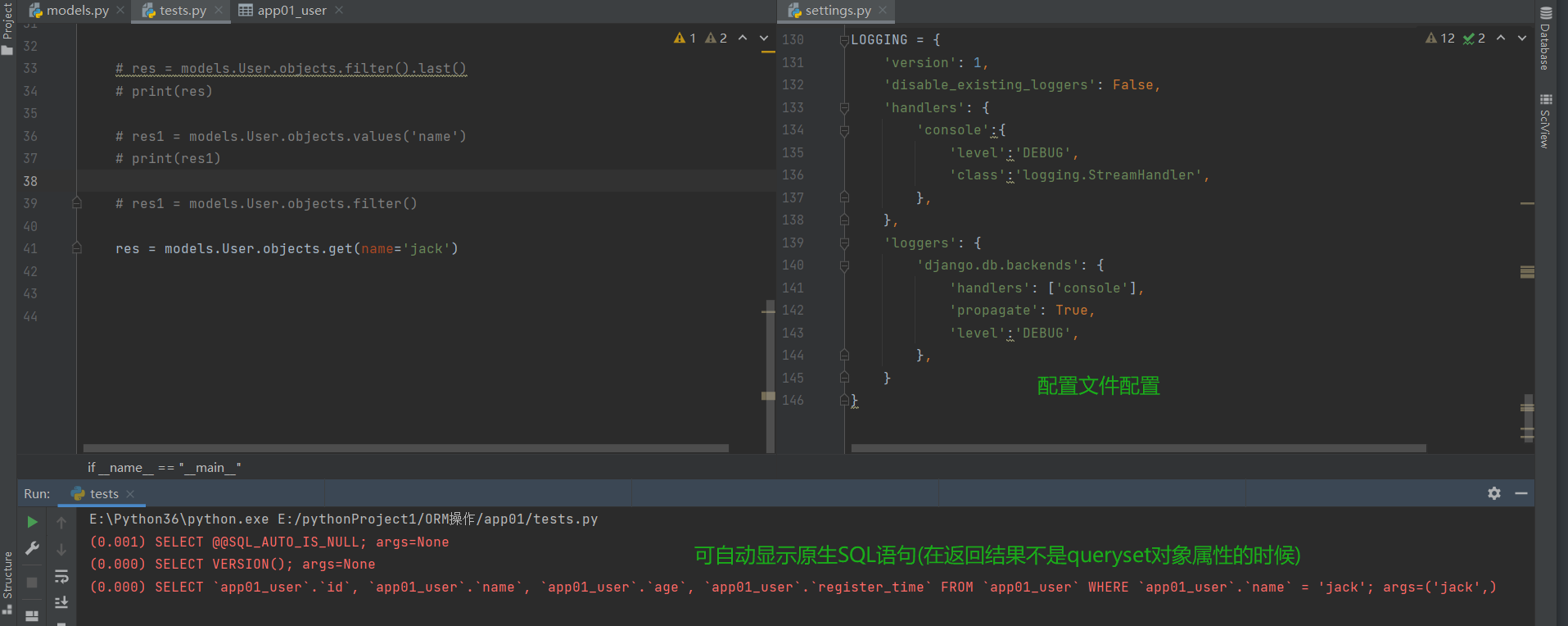
# 解决:所有的sql语句都能查看
# 将下述代码放到配置文件里
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
准备工作:
models.py:
class User(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField()
register_time = models.DateField()
def __str__(self):
return '对象:%s'%self.name # 在执行打印命令时执行

test.py:
all()
# 查询所有数据
res = models.User.objects.all() # 括号内不可添加筛选条件
print(res)
# 结果:<QuerySet [<User: 对象:jack>, <User: 对象:tom>]>
filter()
# 带有过滤条件的查询
res = models.User.objects.filter(pk=2) # 括号内可添加筛选条件
print(res)
# 结果:<QuerySet [<User: 对象:tom>]>
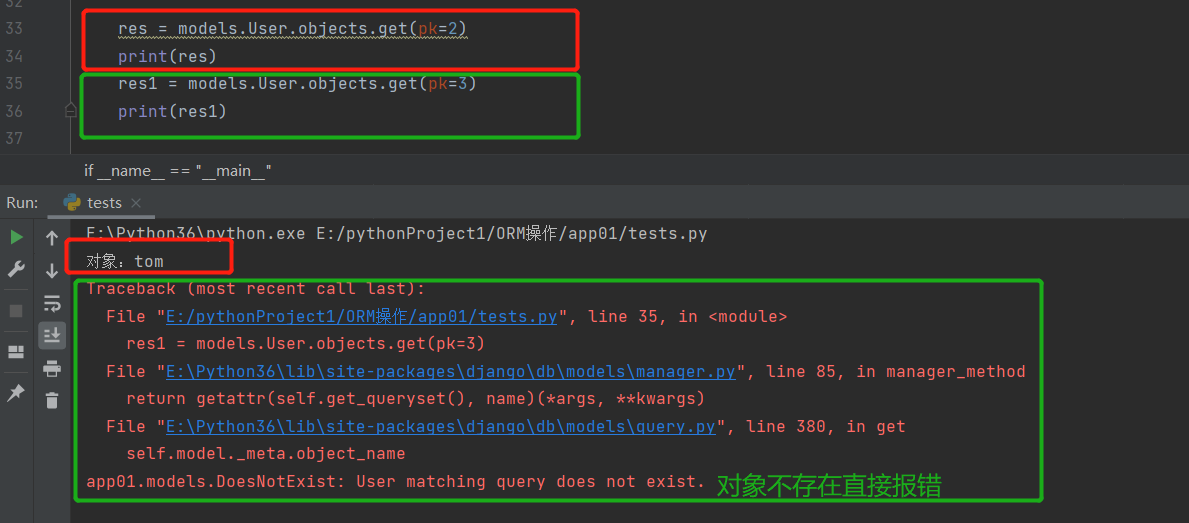
get()
# 直接拿数据对象,但是条件所匹配的数据不存在则直接报错
res = models.User.objects.get(pk=2)
print(res) # 结果 对象:tom
res1 = models.User.objects.get(pk=3)
print(res1) # 结果 报错
first()
# 拿queryset里面的第一个元素
res = models.User.objects.filter().first()
print(res)
# 结果:对象:jack
last()
# 拿queryset里面的最后一个元素
res = models.User.objects.filter().last()
print(res)
# 结果:对象:tom
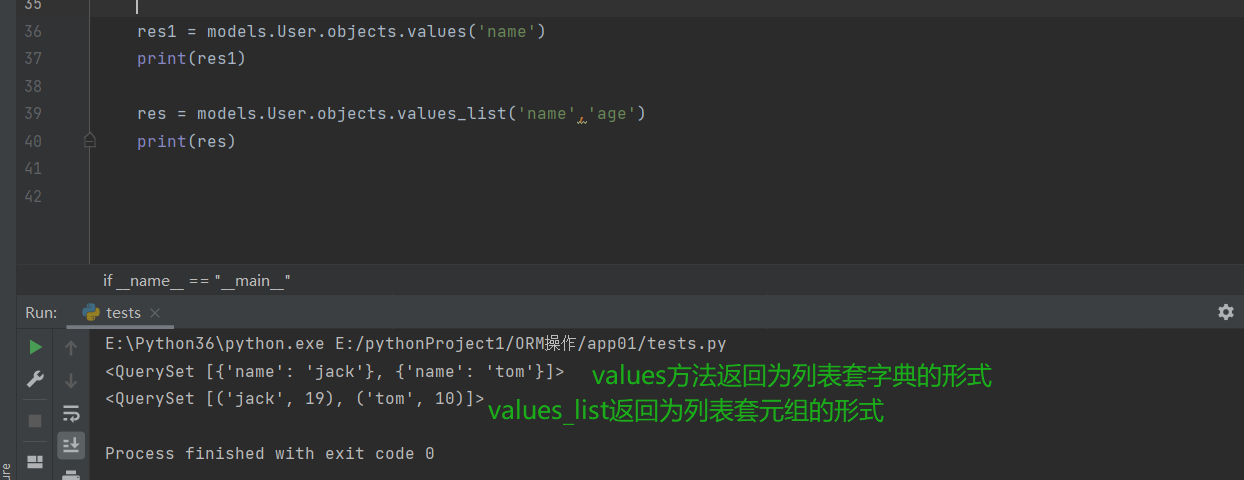
values()
# 可指定获取的字段
# 返回结果可以看作是列表套字典的形式
# 拿到所有用户的信息
res = models.User.objects.values()
print(res)
# 结果:<QuerySet [{'id': 1, 'name': 'jack', 'age': 19, 'register_time': datetime.date(2000, 1, 2)}, {'id': 2, 'name': 'tom', 'age': 10, 'register_time': datetime.date(2022, 2, 26)}]> # 列表套字典的形式
eg:
# 1、只拿用户的名字
res = models.User.objects.values('name')
print(res)
# 结果:<QuerySet [{'name': 'jack'}, {'name': 'tom'}]>
# 2、只拿用户的名字和年龄
res = models.User.objects.values('name','age')
print(res)
# 结果:<QuerySet [{'name': 'jack', 'age': 19}, {'name': 'tom', 'age': 10}]>
相当于sql语句:select name,age from user
values_list()
# 同样可以指定需要获取的字段
# 但返回结果可以看作是列表套元组的形式
res = models.User.objects.values()
print(res)
# 结果:<QuerySet [(1, 'jack', 19, datetime.date(2000, 1, 2)), (2, 'tom', 10, datetime.date(2022, 2, 26))]>
distinct()
# 去重
# 注意:去重一定要是一摸一样的数据(一定要考虑主键),一个对象如果包含主键的话永远去不了重复数据
res = models.User.objects.filter().distinct()
print(res) # 查所有:无意义,因为包含主键
res1= models.User.objects.values('name').distinct()
print(res1) # 按照name字段去重
# 结果:
# <QuerySet [<User: 对象:jack>, <User: 对象:tom>, <User: 对象:jack>, <User: 对象:gary>]>
# <QuerySet [{'name': 'jack'}, {'name': 'tom'}, {'name': 'gary'}]>
order_by()
# 排序
.order_by('age') # 默认升序
.order_by('-age') # 降序在参数前加一个-
# eg:
res1 = models.User.objects.values('age').order_by('age')
print(res1) # 升序
res = models.User.objects.order_by('-age')
print(res) # 降序
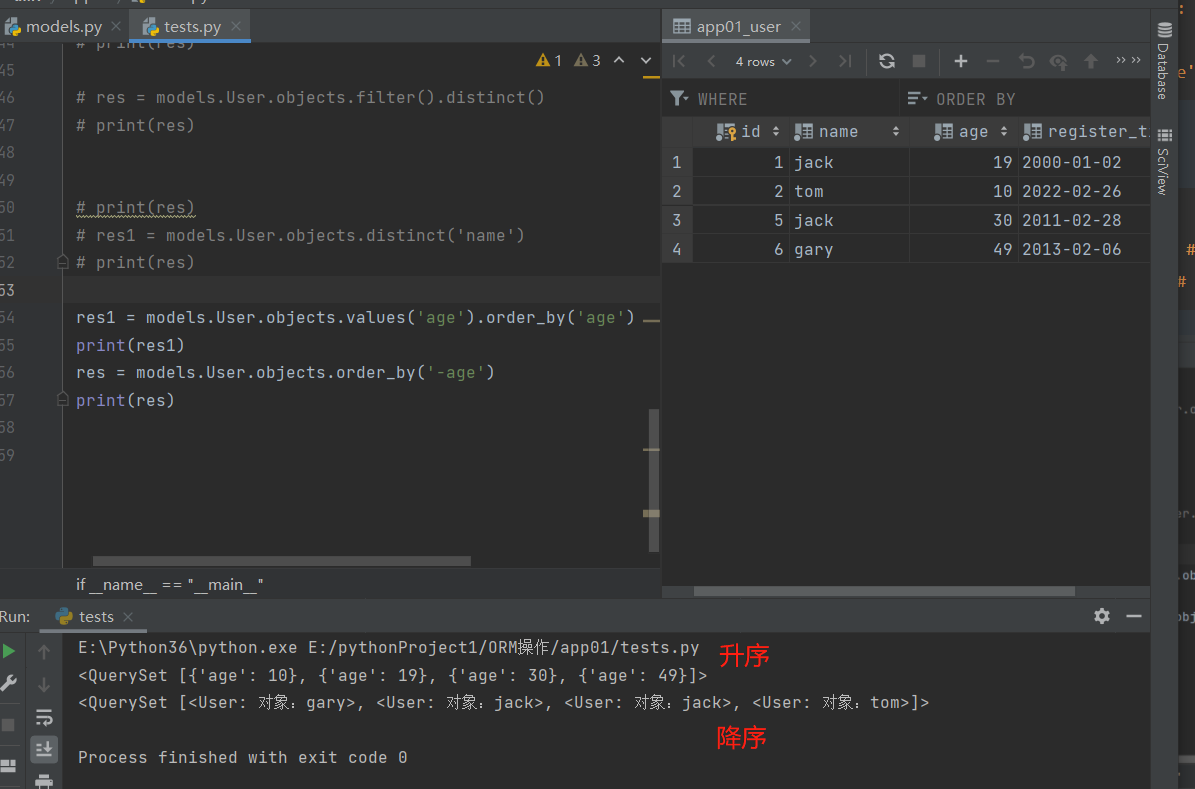
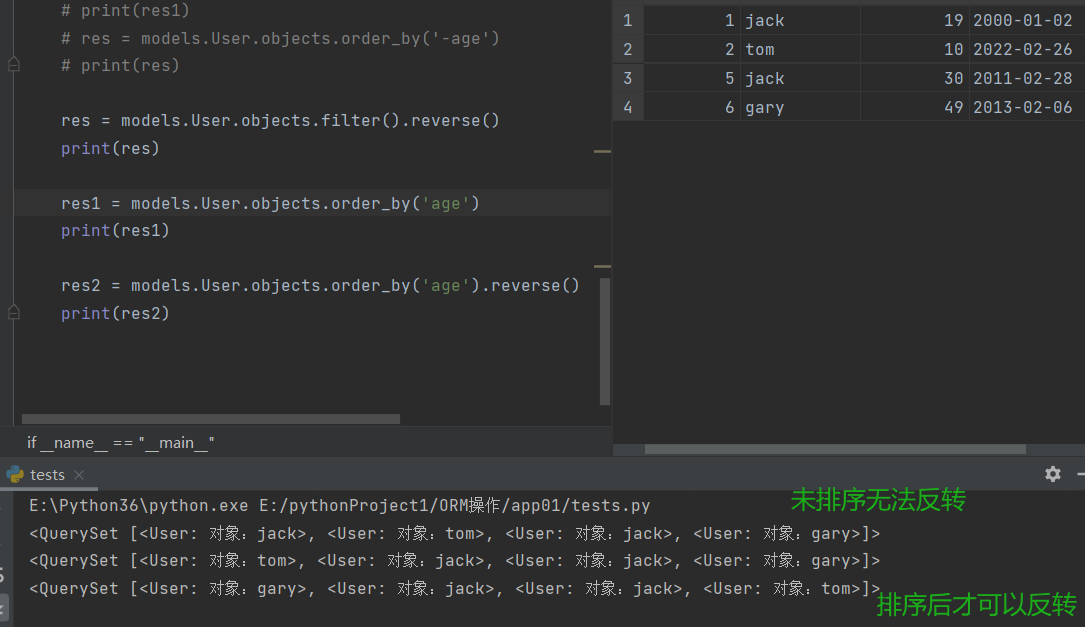
reverse()
# 反转
# 前提:数据已经排序了,如果没排序是不支持反转的,必须提前排序过。
order_by().reverse() # 通常情况下跟order_by联合使用
# eg:
res = models.User.objects.filter().reverse()
print(res)
res1 = models.User.objects.order_by('age')
res2 = models.User.objects.order_by('age').reverse()
print(res2)
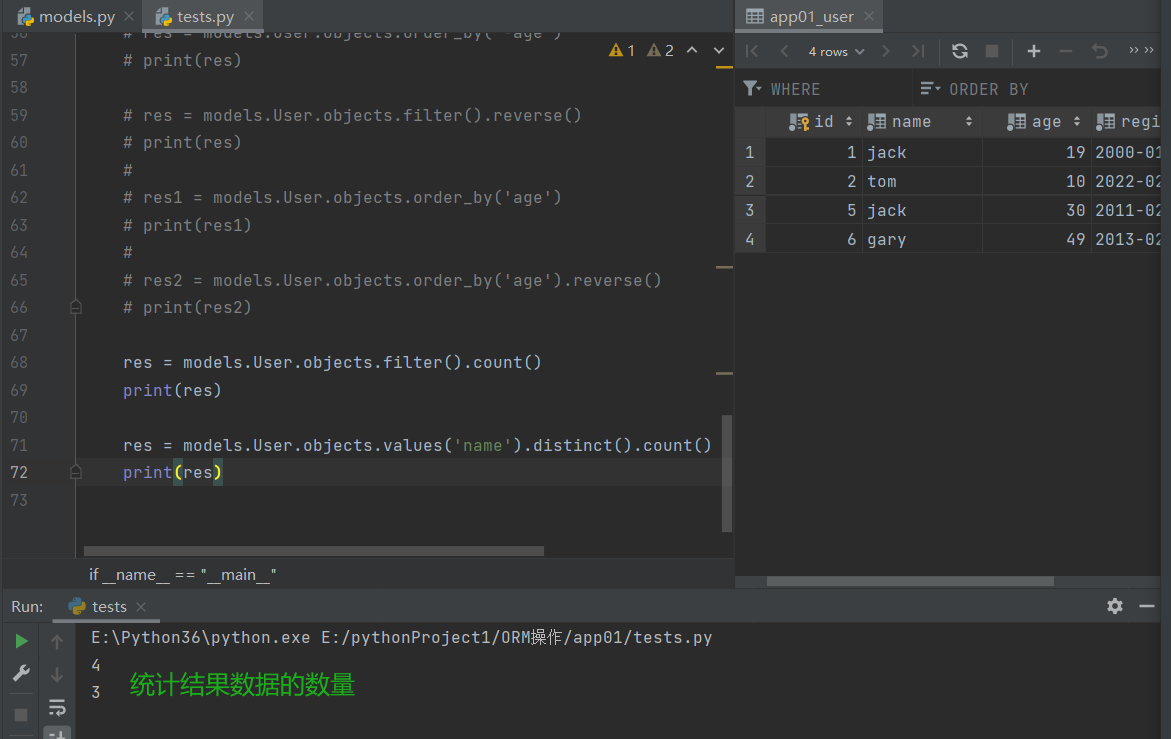
count()
# 统计当前数据的个数
res = .count()
# eg:
res = models.User.objects.filter().count()
print(res) # 统计所有数据对象的个数
res = models.User.objects.values('name').distinct().count()
print(res) # 按照name去重之后统计数据个数
# 结果:
4
3
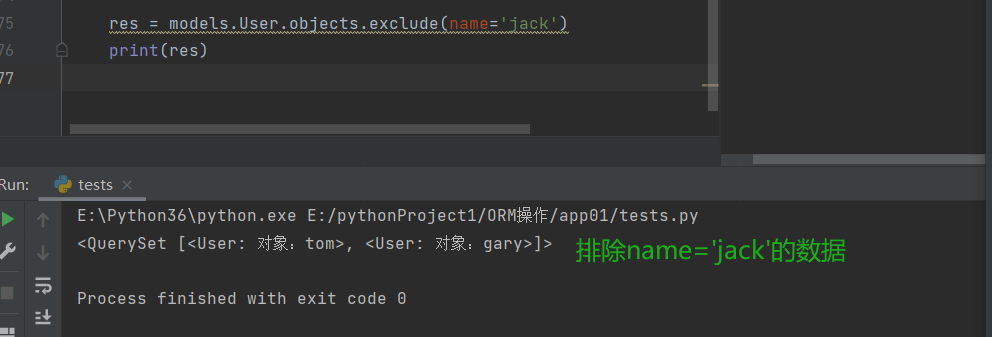
exclude()
# .exclude() # 排除(括号内匹配成功)之外的数据
# eg:
res = models.User.objects.exclude(name='jack')
print(res)
# 查询name = 'jack'之外的数据
exists()
# 判断是否存在 返回的是布尔值
# 作用不大:因为数据本身就存在布尔值
# eg:
res = models.User.objects.filter(pk=1).exists()
print(res)
res1 = models.User.objects.filter(pk=200)
print(res1)
res2 = models.User.objects.filter(pk=200).exists()
print(res2)
# 结果:
True
<QuerySet []>
False

 浙公网安备 33010602011771号
浙公网安备 33010602011771号