mysql之查询关键字 筛选|分组|去重|排序|分页|正则|判断

目录
查询关键字
前期准备(可以拿来练习):
创建表:
create table emp(
id int primary key auto_increment,
name varchar(20) not null,
sex enum('male','female') not null default 'male', # 默认为男的
age int(3) unsigned not null default 28,
hire_date date not null, # 雇佣日期
post varchar(50), # 职业
post_comment varchar(100), # 员工描述
salary double(15,2), # 薪资
office int, # 门牌号:一个部门一个屋子
depart_id int # 编号
);
插入记录:
#三个部门:教学,销售,运营
insert into emp(name,sex,age,hire_date,post,salary,office,depart_id) values
('jaso','male',18,'20170301','第一讲师',7300.33,401,1), #以下是教学部
('tom','male',78,'20150302','teacher',1000000.31,401,1),
('kevin','male',81,'20130305','teacher',8300,401,1),
('tony','male',73,'20140701','teacher',3500,401,1),
('owen','male',28,'20121101','teacher',2100,401,1),
('jack','female',18,'20110211','teacher',9000,401,1),
('jenny','male',18,'19000301','teacher',30000,401,1),
('sank','male',48,'20101111','teacher',10000,401,1),
('哈哈','female',48,'20150311','sale',3000.13,402,2),#以下是销售部门
('呵呵','female',38,'20101101','sale',2000.35,402,2),
('西西','female',18,'20110312','sale',1000.37,402,2),
('乐乐','female',18,'20160513','sale',3000.29,402,2),
('拉拉','female',28,'20170127','sale',4000.33,402,2),
('僧龙','male',28,'20160311','operation',10000.13,403,3), #以下是运营部门
('程咬金','male',18,'19970312','operation',20000,403,3),
('程咬银','female',18,'20130311','operation',19000,403,3),
('程咬铜','male',18,'20150411','operation',18000,403,3),
('程咬铁','female',18,'20140512','operation',17000,403,3);
1、查询关键字之select与from
select :
控制查询表中的那些字段对应的数据
from :
控制查询的表
eg : select * from t1;
解释: 查询t1表所有字段中的所有数据信息
eg : select name from t1;
解释: 查询t1表中name字段的所有数据信息
2、查询关键字之where筛选
定义:where其实就是对数据进行筛选
关键字: where
实例:
1、查询id大于定于3小于等于6的数据
select * from emp where id >=3 and id <=6;
select * from emp where id between 3 and 6; # 第二种写法
2、查询薪资是20000或者18000或者17000的数据
select * from emp where salary = 20000 or salary = 18000 or salary 17000;
可简写为:
select * from emp where salary in (20000,18000,17000);
在练习下面的实例之前先补充一个知识点:
模糊查询:
定义 : 只查询需要数据所含有的部分字母.
比如 : 查询名字中含有杰字的用户信息
关键字 : like
关键符号:
% : 匹配任意个数的任意字符
_ : 匹配单个个数的任意字符
3、查询员工姓名中包含o字母的员工姓名和薪资
select name,salary from emp where name like '%o%';
4、查询员工姓名为四个字符组成的员工姓名和薪资
select name,salary from emp where name like '____'; # 由四个_组成代表四个字符
也可以使用: char_length()查询字符长度
select name,salary from emp where char_length(name) = 4;
5、查询id小于3或者大于6的数据
select * from emp where id < 3 or id > 6;
select * from emp where id not between 3 and 6; # not 取反
6、查询薪资不在20000,18000,17000范围的数据
select * from emp where salary not in (20000,18000,17000); # not 取反
7、查询岗位描述为空的员工与岗位名 针对null不能用等号,只能用is
select name,post from emp where post_comment = null; # 报错
select name,post from emp where post_comment is null;
select name,post from emp where where post_comment is not null;
3、查询关键字之group by 分组
分组定义: 按照某个指定的条件将单个单个的数据分为一个个的整体
关键字 : group by 条件
eg : 班级按照作为横向分组
班级按照年龄进行分组
班级按照年龄进行分组
应用场景: 求每个部门的平均薪资
求男生的平均薪资
求女能的平均薪资
注意:分组之后不在以单个个体为研究对象,也无法直接再获得单个个体的数据,研究对象应该为分组的整体
分组之后默认只能直接获取到分组的依据 其他字段数据无法直接获取
如果需要实现上述要求 需要修改sql_mode
set global sql_mode='only_full_group_by';
注:不能直接获取,但是可以通过某些方法间接获取。


在做实战案例前先补充一点额外知识点:
聚合函数
max() # 最大值
min() # 最小值
sum() # 求和
count() # 计数
avg() # 平均值
# 上述聚合函数都是在分组之后使用 用于操作整体数据
修改结果名:as
在查看结果的时候可以给字段起别名
select post as '部门',max(salary) as '最高薪资' from emp group by post;
省略as:
select post '部门',max(salary) as '最高薪资' from emp group by post;
as可以省略但是为了语义更加明确建议不要省略
了解上述两个小知识点我们再来看一下实例:
1、获取每个部门的最大薪资与最低薪资
select post as '部门',max(salary) as '最高薪资' from emp group by post;
select post as '部门',min(salary) as '最高薪资' from emp group by post;

2、统计每个部门的人数
select post,count(id) as '部门人数' from emp group by post;
注意:count()只是计数 不是针对括号内的id字段
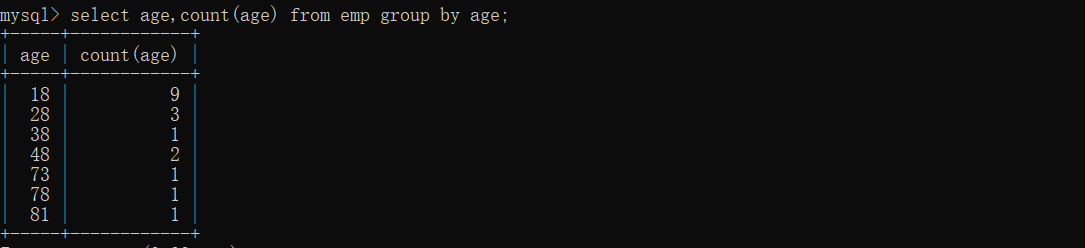
统计各年龄段的员工人数:
select age,count(age) as '各年龄段' from emp group by age;

3、获取每个部门的员工姓名
select post,group_concat(name) from emp group by post;

补充:group_concat用于分组之后获取分组以外的字段数据并支持拼接
concat 用户分组之前的拼接操作
concat_ws 当多个字段链接符相同的情况下推荐使用
实例:1、获取每个部门的员工姓名和薪资
select post,group_concat(name,'|',salary) from emp group by post;
2、获取分组之前所有的员工姓名和薪资
select id,concat(name,'|',salary) from emp;
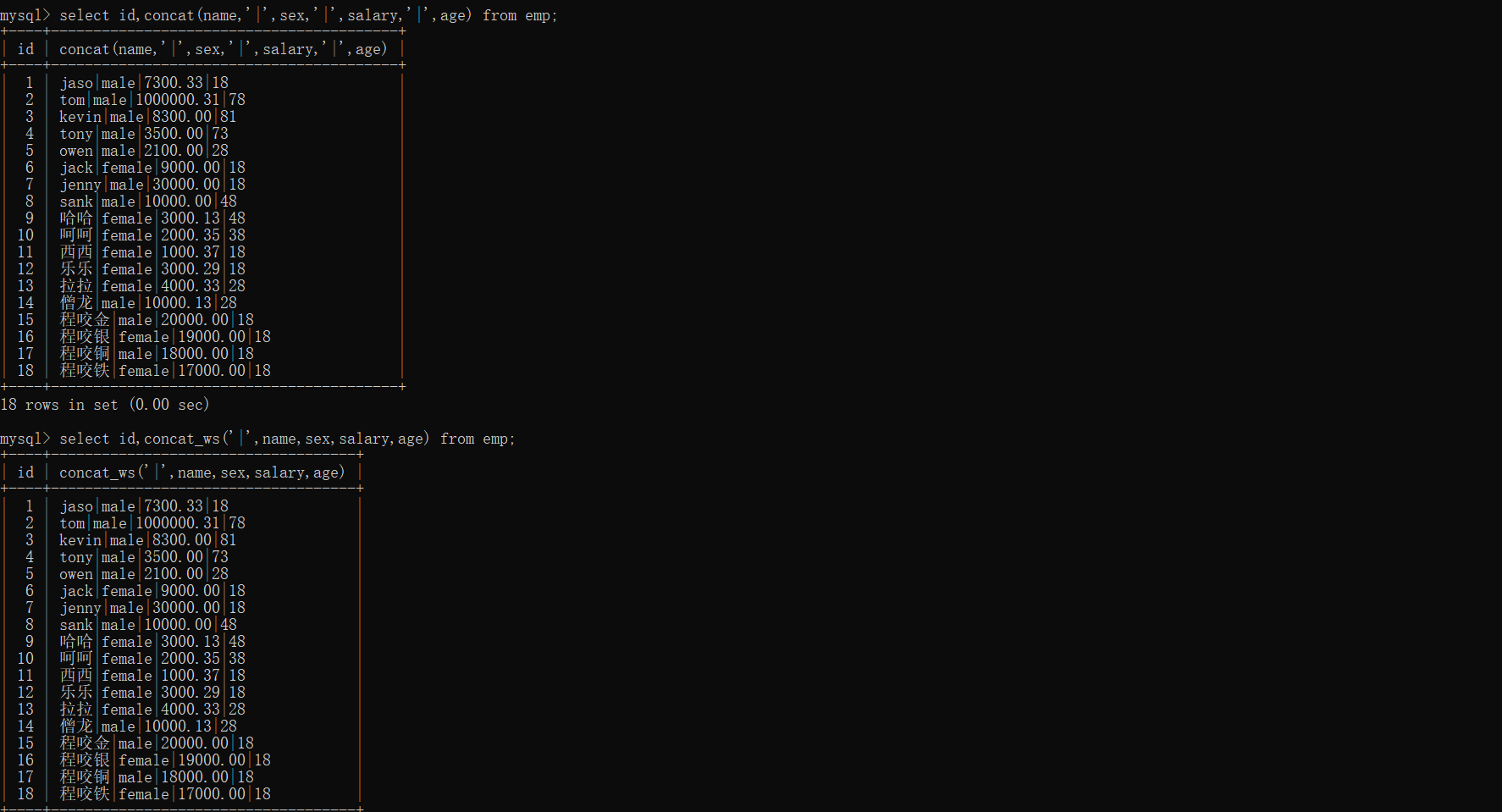
3、获取分组之前所有员工的名字 性别 薪资 年龄
使用concat : select id,concat(name,'|',sex,'|',salary,'|',age) from emp;
使用concat_ws : select id,concat_ws('|',name,sex,salary,age) from emp;
# 效果是一样的
4、查询关键字之having过滤
where与having都是用来筛选数据的
但是where用于分组之前的筛选,having用于分组之后的筛选
为了认为的区分开我们将where用筛选来形容 having用过滤来形容
实例:
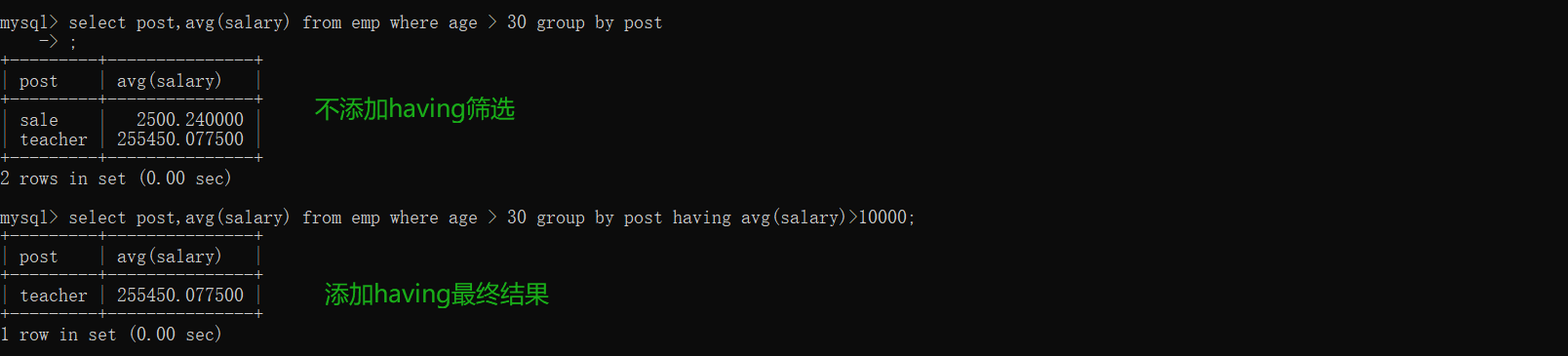
# 统计各部门年龄在30岁以上的员工平均工资,并且保留平均工资大于10000的部门
我们可以先分开解析一下:
1、查看整张表的内容 : select * from emp;
2、统计年龄在30岁以上的 :select * from emp where age > 30;
3、给各个部门分组 :select post from emp group by post;
4、计算各部门的平均薪资 :select post,avg(salary) from emp group by post
5、各部门30岁以上的平均薪资 :select post,avg(salary) from emp where age > 30 group by post;
6、使用having加上限制条件 并且平均工资大于10000 :
select post,avg(salary) from emp where age > 30 group by post having avg(salary)>10000;
5、查询关键字之distinct去重
定义:去重的前提是存在一摸一样的数据,如果针对于主键肯定无法去重
关键字:distinct
实例:
1、针对于主键:
select distinct id,age from emp; # 无效果
select distinct id,distinct age from emp; # 报错
select distinct age,name from emp; # 无效果
2、查看有几个年龄段的员工:
select distinct age from emp;

6、查询关键字之order by排序
定义:使数据升序或者降序
关键字:(asc升序(默认)) (desc降序) # 关键字需要用在指定字段之后
实例:
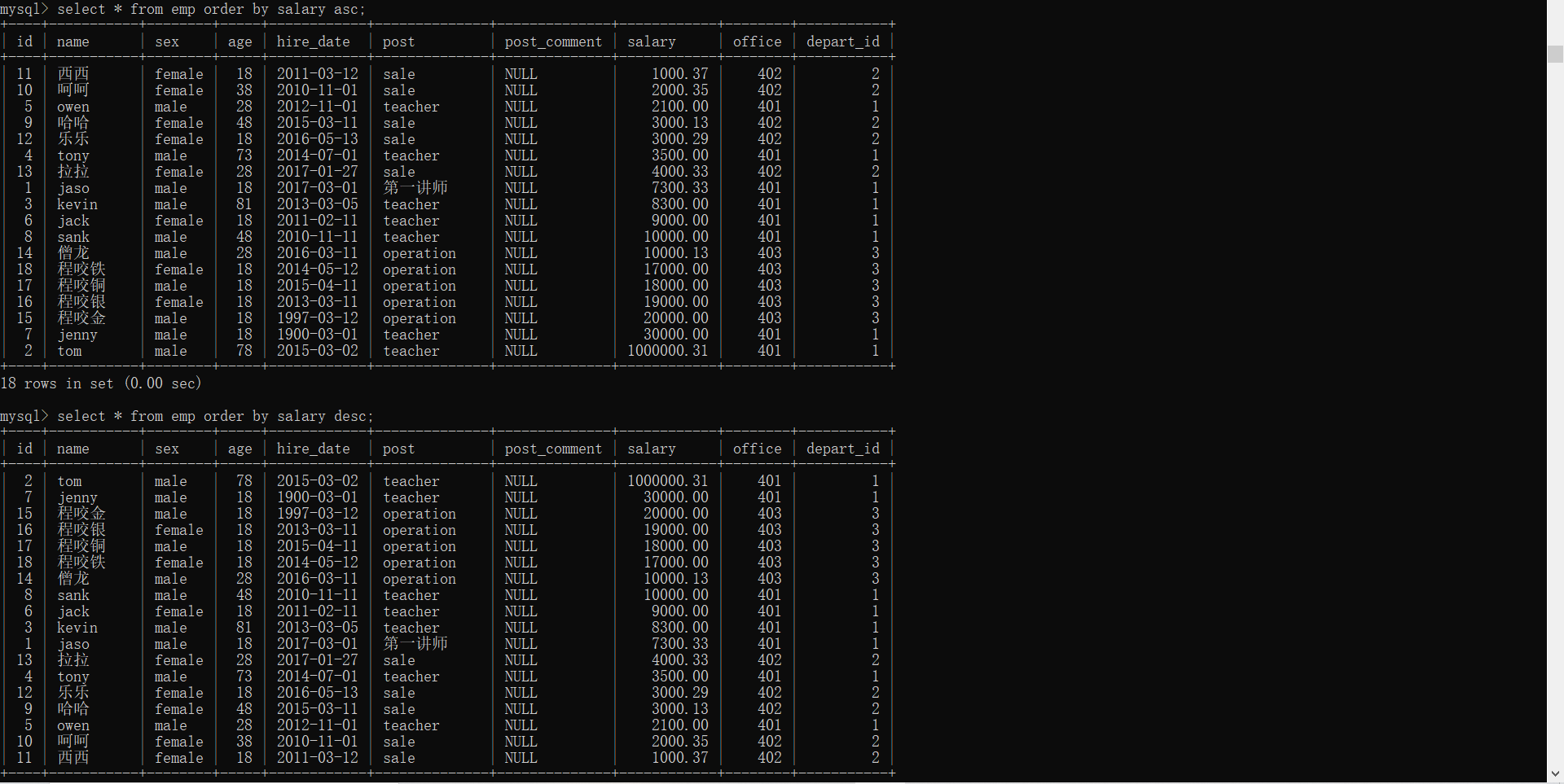
1、以员工薪资从低到高排序
select * from emp order by salary asc; # asc为默认参数可以不写
2、以员工薪资从高到低排序
select * from emp order by salary desc; # 如果使用降序则必须写desc
order by 排序支持多个字段组合(第一个不行就用第二个)
解释:因为用很多重复的数据 比如年龄有很多重复的 重复的数据是无法排序的
比喻:如果同年龄段(因为同年龄段的肯定不止一个人)的无法排序 就是用薪资来排序
实例:
1、以各年龄段薪资升序查看:
select * from emp order by age,salary;
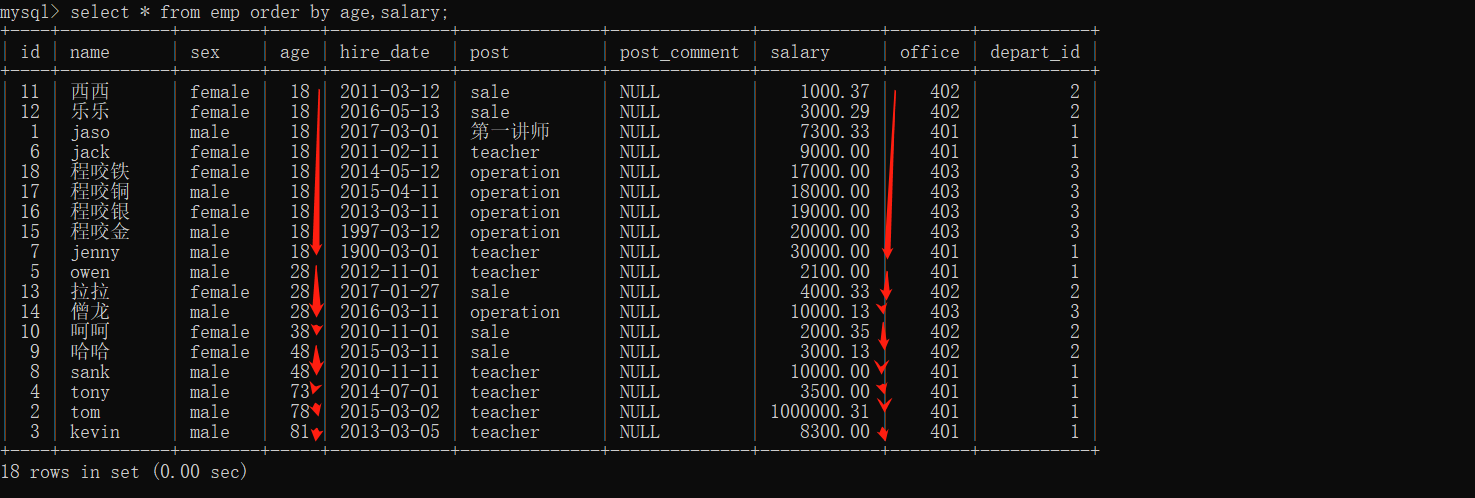
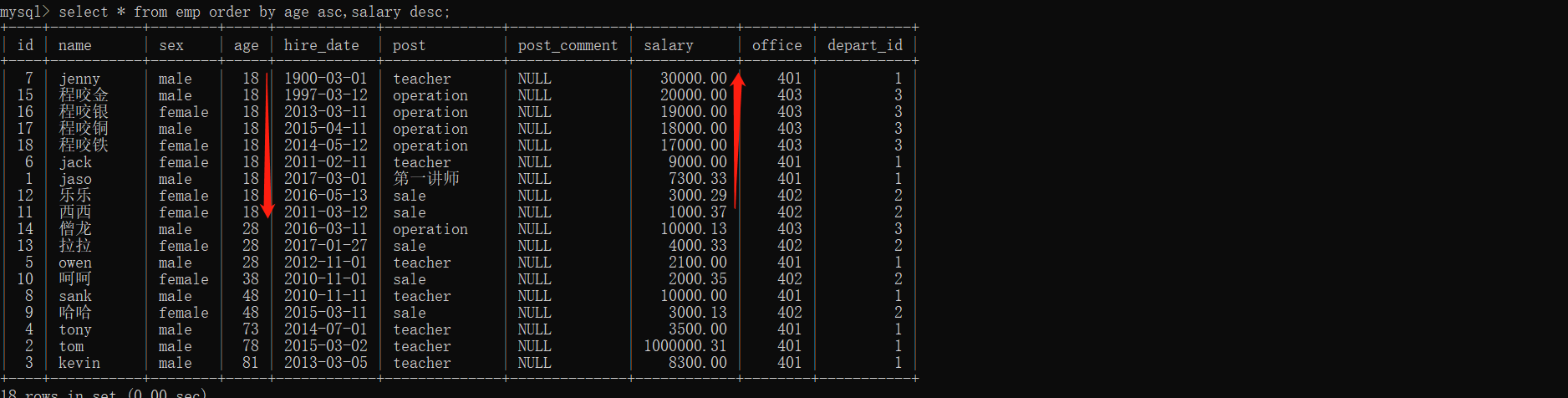
2、也可以(asc,desc)结合使用
以各年龄段薪资降序来查看:
select * from emp order by age asc,salary desc;
7、查询关键字之limit分页
定义:在查看的数据太多情况下,使用分页来限制每次查看数据的数量。
关键字: limit
用法:limit 数字
1、limit后只跟一个数字:从头开始展示多少行
select * from emp limit 5; # 从头开始展示5行
2、limit后跟两个数字:第一个数字为起始位,第二个数字为从起始位开始展示多少行
select * from emp limit 5,5; # 从第5行开始展示5行
实例:
1、求薪资最高的员工所有数据
分析:可以使用order by使薪资降序排序
在使用limit 1 展示一行
select * from emp order by salary desc limit 1;

8、查询关键字之regexp正则表达式
定义:使用正则表达式来限制查找条件,找到符合条件的数据。
关键字:regexp
用法:regexp '正则表达式'
实例:
1、取指定员工信息
select * from emp where name regexp '^j.*(n|y)$';
解释:取员工姓名为:开头为j结尾为n或者y中间是任意字符的所有信息

9、查询关键字之exists判断
定义:exists关键字表示存在。在使用在使用exists关键字时,内层查询语句不返回查询的记录,
而是返回一个真假值,True或False。
当返回为True时,外层查询语句将进行查询、
返回值为False时,外层查询语句不进行查询。
用法:sql语句 exists(判断语句)
判断语句为True则执行sql语句 如果返回为False则不执行.
实例:
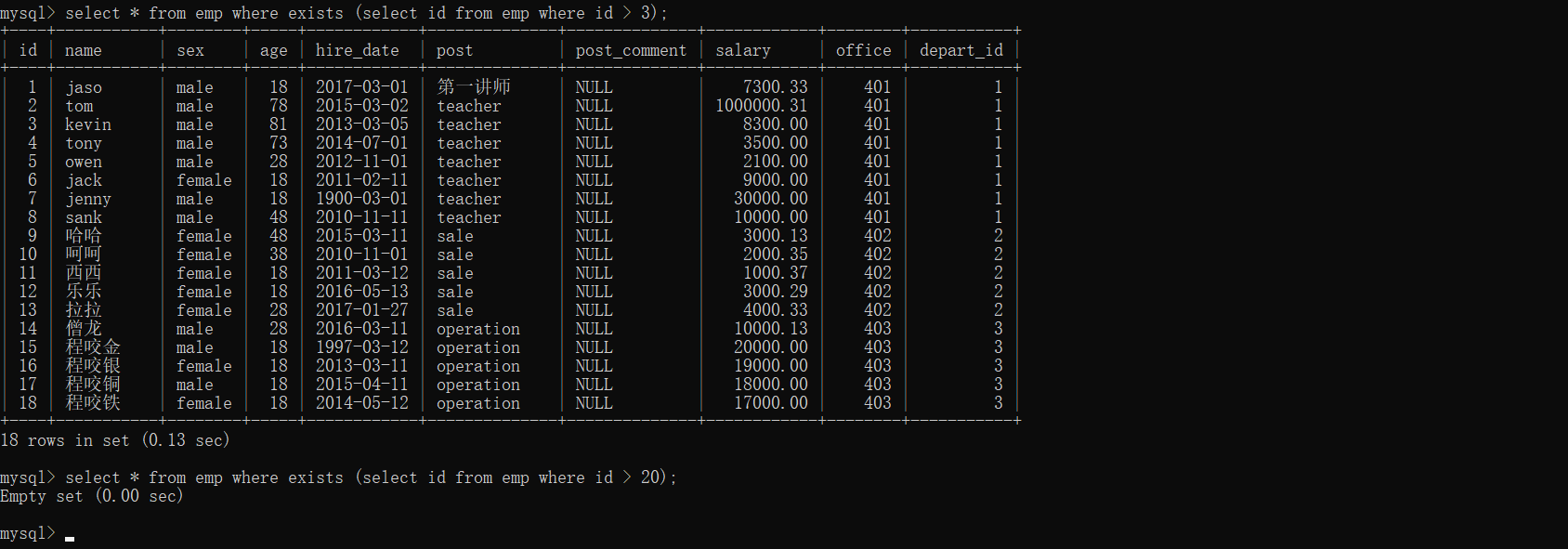
select * from emp where exists (select id from emp where id > 3);
解释:括号内判断语句为True有结果则会执行exists前的sql语句
select * from emp where exists (select id from emp where id > 20);
解释:括号内判断语句为False没有结果则不会执行exists前的sql语句


 浙公网安备 33010602011771号
浙公网安备 33010602011771号