socket套接字编程 | 粘包现象 | 报头 | struck模块
目录
socket套接字编程
什么是套接字编程:所谓套接字(Socket),就是对网络中不同主机上的应用进程之间进行双向通信的端点的抽象。一个套接字就是网络上进程通信的一端,提供了应用层进程利用网络协议交换数据的机制。从所处的地位来讲,套接字上联应用进程,下联网络协议栈,是应用程序通过网络协议进行通信的接口,是应用程序与网络协议栈进行交互的接口。
socket模块
架构启动肯定时先启动服务端再启动客户端。
Socket 对象(内建)方法
| 函数 | 描述 |
|---|---|
| 服务器端套接字 | |
| s.bind() | 绑定地址(host,port)到套接字, 在 AF_INET下,以元组(host,port)的形式表示地址。 |
| s.listen() | 开始 TCP 监听。backlog 指定在拒绝连接之前,操作系统可以挂起的最大连接数量。该值至少为 1,大部分应用程序设为 5 就可以了。 |
| s.accept() | 被动接受TCP客户端连接,(阻塞式)等待连接的到来 |
| 客户端套接字 | |
| s.connect() | 主动初始化TCP服务器连接,。一般address的格式为元组(hostname,port),如果连接出错,返回socket.error错误。 |
| s.connect_ex() | connect()函数的扩展版本,出错时返回出错码,而不是抛出异常 |
| 公共用途的套接字函数 | |
| s.recv() | 接收 TCP 数据,数据以字符串形式返回,bufsize 指定要接收的最大数据量。flag 提供有关消息的其他信息,通常可以忽略。 |
| s.send() | 发送 TCP 数据,将 string 中的数据发送到连接的套接字。返回值是要发送的字节数量,该数量可能小于 string 的字节大小。 |
| s.sendall() | 完整发送 TCP 数据。将 string 中的数据发送到连接的套接字,但在返回之前会尝试发送所有数据。成功返回 None,失败则抛出异常。 |
| s.recvfrom() | 接收 UDP 数据,与 recv() 类似,但返回值是(data,address)。其中 data 是包含接收数据的字符串,address 是发送数据的套接字地址。 |
| s.sendto() | 发送 UDP 数据,将数据发送到套接字,address 是形式为(ipaddr,port)的元组,指定远程地址。返回值是发送的字节数。 |
| s.close() | 关闭套接字 |
| s.getpeername() | 返回连接套接字的远程地址。返回值通常是元组(ipaddr,port)。 |
| s.getsockname() | 返回套接字自己的地址。通常是一个元组(ipaddr,port) |
| s.setsockopt(level,optname,value) | 设置给定套接字选项的值。 |
| s.getsockopt(level,optname[.buflen]) | 返回套接字选项的值。 |
| s.settimeout(timeout) | 设置套接字操作的超时期,timeout是一个浮点数,单位是秒。值为None表示没有超时期。一般,超时期应该在刚创建套接字时设置,因为它们可能用于连接的操作(如connect()) |
| s.gettimeout() | 返回当前超时期的值,单位是秒,如果没有设置超时期,则返回None。 |
| s.fileno() | 返回套接字的文件描述符。 |
| s.setblocking(flag) | 如果flag为0,则将套接字设为非阻塞模式,否则将套接字设为阻塞模式(默认值)。非阻塞模式下,如果调用recv()没有发现任何数据,或send()调用无法立即发送数据,那么将引起socket.error异常。 |
| s.makefile() | 创建一个与该套接字相关连的文件 |
代码示例
服务端:
import socket # 导入socket模块
server = socket.socket() #创建socket模块 默认就是基于网络的TCP传输协议
server.bind(('127.0.0.1',8080)) # 绑定ip和port 127.0.0.1为本地回环地址
server.listen(5) # 半连接池 等待客户端连接
while True:
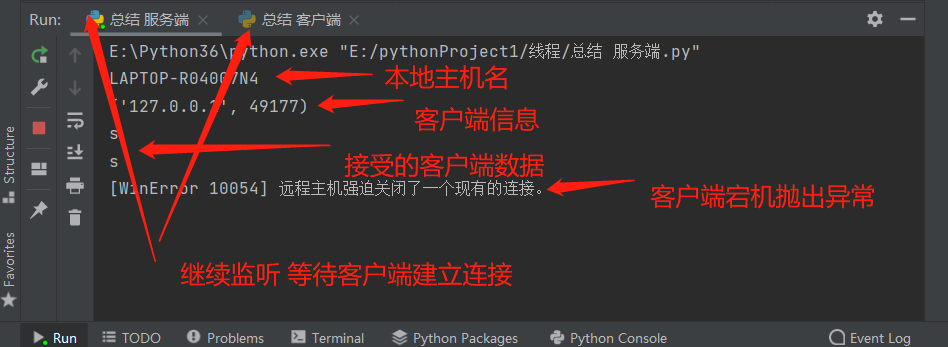
sock, addr = server.accept() # 与客户端建立连接
print(addr) # 打印客户端地址
while True:
try: # 处理客户端突然宕机现象
data = sock.recv(1024) # 接受客户端数据指定最大为1024字节
if len(data) == 0:break # 如果客户端发来数据为空则结束本次循环重新监听
print(data) # 打印客户端数据
sock.send(data + b': go out') # 给客户端发数据 "回话"
except Exception as e: # 万能异常
print(e)
break
sock.close() # 交互结束 等待下一个客户
客户端:
import socket # 导入socket模块
client = socket.socket() # 创建socket模块 默认为TCP传输协议
client.connect(('127.0.0.1',8080)) # 绑定服务端ip与port
while True:
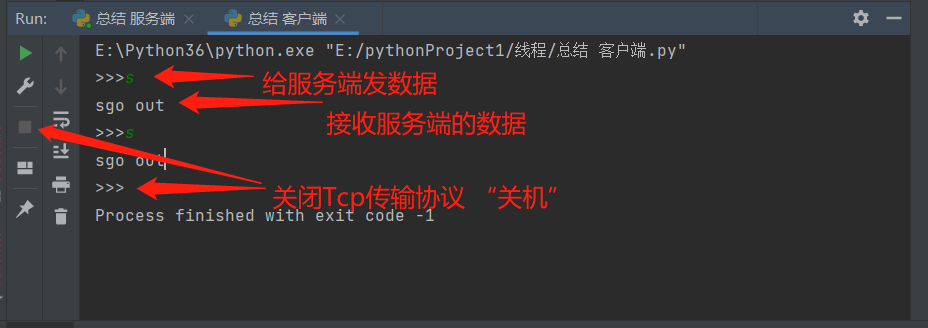
msg = input('>>>').strip() # 创建交互(阻塞态)
if len(msg) == 0:continue # 如果输入的为空则重新交互
client.send(msg.decode('utf8')) # 给服务端发送数据 "给他说话"
data = client.recv(1024) # 接受服务端的数据 "听他说"
print(data.encode('utf8')) # 打印接受的数据
client.close() # 交互结束 "关机"
粘包现象
什么是粘包现象:
# 数据管道的数据没有被完全取出
为什么会出现粘包现象:
TCP协议特性:
# 当数据比较小 且时间间隔比较短的多次数据
# 那么TCP会自动打包成一个数据包发送
那么如何解决粘包现象 就要用到下面的知识点来解决?
举例粘包现象
服务端:
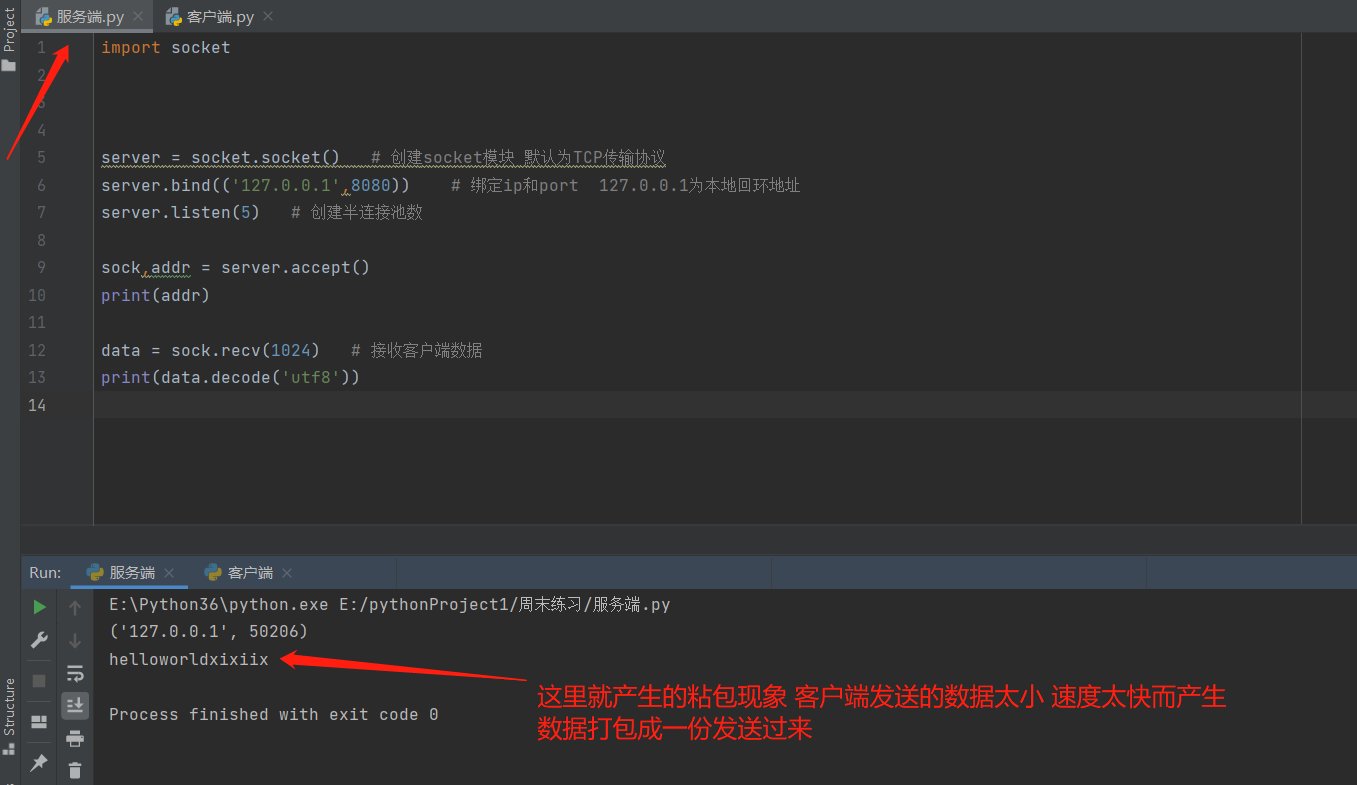
import socket
server = socket.socket() # 创建socket模块 默认为TCP传输协议
server.bind(('127.0.0.1',8080)) # 绑定ip和port 127.0.0.1为本地回环地址
server.listen(5) # 创建半连接池数
sock,addr = server.accept()
print(addr)
data = sock.recv(1024) # 接收客户端数据
print(data.decode('utf8'))
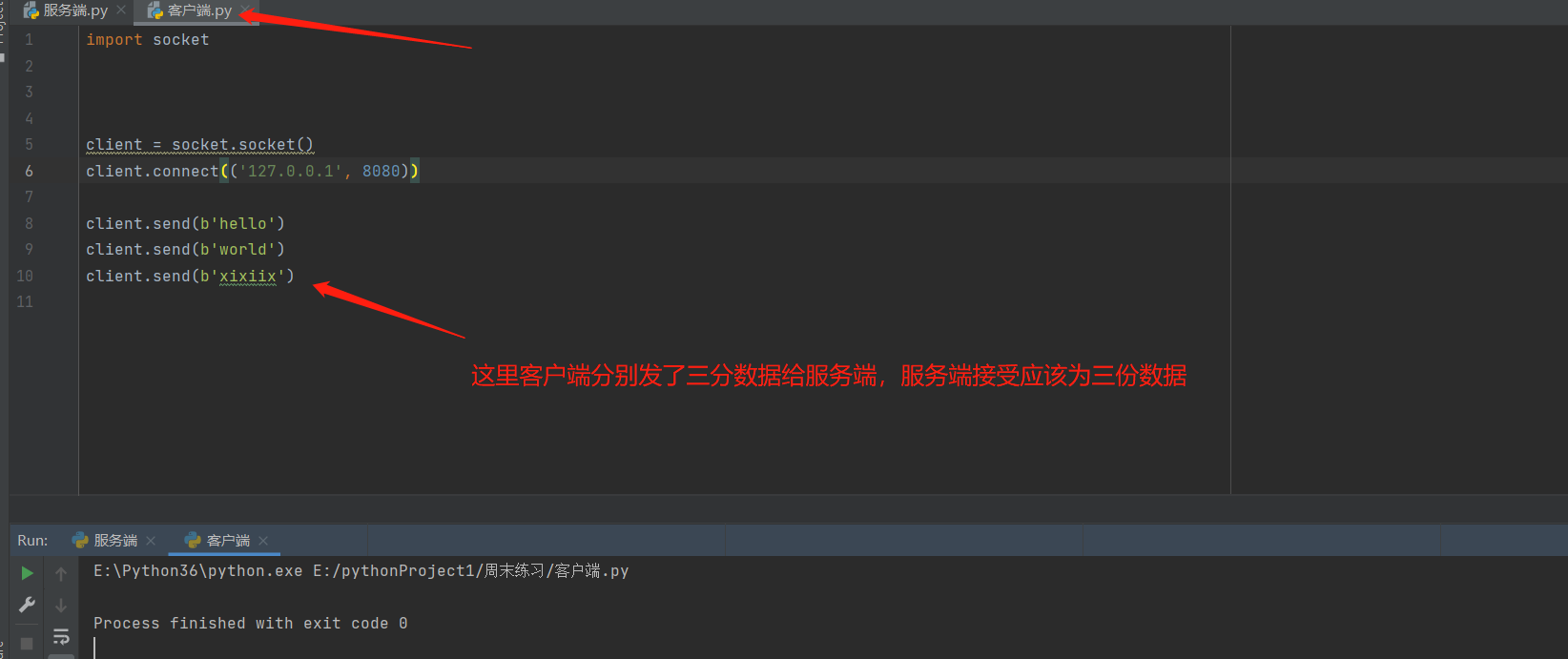
客户端:
import socket
client = socket.socket()
client.connect(('127.0.0.1', 8080))
client.send(b'hello')
client.send(b'world')
client.send(b'xixiix')
解决上述粘包现象
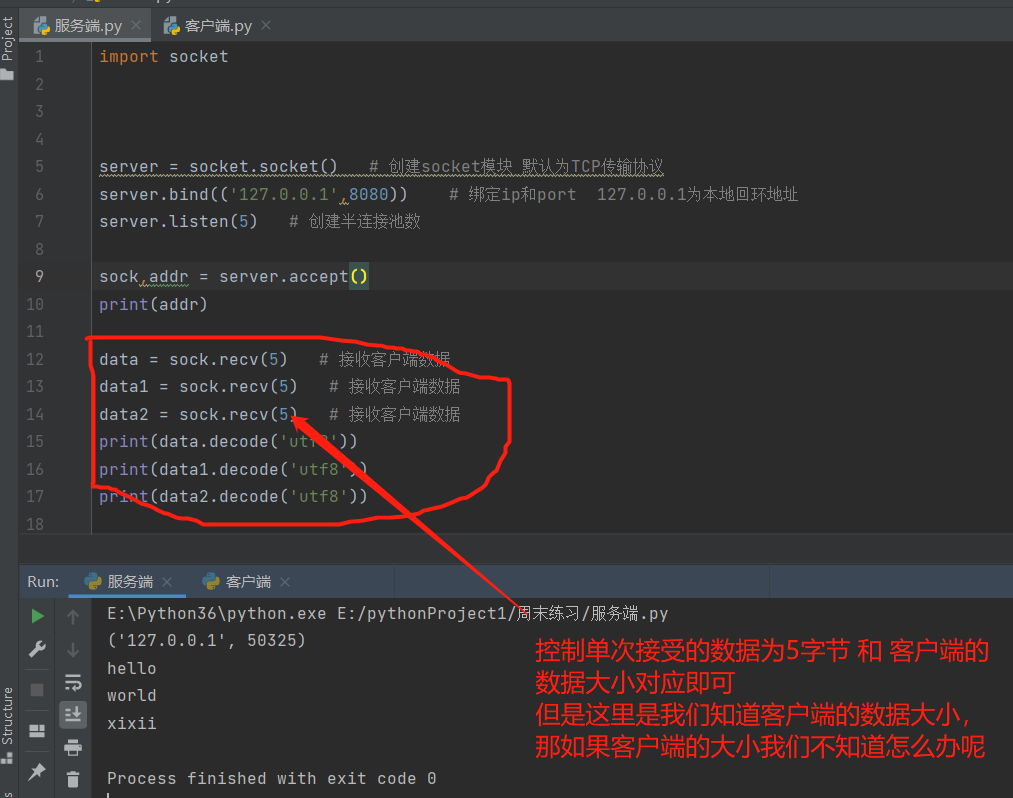
通信循环及代码优化(下述代码实现)
1.客户端校验消息不能为空 (上述代码已解决)
2.服务端添加兼容性代码(mac linux)
3.服务端重启频繁报端口占用错误
from socket import SOL_SOCKET, SO_REUSEADDR
server.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1) # 在bind前加
4.客户端异常关闭服务端报错的问题 (上述代码已解决)
异常捕获
5.服务端链接循环
6.半连接池 # 目前只能等待的客户端为5。
设置可以等待的客户端数量
判断客户端数据大小解决粘包问题
报头
什么是报头:
能够标识即将到来的数据的具体信息
eg : 数据量的大小
# 注意 :报头的长度必须是固定的 。
报头就相当于侦察兵, 打仗之前呢侦察兵先去侦察一下敌方的情报,比如敌方的人数多少,然后回来报告对方的情报(人数)。在进行合理的计划
struct模块
该模块可以把一个类型,如数字,转成固定长度的bytes
>>> struct.pack('i',1111111111111)
struct.error: 'i' format requires -2147483648 <= number <= 2147483647 #这个是范围
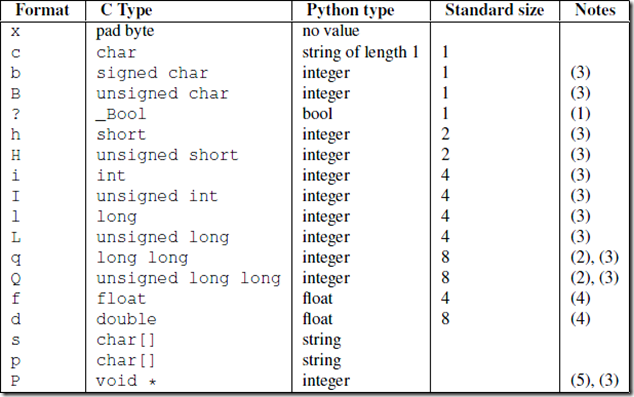
| 发送时 | 接收时 |
|---|---|
| 先发送struct转换好的数据长度4字节 | 先接受4个字节使用struct转换成数字来获取要接收的数据长度 |
| 再发送数据 | 再按照长度接收数据 |
struct模块具体使用
import struct
import json
d = {
'file_name': '很好看.mv',
'file_size': 1231283912839123123424234234234234234324324912,
'file_desc': '拍摄的很有心 真的很好看!!!',
'file_desc2': '拍摄的很有心 真的很好看!!!'
}
d = json.dumps(d) # 序列化为json模式的字符串
res = struct.pack('i',len(d)) # 'i' 模式将序列化的字符串转换成固定长度为4的bytes
print(len(res))
res1 = struct.unpack('i',res)[0] # 'i' 模式解析pack打包的固定长度为4的内容大小
print(res1)
报头和struct实现,解决粘包问题。
使用struct使数据的大小转换成固定的长度的bytes
使用报头(报头是自己制作的)先让服务端确定固定的数据大小
服务端代码块
import struct
import socket
import json
import subprocess
server = socket.socket()
server.bind(('127.0.0.1',8080))
server.listen
while True:
sock, addr = server.accept()
while True:
try:
data = sock.recv(1024) # 接收cmd命令
cmd = data.decode('utf8')
sub = subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
res = sub.stdout.read() + sub.stdarr.read()
# 1、制作报头
data_first = struct.pack('i',len(res))
# 2、发送报头
sock.send(data_first)
# 3、发送真实数据
sock.send(res)
客户端代码块
import socket
import struct
cliend = socket.socket()
cliend.connect(('127.0.0.1',8080))
while True:
msg = input('请输入cmd命令>>>>').strip()
if len(msg) == 0:continue
client.send(msg.encode('utf8'))
# 1、先接受固定长度为4的报头数据
recv_first = client.rect(4)
# 2、解析报头(真是数据的大小)
real_length = struct.unpack('i',recv_first)[0]
# 3、接收真实数据
real_data = client.recv(real_length)
print(real_data.decode('gbk')) # 这里要用到gbk模式 因为反馈结果为
这样的话就不会出现粘包问题,因为报头固定的文件的大小。
案例:上传文件数据(使客户端可以给服务端上传文件)
服务端代码块
import json
import socket
import struct
import os
server = socket.socket() # 创建socket模块 默认为TCP传输协议
server.bind(('127.0.0.1', 8081)) # 绑定ip和port 本地回环地址为127.0.0.1
server.listen(5)
while True:
sock, addr = server.accept()
while True:
try:
# 先接收固定长度为4的字典报头数据
recv_first = sock.recv(4)
# 解析字典报头
dict_length = struct.unpack('i',recv_first)[0]
# 接收字典数据
real_dict = sock.recv(dict_length) # dict_length为上面解析后的字典大小
# 解析字典
real_data = json.loads(real_dict)
# 获取字典中的各项数据
data_length = real_data.get('size') # 真实文件大小
file_name = real_data.get('name') # 真实文件名字
# 循环一行行的接收真实数据
recv_size = 0 # 定义全局变量
with open(file_name, 'wb') as f: # 操作文件名为真实文件名字的文件
while recv_size < data_length: # 判断接收的数据是否小于真实数据大小
data = sock.recv(1024) # 接收真实数据的大小
recv_size += len(data) # 接收点加一点 直到和真实数据相等才算接收完
f.write(data) # 写入文件中
except Exception as e:
print(e)
break
客户端代码块
import json
import struct
import os
import socket
client = socket.socket()
client.connect(('127.0.0.1',8081))
while True:
data_path = r'E:\迅雷下载\xxx老师合集' # 指定路径
movie_name_list = os.listdir(data_path) # 用列表的方式列举出路径下的所有文件
for i,j in enumerate(movie_name_list,1): # 枚举出每个文件信息 其实标签为1
print(i,j)
choice = input('请选择你要上传的文件编号:').strip()
if choice.isdigit():
choice = int(choice)
if choice in range(1, len(movie_name_list)+1):
movie_name = movie_name_list[choice -1]
# 拼接文件绝对路径
movie_path = os.path.join(data_path,movie_name)
# 定义一个字典数据
data_dict = {
'name' : 'XXX老师合集',
'desc' : '这是比较劲爆的内容',
'size' : os.path.getsize(movie_path), # 获取文件的大小
'info' : '很用心的作品'
}
data_json = json.dumps(data_dict)
# 制作字典报头
data_first = struct.pack('i',data_json)
# 发送字典报头
client.send(data_first)
# 发送真实字典
client.send(data_json.encode('utf8'))
# 发送真实数据
with open(movie_path,'rb') as f:
for s in f:
clien.send(s)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号