keepalived高可用|keepalived脑裂问题|keepalived非抢占式
keepalived高可用
什么是高可用
一般是指2台机器启动着完全相同的业务系统,当有一台机器down机了,另外一台服务器就能快速的接管,对于访问的用户是无感知的。
比如公司的网络是通过网关进行上网的,那么如果该路由器故障了,网关无法转发报文了,此时所有人都无法上网了,怎么办?
通常做法是给路由器增加一台备节点,但是问题是,如果我们的主网关master故障了,用户是需要手动指向backup的,如果用户过多修改起来会非常麻烦。
问题一:假设用户将指向都修改为backup路由器,那么master路由器修好了怎么办?
问题二:假设Master网关故障,我们将backup网关配置为master网关的ip是否可以?
其实是不行的,因为PC第一次通过ARP广播寻找到Master网关的MAC地址与IP地址后,会将信息写到ARP的缓存表中,那么PC之后连接都是通过那个缓存表的信息去连接,然后进行数据包的转发,即使我们修改了IP但是Mac地址是唯一的,pc的数据包依然会发送给master。(除非是PC的ARP缓存表过期,再次发起ARP广播的时候才能获取新的backup对应的Mac地址与IP地址)
如何才能做到出现故障自动转移,此时VRRP就出现了,我们的VRRP其实是通过软件或者硬件的形式在Master和Backup外面增加一个虚拟的MAC地址(VMAC)与虚拟IP地址(VIP),那么在这种情况下,PC请求VIP的时候,无论是Master处理还是Backup处理,PC仅会在ARP缓存表中记录VMAC与VIP的信息。
常用工具
1.硬件通常使用 F5
2.软件通常使用 keepalived
如何使用keepalived实现该可用
keepalived软件是基于VRRP协议实现的,VRRP虚拟路由冗余协议,主要用于解决单点故障问题
ARP广播
VRRP协议
vip负责IP漂移
vmac负责通知ARP广播修改mac地址
VRRP协议
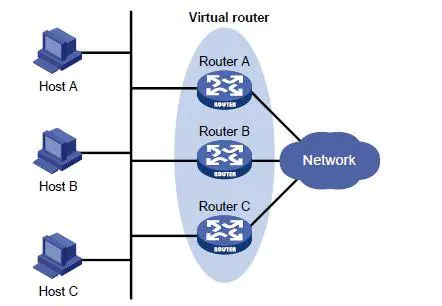
VRRP协议会在一个局域网中进行广播,
如图所示,我们把多个运行着VRRP协议的路由器抽象成一个虚拟路由器(从外边来看,就像只有一个真实的路由器在工作),组成虚拟路由器的一组路由器会有一个会成为Master路由器,其余的会成为Backup路由器。
正常情况下,会由Master完成该虚拟路由器的工作。Master一旦出现故障,从Backup中选出一个成为Master继续工作,从而避免路由器单点问题。
高可用keepalived核心概念
1、如何确定谁是主节点谁是备节点(选举投票,优先级)
2、如果Master故障,Backup自动接管,那么Master恢复后会夺权吗(抢占试、非抢占式)
3、如果两台服务器都认为自己是Master会出现什么问题(脑裂)
部署keepalived
准备工作:
| 代理服务端 | 代理服务端 | 服务端 |
|---|---|---|
| lb01 | lb02 | web01 |
# lb01 lb02
1、安装keepalived
[root@lb01 ~]# yum install keepalived -y
[root@lb02 ~]# yum install keepalived -y
# lb01 lb02 都需要编译安装nginx
wget https://nginx.org/download/nginx-1.20.2.tar.gz # 下载安装包
tar -xf nginx-1.20.2.tar.gz # 解压源码包
./configure --with-http_gzip_static_module --with-stream --with-http_ssl_module --with-http_sub_module
make
make install
# 优化编译安装
mkdir /etc/nginx
mv /usr/local/nginx/conf/* /etc/nginx/
mkdir /etc/nginx/conf.d
vi /etc/nginx/nginx.conf # 编辑配置文件
groupadd www -g 666
useradd www -u 666 -g 666 -M -r -s /sbin/nologin
vim /usr/lib/systemd/system/nginx.service
[Unit]
Description=nginx - high performance web server
Documentation=http://nginx.org/en/docs/
After=network-online.target remote-fs.target nss-lookup.target
Wants=network-online.target
[Service]
Type=forking
PIDFile=/var/run/nginx.pid
ExecStart=/usr/sbin/nginx -c /etc/nginx/nginx.conf
ExecReload=/bin/sh -c "/bin/kill -s HUP $(/bin/cat /var/run/nginx.pid)"
ExecStop=/bin/sh -c "/bin/kill -s TERM $(/bin/cat /var/run/nginx.pid)"
[Install]
WantedBy=multi-user.target
ln -s /etc/nginx/nginx.conf /usr/local/nginx/conf/nginx.conf #创建软连接
mv /usr/local/nginx/sbin/nginx /usr/sbin/
mkdir /var/log/nginx
systemctl start nginx
lb01 配置 keepalived
[root@lb01 ~]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id lb01
}
# 配置VRRP协议
vrrp_instance VI_1 {
# 状态,MASTER和BACKUP
state MASTER
# 绑定网卡
interface eth0
# 虚拟路由标示,可以理解为分组
virtual_router_id 50
# 优先级
priority 100
# 监测心跳间隔时间
advert_int 1
# 配置认证
authentication {
# 认证类型
auth_type PASS
# 认证的密码
auth_pass 1111
}
# 设置VIP
virtual_ipaddress {
# 虚拟的VIP地址
192.168.15.3
}
# 调用检查
track_script {
check_nginx
}
}
# 启动
[root@lb01 ~]# systemctl enable --now keepalived
# lb02 配置 keepalived
lb02 配置 keepalived
[root@lb01 ~]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id lb02
}
# 配置VRRP协议
vrrp_instance VI_1 {
# 状态,MASTER和BACKUP
state BACKUP
# 绑定网卡
interface eth0
# 虚拟路由标示,可以理解为分组
virtual_router_id 50
# 优先级
priority 90
# 监测心跳间隔时间
advert_int 1
# 配置认证
authentication {
# 认证类型
auth_type PASS
# 认证的密码
auth_pass 1111
}
# 设置VIP
virtual_ipaddress {
# 虚拟的VIP地址
192.168.15.3
}
# 调用检查
}
# 启动
[root@lb01 ~]# systemctl enable --now keepalived
验证keepalived是否部署成功
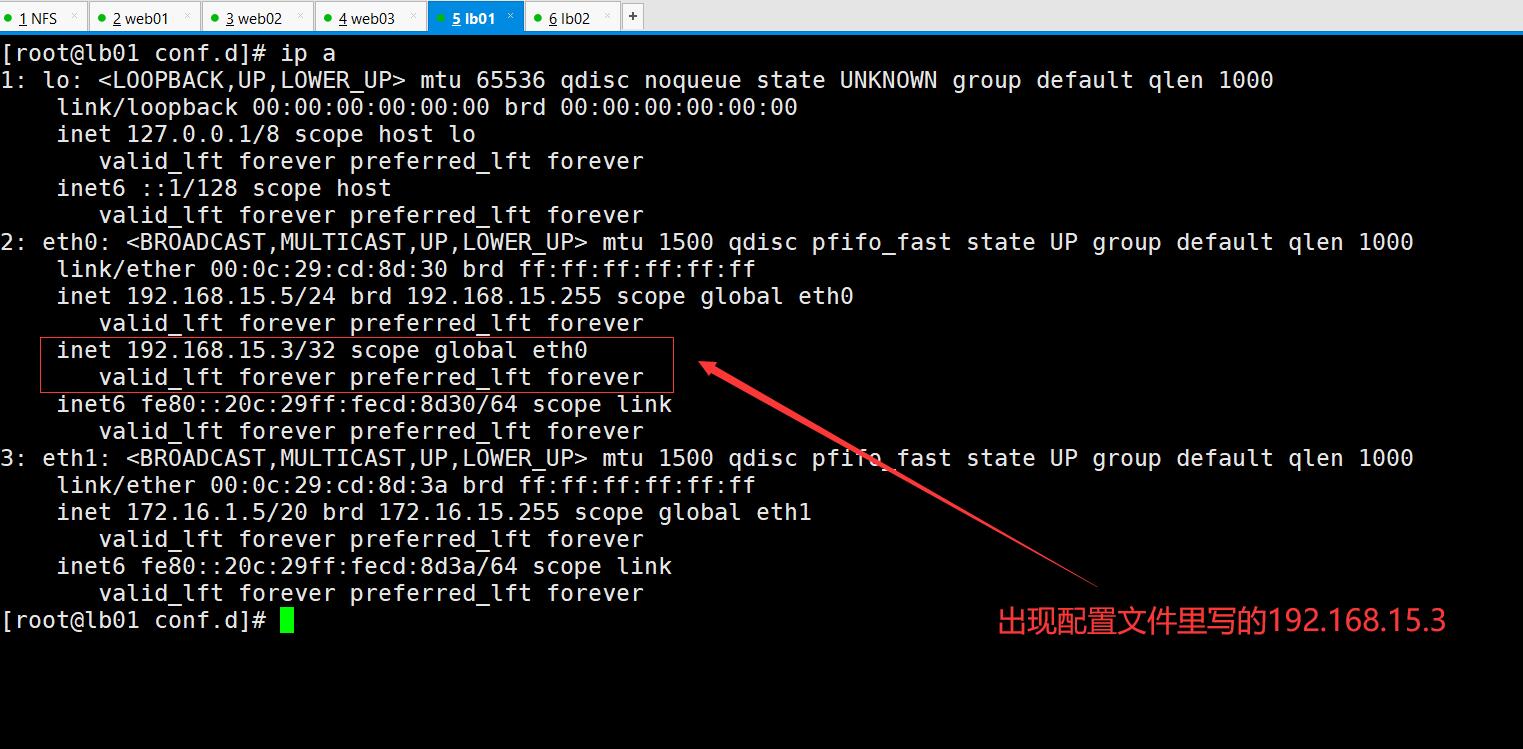
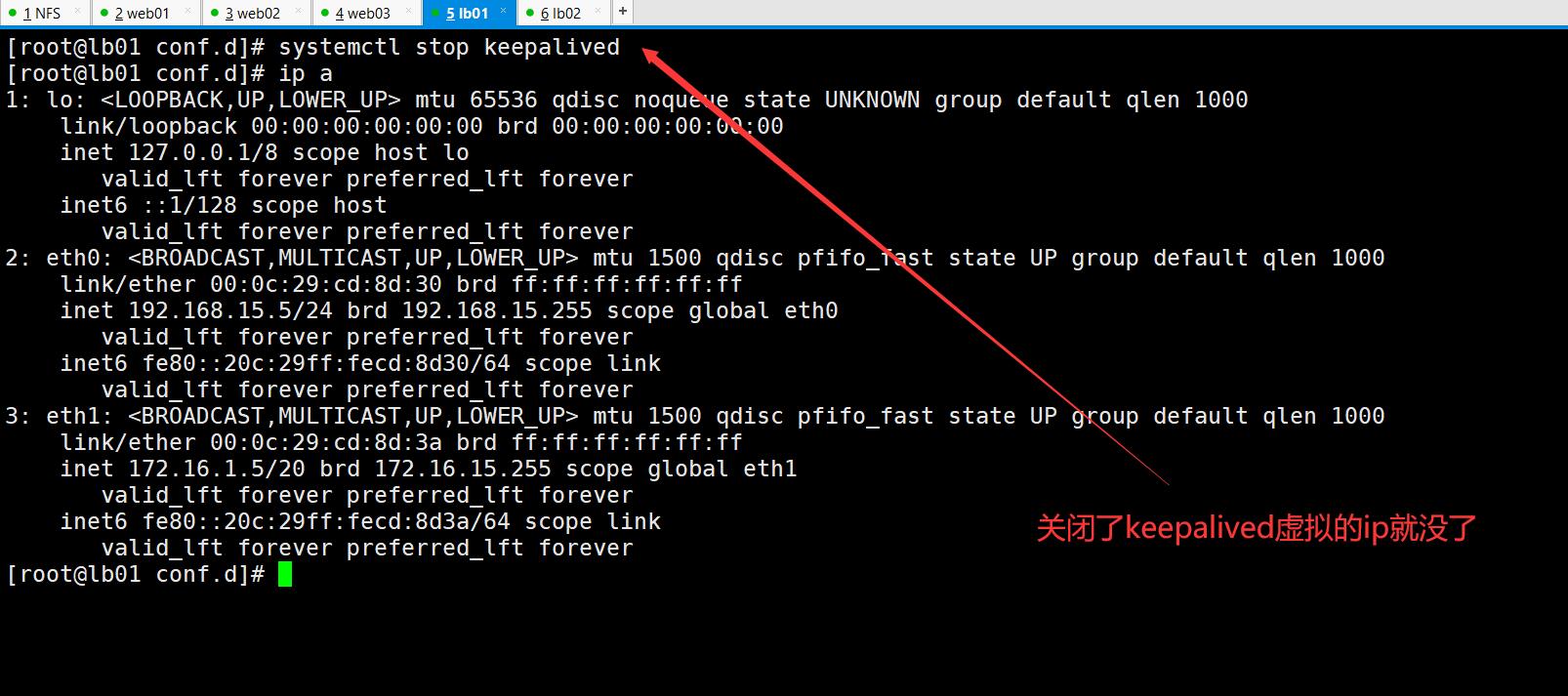
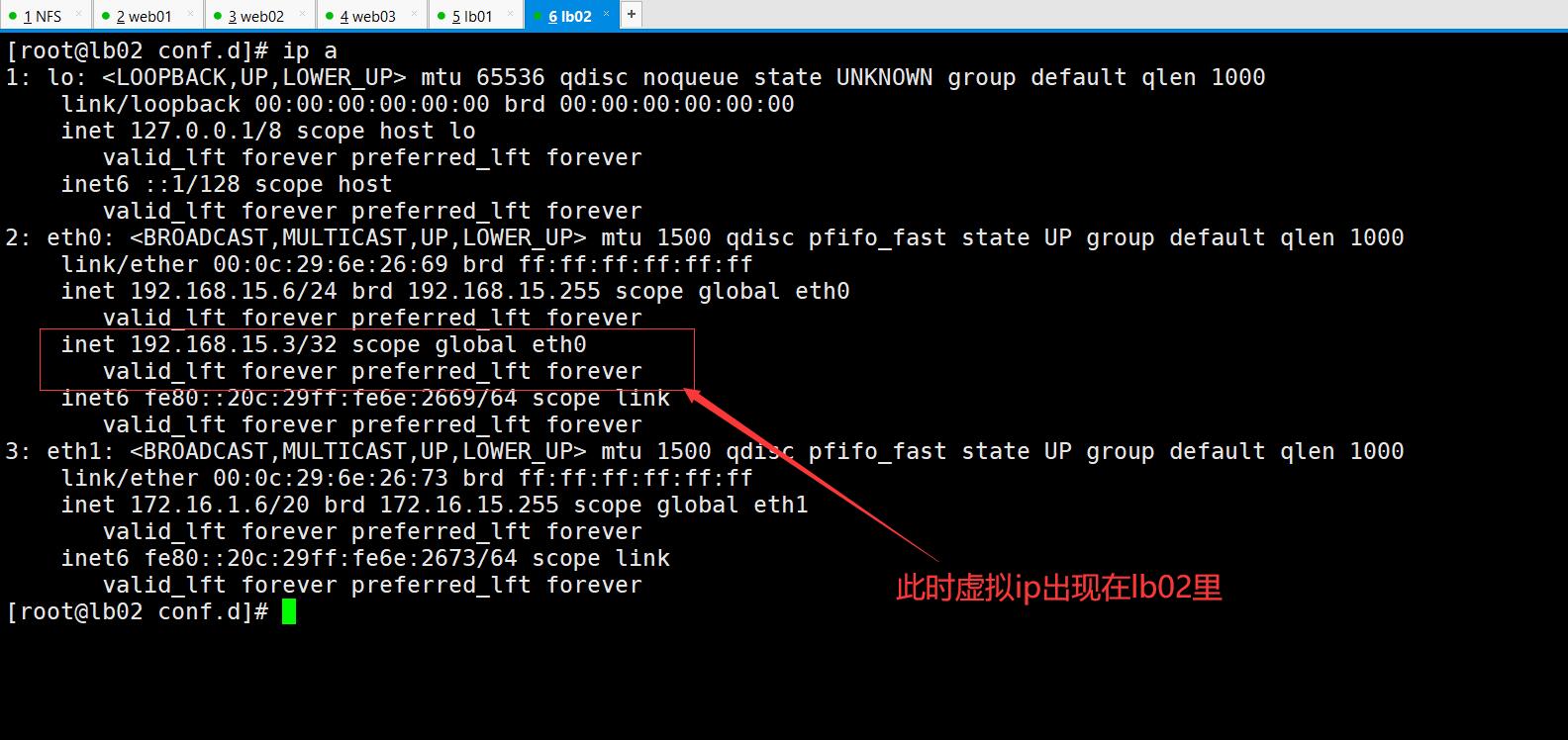
测试:使用192.168.15.3访问
测试:当第一个代理lb01 192.168.15.5宕机 使用192.168.15.3访问
[root@lb01 ~]# systemctl stop keepalived
上边一样的效果就说明成功。此时就实现的高可用。
怎么解决keepalived的脑裂问题
1、什么是keepalived脑裂
两台高可用服务器在指定时间内,无法互相检查到对方的心跳而各自启动故障转移功能。各自取得资源及服务的所有权,而此时的两台高可用服务器又都还活着。(都认为自己是master)
1.网线松动,网络故障
2.服务器硬件故障
3.服务器之间开启了防火墙
世界案例:
1、如果nginx宕机怎么办?
解决方法:部署脚本 判断nginx是否遇意外情况导致关闭 关闭则启动,如果不是这个问题就告诉keepalived实现高可用使用备用代理。
具体部署
1、编辑脚本
[root@lb01 ~]# vim checkNG.sh
[root@lb01 ~]# mv checkNG.sh /etc/keepalived/keeplived.conf
ps -ef | grep -q [n]ginx # 过滤nginx进程
if [ $? -ne 0 ];then # 代表Nginx未正常启动
systemctl start nginx &>/dev/null # 未启动则启动
sleep 2
ps -ef | grep -q [n]ginx # 再次查看进程
if [ $? -ne 0 ];then # 如果还是为启动
systemctl stop keepalived # 则关闭keepalived实现跳转备用代理
fi
fi
2、授权
[root@lb01 ~]# chmod +x checkNG.sh
3、修改keepalived配置文件
[root@lb01 ~]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
# 全局配置
global_defs {
# 当前keepalived的唯一标识
router_id lb01
}
# 检测脚本
vrrp_script check_nginx {
# 指定脚本路径
script "/etc/keepalived/checkNG.sh"
# 执行间隔
interval 5
}
# 配置VRRP协议
vrrp_instance VI_1 {
# 状态,MASTER和BACKUP
state MASTER
# 绑定网卡
interface eth0
# 虚拟路由标示,可以理解为分组
virtual_router_id 50
# 优先级
priority 100
# 监测心跳间隔时间
advert_int 1
# 配置认证
authentication {
# 认证类型
auth_type PASS
# 认证的密码
auth_pass 1111
}
# 设置VIP
virtual_ipaddress {
# 虚拟的VIP地址
192.168.15.3
}
# 调用检查
track_script {
check_nginx
}
}
测试
keepalived的非抢占式
1.什么加抢占式和非抢占式
当lb01宕机的时候lb02会把虚拟ip抢过去,然后lb01维修好后,又会把vip抢回来(因为lb01的优先级高)这种就叫抢占式.
当lb01宕机的时候lb02会把虚拟ip抢过去,然后lb01维修好后,不会把vip抢回来,这种就叫非抢占式.
为什么要设置非抢占式?
因为lb01在恢复之后会把vip抢回来,在这段过程中服务会不稳定,这样会造成用户的体验比较差,而且本身就没有再切换回去的必要,除非lb02宕机了,那lb01会自动抢回去.
2.设置非抢占
实现非抢占式。
1、状态全部都设置成backup
2、增加 nopreempt
eg:
[root@lb02 ~]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id lb01
}
# 检测脚本
vrrp_script check_nginx {
# 指定脚本路径
script "/etc/keepalived/checkNG.sh"
# 执行间隔
interval 5
}
# 配置VRRP协议
vrrp_instance VI_1 {
#状态,MASTER和BACKUP
state BACKUP # lb01这里要把MASTER改成BACKUP
# 开启非抢占式
nopreempt # lb01这里也添加
#绑定网卡
interface eth0
#虚拟路由标示,可以理解为分组
virtual_router_id 50
#优先级
priority 100
#监测心跳间隔时间
advert_int 1
#配置认证
authentication {
#认证类型
auth_type PASS
#认证的密码
auth_pass 1111
}
#设置VIP
virtual_ipaddress {
#虚拟的VIP地址
192.168.15.3
}
# 调用检查
track_script {
check_nginx
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号