SQL优化的方法论
2015-03-05 09:54 TRACEING 阅读(343) 评论(0) 收藏 举报•找到最占用资源的SQL语句
–V$SQLAREA (Shared_pool)
–V$session_longops(6秒)
–StatsPack Report
–SQL*Trace + TKProf
–10g ADDM
–Toad、Quest Data Center
–…
•问题定位 How to find Bad SQL
–V$SQLAREA (Shared_pool)
–StatsPack
–SQL*Trace + TKProf
–10g ADDM
•优化SQL语句
–理解优化器、CBO & RBO和执行计划
–Explain Plan, Tkprof & SQL_TRACE, autotrace, Toad
–Tune Join (Sort Merge, Nest Loop, Hash Join)
–Tune Index, MV (Summery and Join Table)
–分区、并行、使用hint和特殊SQL的优化
---
查找大量逻辑读的语句
select buffer_gets, sql_text
from v$sqlarea
where buffer_gets > 200000
order by buffer_gets desc;
SQL语句的优化:
•索引和数据访问
索引分类:
逻辑上
–单列或组合索引
–唯一非唯一索引
物理上
–分区和非分区索引
–B-tree 和 bitmap
正常或逆向(B-tree only)
–函数索引
•Join模式
•优化提示hint

•分区
•物化视图


•并行


•关于SQL优化的其它事项




Oracle如何访问数据
•Single Table Access Path
–Full Table Scan

–ROWID unique scan
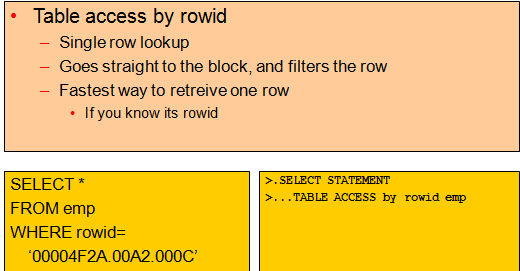
–Index unique scan
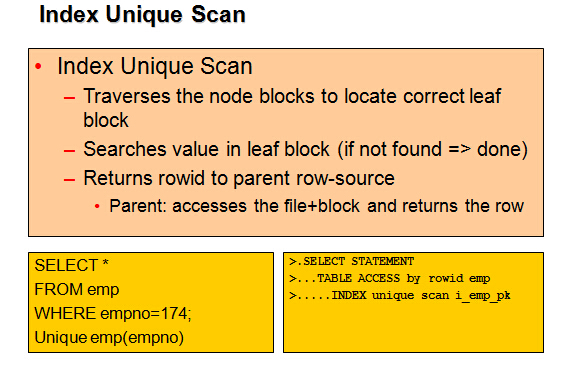
–Index range scan

–Unique Index Range Scan

–Index Skip Scan

–Index (fast) full scan

–Bitmap Index
•Table Join
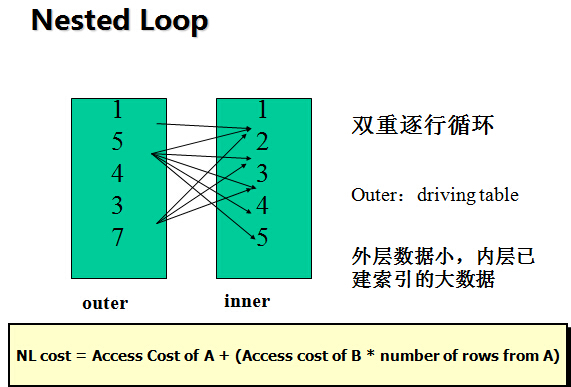
1, Nested Loop
The driving table should be small
The other tables is indexed.


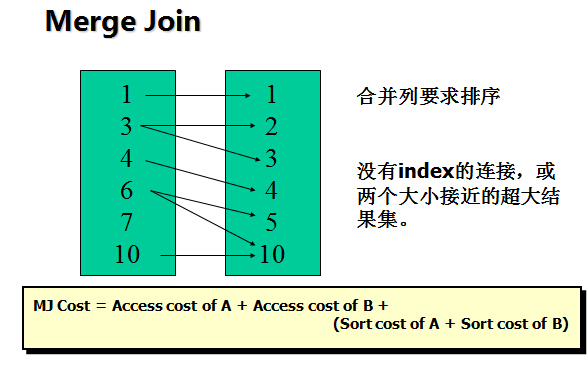
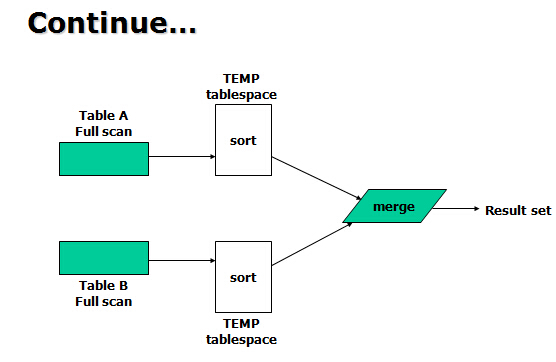
2, Sort Merge
For large data sets (Sort_Area_Size)
The row sources are sorted already.
A sort operation does not have to be done.


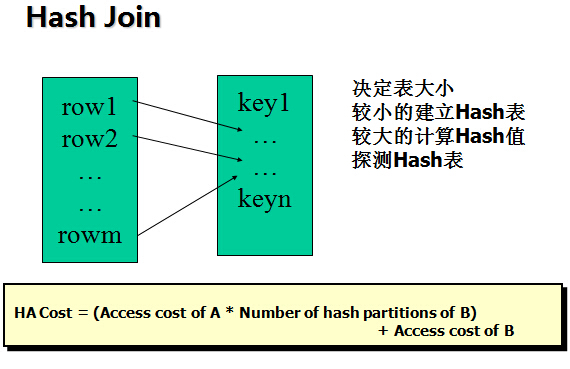
3, Hash Join
For large data sets(Hash_Area_Size)
Optimizer_mode=CBO
Pga_aggregate_target is big enough

如何发现等待事件







 浙公网安备 33010602011771号
浙公网安备 33010602011771号