

requests,unittest——多接口用例,以及需要先登录再发报的用例
之前写过最简单的接口测试用例,本次利用unittest进行用例管理,并出测试报告,前两个用例是两个不同网页的get用例,第三个是需要登录才能访问的网页A,并在其基础上访问一个需要在A页面点开链接才能访问的网页B,第四个用例是直接访问网页B,下面是代码
# encoding=utf-8
import requests,unittest,HTMLTestRunner
class Testbaiduapi(unittest.TestCase):
def setUp(self):
pass
def testsearch(self):
url = "http://10.221.137.68:8180/ldp/index.jsp"
r = requests.get(url,params=None)
assert u'校验点' in r.text
def testsearch2(self):
url = "http://csp.travelsky.com/csp/login"
r = requests.get(url)
assert u'校验点' in r.text
def testsearch3(self):
params = {
"username":"用户名",
"password":"密码",
"lt":"LT-507280-fxjpCVW6a3FFcfTa6EeRbDKeDr0DHe",
"execution":"e1s1",
"submit": "登录" ,
}
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8",
"Accept-Encoding": "gzip, deflate",
"Connection": "keep-alive",
"Host":"authcenter.travelsky.net:8443",
"Referer":"https://authcenter.travelsky.net:8443/authcenter/login",
}
session = requests.session()
url = "http://home.travelsky.net/publish/zghxnw/index.html"
r = session.post(url, data=params,headers=headers,verify=False)
assert u'今天我生日' in r.text
url2="http://home.travelsky.net/publish/zghxnw/847/860/863/index.html"
s = session.get(url2)
assert u'三里屯办公区' in s.text
def testsearch4(self):
params = {
"username":"用户名",
"password":"密码",
"lt":"LT-507280-fxjpCVW6a3FFcfTa6EeRbDKeDr0DHe",
"execution":"e1s1",
"submit": "登录" ,
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8",
"Accept-Encoding": "gzip, deflate",
"Connection": "keep-alive",
"Host":"authcenter.travelsky.net:8443",
"Referer":"https://authcenter.travelsky.net:8443/authcenter/login",
}
url="http://home.travelsky.net/publish/zghxnw/847/860/863/index.html"
s = requests.post(url, data=params,headers=headers,verify=False)
assert u'三里屯办公区' in s.text
if __name__=='__main__':
report_dir= r's.html'
re_open= open(report_dir,'wb')
suite=unittest.TestLoader().loadTestsFromTestCase(Testbaiduapi)
runner=HTMLTestRunner.HTMLTestRunner(
stream=re_open,
title=u'接口测试报告',
description=u'接口测试详情'
)
runner.run(suite)
A网页抓包信息,用来填写接口信息内容

A网页的校验信息

B网页校验信息

我们第三个用例跳过登录页面直接访问登录成功后的首页,不过需要先抓包登录报文的报文头和登录信息,附在post报文上,然后我们特意用session来进行操作,这样在进行后续操作时只需要直接get目的网址就行了,比如B网页的网址,可以直接访问,当然用来测试只要在每个网页添加校验信息即可,一样可以起到测试的作用
但是如果B网页如果登录不成功,那么整个第三个用例会报错,可以预见如果在第三个用例爬取多个网页,那么其中任何一个网页有问题都会导致整个用例报错,对于测试人员排查显得太麻烦了,于是我门单独把B网页写进第四个用例,当然需要重新填写报文头和登录信息,并用post发报,因为只是爬取一个网页所以没有必要用session,只要requests即可
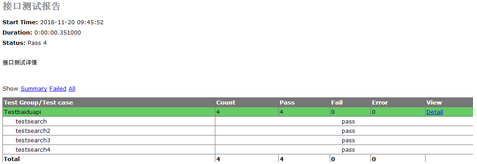
运行结果及报告

 浙公网安备 33010602011771号
浙公网安备 33010602011771号