Python自动化开发学习的第二周---python基础学习
1.列表、元组操作
列表是我们最以后最常用的数据类型之一,通过列表可以对数据实现最方便的存储、修改等操作
切片:取多个元素


1 >>> names = ["Alex","Tenglan","Eric","Rain","Tom","Amy"] 2 >>> names[1:4] #取下标1至下标4之间的数字,包括1,不包括4 3 ['Tenglan', 'Eric', 'Rain'] 4 >>> names[1:-1] #取下标1至-1的值,不包括-1 5 ['Tenglan', 'Eric', 'Rain', 'Tom'] 6 >>> names[0:3] 7 ['Alex', 'Tenglan', 'Eric'] 8 >>> names[:3] #如果是从头开始取,0可以忽略,跟上句效果一样 9 ['Alex', 'Tenglan', 'Eric'] 10 >>> names[3:] #如果想取最后一个,必须不能写-1,只能这么写 11 ['Rain', 'Tom', 'Amy'] 12 >>> names[3:-1] #这样-1就不会被包含了 13 ['Rain', 'Tom'] 14 >>> names[0::2] #后面的2是代表,每隔一个元素,就取一个 15 ['Alex', 'Eric', 'Tom'] 16 >>> names[::2] #和上句效果一样 17 ['Alex', 'Eric', 'Tom']
1 names = ["zhangsan","lisi","wangwu","zhaoliu",["libai","lihe","ligui","lishangyin"],"libai"] 2 3 print (names[1]) 4 print (names[0:5:2]) 5 print (names[0:3]) #查看元素 6 names [1] = "李四" #修改元素 7 names.append("libai") #增加元素 8 names.insert(2,"dufu") #插入元素 9 names.remove("wangwu") 10 del names[2] #删除元素 11 names.sort() #排序 12 names.pop(2) #删除特定元素,括号内不标注表示最后一个 13 names.reverse() #反转 14 names.clear() #清空列表 15 print (names.index("zhangsan")) #查看元素第一次出现的下标 16 print (len(names)) #列表的长度 17 print (names.count("libai")) #统计元素出现的次数 18 19 name2= [1,2,3,4] 20 names.extend(name2) #扩展元素
元组
元组其实跟列表差不多,也是存一组数,只不是它一旦创建,便不能再修改,所以又叫只读列表
它只有2个方法,一个是count,一个是index,完毕。
2.字符串操作
特性:不可修改
1 name.capitalize() 首字母大写 2 name.casefold() 大写全部变小写 3 name.center(50,"-") 输出 '---------------------Alex Li----------------------' 4 name.count('lex') 统计 lex出现次数 5 name.encode() 将字符串编码成bytes格式 6 name.endswith("Li") 判断字符串是否以 Li结尾 7 "Alex\tLi".expandtabs(10) 输出'Alex Li', 将\t转换成多长的空格 8 name.find('A') 查找A,找到返回其索引, 找不到返回-1 9 10 format : 11 >>> msg = "my name is {}, and age is {}" 12 >>> msg.format("alex",22) 13 'my name is alex, and age is 22' 14 >>> msg = "my name is {1}, and age is {0}" 15 >>> msg.format("alex",22) 16 'my name is 22, and age is alex' 17 >>> msg = "my name is {name}, and age is {age}" 18 >>> msg.format(age=22,name="ale") 19 'my name is ale, and age is 22' 20 format_map 21 >>> msg.format_map({'name':'alex','age':22}) 22 'my name is alex, and age is 22' 23 24 25 msg.index('a') 返回a所在字符串的索引 26 '9aA'.isalnum() True 27 28 '9'.isdigit() 是否整数 29 name.isnumeric 30 name.isprintable 31 name.isspace 32 name.istitle 33 name.isupper 34 "|".join(['alex','jack','rain']) 35 'alex|jack|rain' 36 37 38 maketrans 39 >>> intab = "aeiou" #This is the string having actual characters. 40 >>> outtab = "12345" #This is the string having corresponding mapping character 41 >>> trantab = str.maketrans(intab, outtab) 42 >>> 43 >>> str = "this is string example....wow!!!" 44 >>> str.translate(trantab) 45 'th3s 3s str3ng 2x1mpl2....w4w!!!' 46 47 msg.partition('is') 输出 ('my name ', 'is', ' {name}, and age is {age}') 48 49 >>> "alex li, chinese name is lijie".replace("li","LI",1) 50 'alex LI, chinese name is lijie' 51 52 msg.swapcase 大小写互换 53 54 55 >>> msg.zfill(40) 56 '00000my name is {name}, and age is {age}' 57 58 59 60 >>> n4.ljust(40,"-") 61 'Hello 2orld-----------------------------' 62 >>> n4.rjust(40,"-") 63 '-----------------------------Hello 2orld' 64 65 66 >>> b="ddefdsdff_哈哈" 67 >>> b.isidentifier() #检测一段字符串可否被当作标志符,即是否符合变量命名规则 68 True
1、去空格及特殊符号
s.strip().lstrip().rstrip(',')
2、复制字符串
1 #strcpy(sStr1,sStr2) 2 sStr1 = 'strcpy' 3 sStr2 = sStr1 4 sStr1 = 'strcpy2' 5 print sStr2
3、连接字符串
1 #strcat(sStr1,sStr2) 2 sStr1 = 'strcat' 3 sStr2 = 'append' 4 sStr1 += sStr2 5 print sStr1
4、查找字符
1 #strchr(sStr1,sStr2) 2 # < 0 为未找到 3 sStr1 = 'strchr' 4 sStr2 = 's' 5 nPos = sStr1.index(sStr2) 6 print nPos
5、比较字符串
1 #strcmp(sStr1,sStr2) 2 sStr1 = 'strchr' 3 sStr2 = 'strch' 4 print cmp(sStr1,sStr2)
6、扫描字符串是否包含指定的字符
1 #strspn(sStr1,sStr2) 2 sStr1 = '12345678' 3 sStr2 = '456' 4 #sStr1 and chars both in sStr1 and sStr2 5 print len(sStr1 and sStr2)
7、字符串长度
1 #strlen(sStr1) 2 sStr1 = 'strlen' 3 print len(sStr1)
8、将字符串中的大小写转换
S.lower() #小写 S.upper() #大写 S.swapcase() #大小写互换 S.capitalize() #首字母大写 String.capwords(S) #这是模块中的方法。它把S用split()函数分开,然后用capitalize()把首字母变成大写,最后用join()合并到一起 #实例: #strlwr(sStr1) sStr1 = 'JCstrlwr' sStr1 = sStr1.upper() #sStr1 = sStr1.lower() print sStr1
9、追加指定长度的字符串
1 #strncat(sStr1,sStr2,n) 2 sStr1 = '12345' 3 sStr2 = 'abcdef' 4 n = 3 5 sStr1 += sStr2[0:n] 6 print sStr1
10、字符串指定长度比较
1 #strncmp(sStr1,sStr2,n) 2 sStr1 = '12345' 3 sStr2 = '123bc' 4 n = 3 5 print cmp(sStr1[0:n],sStr2[0:n])
11、复制指定长度的字符
1 #strncpy(sStr1,sStr2,n) 2 sStr1 = '' 3 sStr2 = '12345' 4 n = 3 5 sStr1 = sStr2[0:n] 6 print sStr1
12、将字符串前n个字符替换为指定的字符
1 #strnset(sStr1,ch,n) 2 sStr1 = '12345' 3 ch = 'r' 4 n = 3 5 sStr1 = n * ch + sStr1[3:] 6 print sStr1
13、扫描字符串
1 #strpbrk(sStr1,sStr2) 2 sStr1 = 'cekjgdklab' 3 sStr2 = 'gka' 4 nPos = -1 5 for c in sStr1: 6 if c in sStr2: 7 nPos = sStr1.index(c) 8 break 9 print nPos
14、翻转字符串
1 #strrev(sStr1) 2 sStr1 = 'abcdefg' 3 sStr1 = sStr1[::-1] 4 print sStr1
15、查找字符串
1 #strstr(sStr1,sStr2) 2 sStr1 = 'abcdefg' 3 sStr2 = 'cde' 4 print sStr1.find(sStr2)
16、分割字符串
1 #strtok(sStr1,sStr2) 2 sStr1 = 'ab,cde,fgh,ijk' 3 sStr2 = ',' 4 sStr1 = sStr1[sStr1.find(sStr2) + 1:] 5 print sStr1 6 #或者 7 s = 'ab,cde,fgh,ijk' 8 print(s.split(','))
17、连接字符串
1 delimiter = ',' 2 mylist = ['Brazil', 'Russia', 'India', 'China'] 3 print delimiter.join(mylist)
18、PHP 中 addslashes 的实现
1 def addslashes(s): 2 d = {'"':'\\"', "'":"\\'", "\0":"\\\0", "\\":"\\\\"} 3 return ''.join(d.get(c, c) for c in s) 4 5 s = "John 'Johny' Doe (a.k.a. \"Super Joe\")\\\0" 6 print s 7 print addslashes(s)
19、只显示字母与数字
1 def OnlyCharNum(s,oth=''): 2 s2 = s.lower(); 3 fomart = 'abcdefghijklmnopqrstuvwxyz0123456789' 4 for c in s2: 5 if not c in fomart: 6 s = s.replace(c,''); 7 return s; 8 9 print(OnlyStr("a000 aa-b"))
20、截取字符串
1 str = '0123456789′ 2 print str[0:3] #截取第一位到第三位的字符 3 print str[:] #截取字符串的全部字符 4 print str[6:] #截取第七个字符到结尾 5 print str[:-3] #截取从头开始到倒数第三个字符之前 6 print str[2] #截取第三个字符 7 print str[-1] #截取倒数第一个字符 8 print str[::-1] #创造一个与原字符串顺序相反的字符串 9 print str[-3:-1] #截取倒数第三位与倒数第一位之前的字符 10 print str[-3:] #截取倒数第三位到结尾 11 print str[:-5:-3] #逆序截取,具体啥意思没搞明白?
21、字符串在输出时的对齐
1 S.ljust(width,[fillchar]) 2 #输出width个字符,S左对齐,不足部分用fillchar填充,默认的为空格。 3 S.rjust(width,[fillchar]) #右对齐 4 S.center(width, [fillchar]) #中间对齐 5 S.zfill(width) #把S变成width长,并在右对齐,不足部分用0补足
22、字符串中的搜索和替换
1 S.find(substr, [start, [end]]) 2 #返回S中出现substr的第一个字母的标号,如果S中没有substr则返回-1。start和end作用就相当于在S[start:end]中搜索 3 S.index(substr, [start, [end]]) 4 #与find()相同,只是在S中没有substr时,会返回一个运行时错误 5 S.rfind(substr, [start, [end]]) 6 #返回S中最后出现的substr的第一个字母的标号,如果S中没有substr则返回-1,也就是说从右边算起的第一次出现的substr的首字母标号 7 S.rindex(substr, [start, [end]]) 8 S.count(substr, [start, [end]]) #计算substr在S中出现的次数 9 S.replace(oldstr, newstr, [count]) 10 #把S中的oldstar替换为newstr,count为替换次数。这是替换的通用形式,还有一些函数进行特殊字符的替换 11 S.strip([chars]) 12 #把S中前后chars中有的字符全部去掉,可以理解为把S前后chars替换为None 13 S.lstrip([chars]) 14 S.rstrip([chars]) 15 S.expandtabs([tabsize]) 16 #把S中的tab字符替换没空格,每个tab替换为tabsize个空格,默认是8个
23、字符串的分割和组合
1 S.split([sep, [maxsplit]]) 2 #以sep为分隔符,把S分成一个list。maxsplit表示分割的次数。默认的分割符为空白字符 3 S.rsplit([sep, [maxsplit]]) 4 S.splitlines([keepends]) 5 #把S按照行分割符分为一个list,keepends是一个bool值,如果为真每行后而会保留行分割符。 6 S.join(seq) #把seq代表的序列──字符串序列,用S连接起来
24、字符串的mapping,这一功能包含两个函数
1 String.maketrans(from, to) 2 #返回一个256个字符组成的翻译表,其中from中的字符被一一对应地转换成to,所以from和to必须是等长的。 3 S.translate(table[,deletechars]) 4 # 使用上面的函数产后的翻译表,把S进行翻译,并把deletechars中有的字符删掉。需要注意的是,如果S为unicode字符串,那么就不支持 deletechars参数,可以使用把某个字符翻译为None的方式实现相同的功能。此外还可以使用codecs模块的功能来创建更加功能强大的翻译表。
25、字符串还有一对编码和解码的函数
1 S.encode([encoding,[errors]]) 2 # 其中encoding可以有多种值,比如gb2312 gbk gb18030 bz2 zlib big5 bzse64等都支持。errors默认值为"strict",意思是UnicodeError。可能的值还有'ignore', 'replace', 'xmlcharrefreplace', 'backslashreplace' 和所有的通过codecs.register_error注册的值。这一部分内容涉及codecs模块,不是特明白 3 S.decode([encoding,[errors]])
26、字符串的测试、判断函数,这一类函数在string模块中没有,这些函数返回的都是bool值
1 S.startswith(prefix[,start[,end]]) 2 #是否以prefix开头 3 S.endswith(suffix[,start[,end]]) 4 #以suffix结尾 5 S.isalnum() 6 #是否全是字母和数字,并至少有一个字符 7 S.isalpha() #是否全是字母,并至少有一个字符 8 S.isdigit() #是否全是数字,并至少有一个字符 9 S.isspace() #是否全是空白字符,并至少有一个字符 10 S.islower() #S中的字母是否全是小写 11 S.isupper() #S中的字母是否便是大写 12 S.istitle() #S是否是首字母大写的
27、字符串类型转换函数,这几个函数只在string模块中有
1 string.atoi(s[,base]) 2 #base默认为10,如果为0,那么s就可以是012或0x23这种形式的字符串,如果是16那么s就只能是0x23或0X12这种形式的字符串 3 string.atol(s[,base]) #转成long 4 string.atof(s[,base]) #转成float
这里再强调一次,字符串对象是不可改变的,也就是说在python创建一个字符串后,你不能把这个字符中的某一部分改变。任何上面的函数改变了字符串后,都会返回一个新的字符串,原字串并没有变。其实这也是有变通的办法的,可以用S=list(S)这个函数把S变为由单个字符为成员的list,这样的话就可以使用S[3]='a'的方式改变值,然后再使用S=" ".join(S)还原成字符串
3.字典操作
字典一种key - value 的数据类型,使用就像我们上学用的字典,通过笔划、字母来查对应页的详细内容。
字典的特性:
- dict是无序的
- key必须是唯一的,so 天生去重
1 info = { 2 "stu1101": "zhangsan", 3 "stu1102": "lisi", 4 "stu1103": "wangwu", 5 } 6 7 info["stu1104"]="zhaoliu" #增加 8 9 info["stu1101"]="ZHANGSAN" #修改 10 11 info.pop("stu1101") 12 del info["stu1101"]#删除 13 info.popitem()#随机删除 14 15 "stu1101" in info 16 info.get("stu1101") 17 info["stu1101"] #查找
4.集合操作
集合是一个无序的,不重复的数据组合,它的主要作用如下:
- 去重,把一个列表变成集合,就自动去重了
- 关系测试,测试两组数据之前的交集、差集、并集等关系
常用操作
1 s = set([3,5,9,10]) #创建一个数值集合 2 3 t = set("Hello") #创建一个唯一字符的集合 4 5 6 a = t | s # t 和 s的并集 7 8 b = t & s # t 和 s的交集 9 10 c = t – s # 求差集(项在t中,但不在s中) 11 12 d = t ^ s # 对称差集(项在t或s中,但不会同时出现在二者中) 13 14 15 16 基本操作: 17 18 t.add('x') # 添加一项 19 20 s.update([10,37,42]) # 在s中添加多项 21 22 23 24 使用remove()可以删除一项: 25 26 t.remove('H') 27 28 29 len(s) 30 set 的长度 31 32 x in s 33 测试 x 是否是 s 的成员 34 35 x not in s 36 测试 x 是否不是 s 的成员 37 38 s.issubset(t) 39 s <= t 40 测试是否 s 中的每一个元素都在 t 中 41 42 s.issuperset(t) 43 s >= t 44 测试是否 t 中的每一个元素都在 s 中 45 46 s.union(t) 47 s | t 48 返回一个新的 set 包含 s 和 t 中的每一个元素 49 50 s.intersection(t) 51 s & t 52 返回一个新的 set 包含 s 和 t 中的公共元素 53 54 s.difference(t) 55 s - t 56 返回一个新的 set 包含 s 中有但是 t 中没有的元素 57 58 s.symmetric_difference(t) 59 s ^ t 60 返回一个新的 set 包含 s 和 t 中不重复的元素 61 62 s.copy() 63 返回 set “s”的一个浅复制
5.文件操作
对文件操作流程
- 打开文件,得到文件句柄并赋值给一个变量
- 通过句柄对文件进行操作
- 关闭文件
打开文件的模式有:
- r,只读模式(默认)。
- w,只写模式。【不可读;不存在则创建;存在则删除内容;】
- a,追加模式。【可读; 不存在则创建;存在则只追加内容;】
"+" 表示可以同时读写某个文件
- r+,可读写文件。【可读;可写;可追加】
- w+,写读
- a+,同a
"U"表示在读取时,可以将 \r \n \r\n自动转换成 \n (与 r 或 r+ 模式同使用)
- rU
- r+U
"b"表示处理二进制文件(如:FTP发送上传ISO镜像文件,linux可忽略,windows处理二进制文件时需标注)
- rb
- wb
- ab
fp= open("test.txt",w) 直接打开一个文件,如果文件不存在则创建文件
fp.read([size]) #size为读取的长度,以byte为单位
fp.readline([size]) #读一行,如果定义了size,有可能返回的只是一行的一部分
fp.readlines([size]) #把文件每一行作为一个list的一个成员,并返回这个list。其实它的内部是通过循环调用readline()来实现的。如果提供size参数,size是表示读取内容的总长,也就是说可能只读到文件的一部分。
fp.write(str) #把str写到文件中,write()并不会在str后加上一个换行符
fp.writelines(seq) #把seq的内容全部写到文件中(多行一次性写入)。这个函数也只是忠实地写入,不会在每行后面加上任何东西。
fp.close() #关闭文件。python会在一个文件不用后自动关闭文件,不过这一功能没有保证,最好还是养成自己关闭的习惯。 如果一个文件在关闭后还对其进行操作会产生ValueError
fp.flush() #把缓冲区的内容写入硬盘
fp.fileno() #返回一个长整型的”文件标签“
fp.isatty() #文件是否是一个终端设备文件(unix系统中的)
fp.tell() #返回文件操作标记的当前位置,以文件的开头为原点
fp.next() #返回下一行,并将文件操作标记位移到下一行。把一个file用于for … in file这样的语句时,就是调用next()函数来实现遍历的。
fp.seek(offset[,whence]) #将文件打操作标记移到offset的位置。这个offset一般是相对于文件的开头来计算的,一般为正数。但如果提供了whence参数就不一定了,whence可以为0表示从头开始计算,1表示以当前位置为原点计算。2表示以文件末尾为原点进行计算。需要注意,如果文件以a或a+的模式打开,每次进行写操作时,文件操作标记会自动返回到文件末尾。
fp.truncate([size]) #把文件裁成规定的大小,默认的是裁到当前文件操作标记的位置。如果size比文件的大小还要大,依据系统的不同可能是不改变文件,也可能是用0把文件补到相应的大小,也可能是以一些随机的内容加上去。
with语句
为了避免打开文件后忘记关闭,可以通过管理上下文,即:
with open('log','r') as f:
如此方式,当with代码块执行完毕时,内部会自动关闭并释放文件资源。
在Python 2.7 后,with又支持同时对多个文件的上下文进行管理,即:
1 with open('log1') as obj1, open('log2') as obj2: 2 pass
6.字符编码与转码
详细文章:
http://www.cnblogs.com/yuanchenqi/articles/5956943.html
http://www.diveintopython3.net/strings.html
需知:
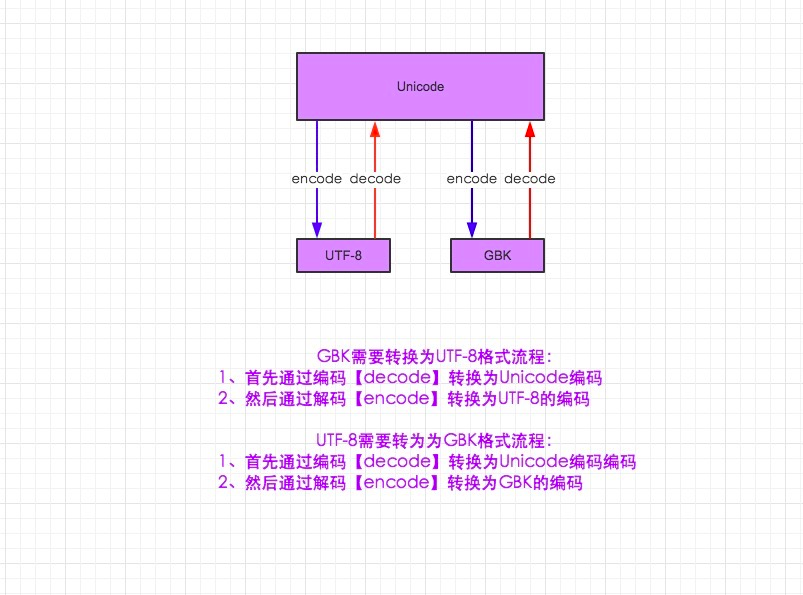
1.在python2默认编码是ASCII, python3里默认是unicode
2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-16就是现在最常用的unicode版本, 不过在文件里存的还是utf-8,因为utf8省空间
3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string

 浙公网安备 33010602011771号
浙公网安备 33010602011771号