Mysql优化 B+Tree索引和Hash索引
B+Tree索引#
B+Tree和普通的B-Tree不大一样。有个网站可以体验这些数据结构:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
先看一下B-Tree
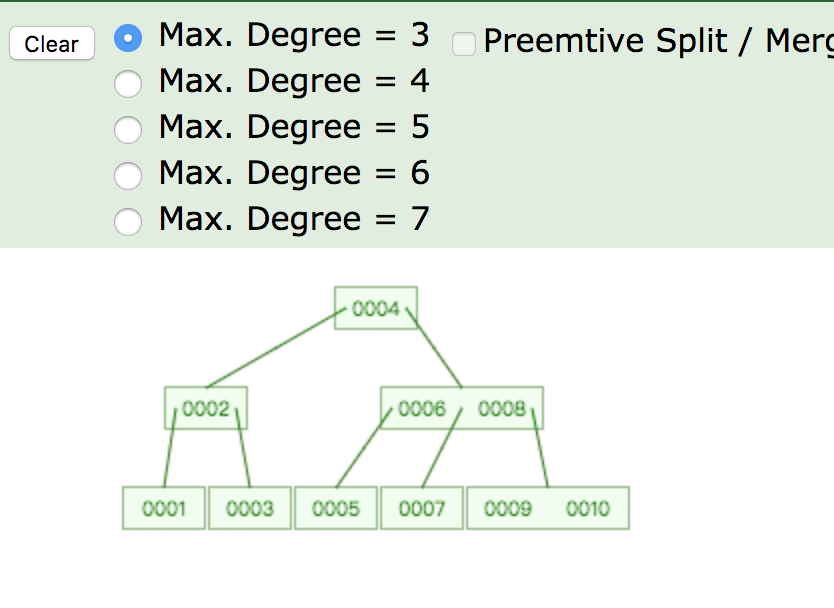
设定最大深度为3,插入10个数字,数据结构如上,他与普通的二叉树区别在于每个节点有多个数据,相当于横向扩展,减少深度。
为什么要减少深度:当数据量比较大的时候,mysql无法将索引全部加载到内存中,只能逐一加载磁盘页,每个磁盘页对应树的节点。造成大量磁盘IO操作(最坏情况下为树的高度)。平衡二叉树由于树深度过大而造成磁盘IO读写过于频繁,进而导致效率低下。所以,我们为了减少磁盘IO的次数,就你必须降低树的深度,将“瘦高”的树变得“矮胖”。
B树在这一点上已经比二叉树先进很多了,但对比B+树还是差了点,为了更好说明B+树,需要提到的是在Mysql中,B数的节点中都带有存储数据。
依然到网站中去体验一下B+树:
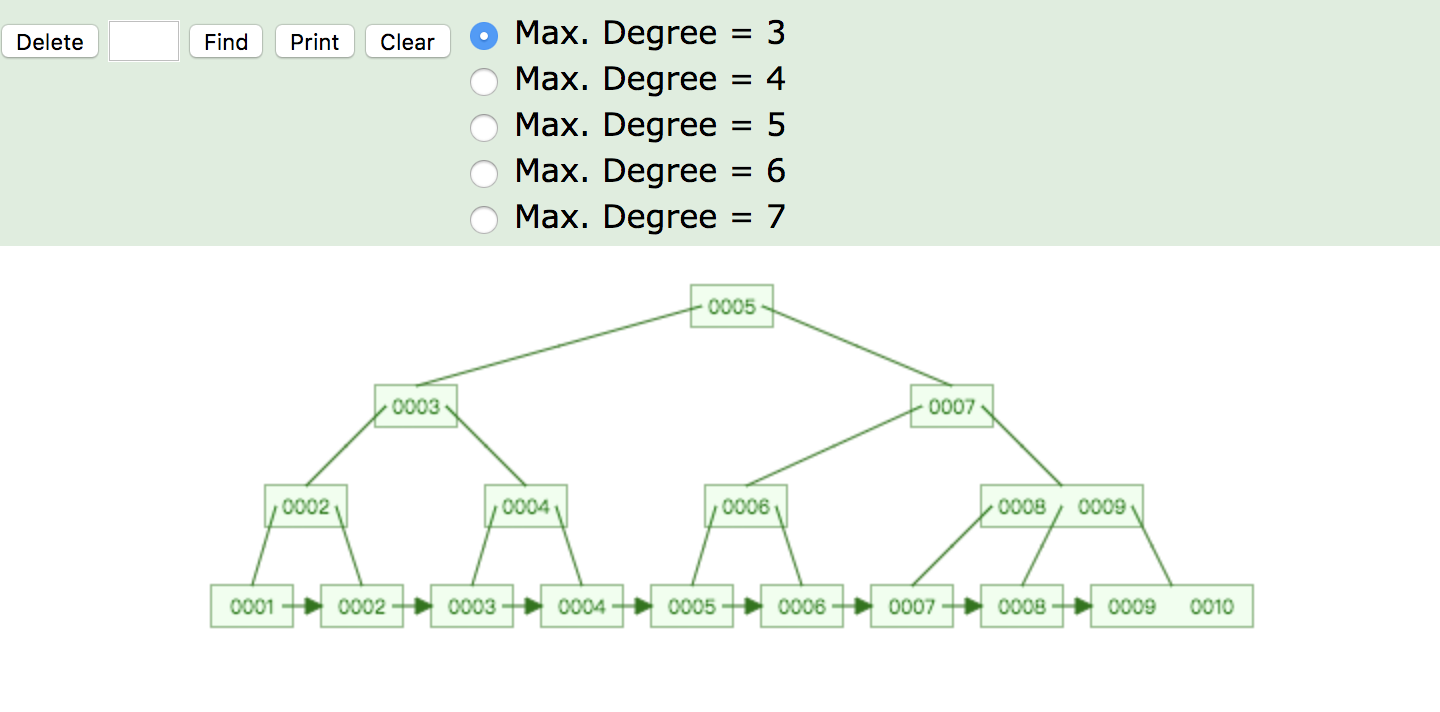
可以看到两个特点:
1.同样是三层数据,但是这里多了一层数据层,那是因为,B+树只有最后的叶子节点才会带有数据,其他的都是索引。
2.数据间带有一个指针
这些特点有什么用呢?
1.在Mysql的B树索引方式中,每个节点的存储容量是固定的,如果节点中存储了数据,意味着,该节点只能存储更少的索引,这将导致查找数据时需要经过更多的IO,反过来,B+树可以更快找到对应的数据
2.B树的查找只需找到匹配元素即可,最好情况下查找到根节点,最坏情况下查找到叶子结点,所说性能很不稳定,而B+树每次必须查找到叶子结点,性能稳定
3.在范围查询方面,B+树的优势更加明显。B树的范围查找需要不断依赖中序遍历。首先二分查找到范围下限,在不断通过中序遍历,知道查找到范围的上限即可。整个过程比较耗时。而B+树的范围查找则简单了许多。首先通过二分查找,找到范围下限,然后同过叶子结点的链表顺序遍历,直至找到上限即可,整个过程简单许多,效率也比较高。
比如,当查找索引值大于某个数值时,根据数据节点的向后指针,B+树只要找到临界点后,直接可以找到后面的所有数据,而不用回到根节点上再去查找。
Hash索引#
哈希索引是基于哈希表实现的,只有精确匹配索引所有的列的查询才有效。对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码,哈希码是一个较小的值,并且不同键值的行计算出来的哈希码也不一样。哈希索引是将所有的哈希码存储在索引中,同时在哈希表中保存指向每个数据行的指针。
在MySQL中,只有Memory 引擎显示支持哈希索引。这也是Memory 引擎表的默认索引类型,Memory 引擎同时也支持B-Tree索引。这里插播一个Mysql的存储引擎,如果涉及到索引的类型的设计,还是有必要参考一下的
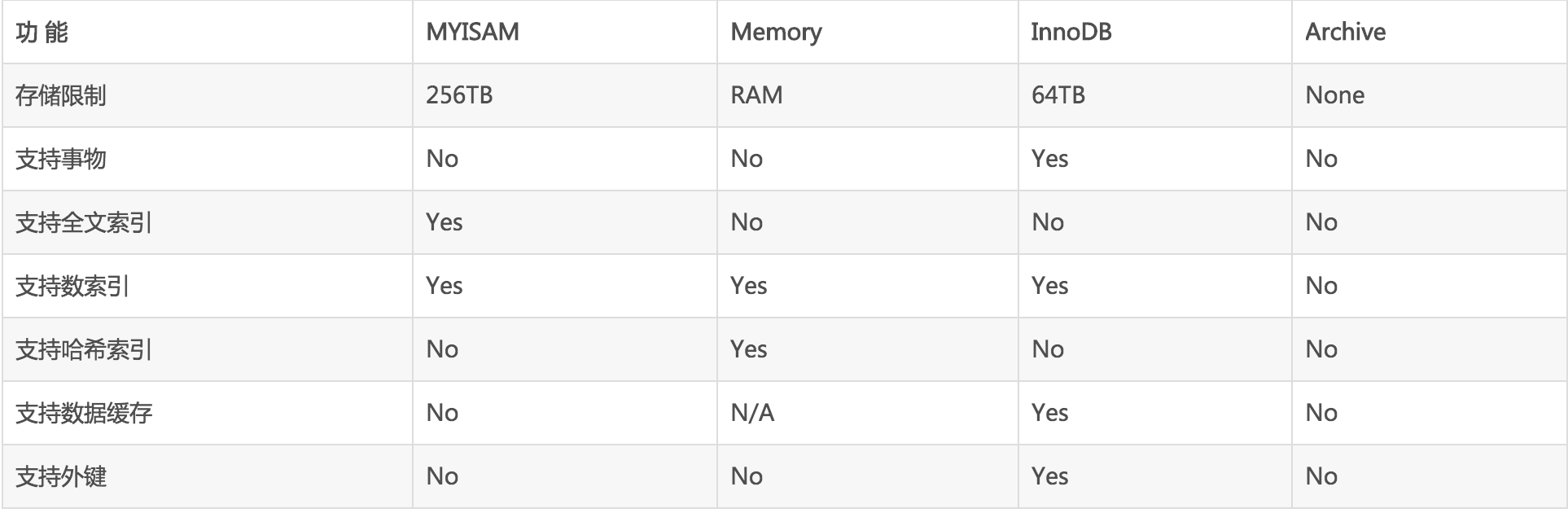
可以主要到,如果需要支持外键的话,那基本只能选择InnoDB类型。
回到主题,当采用了Hash索引之后,在数据库中根据索引查找一个记录时非常快的事情:
1.根据索引值计算hash,速度极快
2.根据hash值获取存储地址,速度极快
3.根据存储地址获取数据,速度极快
hash索引虽然查询快,但是那仅限于精确查询,他的缺陷同样不小:
哈希索引只包含哈希值和行指针,而不存储字段值,所以不能上使用索引中的值来避免读取行。
哈希索引数据并不是按照索引值顺序存储的,所以也就无法用于排序。
哈希索引也不支持部分索引列匹配查找,因为哈希索引始终是使用索引列的全部内容来计算哈希值的。
哈希索引只支持等值比较查询,包括=、IN( )、<=>(注意<>和<=>是不同的操作)。也不支持任何范围查询,如 WHERE price > 100 ;
访问哈希索引的数据结构非常快,除非有许多哈希冲突
如果哈希冲突很多,一些索引维护操作的代价也会很高。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架