JAVA优化篇 如何从茫茫日志中找到运行缓慢的线程
引入#
JAVA提供了一些分析DUMP的工具,比如jmap,visualvm 等
JAVA还有寻找线程状态的工具,jstack等
数据库也有检查连接数,连接状态的命令,status,processlist等
代码中也可以添加一些时间的信息,对比信息发现可优化的地方
但这些都不是今天要记录的内容,今天要做的是使用一个比较暴力的方式查找出高并发模式下运行缓慢的线程
正文#
写高并发的时候经常会遇到的问题:
单独观察每个分支线程或者主线程时,都执行地非常快,但是总体上运行的TPS却并不高,没有达到期望的值
更换环境,或者调大运行内存和CPU后,情况仍然不见好转
这时候有个办法是,找出每个线程的运行过程,寻找出耗时较大的代码段,再对代码进行分析
脚本我已经写好了:



#!/bin/bash parseLog(){ ##初始值 upLine="blank" last_time_pre="blank" last_time_post="blank" cat "$1" | while read line do time_pre=`echo "$line" | awk '{print$1}'` time_post=`echo "$line" | awk '{print$2}'` if [[ `echo "$time_post" | grep ":"` != "" ]] then if [[ "$upLine" == "blank" ]] then upLine=${line} last_time_pre=`echo "$line" | awk '{print$1}'` last_time_post=`echo "$line" | awk '{print$2}'` total2="$last_time_pre"" $last_time_post" last_time_pre=`date +%s -d "$total2"` last_time_pre=`expr "$last_time_pre" \* 1000` last_time_post=`echo ${last_time_post:9:3}` else total="$time_pre"" $time_post" time_pre=`date +%s -d "$total"` time_pre=`expr "$time_pre" \* 1000` time_post=`echo ${time_post:9:3}` time_end=`expr "$time_pre" + "$time_post"` time_begin=`expr "$last_time_pre" + "$last_time_post" + "$2"` last_time_pre=${time_pre} last_time_post=${time_post} if [[ "$time_end" -gt "$time_begin" ]] then echo ${upLine} >> result.log echo ${line} >> result.log fi upLine=${line} fi fi done } if [[ ! -n "$1" ]] || [[ ! -n "$2" ]] || [[ ! -n "$3" ]] then echo [log file] [interval millis] [key words] exit fi awk '{num[$4]++} END{for(k in num)print k,"----",num[k]|"sort -k 3 -rn"}' "$1" | head -n 15 | awk '{str[$1]++} END{for (s in str)print s}'| grep "$3" > thread.log ##对上述输出的每一个线程做分析处理,调用parseLog cat thread.log | while read line do grep "\""${line}"\"" "$1" > temp.log parseLog temp.log $2 done exit
这个脚本有个基础条件是,分析的日志必须得是按照一定规范输出的日志,输出字段中带有时间和线程名
脚本传参:
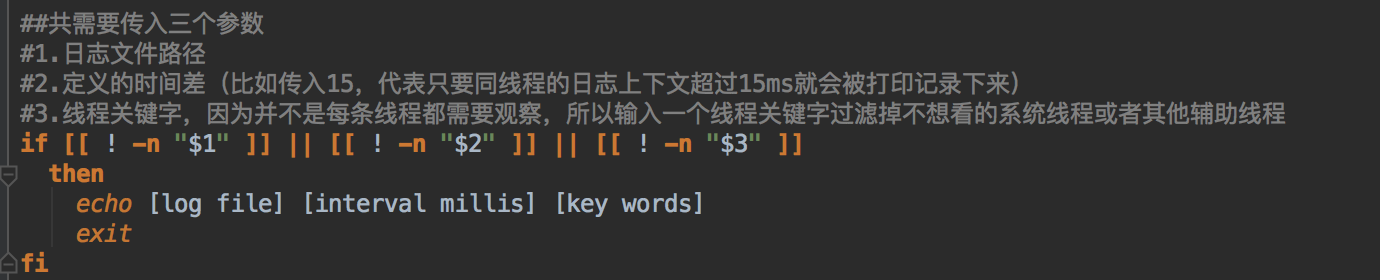
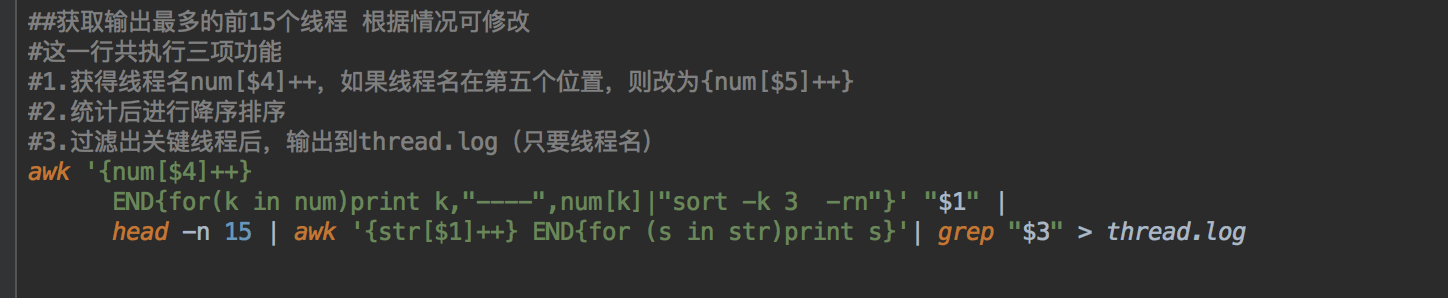
获得可以分析的所有线程,按照数量排序,并只获得前15个
接下来对每一个过滤出来的线程做分析处理

最后就是分析日志的方法了
主要思路是,用下一行的时间减去上一行的时间,如果超过给定的值,就将两行都输出到指定文件。

执行效果:
[utap@host145 logs]$ sh pick_thread.sh bb.log 1 timer timerQ_3-service-#146] [utap@host145 logs]$ cat result.log 2019-11-05 00:02:00.371 [DEBUG] [TaskRule:405][printExpr] [timerQ_3-service-#146] [100000000004] - TaskRule printExpr i-j=2-0, expr[i].elementAt(j).m_min=0, m_max=9999 2019-11-05 00:02:00.373 [DEBUG] [TaskRule:405][printExpr] [timerQ_3-service-#146] [100000000004] - TaskRule printExpr i-j=3-0, expr[i].elementAt(j).m_min=0, m_max=9999^C
方便再次使用到吧,地址在 https://github.com/garfieldcgf/notes/tree/master/operations/bin



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架
2019-01-03 Specified version of key is not available (44)