Python修炼之路-数据类型
Python编程之列表
列表是一个使用一对中括号"[ ]" 括起来的有序的集合,可以通过索引访问列表元素,也可以增加和删除元素。
列表的索引:第一个元素索引为0,最后一个元素索引为-1。
#列表的定义与访问 >>> L = ['python', 11, True] >>> print(L) #['python', 11, True] >>> L[-1] # True >>> L[0] # 'python' >>> L[2] # True
列表常用方法
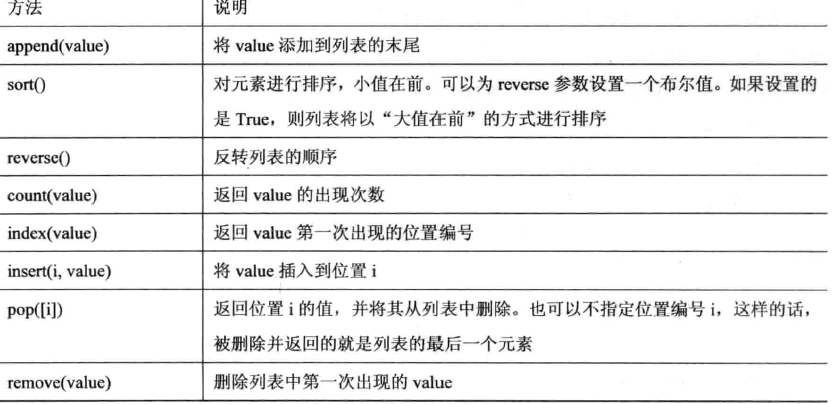
实例
#***************插入******************* >>> L = ['python', 11, True] >>> L.append('hello') #append插入 >>> L # ['python', 11, True, 'hello'] >>> L.insert(0,False) #指定位置插入 >>> L #[False, 'python', 11, True, 'hello'] >>> L.insert(10,'world') #插入索引区别 >>> L #[False, 'python', 11, True, 'hello', 'world'] >>> L[5] #'world' #***************删除******************* >>> L = ['python', 11, True] >>> L.pop() #True #pop弹出,默认弹出最后一个 >>> L #['python', 11] >>> L.pop(0) #'python' #pop指定位置弹出 >>> L #[11] >>> L = ['python', 11, True] >>> L.remove(11) #remove删除 >>> L #['python', True] >>> L = ["A","B","C","D","E"] >>> del L[2] #删除一个元素 >>> L #['A', 'B', 'D', 'E'] >>> del L[2:] #删除一个范围内的元素 >>> L #['A', 'B'] #***************更新******************* >>> L = ['python', 11, True] >>> L[2] = False >>> L #['python', 11, False]
#***************排序与索引***************** >>> L.sort(reverse=True) #排序 >>> L #['E', 'D', 'C', 'B', 'A'] >>> L = ["A",1,"Bob"] #注意不能和数字在一起排序 >>> L.sort() Traceback (most recent call last): File "<pyshell#34>", line 1, in <module> L.sort() TypeError: unorderable types: int() < str() >>> L = ["A","1","Bob"] #转换成字符串即可 >>> L.sort() >>> L #['1', 'A', 'Bob'] >>> L.reverse() #参考上面reverse=False >>> L #['Bob', 'A', '1']
#***************扩展********************** >>> M = ["1",2,"C"] >>> L.extend(M) >>> L #['Bob', 'A', '1', '1', 2, 'C']
#***************其他用法******************* >>> L = ["A","B","C","D","E"] >>> L.index("B") #1 返回索引值 >>> L.count('C') #1 统计"value"出现的次数
列表切片
列表切片:用于从列表或元组中截取元素。
截取原则:自左向右截取,顾头不顾尾原则。
usage: if the first index is ‘0’ or the last one, which could be ignored; Meanwhile slice could appoint the third parameter that means intercept one element out of every N element.
L[1:3]: it means that the index is from one to three, but it doesn’t include this element which index is three.
>>> L = ['A',1,True,'a'] >>> L[1:3] #[1, True] >>> L = ['A',1,True,’a’] >>> L[:2] #['A', 1] >>> L[:] #['A', 1, True, 'a'] >>> L = range(1,10) >>> L[2::3] #[3, 6, 9] >>> L[2:7:3] #[3, 6] >>> L = range(1,11) >>> L [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] >>> L[-5:-1] [6, 7, 8, 9] >>> L[-5:] [6, 7, 8, 9, 10] >>> L[-5::3] [6, 9]
字符串切片处理
>>> 'asdfghjkl'[:3] 'asd' >>> 'asdfghjkl'[-3:] 'jkl' >>> 'asdfghjkl'[::2] 'adgjl'
遍历列表
#**********enumerate用法:返回列表的索引以及元素值******************** f = open("file","r",encoding="utf-8") #文件句柄,输出中文时注意文件编码 count = 0 for index, line in enumerate(f): count += 1 print(count) #9 一共有多少行 print(index) #8 最后一个索引值 f.close()
Python编程之元组
元组(tuple):一个用括号"()"括起来的有序序列,但是一旦创建便不可修改,所以又叫只读序列。
元组只有两个方法:count与index,参考list。
# if there is one element in tuple, there should be add one ‘,’ after element. >>> t = ('python',11,True) >>> t[0] 'python' >>> t = (1) #这只是一个数字,不是元组 >>> t 1 >>> t = (1,) >>> t (1,)
一个特殊的元组
>>> t = ('a','b',['A','B']) >>> t ('a', 'b', ['A', 'B']) >>> L = t[2] >>> L[0] = 'X' >>> L[1] = 'Y‘ >>> t ('a', 'b', ['X', 'Y'])
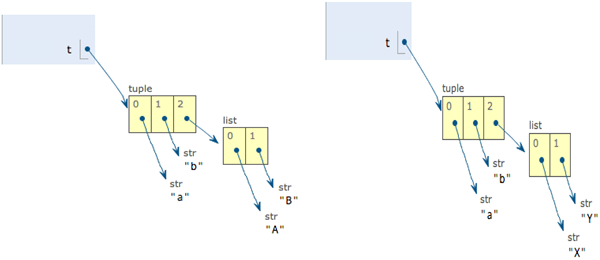
The unchangeable means tuple appointed should not be changed. Example, if appointed to a, it shouldn’t change to b.
#关于更多的赋值与指向,可以参考深浅拷贝。
Python编程之字符串操作
字符串定义:用单引号或双引号括起来任意字符。
特性:不可修改
转义字符:\
# \n : Enter \t: tab \\: \ \': '
raw string: 可以不使用"\"来转义, 禁止转义。
print(r'\(~_~)/(~_~)/') #\(~_~)/(~_~)/
使用:"""..."""或者'''...'''表示多行字符串。
print('''"To be, or not to be\": that is the question. Whether it\'s nobler in the mind to suffer.''')
字符串常用方法
| S.lower() | 小写 |
| S.upper() | 大写 |
| S.swapcase() | 大小写互换 |
| S.capitalize() | 首字母大写 |
| S.title() | 只有首字母大写,其余为小写 |
| S.ljust(width,"fillchar") | 输出width个字符,S左对齐,不足部分用fillchar填充,默认的为空格 |
| S.rjust(width,"fillchar") | 右对齐 |
| S.center(width, "fillchar") | |
| S.zfill(width) | 把S变成width长,并在右对齐,不足部分用0补足,左边补0 |
| S.find(substr, [start, [end]]) | 返回S中出现substr的第一个字母的标号,如果S中没有substr则返回-1。start和end作用就相当于在S[start:end]中搜索 |
| S.index(substr, [start, [end]]) | 与find()相同,只是在S中没有substr时,会返回一个运行时错误 |
| S.rfind(substr, [start, [end]]) | 返回S中最后出现的substr的第一个字母的标号,如果S中没有substr则返回-1,也就是说从右边算起的第一次出现的substr的首字母标号 |
| S.rindex(substr, [start, [end]]) | 计算substr在S中出现的次数 |
| S.replace(oldstr, newstr, [count]) | 把S中的oldstar替换为newstr,count为替换次数。这是替换的通用形式,还有一些函数进行特殊字符的替换 |
| S.strip([chars]) | 把S中前后chars中有的字符全部去掉,可以理解为把S前后chars替换为None |
| S.rstrip([chars]) | |
| S.lstrip([chars]) | |
| S.expandtabs([tabsize]) | 把S中的tab字符替换没空格,每个tab替换为tabsize个空格,默认是8个 |
| S.split([sep, [maxsplit]]) | 以sep为分隔符,把S分成一个list。maxsplit表示分割的次数。默认的分割符为空白字符 |
| S.rsplit([sep, [maxsplit]]) | |
| S.splitlines([keepends]) | 把S按照行分割符分为一个list,keepends是一个bool值,如果为真每行后而会保留行分割符。 |
| S.join(seq) | 把seq代表的序列(字符串序列),用S连接起来 |
| S.encode([encoding,[errors]]) | 编码 |
| S.decode([encoding,[errors]]) | 译码 |
| S.startwith(prefix[,start[,end]]) | 是否以prefix开头 |
| S.endwith(suffix[,start[,end]]) | 以suffix结尾 |
| S.isalnum() | 是否全是字母和数字,并至少有一个字符 |
| S.isalpha() | 是否全是字母,并至少有一个字符 |
| S.isdigit() | 是否全是数字,并至少有一个字符,如果是全数字返回True,否则返回False. |
| S.isspace() | 是否全是空白字符,并至少有一个字符 |
| S.islower() | S中的字母是否全是小写 |
| S.isupper() | S中的字母是否便是大写 |
| S.istitle() | S是否是首字母大写的 |
| trantab = str.maketrans(intab, outtab) | 制表 |
| S.translate(trantab) | 翻译,和上面的结合使用 |
实例
poem = "gently I go as quietly as I came here" print(poem.capitalize()) #首字母大写 # Gently i go as quietly as i came here print(poem.lower()) #所有字母变成小写 # gently i go as quietly as i came here print(poem.upper()) #GENTLY I GO AS QUIETLY AS I CAME HERE print(poem.swapcase()) # GENTLY i GO AS QUIETLY AS i CAME HERE print(poem.casefold()) #大写全部变小写 #gently i go as quietly as i came here print(poem.center(80,"-")) #输出80个字符,不足80个以“-”在字符串前后补充,字符串居中 #---------------------gently I go as quietly as I came here---------------------- print(poem.ljust(80,"*")) #打印80个字符,字符串在前,不足80的部分用"*"补充 # gently I go as quietly as I came here******************************************* print(poem.rjust(80,"-")) #-------------------------------------------gently I go as quietly as I came here print(poem.zfill(80)) #把字符串变成80个字符宽度,不足80的用0补足 #0000000000000000000000000000000000000000000gently I go as quietly as I came here print(poem.count("e")) #统计 e 出现次数 # 5 print(poem.find("e")) #返回字符串中第一次出现“e”的标号,如果没有则返回-1; # 1 也可以poem.find("e",[start, [end]])设置返回,相当于 poem[start:end] print(poem.rfind("e")) #返回poem中最后一次出现"e"的标号,如果没有则返回-1, #36 print(poem.rindex("e")) #同rfind() #36 print(poem.replace("e","E",2)) #replace(oldstr, newstr, [count]) , 替换 #gEntly I go as quiEtly as I came here print("\n\tPython\t is\n".strip()) #把前后的空格,换行制表等字符去掉 print("\n\tPython\t is\n".lstrip()) print("\n\tPython\t is\n".rstrip()) print("\n\tPython\t is".rstrip("s")) #也可以指定字符去掉 ''' Python is Python is Python is Python i ''' print(poem.encode()) #将字符串编码成bytes格式,解码为poem1.decode() # b'gently I go as quietly as I came here' print(poem.endswith("re")) #判断字符串是否以 re结尾 # True print("Python is a programming \tlanguage".expandtabs(10)) #将\t转换成10个空格,默认是8个 # Python is a programming language print(poem.find('e')) #查找e,返回第一次找到'e'的索引;如果找不到,返回-1 # 1 #------------------------format格式化输出-------------------------- msg = "{} is a programming language, using {}" print(msg.format("Python",3)) # Python is a programming language, using 3 msg = "{1} is a programming language, using {0}" print(msg.format("Python",3)) # 3 is a programming language, using Python msg = "{name} is a programming language, using {version}" print(msg.format(version=3,name="Python")) #Python is a programming language, using 3 print(msg.format_map({ 'name':'Python','version':3})) #Python is a programming language, using 3 print(poem.index('h')) #返回字符串中第一个字符'h'的索引,如果没有会出现错误 # 33 print('90Ads'.isalnum()) #字符串是否只包含字母或者数字,其他字符会返回False #True print('9'.isdigit()) #字符串是否是只包含数字,如果包括其他字符,小数点,字母则返回False #True print('111'.isnumeric()) #字符串是否只包含数字或者字符串数字 # True print(poem.isprintable()) #是否可打印 print(' '.isspace()) #是否为空格,含有其他字符返回False print(poem.istitle()) #是否为title,即每个单词的首字母是否为大写 print('AA133.'.isupper()) #字符串中字母是否全部为大写,可以包括数字,其他字符等,不能包括小写字母 #True print(poem.split()) #把poem分割成一个list,也可以指定分割符合分割次数,如下,默认分割符为空白符 #['gently', 'I', 'go', 'as', 'quietly', 'as', 'I', 'came', 'here'] print(poem.rsplit(" ",2)) #自右向左分割 # ['gently I go as quietly as I', 'came', 'here'] print("""111111111111 222222222222 3333333333""".splitlines(True)) #按照行分割符分割成一个list,如果为真,每行后会保留分割符 #['111111111111\n', '222222222222\n', '3333333333'] print("-".join(["python","is","a"])) #把["python","is","a"]序列,一个字符一个字符的用“-”串起来 #python-is-a intab = "aeiou" #This is the string having actual characters. outtab = "12345" #This is the string having corresponding mapping character trantab = str.maketrans(intab, outtab) print(poem.translate(trantab)) #g2ntly I g4 1s q532tly 1s I c1m2 h2r2 print("as d".isidentifier()) #检测一段字符串可否被当作标志符,即是否符合变量命名规则 #False print(poem.partition("e")) #如果字符串包含指定的分隔符,则返回一个3元的元组,第一个为分隔符左边的子串,第二个为分隔符本身,第三个为分隔符右边的子串。 #('g', 'e', 'ntly I go as quietly as I came here')
Python编程之字典
访问元素更快,但是需要更多内存,通过key来访问value,所以key是唯一的;
key-value是无序的,区别list;
key是不可变的,数字,字符串,元组都可以作为key,list除外。
可以通过if判断key是否在字典中: if key in dict:
字典的查找、修改、增加、删除等用法。
info = { "stu1" : "Jack", "stu2" : "Bob", "stu3" : "Adam" } print(info) # {'stu1': 'Jack', 'stu2': 'Bob', 'stu3': 'Adam'} #无序的,每次打印顺序会变动 #****************查找 **************************** print(info["stu1"]) #不建议使用这种方式查找,如果所查元素不存在,会出错,Key error print(info.get("stu1")) #查找,如果不存在返回None,安全获取 print("stu2" in info) #如果存在则返回True,判断是否存在;相当于python2.x中的info.has_key('stu2') #True #****************修改 ************************* info["stu3"] = "Mary" #如果存在,则是修改 print(info) #{'stu2': 'Bob', 'stu1': 'Jack', 'stu3': 'Mary'} #***************创建 ************************* info["stu4"] = "Kerry" #如果不存在,则是创建 print(info) #{'stu2': 'Bob', 'stu1': 'Jack', 'stu3': 'Mary', 'stu4': 'Kerry'} #**************删除 ************************** del info["stu1"] # 删除 del print(info) #{'stu2': 'Bob', 'stu3': 'Mary', 'stu4': 'Kerry'} info.pop("stu2") #删除 pop(), 建议使用 print(info) #{'stu3': 'Mary', 'stu4': 'Kerry'} info.popitem() #删除 popitem(), 随机删除,不建议使用 print(info) #{'stu3': 'Mary'}
多级字典嵌套及操作
#***************多级字典嵌套****************** Earth = { "Asia":{ "China" : ["Beijign","Shanghai"], "Japan" : ["Tokyo","Osaka"] }, "Europe":{ "France" : ["Paris","Lyons"], "England":"London" }, "North America":{ "America":["Washington","New York"], "Canada" :"Ottawa" } } print(Earth["Asia"]["China"]) #['Beijign', 'Shanghai'] Earth["Asia"]["India"] = "New Delhi" print(Earth["Asia"]) #{'China': ['Beijign', 'Shanghai'], 'India': 'New Delhi', 'Japan': ['Tokyo', 'Osaka']}
遍历字典
#***************************字典的循环*********************************** info = { "stu1" : "Jack", "stu2" : "Bob", "stu3" : "Adam" } for i in info: #比下面循环高效,通过键值来查找 print(i,info[i]) # stu3 Adam # stu1 Jack # stu2 Bob for k,v in info.items(): print(k,v)
字典的其他用法
#******************* 字典其他用法*************************** info = { "stu1" : "Jack", "stu2" : "Bob", "stu3" : "Adam" } b = { "stu8" : "A", "stu1" : "B" } #******************* values() ******************* print(list(info.values())) #以列表返回字典中的所有值 #['Adam', 'Jack', 'Bob'] #******************* keys() ******************* print(list(info.keys())) #以列表返回字典中的key #['stu1', 'stu3', 'stu2'] #******************* setdefault() ******************* info.setdefault("stu4","Mary") #如果键不存在于字典中,将会添加键并将值设为默认值 print(info) #{'stu3': 'Adam', 'stu2': 'Bob', 'stu4': 'Mary', 'stu1': 'Jack'}
info.setdefault("stu1","Kelly") #如果字典中包含有给定键,则返回该键对应的值,否则返回为该键设置的值 print(info.setdefault("stu1","Kelly") ) #Jack print(info) {'stu3': 'Adam', 'stu2': 'Bob', 'stu4': 'Mary', 'stu1': 'Jack'} #******************* update() ************************* info.update(b) #把字典b中的信息更新到字典info中,区别setdefault print(info) #相当于合并字典,info有的元素就更新,没有的元素就添加 #{'stu3': 'Adam', 'stu8': 'A', 'stu2': 'Bob', 'stu1': 'B'} #******************* items() ************************* 以列表返回可遍历的(键, 值) 元组数组 print(info.items()) #将字典转化为列表,可用list()序列化 #dict_items([('stu8', 'A'), ('stu1', 'B'), ('stu2', 'Bob'), ('stu3', 'Adam')]) #******************* fromkeys() ************************* c = dict.fromkeys([6,7,8],[1,{"name":"Jack"},123]) #创建一个新的字典,(键:值) print(c) #{8: [1, {'name': 'Jack'}, 123], 6: [1, {'name': 'Jack'}, 123], 7: [1, {'name': 'Jack'}, 123]}
c[7][1]["name"] = "Bob" #注意内存中数据的变化,参考深浅copy print(c) #{8: [1, {'name': 'Bob'}, 123], 6: [1, {'name': 'Bob'}, 123], 7: [1, {'name': 'Bob'}, 123]}
集合set
集合是一个无序不重复的序列。可以用来去重,把一个列表变成集合,就自动去重了。关系测试,测试两组数据之前的交集、差集、并集等关系。
l=[1,2,3,4,3,2,5] print(l) # [1, 2, 3, 4, 3, 2, 5] n = set(l) print(n) # {1, 2, 3, 4, 5} #交集 l=set([1,2,3,4]) m=set([3,4,5,6]) print(l.intersection(m)) # {3, 4} # 并集 print(l.union(m)) # {1, 2, 3, 4, 5, 6} # 差集 print(l.difference(m)) # {1, 2} # 子集 print(l.issubset(m)) # False # 对称差集 print(l.symmetric_difference(m)) # {1, 2, 5, 6} # 用于判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。。 print(l.isdisjoint(m)) # False
其他操作
s = set([3,5,9,10]) #创建一个数值集合 t = set("Hello") #创建一个唯一字符的集合 a = t | s # t 和 s的并集 b = t & s # t 和 s的交集 c = t – s # 求差集(项在t中,但不在s中) d = t ^ s # 对称差集(项在t或s中,但不会同时出现在二者中) t.add('x') # 添加一项 s.update([10,37,42]) # 在s中添加多项 使用remove()可以删除一项: t.remove('H') len(s) set 的长度 x in s 测试 x 是否是 s 的成员 x not in s 测试 x 是否不是 s 的成员 s.issubset(t) s <= t 测试是否 s 中的每一个元素都在 t 中 s.issuperset(t) s >= t 测试是否 t 中的每一个元素都在 s 中 s.union(t) s | t 返回一个新的 set 包含 s 和 t 中的每一个元素 s.intersection(t) s & t 返回一个新的 set 包含 s 和 t 中的公共元素 s.difference(t) s - t 返回一个新的 set 包含 s 中有但是 t 中没有的元素 s.symmetric_difference(t) s ^ t 返回一个新的 set 包含 s 和 t 中不重复的元素 s.copy() 返回 set “s”的一个浅复制

 浙公网安备 33010602011771号
浙公网安备 33010602011771号