
hydrogenaudio 编解码标准测试结果
http://listening-tests.hydrogenaudio.org/igorc/results.html
Results of the public multiformat listening test @ 64 kbps (March/April 2011)
These are the summary results of the multiformat listening test @ 64 kbps.
You can download a ZIP file containing all results for all samples.
Encryption keys can be downloaded from here and here.
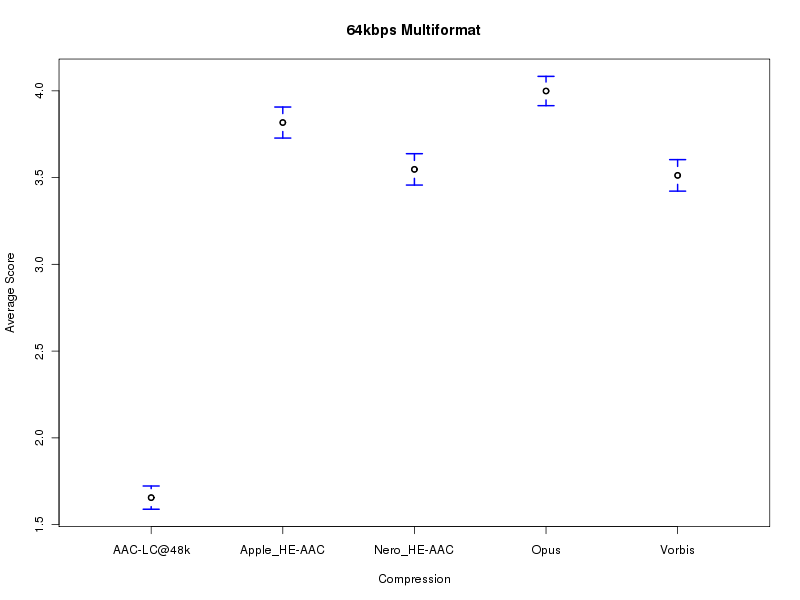
How to interpret the plots: Each plot is drawn with 5 codecs on the X axis and the rating given (1.0 to 5.0) on the Y axis. The 95% confidence intervals are given on each plot. The mean rating given to each codec is indicated by the middle point of each vertical line segment. Each vertical line segment represents the 95% confidence interval (using ANOVA analysis) for each codec. This analysis is identical to the one used in previous listening tests.
One codec can be said to be better than another with greater than 95% confidence if the bottom of its segment is at or above the top of the competing codec's line segment. Note that this is an approximate analysis with some assumptions, and the confidence is far greater in most cases. An almost assumption-free analysis (bootstrap) is below.
Note that CELT is referred to as Opus as this will be the standardized name.
Important note: These plots represent group preferences (for the particular group of people who participated in the test). Individual preferences vary somewhat. The best codec for a person is dependent on his own preferences and the type of music he prefers.
Plot of the complete result (30 samples, 531 results):
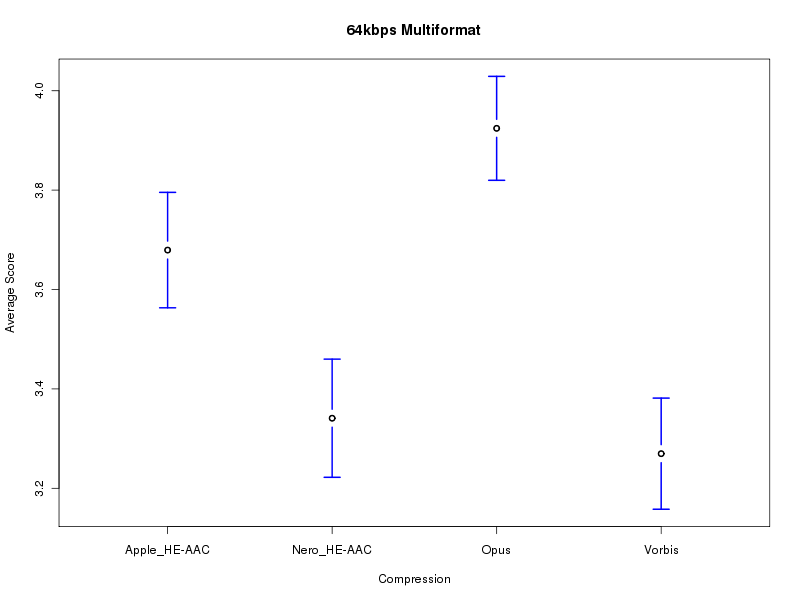
Closeup of the interesting results (30 samples, 531 results):

Per-sample results
A page with graphics for each sample individually is here.
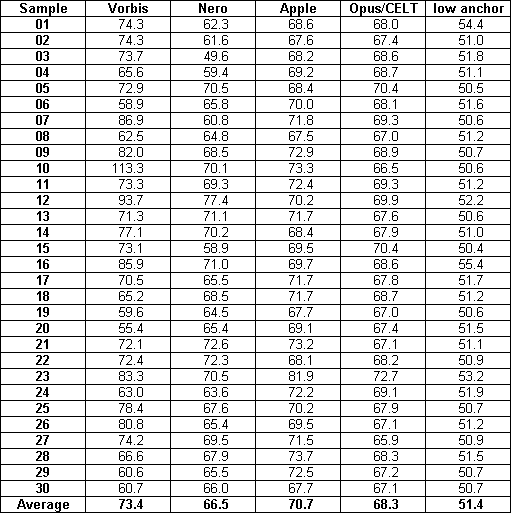
Bitrate table
The codecs and settings were calibrated to provide ~64kbps on a large variety of music.
These are the bitrates used by the codes for the samples in the test:
Bootstrap analysis:
Read 5 treatments, 531 samples => 10 comparisons
Means:
Vorbis Nero_HE-AAC Apple_HE-AAC Opus AAC-LC@48k
3.513 3.547 3.817 3.999 1.656
Unadjusted p-values:
Nero_HE-AAC Apple_HE-AAC Opus AAC-LC@48k
Vorbis 0.488 0.000* 0.000* 0.000*
Nero_HE-AAC - 0.000* 0.000* 0.000*
Apple_HE-AAC - - 0.000* 0.000*
Opus - - - 0.000*
Apple_HE-AAC is better than Vorbis (p=0.000)
Apple_HE-AAC is better than Nero_HE-AAC (p=0.000)
Opus is better than Vorbis (p=0.000)
Opus is better than Nero_HE-AAC (p=0.000)
Opus is better than Apple_HE-AAC (p=0.000)
AAC-LC@48k is worse than Vorbis (p=0.000)
AAC-LC@48k is worse than Nero_HE-AAC (p=0.000)
AAC-LC@48k is worse than Apple_HE-AAC (p=0.000)
AAC-LC@48k is worse than Opus (p=0.000)
p-values adjusted for multiple comparison:
Nero_HE-AAC Apple_HE-AAC Opus AAC-LC@48k
Vorbis 0.490 0.000* 0.000* 0.000*
Nero_HE-AAC - 0.000* 0.000* 0.000*
Apple_HE-AAC - - 0.000* 0.000*
Opus - - - 0.000*
Apple_HE-AAC is better than Vorbis (p=0.000)
Apple_HE-AAC is better than Nero_HE-AAC (p=0.000)
Opus is better than Vorbis (p=0.000)
Opus is better than Nero_HE-AAC (p=0.000)
Opus is better than Apple_HE-AAC (p=0.000)
AAC-LC@48k is worse than Vorbis (p=0.000)
AAC-LC@48k is worse than Nero_HE-AAC (p=0.000)
AAC-LC@48k is worse than Apple_HE-AAC (p=0.000)
AAC-LC@48k is worse than Opus (p=0.000)
ANOVA analysis:
FRIEDMAN version 1.24 (Jan 17, 2002) http://ff123.net/
Blocked ANOVA analysis
Number of listeners: 531
Critical significance: 0.05
Significance of data: 0.00E+00 (highly significant)
---------------------------------------------------------------
ANOVA Table for Randomized Block Designs Using Ratings
Source of Degrees Sum of Mean
variation of Freedom squares Square F p
Total 2654 4521.67
Testers (blocks) 530 1498.18
Codecs eval'd 4 1893.65 473.41 888.29 0.00E+00
Error 2120 1129.85 0.53
---------------------------------------------------------------
Fisher's protected LSD for ANOVA: 0.088
Means:
Opus Apple_HE Nero_HE- Vorbis AAC-LC@4
4.00 3.82 3.55 3.51 1.66
---------------------------- p-value Matrix ---------------------------
Apple_HE Nero_HE- Vorbis AAC-LC@4
Opus 0.000* 0.000* 0.000* 0.000*
Apple_HE 0.000* 0.000* 0.000*
Nero_HE- 0.439 0.000*
Vorbis 0.000*
-----------------------------------------------------------------------
Opus is better than Apple_HE-AAC, Nero_HE-AAC, Vorbis, AAC-LC@48k
Apple_HE-AAC is better than Nero_HE-AAC, Vorbis, AAC-LC@48k
Nero_HE-AAC is better than AAC-LC@48k
Vorbis is better than AAC-LC@48k
Notes:
The graphs are a simple ANOVA analysis over all submitted and valid results. This is compatible with the graphs of previous listening tests, but should only be considered as a visual support for the real analysis.
For a correct calculation of the statistical probability, and to see if one can safely make any conclusions, one has to refer to the bootstrap output. You can see that the results are highly significant for all but one comparison (Vorbis vs. Nero HE-AAC).
When crosschecking against the old friedman/ANOVA utility one can see that the results are almost identical, which is expected as there are many results and the codecs were mostly not transparent, so the results are reasonably normally distributed in this test.
A potential issue is that not every sample was tested by the same amount of listeners, and that notably, the first few samples got more submissions than later ones. Preliminary analsysis (by only including the listeners that tested all samples) shows that this makes no difference to the conclusions.
Post-screening:
Invalid results were discarded according to the following criteria, which were made public at the beginning of the test:
- If the listener ranked the reference worse than 4.5 on a sample, the listener's results for that sample were discarded.
- If the listener ranked the low anchor at 5.0 on a sample, the listener's results for that sample were discarded.
- If the listener ranked the reference below 5.0 on more than 4 samples, all of that listener's results were discarded.
Contact
IgorC: igoruso@gmail.com


{kind=link}