redis分片集群
取消集群
#1.关闭所有的redis服务
redis-cli -c -h 192.168.181.143 -p 6379 shutdown
#2.删除所有的node.conf配置文件
#3.重新启动服务
一.认识
redis三种部署方案:主从复制、哨兵模式、分片集群,其实三种都叫集群部署
不同之处:
- 主从复制:master节点的写操作可以同步到slave节点,但是反过来不行,一旦master节点宕机,如果要写入slave节点数据,将造成数据不一致
- 哨兵模式:基于主从复制加入了哨兵检测,当master宕机,会选举指定的slave节点作为master节点,因为无论是主从复制、还是哨兵模式,都是基于master节点来进行读写(master的数据会同步到slave上,反过来不行),也是为了防止数据丢失,不然的话直接写slave上不就行了?对吧
- 分片集群:和上面两种都不一样,上面的是所有的节点的数据都保持一致,哨兵模式是为了redis的高可用,防止数据丢失。但是分片集群是为了减少一台节点的压力,因此每个节点的数据都不一致,那其中一台节点宕机怎么搞,可以再给每一台节点增加slave啊。。。。
二.安装
1.环境准备
wget http://download.redis.io/releases/redis-6.2.0.tar.gz
准备3台服务器,每一台服务器上部署主从两个redis节点
| IP | PORT | 角色 |
|---|---|---|
| 192.168.181.141 | 6379 | master |
| 192.168.181.141 | 6380 | slave |
| 192.168.181.142 | 6379 | master |
| 192.168.181.142 | 6380 | slave |
| 192.168.181.143 | 6379 | master |
| 192.168.181.143 | 6380 | slave |
2.配置文件
每台机器下在/home目录下创建6379,6380两个文件夹,并都创建redis.conf配置文件
# 守护进行模式启动
daemonize yes
# 关闭保护模式
protected-mode no
# 设置数据库数量,默认数据库为0
databases 16
# 绑定地址,需要修改(其他两台机器分别192.168.181.142,192.168.181.143)
bind 192.168.181.141
# 绑定端口,需要修改(6380文件夹下的改为6380)
port 6379
# pid文件存储位置,文件名需要修改(6380文件夹下的改为6380)
pidfile /home/redis-6.2.0/6379/redis_6379.pid
# log文件存储位置,文件名需要修改(6380文件夹下的改为6380)
logfile /home/redis-6.2.0/6379/redis_6379.log
# RDB快照备份文件名,文件名需要修改(6380文件夹下的改为6380)
dbfilename redis_6379.rdb
# 本地数据库存储目录,需要修改(6380文件夹下的改为6380)
dir /home/redis-6.2.0/6379
# 集群相关配置
# 是否以集群模式启动
cluster-enabled yes
# 集群节点回应最长时间,超过该时间被认为下线
cluster-node-timeout 15000
# 生成的集群节点配置文件名,这个和redis.conf不是一回事,文件名需要修改(6380文件夹下的改为6380)
cluster-config-file /home/redis-6.2.0/6379/node.conf
3.启动
每台机器操作
$ redis-server /home/redis-6.2.0/6379/redis.cnf
$ redis-server /home/redis-6.2.0/6380/redis.cnf
通过ps查询状态:ps -ef|grep redis

4.创建集群
虽然服务启动了,但是目前每个服务之间都是独立的,没有任何关联。
我们需要执行命令来创建集群,在Redis5.0之前创建集群比较麻烦,5.0之后集群管理命令都集成到了redis-cli中。
1)Redis5.0之前
Redis5.0之前集群命令都是用redis安装包下的src/redis-trib.rb来实现的。因为redis-trib.rb是有ruby语言编写的所以需要安装ruby环境。
# 安装依赖
yum -y install zlib ruby rubygems
gem install redis
然后通过命令来管理集群
# 进入redis的src目录
cd /tmp/redis-6.2.4/src
# 创建集群
./redis-trib.rb create --replicas 1 192.168.150.101:7001 192.168.150.101:7002 192.168.150.101:7003 192.168.150.101:8001 192.168.150.101:8002 192.168.150.101:8003
2)Redis5.0以后
我们使用的是Redis7.0.5版本,集群管理以及集成到了redis-cli中,格式如下,在其中一台机器上执行就可以(网上说总数/(replicas+1)是master数,前n个是master,但是实验得出结果不是,此处仍然需要查证):
暂实验得出结论(这种创建方式是随机选取,不能指定哪台副本的master节点):
- 如果是三台机器,6节点,create命令会根据ip来决定每台机器上都会有一个master,而不是根据ip列表来确定前三台机器是master。
- 如果是6台机器,6节点,会选择前3台作为master节点
redis-cli --cluster create 192.168.181.141:6379 192.168.181.141:6380 192.168.181.142:6379 192.168.181.142:6380 192.168.181.143:6379 192.168.181.143:6380 --cluster-replicas 1
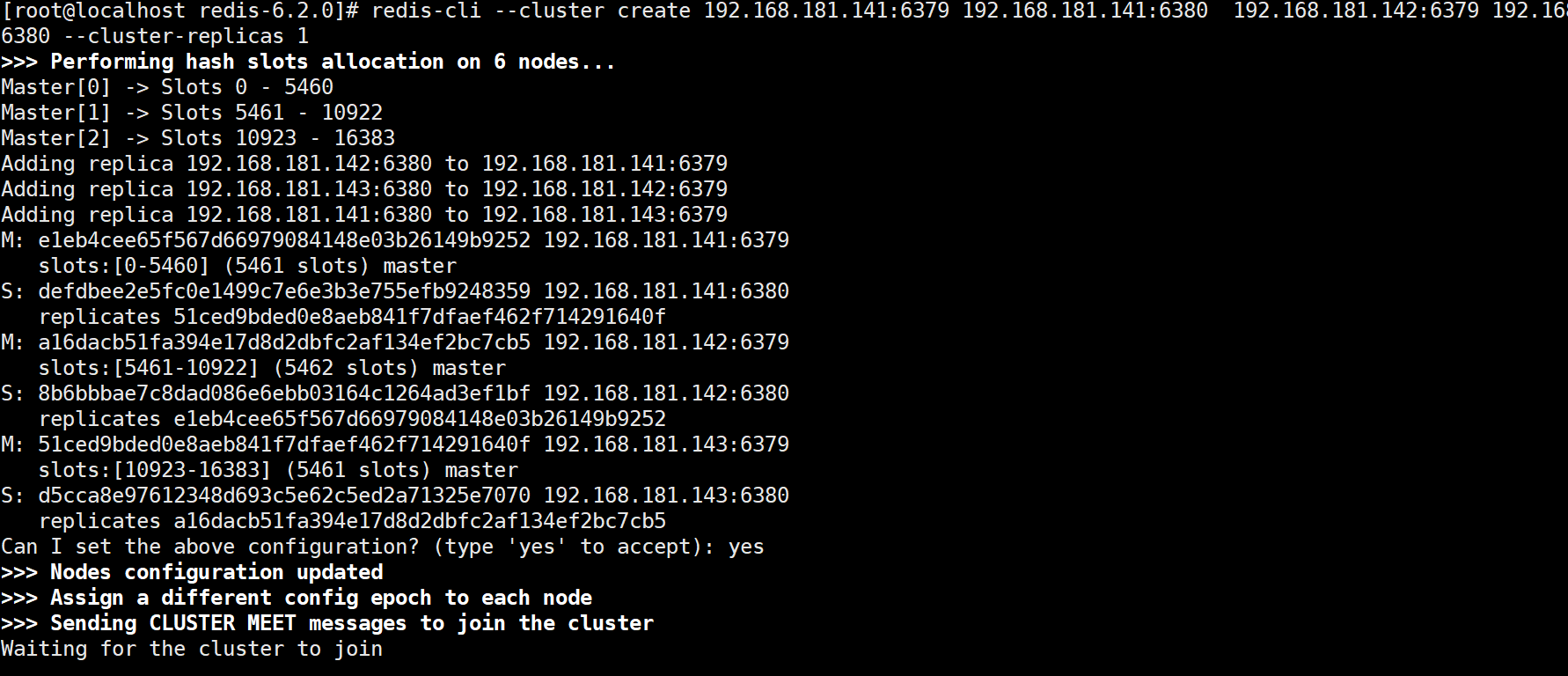
当已经创建好集群再次创建时会报错,此时如果需要重新创建,就需要先停掉redis所有服务,然后删除配置文件中cluster-config-file对应的文件,最后重新创建即可

5.通过命令查看集群状态
redis-cli -h master -p 6379
#查看集群状态
CLUSTER INFO
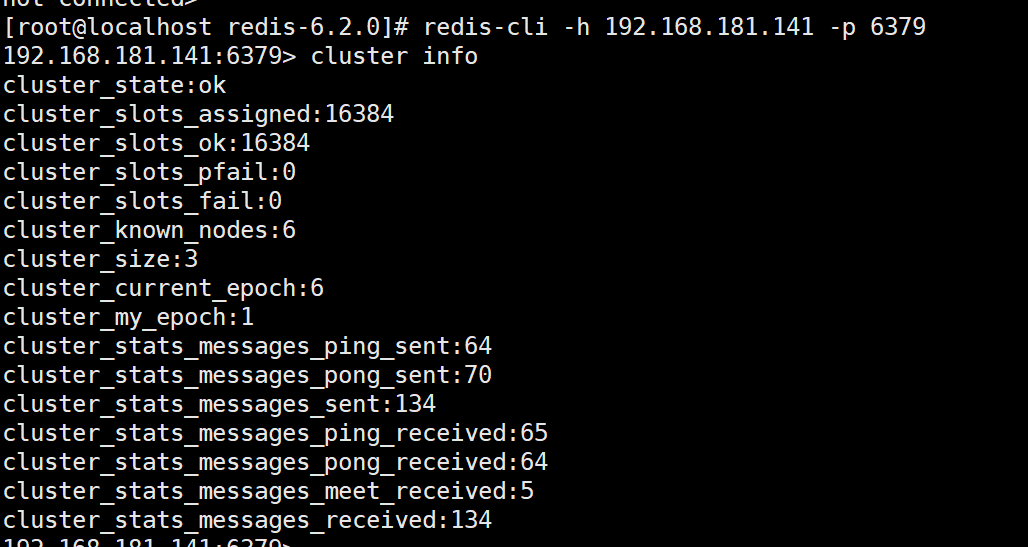
查看节点信息
CLUSTER nodes

6.验证分片集群
随便进入一台机器执行命令redis-cli -h 192.168.181.143 -p 6379 -c,注意此处加上-c参数才是在集群中操作,不然只是针对于192.168.181.143操作
可以看到如下图所示,当有读写操作时,redis集群会根据算法重定向到指定的节点上进行读写操作。这样带来的好处是可以外部配置keepalived配置,这样无论哪台机器宕机,使用命令进入,都会根据算法自动调节。

三.其他命令
查看帮助,参考连接:https://www.cnblogs.com/zhoujinyi/p/11606935.html
redis-cli --cluster help
Cluster Manager Commands:
create host1:port1 ... hostN:portN #创建集群
--cluster-replicas <arg> #从节点个数
check host:port #检查集群
--cluster-search-multiple-owners #检查是否有槽同时被分配给了多个节点
info host:port #查看集群状态
fix host:port #修复集群
--cluster-search-multiple-owners #修复槽的重复分配问题
reshard host:port #指定集群的任意一节点进行迁移slot,重新分slots
--cluster-from <arg> #需要从哪些源节点上迁移slot,可从多个源节点完成迁移,以逗号隔开,传递的是节点的node id,还可以直接传递--from all,这样源节点就是集群的所有节点,不传递该参数的话,则会在迁移过程中提示用户输入
--cluster-to <arg> #slot需要迁移的目的节点的node id,目的节点只能填写一个,不传递该参数的话,则会在迁移过程中提示用户输入
--cluster-slots <arg> #需要迁移的slot数量,不传递该参数的话,则会在迁移过程中提示用户输入。
--cluster-yes #指定迁移时的确认输入
--cluster-timeout <arg> #设置migrate命令的超时时间
--cluster-pipeline <arg> #定义cluster getkeysinslot命令一次取出的key数量,不传的话使用默认值为10
--cluster-replace #是否直接replace到目标节点
rebalance host:port #指定集群的任意一节点进行平衡集群节点slot数量
--cluster-weight <node1=w1...nodeN=wN> #指定集群节点的权重
--cluster-use-empty-masters #设置可以让没有分配slot的主节点参与,默认不允许
--cluster-timeout <arg> #设置migrate命令的超时时间
--cluster-simulate #模拟rebalance操作,不会真正执行迁移操作
--cluster-pipeline <arg> #定义cluster getkeysinslot命令一次取出的key数量,默认值为10
--cluster-threshold <arg> #迁移的slot阈值超过threshold,执行rebalance操作
--cluster-replace #是否直接replace到目标节点
add-node new_host:new_port existing_host:existing_port #添加节点,把新节点加入到指定的集群,默认添加主节点
--cluster-slave #新节点作为从节点,默认随机一个主节点
--cluster-master-id <arg> #给新节点指定主节点
del-node host:port node_id #删除给定的一个节点,成功后关闭该节点服务
call host:port command arg arg .. arg #在集群的所有节点执行相关命令
set-timeout host:port milliseconds #设置cluster-node-timeout
import host:port #将外部redis数据导入集群
--cluster-from <arg> #将指定实例的数据导入到集群
--cluster-copy #migrate时指定copy
--cluster-replace #migrate时指定replace
help
1.检查集群slot分配情况
redis-cli --cluster check 192.168.181.155:6379
如果没有集群,或没有加入集群得到如下图:
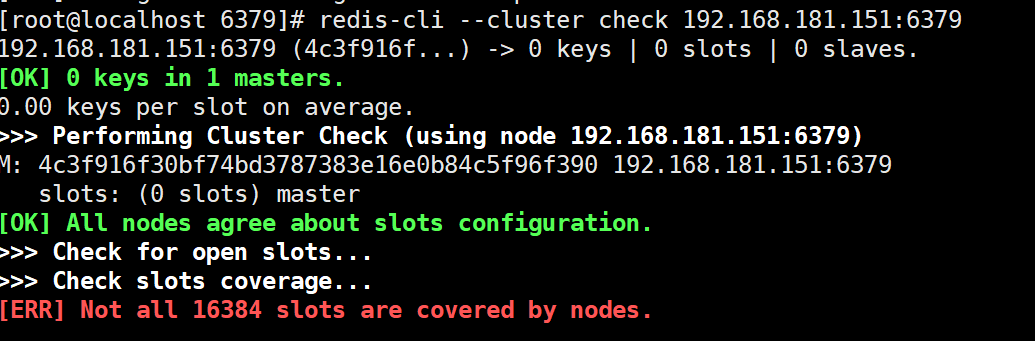
已有集群,得到下图:

2.检查集群状态
redis-cli --cluster info 192.168.181.156:6379

已有集群得到下图:

3.创建master节点
#创建151-153为master节点3
redis-cli --cluster create 192.168.181.151:6379 192.168.181.152:6379 192.168.181.153:6379`
4.创建主从节点
#如果是三台机器,6节点,create命令会根据ip来决定每台机器上都会有一个master,而不是根据ip列表来确定前三台机器是master。
#如果是6台机器,6节点,会选择前3台作为master节点
redis-cli --cluster create 192.168.181.151:6379 192.168.181.152:6379 192.168.181.153:6379 192.168.181.151:6380 192.168.181.152:6380 192.168.181.153:6380 --cluster-replicas 1
注意:3和4不能同时使用,当使用了3,再用4,会报错

5.添加master节点
#新节点在前,集群中任一节点在后
redis-cli --cluster add-node 192.168.181.154:6379 192.168.181.153:6379
添加完之后可通过check命令查看得到新节点slots数量为0,需要给其分配slots(将老master节点的槽位分出来点给新master),依据11操作,或者基于redis-cli --cluster rebalance 192.168.181.153:6379重新平衡节点slots(默认不给新master分配slots,需要参考参数)
6.添加从节点
该命令可指定从节点的master节点,平常创建集群时:(3或5)+6,4是单独使用但是不能指定从节点的master节点
#新的从节点在前,集群中任一节点在后,需要指定cluster-master-id,可使用check命令查看
redis-cli --cluster add-node 192.168.181.152:6380 192.168.181.152:6379 --cluster-slave --cluster-master-id 4c3f916f30bf74bd3787383e16e0b84c5f96f390
7.删除节点
当被删除掉的节点重新起来之后不能自动加入集群,但其和主的复制还是正常的,也可以通过该节点看到集群信息(通过其他正常节点已经看不到该被del-node节点的信息)
redis-cli --cluster del-node 192.168.181.151:6380 061c4d9d6fc95917e1e6ef14a0ca577f7d853adf
以上命令删除从节点可直接使用,但是要删除master节点,先要把对应master节点的slots移走,先check查询有多少slots,然后采用11即可。
8.修复集群
redis-cli --cluster fix 192.168.181.151:6380 --cluster-search-multiple-owners
9.设置集群的超时时间
redis-cli --cluster set-timeout 192.168.181.151:6380 10000
10.集群中执行相关命令
说明:连接到集群的任意一节点来对整个集群的所有节点进行设置
call .. config ..
redis-cli --cluster call 192.168.163.132:6381 config set requirepass pwd
redis-cli -a pwd --cluster call 192.168.163.132:6381 config set masterauth cc
redis-cli -a pwd --cluster call 192.168.163.132:6381 config rewrite
redis6.0后新增
1,fix 的子命令:--cluster-fix-with-unreachable-masters
2,call的子命令:--cluster-only-masters、--cluster-only-replicas
11.给新master节点分配slots
#redis-cli --cluster reshard 集群任一节点 --cluster-from 老nodeid --cluster-to 新nodeid --cluster-slots slots数量
redis-cli --cluster reshard 192.168.181.151:6379 --cluster-from 12e72eaa07f804c2a8eaa7fbd27bc915c5f240b0 --cluster-to 0257c675f1fe9a12bf5ea43612bce4fbd977073f --cluster-slots 2000
四.集群迁移
参考:https://www.cnblogs.com/zhoujinyi/p/11606935.html
五.k8s部署redis集群
参考:https://www.cnblogs.com/xmwan/archive/2022/09/22/16718221.html
k8s部署redis集群和真机部署的几点不同:
1.真机一般需要3台机器及以上数量,k8s不需要,因为每个pod的ip不一样
2.按照上述文档部署好k8s的redis集群后,外界无法访问且本机中其他pod访问只能通过pod名称.无头svc名称.命名空间.svc.cluster.local一个pod一个pod访问,因为无头svc没有负载均衡,如果要外界访问或者负载均衡需要重建有头svc
理解注意点:
-
redis.conf中的路径都是在pod中的,因此redis-sts.yaml中的redis-data是基于volumeClaimTemplates使用了pv挂载,将pv对应的存储挂载到pod的/var/lib上
appendonly yes cluster-enabled yes cluster-config-file /var/lib/redis/nodes.conf cluster-node-timeout 5000 dir /var/lib/redis port 6379redis-sts.yaml
apiVersion: apps/v1 kind: StatefulSet #StatefulSet类型 metadata: name: redis-app #StatefulSet名称 namespace: my-ns-redis #使用的命名空间 spec: serviceName: "redis-service" #引用上面创建的headless service,名字必须一致 replicas: 6 #副本数 selector: #标签选择器 matchLabels: app: redis #选择redis标签 appCluster: redis-cluster template: #容器模板 metadata: labels: app: redis #容器标签:redis appCluster: redis-cluster spec: containers: - name: redis #容器名字 image: "redis:7.0.4" #使用的镜像 command: ["/bin/bash", "-ce", "tail -f /dev/null"] command: ["redis-server"] args: - "/etc/redis/redis.conf" - "--protected-mode" - "no" ports: - name: redis containerPort: 6379 protocol: "TCP" - name: cluster containerPort: 16379 protocol: "TCP" volumeMounts: #挂载卷 - name: "redis-conf" #自定义挂载卷1的名称 mountPath: "/etc/redis" #挂载的路径,这个是redis容器里面的路径 - name: "redis-data" mountPath: "/var/lib/redis" volumes: - name: "redis-conf" #引用挂载,名字要和上面自定义的一致,否则无法对应挂载 configMap: #使用的存储类型 name: "redis-conf" #引用之前创建的configMap存储,名字要和之前创建使用的名字一致 items: #可以不写 - key: "redis.conf" path: "redis.conf" #这个就表示mountPath: "/etc/redis"+path: "redis.conf" ,最终:/etc/redis/redis.conf volumeClaimTemplates: #创建pvc的模板,我们没有单独创建pvc,直接使用模板创建 - metadata: name: redis-data #引用上面自定义的挂载卷2的名称,必须一致 spec: #元数据 accessModes: [ "ReadWriteMany" ] #必须和前面创建的pv的保持一致,否则pv,pvc可能绑定失败 storageClassName: "redis" #必须和前面创建的pv的保持一致 -
按照以上配置完成之后,只是使用了headless服务,因此没有负载均衡,如果想内部其他资源能够访问到,需要添加cluster服务
apiVersion: v1 kind: Service metadata: name: redis-access-service namespace: my-ns-redis #需要跟redis的pod在同一namespace下 labels: app: redis spec: ports: - name: redis-port protocol: "TCP" port: 6379 targetPort: 6379 selector: app: redis appCluster: redis-cluster
通过10.103.33.228访问即可访问到redis集群,也可添加nodeport用来外界访问

 浙公网安备 33010602011771号
浙公网安备 33010602011771号