容器监控
docker容器监控分为两部分:
-宿主机的资源:剩余内存,磁盘空间,cpu负载
-容器资源:每个容器使用的cpu,内存,磁盘
zabbix监控(基于命令行取值,命令行能够得到数据,zabbix也能获取到)
zabbix和prometheus区别:zabbix更适用于linux系统,pr更适合容器
在了解prometheus(普罗米修斯)之前,我们先了解下zabbix。
1.zabbix简介
参考: https://baijiahao.baidu.com/s?id=1689945188583938997&wfr=spider&for=pc
zabbix是开源的分布式监控系统,支持多种采集方式和采集客户端, 同时支持 SNMP、IPMI、JMX、Telnet、SSH 等多种协议,它将采集到的数据存放到数据库中,然后对其进行分析整理,如果符合告警规则,则触发相应的告警。
核心组件:Agent和Server。Agent主要负责采集数据并将数据发送到server/proxy,除此之外,为扩展监控项,agent还支持执行自定义脚本,Server主要负责接受agent发送的监控信息,并进行汇总、触发告警等。
zabbix使用关系型数据存储时序数据,因此在大规模集群监控时常常在数据存储方面方面捉襟见肘。
2.prometheus
2.1 优缺点
1.提供多维度数据模型和灵活的查询方式,通过将监控指标关联多个 tag,来将监控数据进行任意维度的组合,并且提供简单的 PromQL 查询方式,还提供 HTTP 查询接口,可以很方便地结合 Grafana 等 GUI 组件展示数据。
2.在不依赖外部存储的情况下,支持服务器节点的本地存储,通过 Prometheus 自带的时序数据库,可以完成每秒千万级的数据存储;不仅如此,在保存大量历史数据的场景中,Prometheus 可以对接第三方时序数据库和 OpenTSDB 等。
3.定义了开放指标数据标准,以基于 HTTP 的 Pull 方式采集时序数据,只有实现了 Prometheus 监控数据才可以被 Prometheus 采集、汇总、并支持 Push 方式向中间网关推送时序列数据,能更加灵活地应对多种监控场景。
4.支持通过静态文件配置和动态发现机制发现监控对象,自动完成数据采集。Prometheus 目前已经支持 Kubernetes、etcd、Consul 等多种服务发现机制。
5.易于维护,可以通过二进制文件直接启动,并且提供了容器化部署镜像。
6.支持数据的分区采样和联邦部署,支持大规模集群监控。
2.2 主要组件
-
prometheus Server(核心部分)
prometheus server本身就是一个时序数据库,负责对监控数据的获取、存储和查询。 提供了自定义的promql语言,实现对数据的查询以及分析 -
推送网关(push gateway)
主要是实现接收由 Client push 过来的指标数据,在指定的时间间隔,由主程序来抓取。其实就是将exporter采集到的数据推送给prometheus server -
Exporter
主要用来采集数据,并通过HTTP服务的形式暴露给prometheus Server,prometheus Server通过访问该Exporter提供的接口,来获取到需要采集的监控数据
-
告警管理(Alertmananager)
主要负责实现报警功能,在prometheus Server 中支持基于promQL创建告警规则,如果满足定义的规则,则产生一条告警信息
2.3 架构
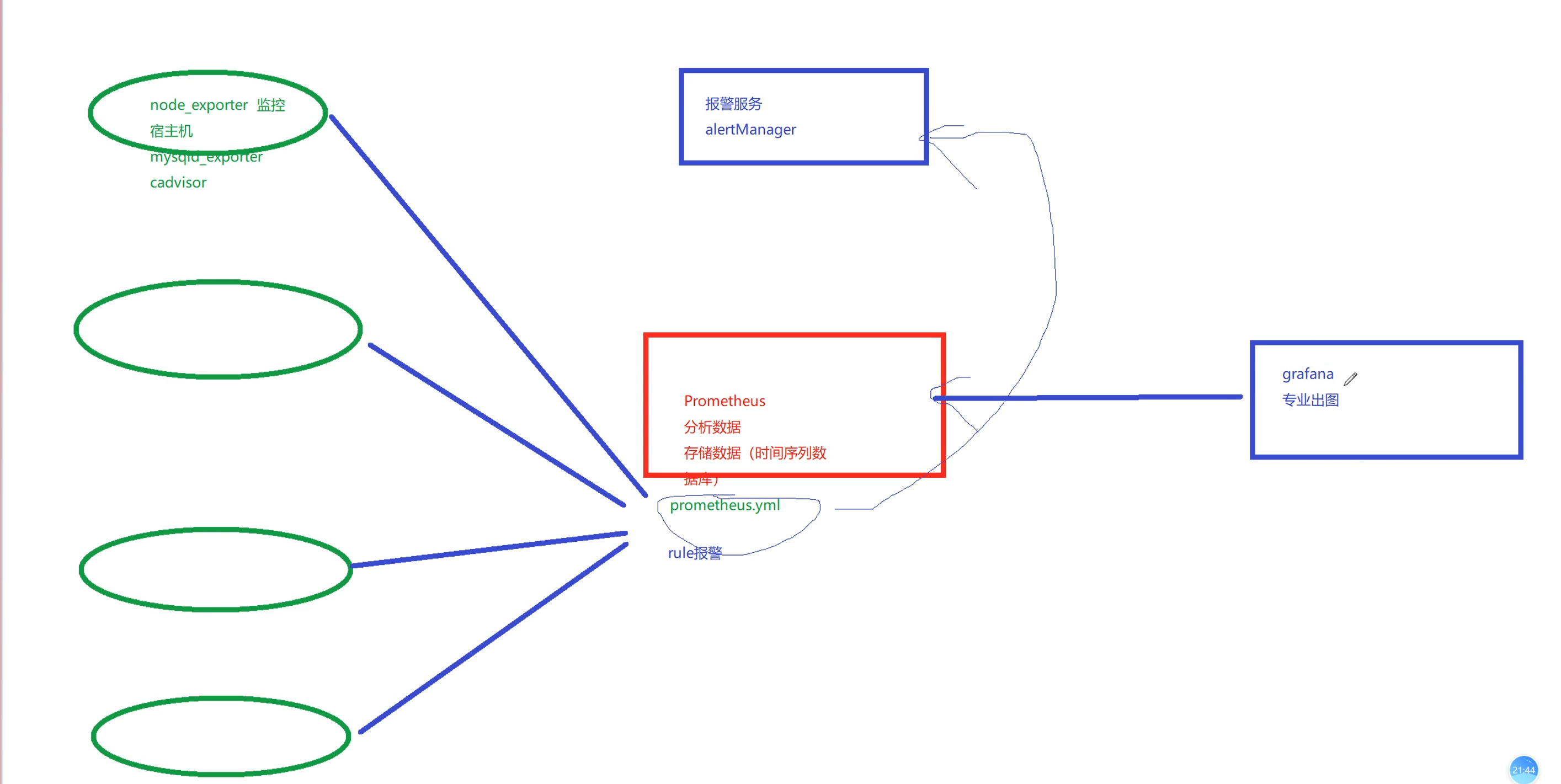
我们需要在每一台要监控的服务器上安装采集软件(node_exporter、mysql_exporter等),每安装一台监控服务器都需要在Prometheus主服务上yaml文件中配置对应的ip和监控节点安装的服务,然后Prometheus主服务会从监控节点上取数据,做分析,然后根据自身rule来判断是否报警。因为Prometheus自身图形界面很烂,因此常搭配grafana(专业出图软件)来出图。
它针对大规模的集群环境设计了拉取式的数据采集方式,只需要在应用里面实现一个metrics接口,然后把这个接口告诉Prometheus就可以完成数据采集了
2.4 和influxdb区别
influxdb仅仅是一个数据库,它被动的接受客户的数据插入和查询请求。而后者是完整的监控系统,能抓取数据、查询数据、报警等功能
2.5 安装
prometheus安装: https://www.jianshu.com/p/8c898785c8ca,安装完或修改完yml文件可使用命令./promtool check config ./prometheus.yml检查配置文件是否正确
granafa国内元: https://mirrors.huaweicloud.com/grafana/
2.6 nginx监控nginx-vts-exporter
两种监控方案: nginx-lua-prometheus和nginx-vts-exporter
这里使用第二种,部署参考:https://blog.csdn.net/qq_32502263/article/details/109766259
1.nginx-module-vts
在nginx.conf用来实时出json数据,文件配置如下:
http {
vhost_traffic_status_zone; #http下开启vhost过滤
server {
listen 8088;
location /status {
vhost_traffic_status_display; #添加此两句
vhost_traffic_status_display_format html;
}
}
2.nginx-vts-exporter
默认端口9913,用来获取nginx-module-vts的json格式数据,可使用http://xx:9913/metrics来访问
2.7 blackbox_exporter
2.7.1 配置
blackbox_exporter是Prometheus 官方提供的 exporter ,可以提供 http、dns、tcp、icmp 的监控数据采集。
配置参考:https://www.cnblogs.com/xiao987334176/p/12022482.html
配置完加入systemcl管理
[Unit]
Description=blackbox_exporter
After=network.target
[Service]
Type=simple
User=root
Group=root
# 启动命令
ExecStart=/usr/local/blackbox_exporter/blackbox_exporter \
--config.file=/usr/local/blackbox_exporter/blackbox.yml \
--web.listen-address=:9115
Restart=on-failure
[Install]
WantedBy=multi-user.target
执行命令systemctl daemon-reload 使新服务配置文件生效,然后systemctl start blackxx
prometheus.yml中加入配置如下(监听服务端口)配置完重启prometheus,再次访问会出现如下图

2.7.2 访问prometheus查看
访问http://192.168.181.141:9090/,发现3个端口都是up状态,

2.7.3 访问blackbox_exporter服务
访问http://192.168.181.141:9115/,blackbox_exporter默认9115端口,出现如下图日志:
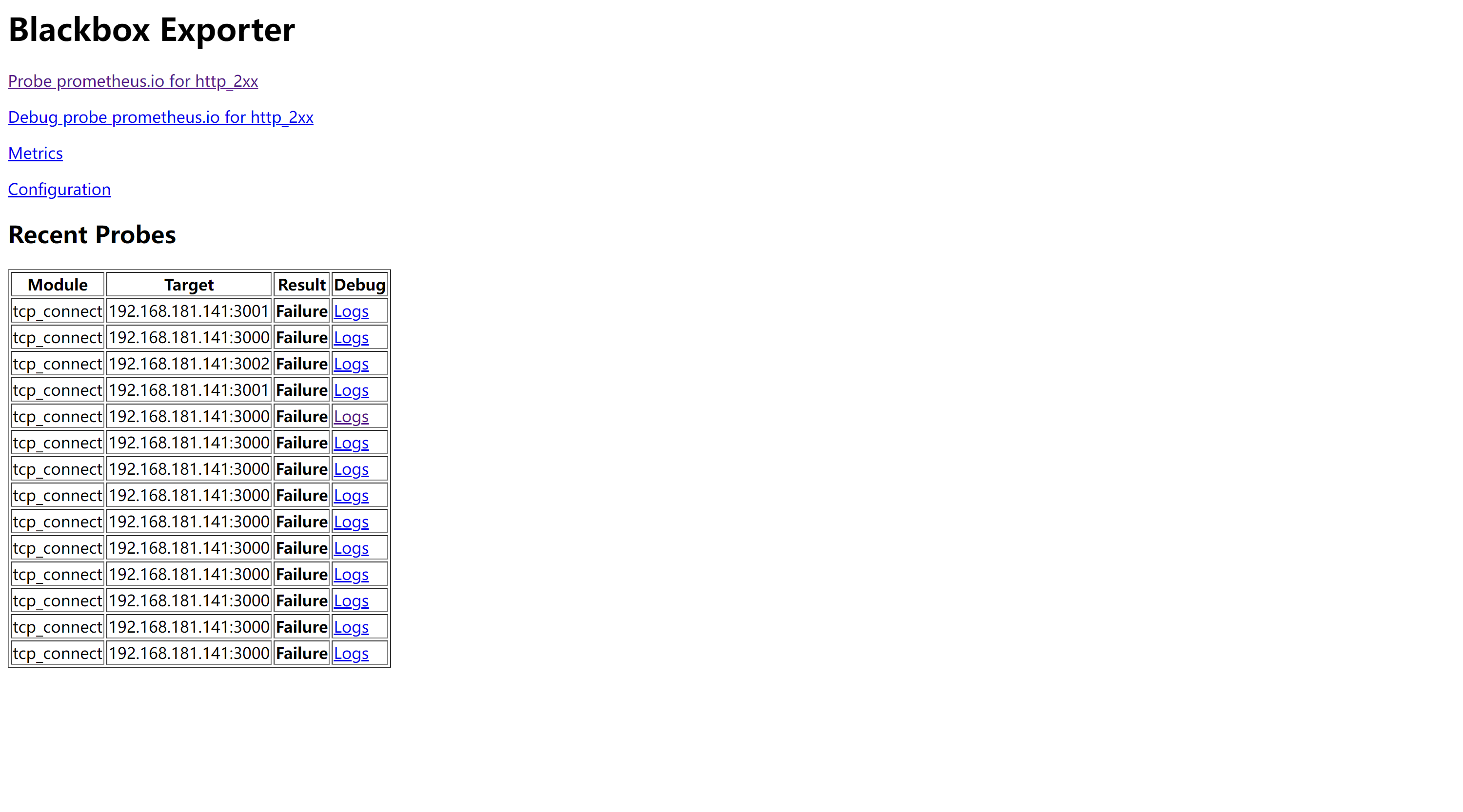
注意:当停掉3000、3001、3002服务,访问9090端口是不会发生变化的,因为监听的是9115端口,9115的blackbox_exporter监听的才是3000服务
2.7.4grafana配置
1.启动grafana:docker run -d -p3000:30000 grafana/grafana
2.进入grafana引入模板9965
3.下载grafana-piechart-panel:docker exec -it grafana容器id grafana-cli plugins install grafana-piechart-panel并重启dockerdocker restart grafana容器id
4.再次访问grafana,得到如下图结果,如果要告警,需配置rules

2.8 prometheus告警:
部署参考:https://blog.csdn.net/u012599988/article/details/102898282
参数注意: https://blog.csdn.net/weixin_38645718/article/details/103040647
#alert的三种状态
1. pending:警报被激活,但是低于配置的持续时间。这里的持续时间即rule里的FOR字段设置的时间。改状态下不发送报警。
2. firing:警报已被激活,而且超出设置的持续时间。该状态下发送报警。
3. inactive:既不是pending也不是firing的时候状态变为inactive
prometheus触发一条告警的过程:
prometheus--->触发阈值--->超出持续时间--->alertmanager--->分组|抑制|静默--->媒体类型--->邮件|钉钉|微信等。
如果单单只是配置监控,只需要在prometheus.yml文件scrape_configs下配置即可,如果要加上告警,需要在rule_files下面配置(所有的监控节点都会按照rule_files来进行告警),配置完之后重启prometheus,在rules和Alerts中会看到相应的信息,在配置告警之前这两部分是空的
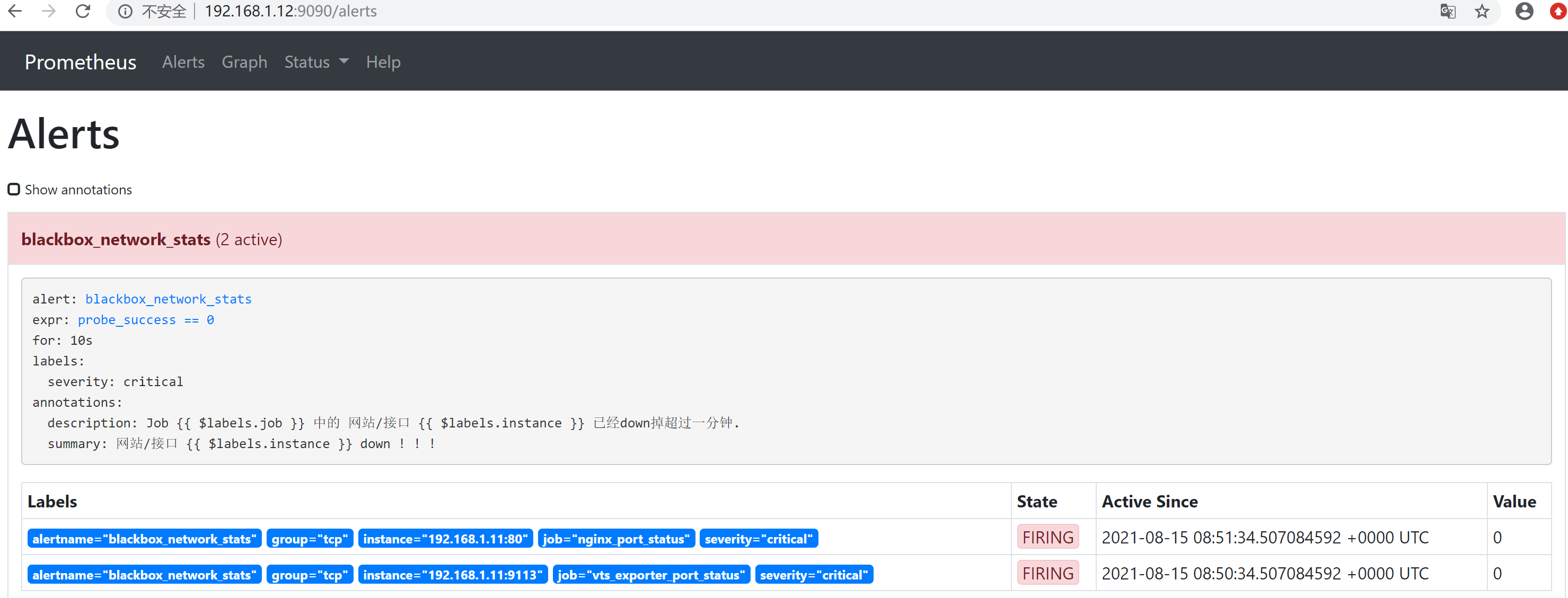
#当前路径下alerting/black.yml
groups:
- name: blackbox_network_stats #组名
rules:
- alert: blackbox_network_stats #同一组的名称不能重复
expr: probe_success == 0
for: 10s #如1分钟内持续为0 报警
labels:
severity: critical
annotations:
description: 'Job {{ $labels.job }} 中的 网站/接口 {{ $labels.instance }} 已经down掉超过一分钟.'
summary: '网站/接口 {{ $labels.instance }} down ! ! !'
如果要发送邮件、钉钉、webhook,就需要用到Alertmanager插件,这是一个独立的告警模块,接受promethues等客户端(上述rules文件夹下面的配置文件)发来的告警信息,然后通过分组、删除重复等处理,最后发送警告信息
https://www.cnblogs.com/gschain/p/11697200.html
alertmanager.yml 配置如下
global:
resolve_timeout: 1m
smtp_smarthost: 'smtp.163.com:25'
smtp_from: 'a17320180454@163.com'
smtp_auth_username: 'a17320180454@163.com'
smtp_auth_password: 'QMABWVAUUQXCLYGT'
smtp_hello: 'office365.com'
smtp_require_tls: false
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 1m
repeat_interval: 1m
receiver: default
routes:
- receiver: email
group_wait: 10s
receivers:
- name: 'default'
email_configs:
- to: '1151048226@qq.com'
send_resolved: true
- name: 'email'
email_configs:
- to: '1151048226@qq.com'
send_resolved: true
2.9 配置文件简介
# my global config
global:
scrape_interval: 15s #proemtheus抓取信息时间间隔
evaluation_interval: 15s #每隔多长时间计算一次rules,并发送给alertmanagers
alerting: #此处用到单独Alertmanager插件,默认启动端口9093,告警的信息会发送给这个插件
alertmanagers:
- static_configs:
- targets:
#- 192.168.1.12:9093
rule_files: #配置rules之后,在rules和Alerts中会看到对应的状态
- "alerting/*.yml"
scrape_configs: #监控节点配置(会在http://192.168.1.12:9090/targets中显示)
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
3.k8s监控
cadvisor是集成于k8s的agent之中的,负责监控容器资源,和prometheus官网提供的exporter是同一作用,k8s要实现kubectl top node命令需要先安装metrics服务,负责收集cadvisor中的数据,而prometheus自身集成的有metrics服务,会自动拉取exporter的数据,然后存入本身自带库
-
cadvisor+heapster/metrics+influxdb+dashboard
缺点:只能支持监控容器资源,无法支持业务监控,扩展性较差
-
cadvisor/exporter+prometheus+grafana
总体流程: 数据采集–>汇总–>处理–>存储–>展示
容器监控:
1.prometheus使用cadvisor采集容器监控指标,cadvisor集成在k8s的kubelet中-通过prometheus进程存储-使用grafana进行展现 2.node的监控-通过node_pxporter采集当前主机的资源-通过prometheus进程存储-使用grafana进行展现 3.master的监控-通过kube-state-metrics插件从k8s中获取到apiserver的相关数据-通过prometheus进程存储-使用grafana进行展现2.2 Prometheus+Grafana的监控部署
部署之前工作:
-
安装好metrics-sever服务
-
同步windows和linux时间(每台机器)
yum install -y ntpdate sudo ntpdate time.windows.com sudo hwclock --localtime --systohc
2.2.1 master/node节点环境部署
- 在master可以进行安装部署
安装git,并下载相关yaml文件
git clone https://github.com/redhatxl/k8s-prometheus-grafana.git- 在node节点下载监控所需镜像
docker pull prom/node-exporter docker pull prom/prometheus:v2.0.0 docker pull grafana/grafana:4.2.02.2.2 采用daemonset方式部署node-exporter组件
kubectl create -f node-exporter.yaml添加标注如下:
annotations: prometheus.io/scrape: 'true' prometheus.io/port: '9100' prometheus.io/path: '/metrics'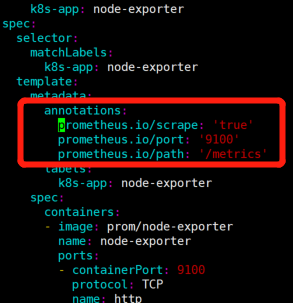
2.2.3 部署prometheus组件
2.2.3.1 rbac文件
kubectl create -f k8s-prometheus-grafana/prometheus/rbac-setup.yaml2.2.3.2 以configmap的形式管理prometheus组件的配置文件
kubectl create -f k8s-prometheus-grafana/prometheus/configmap.yaml2.2.3.3 Prometheus deployment 文件
kubectl create -f k8s-prometheus-grafana/prometheus/prometheus.deploy.yml2.2.3.4 Prometheus service文件
kubectl create -f k8s-prometheus-grafana/prometheus/prometheus.svc.yml2.2.4 部署grafana组件
2.2.4.1 grafana deployment配置文件
kubectl create -f k8s-prometheus-grafana/grafana/grafana-deploy.yaml2.2.4.2 grafana service配置文件
kubectl create -f k8s-prometheus-grafana/grafana/grafana-svc.yaml2.2.4.3 grafana ingress配置文件
登录后复制
kubectl create -f k8s-prometheus-grafana/grafana/grafana-ing.yaml安装完成之后操作:
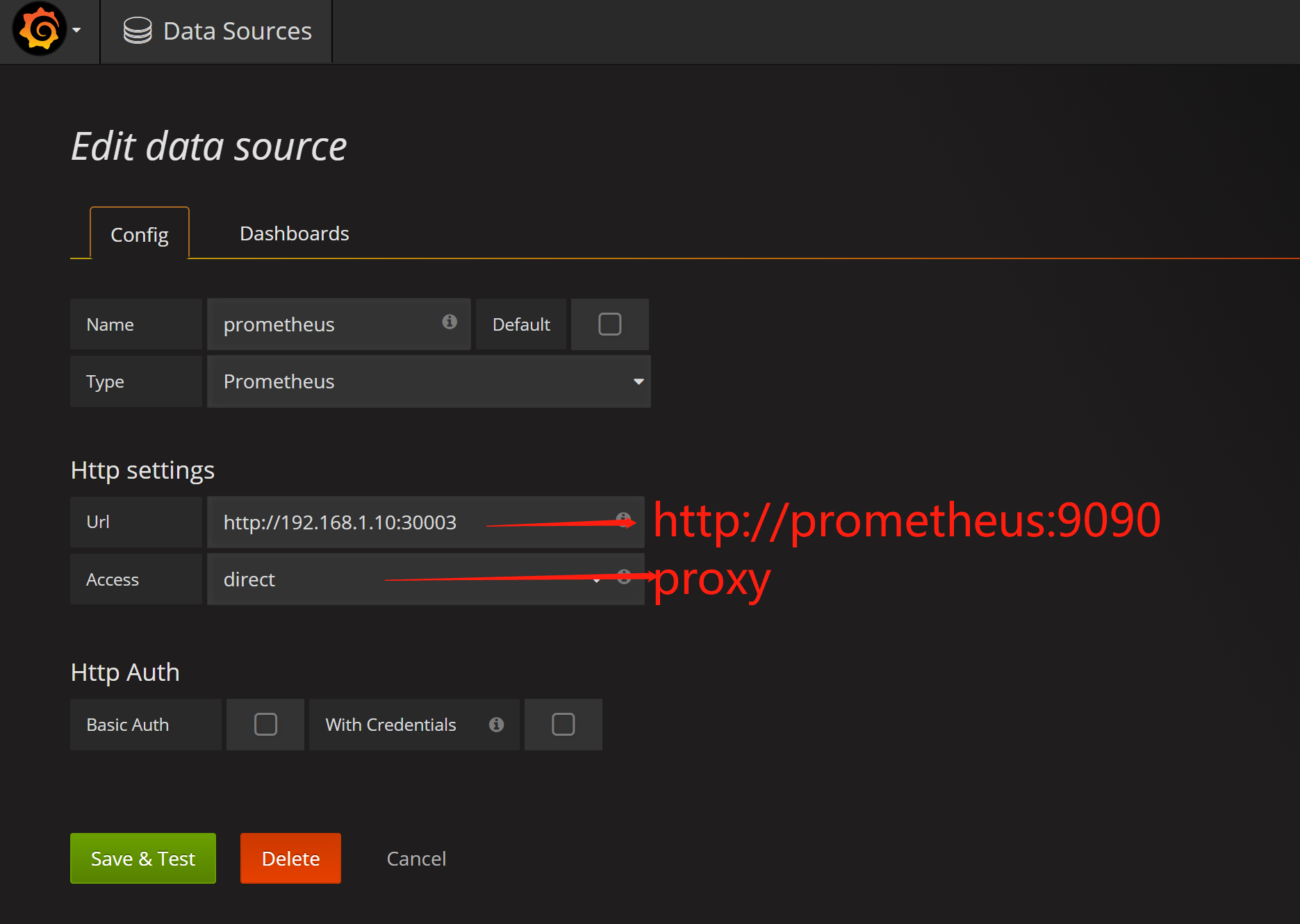
配置grafana:
1.data sources添加(url和access可替换)
2.添加dashboard(默认的可能无法显示数据),输入315编号即可。
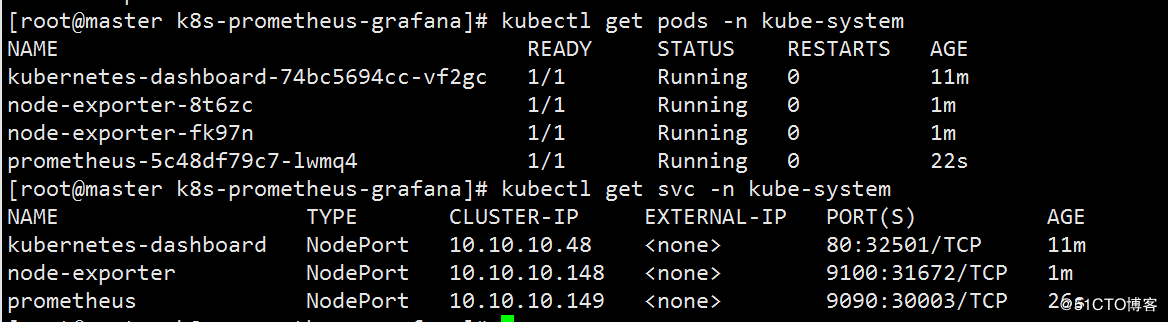
- 查看node-exporter,192.168.1.10:31672端口
- 查看prometheus,192.168.1.10:30003端口
- 查看granfa,192.168.1.10:32501端口
-
4.promethues数据持久化
数据持久化分为本地存储和远端存储。
本地存储非常简单,只用命令行启动参数即可( —storage.tsdb.path )
远端存储的外部服务可以是influxdb、mysql、消息队列等,通常是在prometheus.yml中配置remote_write,remote_read参数来进行http通信
在配置本机服务时,会在配置文件中添加对应的存储路径,默认存储15天
ExecStart=/root/prometheus/prometheus --config.file=/root/prometheus/prometheus.yml --storage.tsdb.path=/root/prometheus/data
4.1rpm安装influxdb
wget https://repos.influxdata.com/rhel/6Server/x86_64/stable/influxdb-1.2.0.x86_64.rpm
rpm -ivh influxdb-1.2.0.x86_64.rpm
安装完启动服务:systemctl start influxdb.service
创建数据库curl -XPOST http://localhost:8086/query --data-urlencode "q=CREATE DATABASE prometheus1"
influxdb对应prometheus的接口如下
/api/v1/prom/read
/api/v1/prom/write
/api/v1/prom/metrics
因此在prometeus.yml中配置如下
remote_write:
- url: "http://localhost:8086/api/v1/prom/write?db=prometheus1"
remote_read:
- url: "http://localhost:8086/api/v1/prom/read?db=prometheus1"
https://blog.csdn.net/Happy_Sunshine_Boy/article/details/107806342
4.2 influxdb集群
集群采用influx-proxy方式
https://www.cnblogs.com/enobear/p/13595712.html
5.prometheus高可用
总体三种方式: https://zhuanlan.zhihu.com/p/86763004
-
部署多个相同的server。server1和server2配置完全一样,都要监控所有的数据
-
基于上面方法加上第三方持久化存储
-
基于联邦机制
为什么有联邦机制:单一的prometheus无法处理大量的采集任务,将不同的采集任务分配到不同的prom节点中,从而实现功能分区,这就叫联邦机制 什么是联邦机制,Server1和server2分别抓取一部分数据,然后由server中心从1和2中抓取需要的数据存入第三方存储 联邦机制适用于两种场景: 1.单数据中心(一般公司用) 2.多数据中心
6.promql
https://www.cnblogs.com/linuxk/p/12054401.html
查询方式:metrics_name{查询条件}[范围] offset 位移(天数)
监控指标名称查询
范围查询
时间位移查询
聚合查询
4种metrics(指标)
https://blog.csdn.net/weixin_37512224/article/details/105248696



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律