k8s基础一
一.认识
https://zhuanlan.zhihu.com/p/96908130
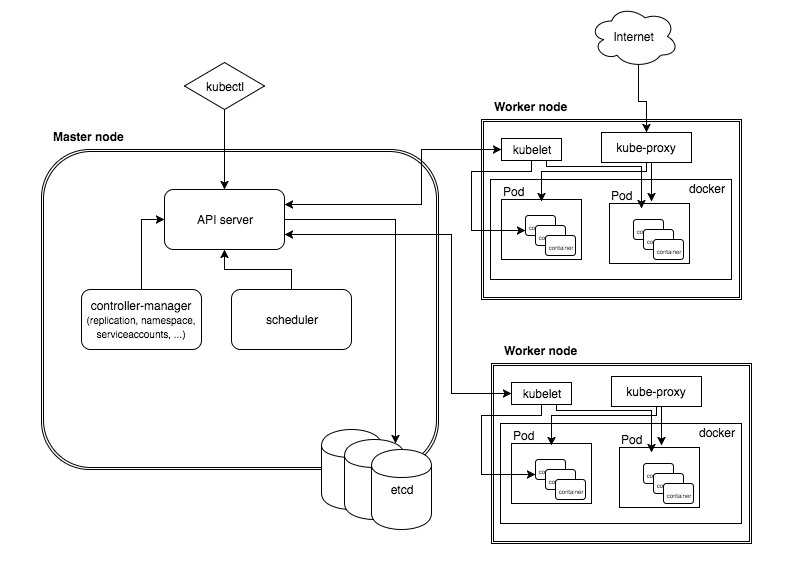
k8s是一个管理平台,或者说是一个跨宿主机的编排工具,属于主从分布式架构,主要由master node和worker node构成,用来管理docker容器集群(一个集群就是一个虚拟机)。
Master Node:作为控制节点,对集群进行调度管理;Master Node由API Server、Scheduler、Cluster State Store和Controller-Manger Server所组成;
Worker Node:作为真正的工作节点,运行业务应用的容器;Worker Node包含kubelet、kube proxy和Container Runtime;
kubectl:用于通过命令行与API Server进行交互,而对Kubernetes进行操作,实现在集群中进行各种资源的增删改查等操作;
下面是一些组件的介绍
API Server:运维人员通过UI或kubelctl来控制apiserver进而来控制整个k8s集群,worknode也通过aipserver来进行对etcd的更新操作
crontroller manager:k8s是一套自动运行的系统,cm就是系统的管理者,里面包含8个controller
etcd:分布式的键值对存储库,集群上的所有配置信息都存在此库。node想更新etcd库也需要通过apiserver
scheduler:负责将Pod调度到Node上,调度完之后由kubelet来管理Node
kubelet:k8s并不会直接调用节点上的容器,而是通过kubelet(相当于小跟班),kubelet再调用docker来调用、创建容器
cadvisor:监控容器,已经被集成在kubelet中,默认http://node:4194端口即可访问
flannel:通道
kube-proxy:负载均衡到后端的真正容器,用户来访问
crontroller manager由以下8部分构成
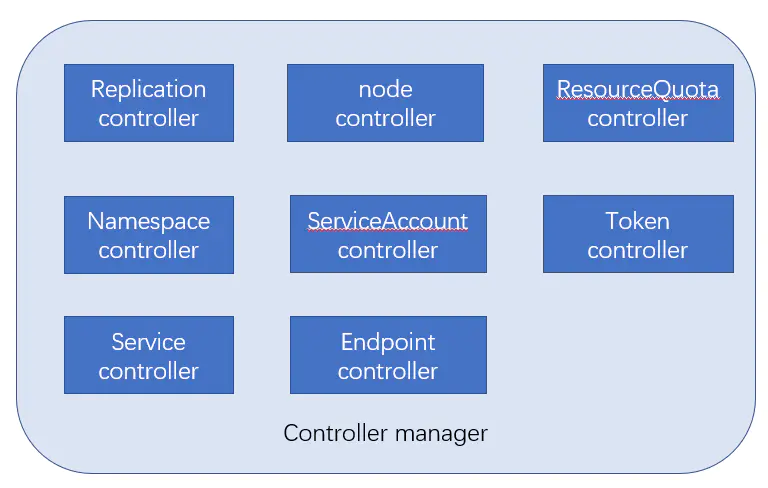
Replication controller:副本控制器
node controller:kubelet定时向apiserver汇报状态信息,apiserver将信息更新到etcd中
ResourceQuota Controller:
Namespace Controller:管理命名空间
3.架构图
二.工作流程
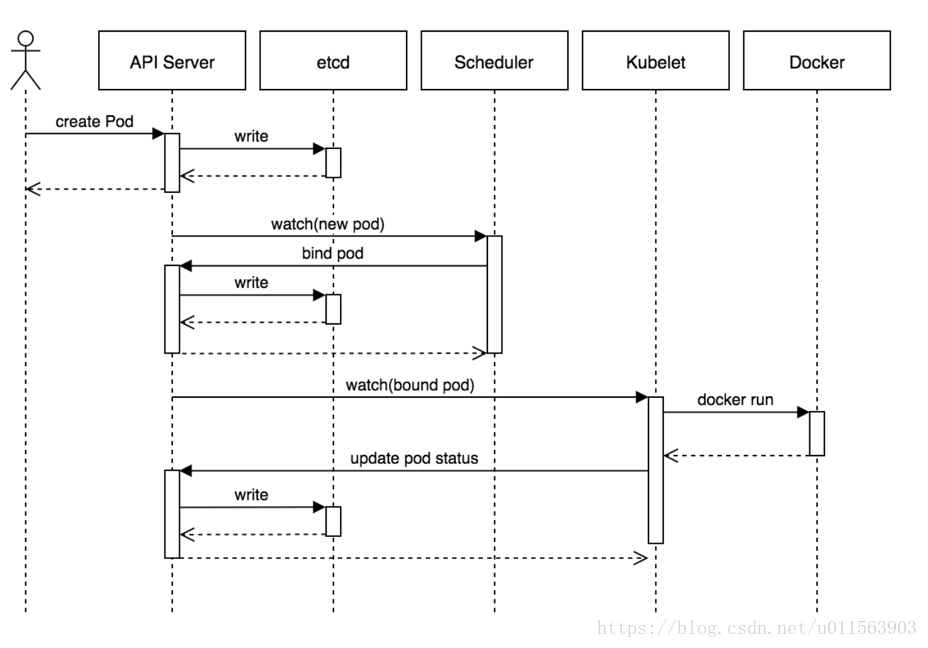
1. 用户提交创建Pod的请求,可通过API Server的REST API和Kubectl命令行工具,支持Json和Yaml两种格式;
2. API Server处理用户请求,将pod信息存储到etcd
3. Scheduler通过API Server的定时watch机制,查看到etcd中新的pod,尝试为pod绑定Node
4. kubelet根据调度结果执行Pod创建操作: 绑定成功后,会启动container, docker run, scheduler会调用API Server的API在etcd中创建一个bound pod对象,描述在一个工作节点上绑定运行的所有pod信息。运行在每个工作节点上的kubelet也会定期与etcd同步bound pod信息,一旦发现应该在该工作节点上运行的bound pod对象没有更新,则调用Docker API创建并启动pod内的容器。
三.特点
- 自我修复。重新在其他节点启动失败的pod,前提是此pod通过rc创建
- 服务发现和负载均衡。如果节点挂掉,kube-proxy(用户访问)会将此节点去掉
- 弹性伸缩。当一个容器访问量大,会给其赋予更多资源
- 滚动升级
四.安装
k8s多种安装方式(2,3适合生产使用)
1.yum安装
2.二进制安装
3.kubeadm安装
4.阿里云直接购买k8s服务器
五.应用场景
k8s最适合微服务使用
简单认识下微服务(mvc只有一套架构,微服务是多套架构)

微服务架构优点:
支持更多的并发(mvc是所有服务都在一套集群,微服务是不同集群)
高可用更强(某网站某服务挂了,直接连链接都给取消了,用户可能都不知道有这个功能存在)
代码更新更快
微服务和k8s的关系
微服务其实就是原来的mvc架构拆分出来的一个个小的服务,假如一个django项目拆分成了100个django小项目,那么如果要给100台服务器配置django环境,是不是很麻烦,此时就用到了docker,只需要一个docker镜像安装django环境,换成不同的代码执行就行。但是这时又有问题了,假如生产、开发、测试、沙盒等等环境都需要一样的环境,这样手动起来是不是也是做了重复性工作?此时就用到了k8s
六.k8s常用资源
1.创建pod资源
pod是k8s最小的资源单位。任何一个k8s资源都可以由yml清单文件来定义
k8s yaml的主要组成(这几部分顶格写,pod的创建由master来执行,会随机选取node节点创建)
apiVersion:v1 #api版本
kind:pod #资源类型
metadata: #属性
spec: #详细
master节点新建k8s_pod文件夹,文件夹下新建k8s_pod.yaml(注意空格、大小写)
apiVersion: v1
kind: Pod #资源类型
metadata:
name: nginx #pod的名字
labels:
app: web #pod打的标签
spec:
containers: #pod里面运行的容器(一个pod可以运行多个容器)
- name: nginx
image: 10.0.0.11:5000/nginx:1.13 #已存在的镜像名称,在私有仓库的需要拉下来
ports:
- containerPort: 80
执行命令创建pod:kubectl create -f k8s_pod.yaml,出现pod "nginx" created即可
查看有几个pod:kubectl get pod (或者kubectl get pods)这个命令只能查看有几个pod
NAME READY STATUS RESTARTS AGE
nginx 0/1 ContainerCreating 0 26s
查看pod是否创建成功kubectl describe pod nginx (kubectl describe 类型 名称),查看到错误如下
FirstSeen LastSeen Count From SubObjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
23m 23m 1 {default-scheduler } Normal Scheduled Successfully assigned nginx to 192.168.1.12
23m 2m 9 {kubelet 192.168.1.12} Warning FailedSync Error syncing pod, skipping: failed to "StartContainer" for "POD" with ErrImagePull: "image pull failed for registry.access.redhat.com/rhel7/pod-infrastructure:latest
进入到上面提示的192.168.1.12node节点的/etc/docker/certs.d/registry.access.redhat.com/目录下,发现有证书,再通过ll rehat-ca.crt查看,发现是软连接无法找到指定的文件/etc/rhsm/ca/redhat-uep.pem,具体原因是registry.access.redhat.com/rhel7/pod-infrastructure:latest\镜像没有pull下来,这个镜像地址就是node节点上/etc/kubernetes/kublet文件里的镜像路径。

解决方法如下:
1.master节点建立私有仓库(建立完成后永久启动)
-docker run -d -p 5000:5000 --restart=always --name registry registry:latest
2.master或node节点导入对应的镜像并上传到私有仓库 (也可通过docker search pod-infrastructure下载最新)
-docker tag docker.io/tianyebj/pod-infrastructure 192.168.1.10/pod-inxx:latest
-docker push 192...inxx:latest
3.node节点修改kubelet中的镜像地址为私有仓库的地址
-vim /etc/kubeteletes/kubelet 修改如下图

此时systemctl restart kubelet 再进入master节点kubectl get pods查看到某个节点上已经成功装上pod(name:pod名称,ready:pod数量,status:运行状态,AGE:运行时间)

进入到192.168.1.12node节点docker ps此时查到两个容器(1.nginx容器2.基础容器infrastru,且nginx容器没有ip有端口,infrasteru容器有ip无端口,两者公用一个ip)
什么是pod资源
pod由最少两个容器组成(一个是pod基础容器,一个是yaml里配置的业务容器,最多1+4),基础容器pod就是为了实现k8s的高级功能如弹性伸缩、自我修复等等
再来看个例子:
apiVersion: v1
kind: Pod
metadata:
name: test
labels:
app: web
spec:
containers:
- name: nginx
image: 192.168.1.10:5000/nginx:1.13
ports:
- containerPort: 80
- name: alpine
image: 192.168.1.10:5000/alpine:latest
command: ["sleep","1000"] #启动容器需要此命令,不然已启动就自动关闭
使用命令kubectl create -f k8s_pod2.yaml创建pod
创建完之后 kubectl get nodes -o wide 会得到如下所示(IP为pod里容器的ip,NODE为宿主机的ip)

此时进入192.168.11执行docker ps会看到3个容器(nginx、alpine、pod-infrastructure基础容器),查看基础容器的ipdocker inspect 容器id查看其ip,与上图ip一样
yaml文件
yaml告诉kubelet通过调用docker来启动容器
2.replicationController资源
rc作用:1.保证指定数量的pod始终存活 2.通过标签选择器来关联pod
创建一个rc(创建的时候查看labels,保证此次创建没有相同的,可使用kubectl get pod --show-labels命令查看,如果此yaml文件和其他的yaml有相同的label,很大可能此次创建会少pod,因为副本数量是一定的,老的会挤掉新创建的),rc的yaml文件中有replicas,用来创建pod,所以不用pod相关的yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: nginx
spec:
replicas: 5 #5个pod副本
selector: #1.和下面的labels对应 2.selector下可有多个label
app: web #不要和其他yaml的重复(app: web是一个label整体)
ver: v1
template: #pod模板
metadata:
labels:
app: web
ver: v1
spec:
containers:
- name: web
image: 192.168.1.10:5000/nginx:1.13 #本地没有会从仓库中pull
ports:
- containerPort: 80
执行kubectl create -f xx.yaml看到下图所示,证明rc创建完成

- 执行
kubectl get pod,会看到一共有5个pod,其中nginx和test都是之前pod创建的,这是什么问题呢,明明声明了5个副本,应该是产生5个nginxrc-xx的。这其中的原因就是因为之前pod创建的labels和本次相同。

-
执行
kubectl delete rc nginxrc-xx删除rc新创建的pod,修改yaml文件中的selector和labels,再重新创建。 -
执行
kubectl get pod -o wide查看到rc创建的pod会均匀分布在node节点11,12上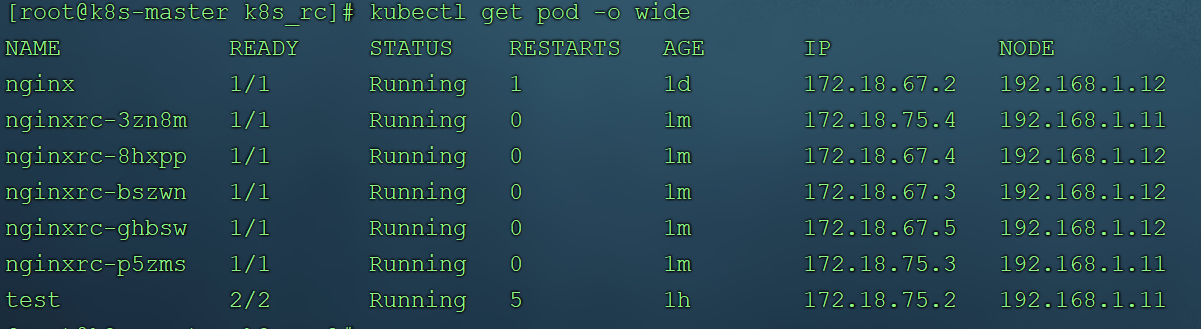
如果不小心删除podkubectl delete pod xx(和删除rc创建的命令不同),会重新自动生成pod,保证副本的数量
2.2rc滚动升级
什么是滚动升级:每次只升级其中一个pod,保证其他pod、系统正常运行。rc的滚动升级需要新旧两个yaml文件,规范如下:
1.RC的名字不能与旧的RC名字相同
2.在selector中应至少有一个label与旧的RC的label不同,以标识其为新的RC(template中labels要和本文件中selector保持同步)
新建rc文件
apiVersion: v1
kind: ReplicationController
metadata:
name: nginx2
spec:
replicas: 5 #5个pod副本
selector:
app: web2 #和下面的labels对应,不要和其他yaml的重复
template: #pod模板
metadata:
labels:
app: web2
spec:
containers:
- name: web2
image: 192.168.1.10:5000/nginx:1.15 #本地没有会从仓库中pull
ports:
- containerPort: 80
如果想对pod进行升级,另外新建一个yaml文件(滚动升级之后会删除原来的rc)
命令vimdiff rc1.yaml rc2.yaml查看两文件的不同
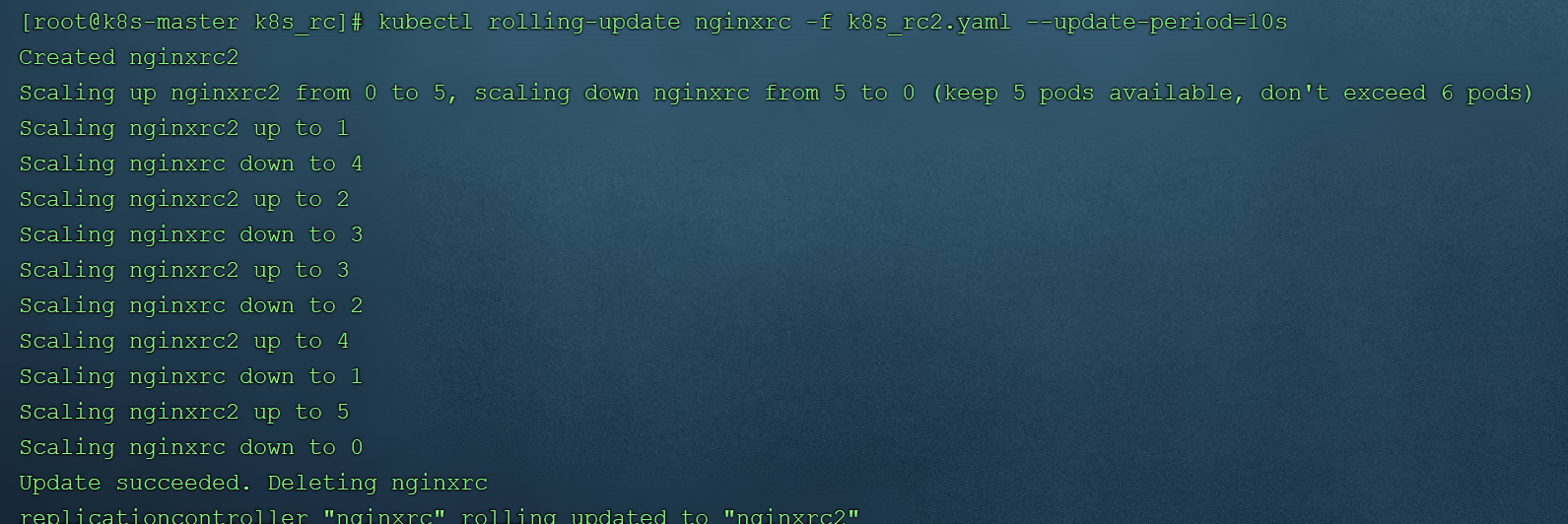
滚动升级命令:kubectl rolling-update nginx -f rc2.yaml --update-period=30s
3.service资源
service分为普通service和无头service(handless service)
- 普通service的负载均衡其实是由kube-proxy实现的,kube-proxy发现普通service有clusterip,就会处理它并对它负载均衡到后端的pod上;
- 无头service的是没有clusterip的,这时kube-proxy发现service没有clusterIP,就不会处理它,也就没有所谓的负载均衡。
几种资源简单介绍
参考:https://zhuanlan.zhihu.com/p/157565821
k8s中的service是四层协议上工作,ip:端口,而ingress是七层负载均衡
service几种类型的说明参考: https://zhuanlan.zhihu.com/p/157565821
三种外部访问的方式:NodePort,LoadBalancer,Ingress
--访问方式区别:
ClusterIP:用于集群内部pod之间的访问(可通过http://ClusterIp:port和http://ClusterName:port访问)
NodePort:node端口只能是30000-32767
LoadBalancer:类似于keepalived,有浮动ip,价格非常昂贵
1.ClusterIP
默认ClusterIP无法外部访问,但是可以通过proxy模式来访问,应用场景为内部调试的时候

启动proxy模式:
kubectl proxy --port=8080
通过k8s api,使用如下模式来访问服务
http://localhost:8080/api/v1/proxy/namespaces/<NAMESPACE>/services/<SERVICE-NAME>:<PORT-NAME>/
例子如下:
apiVersion: v1
kind: Service
metadata:
name: service-python
spec:
ports:
- port: 3000
protocol: TCP
targetPort: 443
selector:
run: pod-python
type: ClusterIP
2.NodePort
实现集群外的业务访问
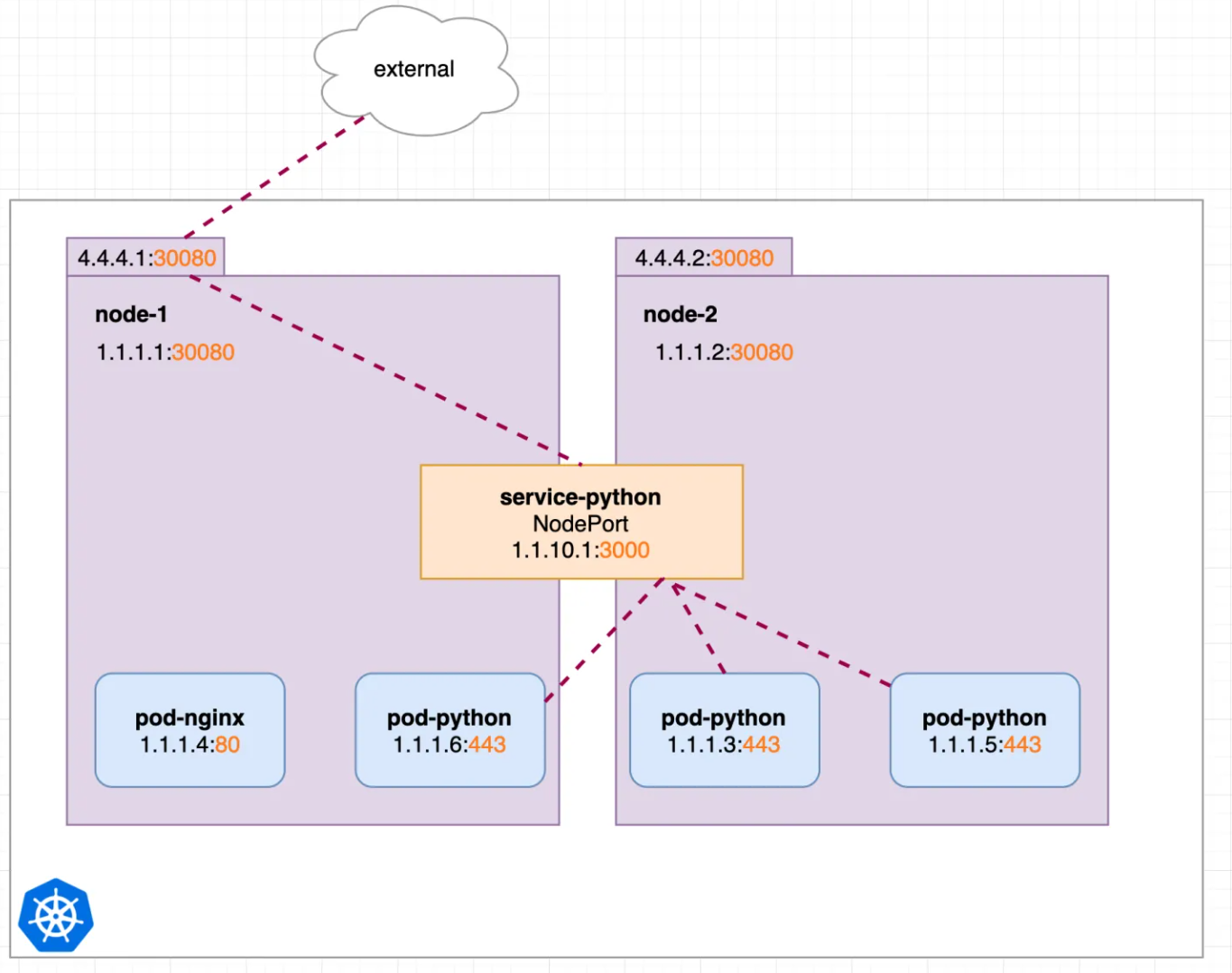
创建一个service(k8s_svc.yaml)
apiVersion: v1
kind: Service
metadata:
name: service-python
spec:
ports:
- port: 3000
protocol: TCP
targetPort: 443
nodePort: 30080
selector:
run: pod-python
type: NodePort
创建完浏览器访问node对应ip和端口:http://4.4.4.1:30080(或http://4.4.4.2:30080)可访问
3.loadbalancer
nodeport需要访问node的ip,loadbalancer相当于给node负载均衡

示例如下:
apiVersion: v1
kind: Service
metadata:
name: service-python
spec:
ports:
- port: 3000
protocol: TCP
targetPort: 443
nodePort: 30080
selector:
run: pod-python
type: LoadBalancer
使用kubectl get svc

可以看到external-ip。我们就可以通过该ip来访问了。
4.知识点
修改rc副本数量kubectl scale replicationcontroller nginxrc2 --replicas=3,再kubectl describe svc myweb查看,会负载均衡到3个node上,这也是服务的自动发现
进入pod容器kubectl exec -it podname /bin/bash可进行修改静态文件index.html,试验负载均衡
service使用iptables(iptables -t nat -L -n|grep svc的地址进行查看), 将发向clusterIP对应端口的数据,转发到kube-proxy中 来进行负载均衡,k8s1.8版本之后推荐使用lvs
修改nodeport范围(修改完之后重启:systemctl restart kubelet)
vim /etc/kubernetes/apiserver
KUBE_API_AGES="--service-node-port-range=3000-50000"
命令行创建service资源(会随机生成node端口,使用较少)
kubectl expose rc rc名称 --type=NodePort --target-port=80 --port=80
4.Deployment资源
在rc滚动升级后,服务会中断(因为rc更新需要改动labels),这是因为rc标签和template中labels改变导致和原来的svc标签不一致。可使用kubectl get rc -o wide和kubectl get svc -o wide查看到rc和svc的标签不一致,还需要手动改svc的标签kubectl edit svc xx,比较麻烦。因此引入了deployment(简称deploy),deploy会创建rs(rc的升级版)来管理副本数,deploy中有资源限制
apiVersion: extensions/v1beta1 #此处名称注意
kind: Deployment
metadata:
name: nginx #deploy名称
spec:
replicas: 3 #会启动3个pod
selector: #定义标签选择器,部署需要管理的pod(带有该标签的的会被管理)需在pod 模板中定义
matchLabels: #集合选择器,会匹配template中含有其下label的pod(注意:含有2字)
app: nginx
template:
metadata:
labels:
app:nginx
ver:v1
spec:
containers:
- name: nginx
image: 192.168.1.10:5000/nginx:1.13
ports:
- containerPort: 80
resources: #docker容器对宿主机占用资源的限制(可使用docker stats --no-stream查看docker容器所占的资源)
limits:
cpu: 100m #100m=0.1个cpu
requests:
cpu: 100m
使用kubectl create -f k8s_deploy.yaml创建,创建成功后可使用kubectl get deploy -o wide查看
deployment滚动升级很简单,kubectl edit deploy xx修改配置文件中镜像版本即可,退出会自动升级,且curl可一直访问
deploy的一些操作都可以用命令行来操作
#1.命令行创建deployment(kubectl run是专门针对deploy来说的)
kubectl run nginx --image=192.168.2.11/nginx:1.13 --replicas=3 --record
#2.命令行升级脚本,升级资源中的容器镜像(set image deployment 资源名称 容器名称)
kubectl set image deployment nginx nginx=192.168.2.11/nginx:1.15
#3.查看deployment所有历史版本
kubectl rollout history deployment nginx
#4.回滚到上一版本(回滚会去除上一版本,进行替换,且生成新的版本号)
kubectl rollout undo deployment nginx
#5.回滚到指定版本
kubectl rollout undo deployment nginx --to-revision=2
deploy和rc区别
1.版本升级时,deploy的服务不中断
2.修改配置文件立即生效
3.deploy所有的操作都可以命令行来实现
#在新版的Kubernetes中建议使用ReplicaSet (RS)来取代ReplicationController。ReplicaSet跟ReplicationController没有本质的不同,只是名字不一样,但ReplicaSet支持集合式selector。
#虽然 ReplicaSets 可以独立使用,但如今它主要被Deployments 用作协调 Pod 的创建、删除和更新的机制。当使用 Deployment 时,你不必担心还要管理它们创建的 ReplicaSet,Deployment 会拥有并管理它们的 ReplicaSet。
#rs支持基于集合的选择器需求,rc支持相等选择器的支持
滚动升级注意事项
1.新建deploy和改变其配置文件,都会生成新的rs,来启动新pod,删除老的pod
2.无需创建新版本yaml,在本文件中修改即可(selector不变,template中labels中更新版本 ver:v2)
deploy滚动升级时服务不中断的原因:两个标签选择器(一个文件中配置的不会变,一个是rs的更新时会做改变),当要升级版本,文件内容改变时,rs相应做出版本改变
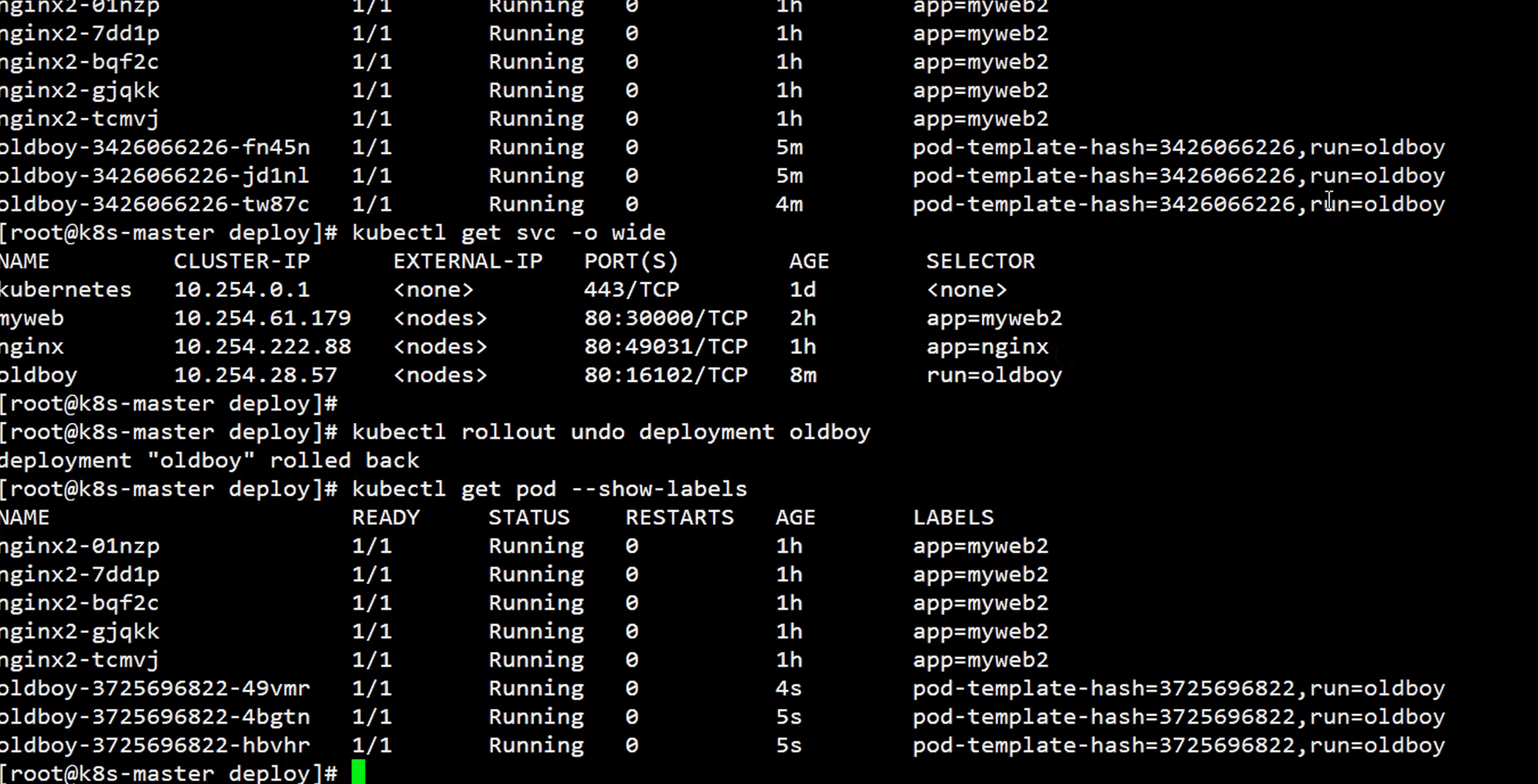
5.总结(副本控制器)
以上rc、rs、deployment都是副本控制器,其他还有Daemon Sets、Pet Sets、Jobs,都是通过控制pod对容器进行操作,如下图。
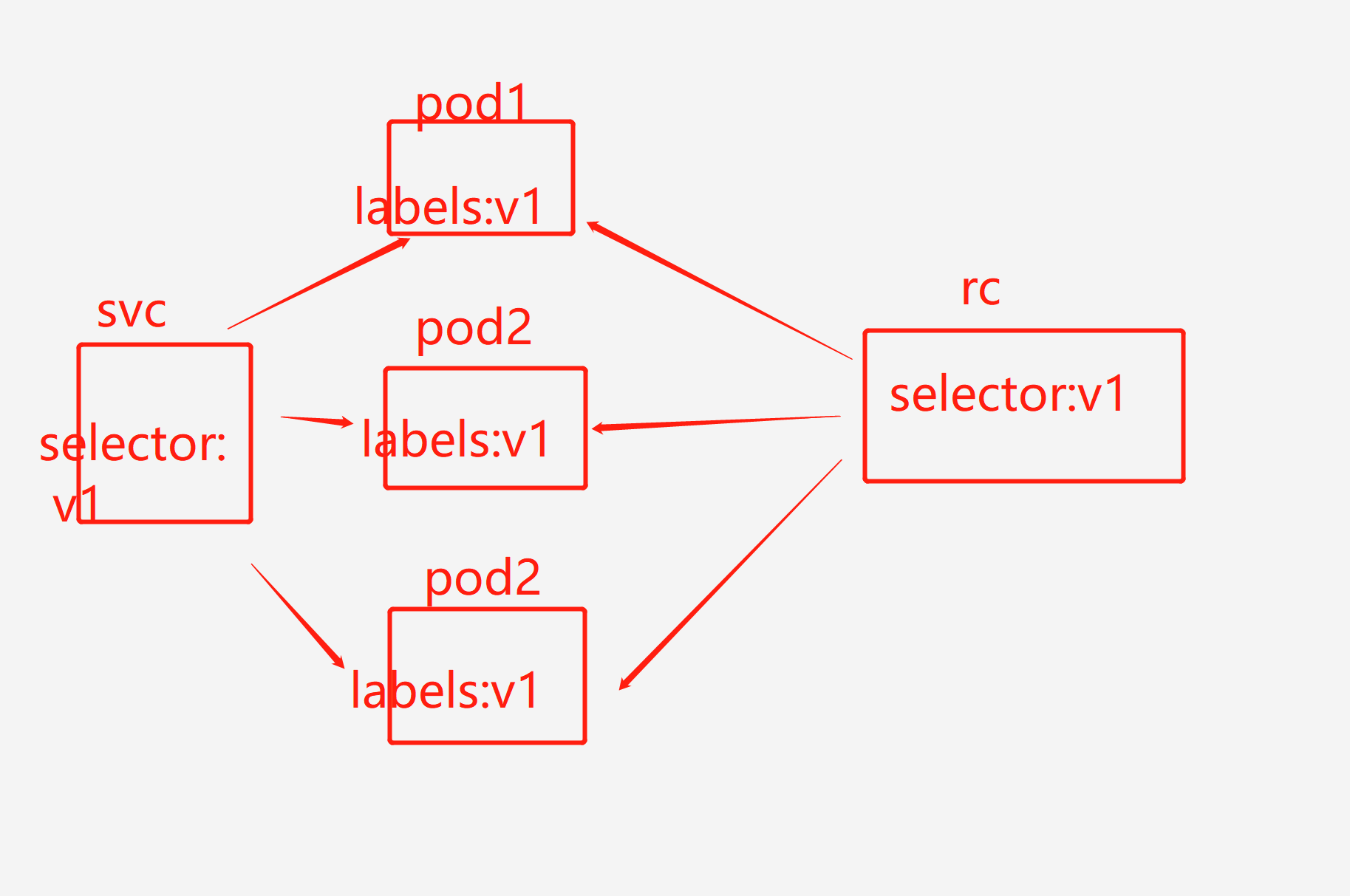
七.tomcat+mysql
不同pod之间如果要通信,不是直接连接的,而是通过vip来通信(如tomcat要访问mysql,就需要通过mysql色svc中的ip)

mysql-rc.yaml
#mysql-rc.yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: mysql
spec:
replicas: 1
selector:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: 192.168.1.10:5000/mysql:1.10
ports:
- containerPort: 3306
env:
- name: MYSQL_ROOT_PASSWORD
value: '123456'
mysql-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: mysql
spec:
ports:
- port: 3306
targetPort: 3306
selector:
app: mysql
tomcat-rc.yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: tomcat
spec:
replicas: 1
selector:
app: tomcat
template:
metadata:
labels:
app: tomcat
spec:
containers:
- name: tomcat
image: 192.168.2.10:5000/tomcat:1.10
ports:
- containerPort: 8080
env:
- name: MYSQL_SERVICE_HOST
value: '172.18.94.11' #数据库地址
- name: MYSQL_SERVICE_PORT
value: '3306'
tomcat-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: tomcat
spec:
type: NodePort
ports:
- port: 8080
nodePort: 30008
selector:
app: tomcat
先创建mysql对应的rc和svc,然后改动tomcat中的rc的数据库地址再进行创建。此处创建完成之后可用http://nodeip/30008/demo访问
八.namespace
namespace是为了资源隔离,假如一个计算节点上要放多个相同名称的mysql节点pod,这就用到资源隔离了,有了namespace,可以将多个pod改为相同名称。如果yaml文件中不写namespace,系统会默认将其添加到default资源下。kubectl get all -n 可查看

在使用资源隔离之前,需kubectl create namespace 名称,然后在pod的yaml文件中使用
九.健康检查和可用性检查
参考:https://blog.csdn.net/Jerry00713/article/details/123894868
1.探针的种类
livenessProbe:健康状态检查,周期性检查服务是否存活,检查结果失败,将重启容器
readinessProbe:可用性检查,周期性检查服务是否可用,不可用将从service的endpoints中移除
StartupProbe: k8s1.16版本后新加的探测方式,用于判断容器内进程是否已经启动。如果配置了startupProbe,.就会先禁止其他的探测,直到它成功为止,成功后将不在进行探测(当容器中程序启动很慢的时候用)
2.探针的检测方法
检测方法同时只能使用一种
- exec:在容器内执行一个命令,如果返回值为0,则认为容器健康
- httpGet:通过应用程序暴露的API地址来检查程序是否是正常的,如果状态码为200~400之间,则认为容器健康。
- tcpSocket:通过TCP连接检查容器内的端口是否是通的,如果是通的就认为容器健康。
3.liveness探针的exec使用

4.三者区别
startupprobe在探测成功后不会再探测,其他两个在容器消亡后停止探测
livenessprobe和readinessprobe建议都使用接口检测方式,假设容器中是java应用程序,readinessprobe采用cmd命令pgrep java检测方式,检测成功,但是livenessprobe使用接口检测方式,检测失败,因为只是启动了java进程,应用程序没有启动,那pod状态就会一直是0/1.
十.k8s弹性伸缩
根据node中cpu的使用率,来自动增加或减少pod的数量,增加或减少多少都是根据弹性伸缩的规则。要监控cpu使用率,此处使用heapster插件。k8s1.8版本之后使用Metrics
1.安装heapster监控
heapster主要有三部分构成:heapster主体、influxdb、grafana
heapster里面需要配置api-server,通过api-server来得到node,它是一个收集者,收集cadvirsor的数据需要存储在influxdb,influxdb再通过grafana来出图,进而展示在dashborad。我们需要部署三个容器:heapster、influxdb、grafana
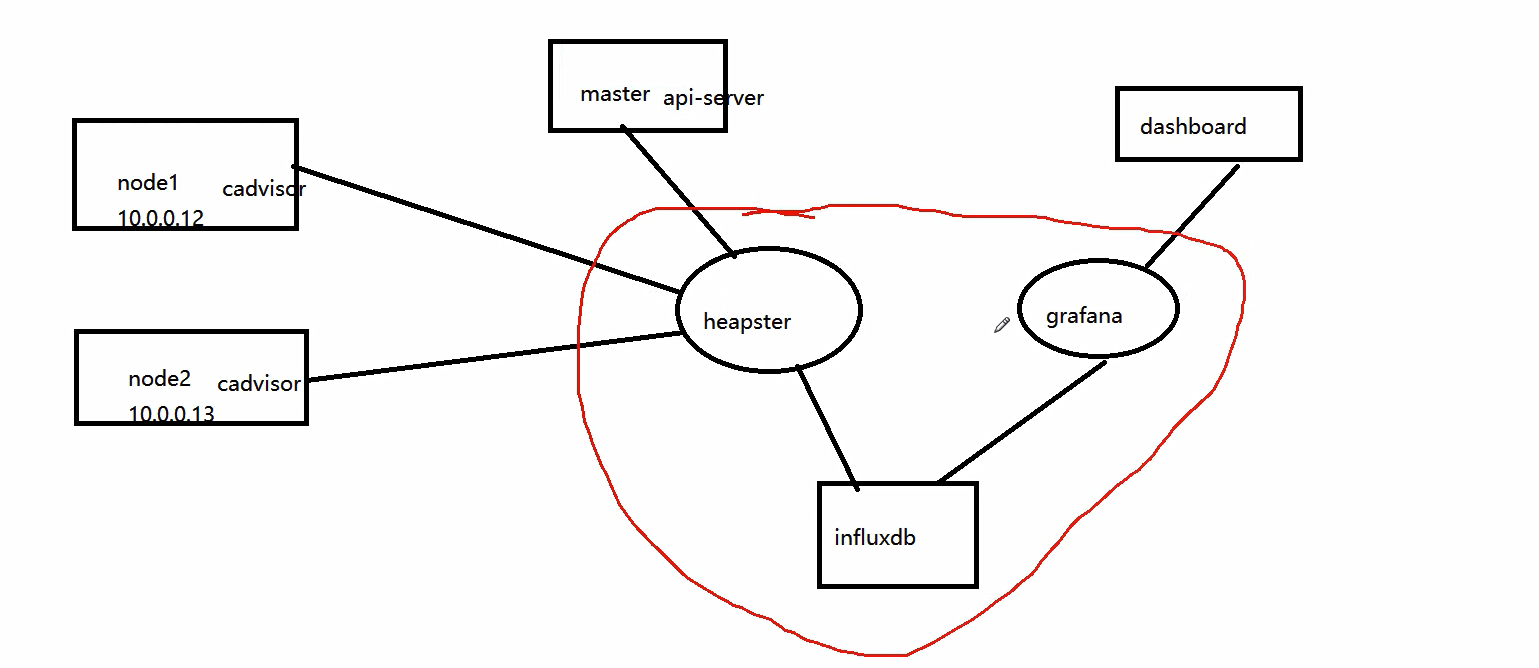
参考: https://www.cnblogs.com/guyeshanrenshiwoshifu/p/9155939.html
2.弹性伸缩
Hpa(全称叫做Horizontal Pod Autoscaler),HPA的操作对象是RC\RS\Deployment
三大步骤:
1.yaml文件中要有资源限制
2.创建HPA,设置资源阈值(pod) #kubectl autoscale replicationcontroller myweb --max=8 --min=1 --cpu-percent=5
3.压测分析
-
新建deploy文件
apiVersion: v1 kind: Pod metadata: name: myweb labels: app: web env: myweb spec: containers: - name: myweb image: 192.168.110.133:5000/nginx:1.13 ports: - containerPort: 80 resources: # 最大可以使用的资源,100m的cpu时间片,50Mi的内存。 limits: cpu: 100m memory: 50Mi # requests代表资源Pod需求的资源,100m的cpu时间片,50Mi的内存。 requests: cpu: 100m memory: 50Mi -
kubectl autoscale replicationcontroller myweb --max=8 --min=1 --cpu-percent=5
-
压测
yum install httpd-tools.x86_64 -y #总共发起50000次请求,每次30个请求 ab -n 500000 -c 30 http://172.16.94.3/index.html/ -
可使用dashboard界面查看相关pod是否增加或减少,也可使用
kubectl get all实时查看
3.metrics安装
参考: https://www.cnblogs.com/klvchen/p/14048803.html
k8s中集成了cadivisor,metrics只相当于一个采集服务,k8s top命令要想使用,需要安装metrics
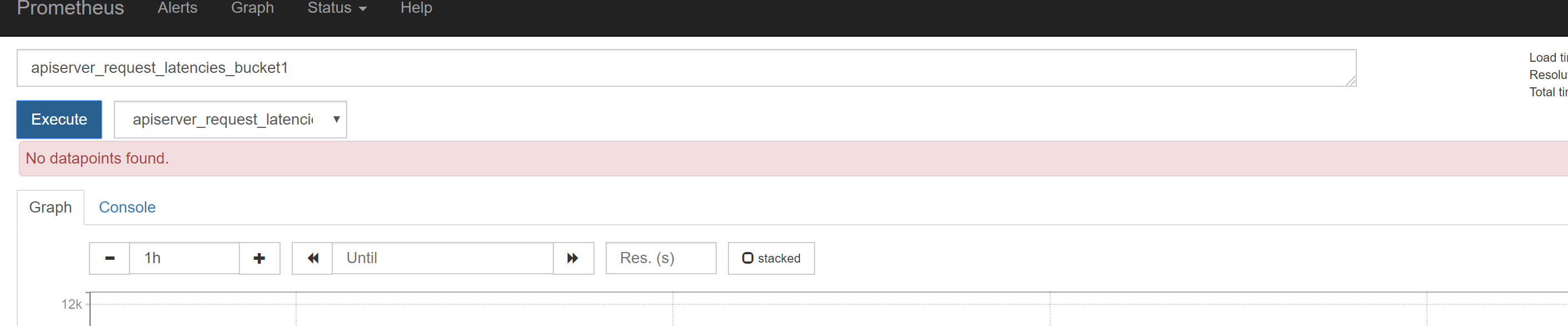
当prometheus安装之后,界面显示"No datapoints found",应该是metrics没有安装。具体安装方法如下:
版本:
K8S:v1.16.9
metrics-server:v0.3.7
wget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.3.7/components.yaml
cp components.yaml components.yaml.ori
vi components.yaml
# 修改3个地方:
image: juestnow/metrics-server:v0.3.7 # 改成国内源
args:
- --kubelet-preferred-address-types=InternalIP,Hostname,InternalDNS,ExternalDNS,ExternalIP # 默认使用node的主机名,但是coredns里面没有物理机主机名的解析,部署的时候添加一个参数
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-insecure-tls #接通过InternalIP进行访问,忽略客户端证书。
修改好之后
docker pull juestnow/metrics-server:v0.3.7
kubectl apply -f components.yaml
kubectl get pods -n kube-system #稍等一段时间进行测试
安装好之后,可查到相关cpu和内存使用情况

十一.持久化存储
k8s中所有持久化方式默认都是宿主机目录覆盖pod目录,要想使用持久化存储,需要清楚:
- 先使用docker下载相关镜像,如果默认镜像(没有启动容器之前的镜像)相关目录下没有文件,可进行挂载,此时不需担心会覆盖pod中内容(mysql镜像默认/var/lib/mysql下没有生成相关文件,可直接挂载)
- 如果默认镜像要挂载的目录下有内容,就需要使用configmap+subpath
1.emptyDir
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
containers:
- image: busybox
name: test-emptydir
command: [ "sleep", "3600" ]
volumeMounts:
- mountPath: /data
name: data-volume
volumes:
- name: data-volume
emptyDir: {}
命令kubectl create -f busybox.yaml创建成功后,会有以下发现
kubectl exec -it busybox -- sh进入容器,存在已创建的/data目录docker inspect 容器id|grep volumes,可以找到/data目录在宿主机对应的docker数据卷所在目录- 在容器中/data创建新文件,docker数据卷下也会同步
kubectl delete -f buxybox.yaml,emptyDir也会删除,因此无法持久化
2.HostPath
同一宿主机上可用于多个pod的持久化方式,删除pod后,在宿主机上的持久化数据不会被删除,可持久化
volumes: #新增:策略HostPath
- name: mysql
hostPath:
path: /data/xx #先在宿主机上创建对应目录,再挂载到容器上
type: DirectoryOrCreate #宿主机上没有目录就创建,可创建多级目录
#type: FileOrCreate #没有文件就创建(前提:文件所在目录须存在)
3.nfs
volumes:
- name: mysql
nfs:
path: /data/xxx #nfs服务端目录
server: 192.168.1.10 #nfs服务端ip
4.configmap
configmap将文件直接作为文件或目录挂载
apiVersion: v1
kind: Pod
metadata:
name: vol-test-pod
spec:
containers:
- name: test-container
image: gcr.io/google_containers/busybox
command: [ "/bin/sh", "-c", "cat /etc/config/special.how" ]
volumeMounts:
- name: config-volume
mountPath: /etc/config
volumes:
- name: config-volume
configMap:
name: special-config
restartPolicy: Never #当容器终止退出,从不重启容器
#1、Always:当容器终止退出后,总是重启容器,默认策略。
#2、OnFailure:当容器异常退出(退出状态码非0)时,才重启容器。
5.pv和pvc
5.1什么pv和pvc
- PV:持久化存储卷,是对底层的共享存储的一种抽象,PV由管理员进行创建和配置(是k8s中对存储资源的抽象),主要含存储能力、访问模式、存储类型、回收策略、后端存储类型等主要信息,它和具体的底层的共享存储技术的实现方式有关,比如NFS、Hostpath、RBD等。注意:k8s只是提供pv和pvc对这些存储支持,并不会自动安装,因此需要自行安装。
- PVC的全称是: PersistenVolumeClaim (持久化卷声明),有namespace,PVC是用户存储的一种声明,PVC和Pod类似,Pod是消耗节点node资源,PVC消耗的是PV资源,Pod可以请求CPU的内存,而PVC可以请求特定的存储空间和访问模式。
- pv由存储工程师创建,pvc由k8s管理员创建,当创建的pvc找不到合适的pv,会等待pv生成而后自动完成绑定
- 每个k8s的底层都有nfs、glusterfs、ceph等存储方式,pv声明了存储能力和哪个存储的指向。pvc会选择自己namespace下的pv,好处:不用再指定nfs或者hostpath等持久化方式,这样pvc文件就可以在不同的机器上通用,不用改变配置文件的存储方式。也就是说你的pvc文件可能选择底层的nfs方式,也可选择hostpath方式,具体根据pvc文件来自动决定。
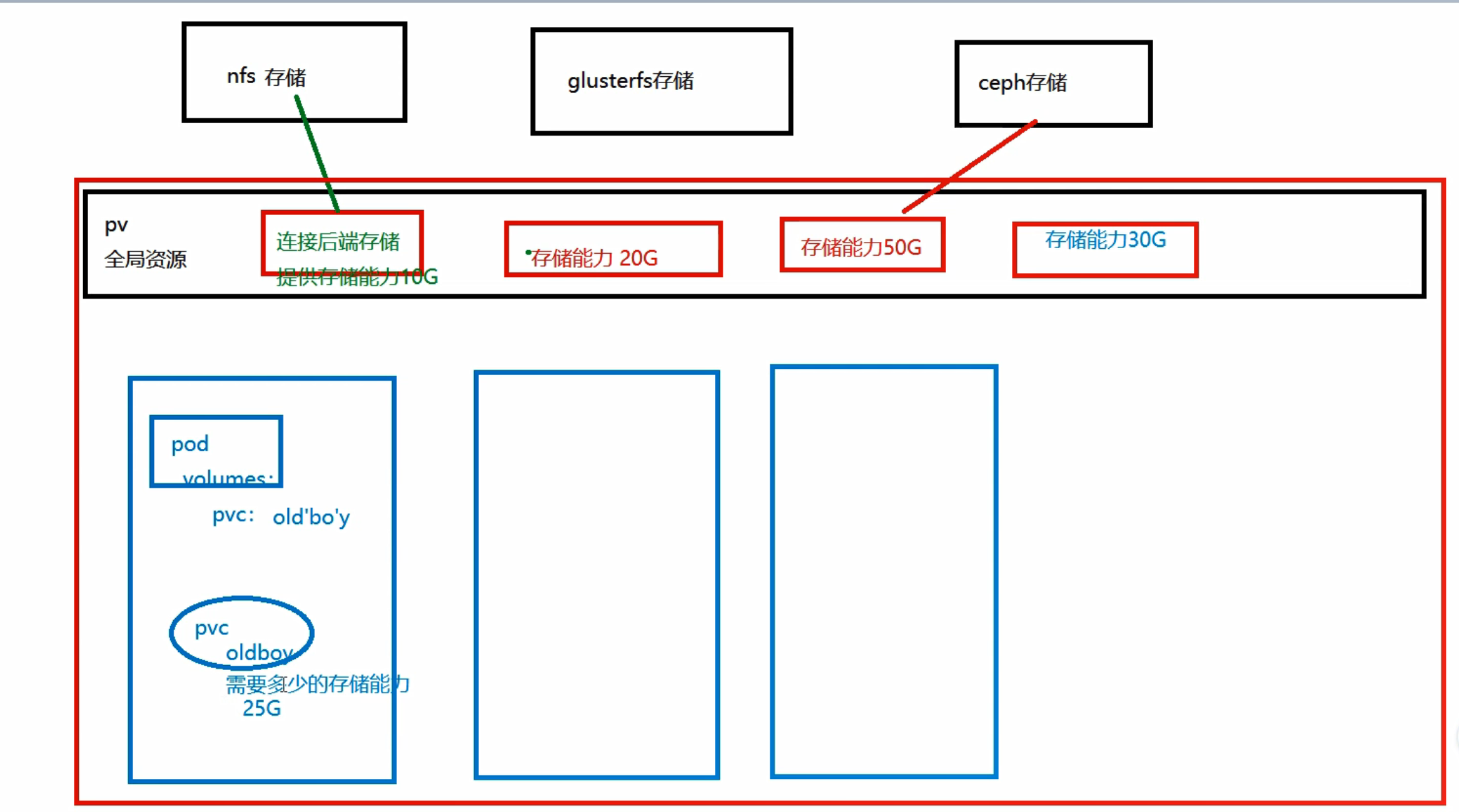
5.2创建pv
第一步:先在宿主机mkdir -p /data/pod/volume1,volume1将作为pv对应的hostpath本地存储的目录
第二步:创建pv(pv-hostpath.yaml),也可指定nfs方式
#阿里云创建pv
apiVersion: v1
kind: PersistentVolume
metadata:
name: cloudai-code-pv
namespace: cloudai-2
labels:
alicloud-pvname: pv-nas
spec: # 定义pv属性
capacity: # 容量
storage: 1Gi # 存储容量
storageClassName: nas
accessModes: # 访问模式
- ReadWriteMany # ReadWriteOnce:单个节点读写。ReadOnlyMany:多节点只读。ReadWriteMany:多节点读写。挂载时只能使用一种模式。
flexVolume:
driver: "alicloud/nas" # 这里是固定的
options:
server: "xxxxxxxxxxxxxxxxxxxx" # 这里要问阿里云管理者
path: "/k8s/cloudai2/code"
vers: "4.0"
persistentVolumeReclaimPolicy: Recycle # 回收策略 目前NFS和HostPath支持回收Recycle。 AWS、EBS、GCE、PD和Cinder支持删除Delete。Retain保留所有的数据资源
#创建hostpath的pv
kind: PersistentVolume
apiVersion: v1
metadata:
name: pv001
labels:
release: stable
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
hostPath:
path: /data/pv
#创建nfs的pv
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv002
labels:
release: stable
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
nfs:
path: /tmp/data
server: 172.17.0.2
说明:
accessModes支持多种访问模式
- ReadWriteOnce(RWO): 读写权限,仅在一个node上运行的多个pod可以连接到存储并进行读写操作
- ReadOnlyMany(ROX):只读权限, 运行在不同节点上的多个 pod 可以连接到存储并执行读取操作
- ReadWriteMany(RW):读写权限, 运行在不同节点上的多个 pod 可以连接到存储并进行读写操作
persistentVolumeReclaimPolicy的策略,指的是如果PVC被释放掉后,PV的处理,这里所说的释放,指的是用户删除PVC后,与PVC对应的PV会被释放掉,PVC和PV是一一对应的关系
- Retain,PV的数据不会清理,会保留volume,如果需要清理,需要手动进行
- Recycle,会将数据进行清理,即 rm -rf /thevolume/*(只有 NFS 和 HostPath 支持),清理完成后,PV会呈available状态,支持再次的bound
- Delete,删除存储资源,会删除PV及后端的存储资源,比如删除 AWS EBS 卷(只有 AWS EBS, GCE PD, Azure Disk 和 Cinder 支持)
5.3创建pvc
pvc-hostpath.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mppvc-01 # 指定PVC的名称
namespace: default # 必须有,且跟pod在一个namespace下,不然pod无法使用
spec:
accessModes: ["ReadWriteOnce"] # 指定PVC的访问模式
resources:
requests:
storage: 0.05Gi # PVC申请的容量
- PVC声明了accessModes访问类型为ReadWriteOnce,创建后,系统会自动去找能够支持ReadWriteOnce访问类型的PV,若无符合条件的PV,则不会进行绑定。
- PVC声明了storage的大小为0.05Gi,创建后,系统会自动去找能够支持此容量的PV,通常PV的容量至少要大于或者等于0.05Gi才会去进行绑定
5.4pod引用pvc
1.这是在已有4.3中pvc的情况下的pod引用方式
volumes:
- name: mysql
persistentVolumeClaim:
claimName: mppvc-01(pvc名称)
containers:
- name: lp-container # 容器名称
image: xxxxxxxxxxx # 基于的镜像名, 根据镜像创建容器
command: ['sleep','30000']
volumeMounts:
- name: mysql
mountPath: /app
2.pvc自动化实现
- volumeClaimTemplates实现了pvc自动化创建,只有satefulset有volumeClaimTemplates
- 以下例子没有创建storageclass,只是在pv中声明了storageclassname,是为了volumeClaimTemplates引用
- storageclass通过pvc来实现pv的自动化创建,但是在使用satefulset时,storageclass会为我们每一个Pod创建一个pv和pvc
2.1先创建storageClassName相关pv
apiVersion: v1
kind: PersistentVolume
metadata:
name: redis-pv3
labels:
type: sata
namespace: my-ns-redis
spec:
capacity:
storage: 2Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
storageClassName: "redis"
nfs:
path: "/data/k8s/redis/pv3"
server: 192.168.198.144
readOnly: false
2.2pod中引用
template: #容器模板
metadata:
labels:
app: redis #容器标签:redis
appCluster: redis-cluster
spec:
containers:
xxxx
volumeMounts:
- name: "redis-data"
mountPath: "/var/lib/redis"
volumeClaimTemplates:
- metadata:
name: redis-data
spec: #元数据
accessModes: [ "ReadWriteMany" ]
storageClassName: "redis" #必须和前面创建的pv的保持一致
5.5查询pv和pvc
可以看到pv-statefulset这个PV已经和mppvc-01的PVC进行了绑定(Bound),RWO和Recycle也是之前PV和PVC声明的状态,说明绑定成功
[root@k8s-master zhanglei]# kubectl get pv |grep pv-statefulset
pv-statefulset 107374182400m RWO Recycle Bound default/mppvc-01
[root@k8s-master zhanglei]# kubectl get pvc |grep mppvc-01
mppvc-01 Bound pv-statefulset 107374182400m RWO 13d
5.6storageclass
因为pv和pvc一一对应,如果pvc增多,pv不够用,手动一个个创建麻烦,storageclass可根据pvc来自动创建pv
参考:https://www.cnblogs.com/rexcheny/p/10925464.html
https://blog.csdn.net/weixin_41947378/article/details/111509849
https://blog.51cto.com/jiangxl/5076635
6.总结
https://blog.csdn.net/weixin_46902396/article/details/124780531
6.1pv和pvc关系
- 一个pod可以挂载多个pvc,因为一个pod中可能有多个项目路径需要持久化
- 一个pvc可以给n个pod提供服务
- 一个pvc只能绑定一个pv,当pv被绑定后处于binding状态,其他pvc无法绑定
6.2volume类型
-
volume是为了声明宿主机上配置,volumeMounts是声明pod上配置
-
在没有pv概念情况下常用的几种类型:emptyDir,HostPath,nfs,configmap,volume下是各种指定的类型,volumeMounts挂载具体路径
-
有pv概念:所有控制器控制的pod的volume下是pvc名称,volumeMounts挂载
-
有storageclassname概念,volumeClaimTemplates中引用pvc,volumeMounts挂载
6.3.subPath
参考:https://www.cnblogs.com/gdut1425/p/13112176.html
十二.分布式存储glusterfs
nfs是单机存储,无法解决单点故障,后期无法扩容
1.什么是分布式存储
分布式存储服务端至少2台,2台合起来的数据才是完整的,如下图2,文件被分别存放在不同的服务端。
缺点:一台服务挂了,其上的数据全部丢失
优点:数据读写更快,支持扩容(一台服务端不够,就多加几台)

为解决上述缺点,可通过添加副本数来解决,在k8s中,一般副本数设置为3就可以。我们挂载任意一个节点就可以,gluster内部会同步数据,将三台服务端关联起来
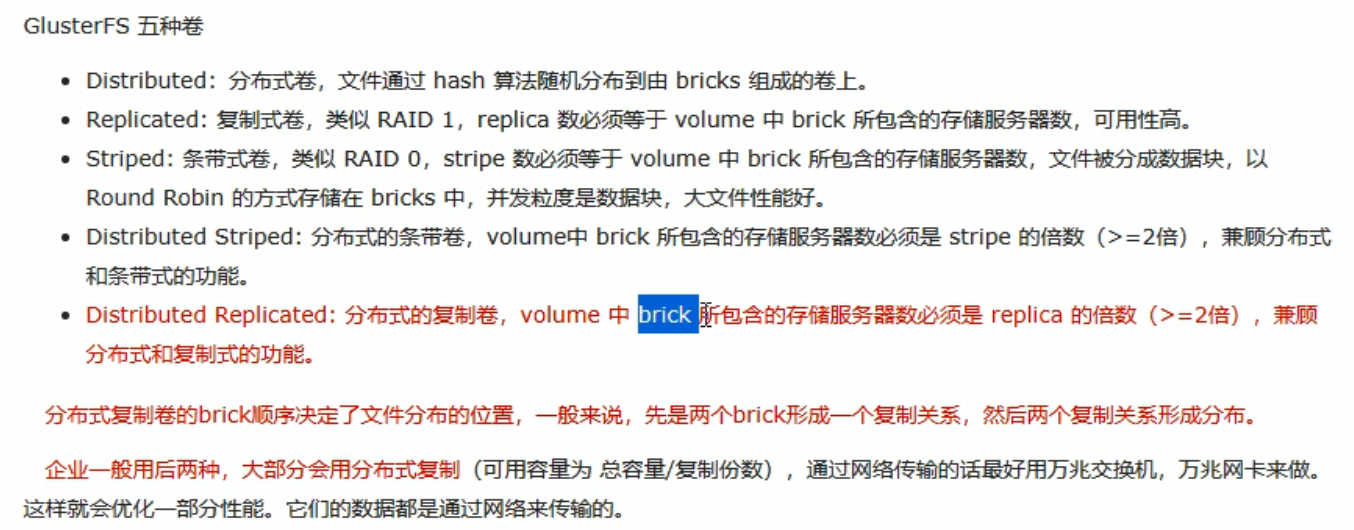
2.gluster五种卷
3.gluster安装
a.安装+配置硬盘
yum install centos-release-gluster6.noarch -y
yum install glusterfs-server -y
systemctl start glusterd.service
systemctl enable glusterd.service
#为gluster集群添加存储单元brick(就是存储),新建的硬盘不重启无法识别用下述方法
echo "- - -" > /sys/class/scsi_host/host0/scan
echo "- - -" > /sys/class/scsi_host/host1/scan
echo "- - -" > /sys/class/scsi_host/host2/scan
#执行完成后再fdisk -l可查看到新建的硬盘,再格式化
mkfs.xfs /dev/sdb
mkfs.xfs /dev/sdc
mkfs.xfs /dev/sdd
mkdir -p /gfs/test1
mkdir -p /gfs/test2
mkdir -p /gfs/test3
#将新建的盘挂载到本地
mount /dev/sdb /gfs/test1
mount /dev/sdc /gfs/test2
mount /dev/sdd /gfs/test3
b.添加存储资源池
gluster pool list #此时只看到本机的,没有构成gluster集群
gluster peer probe 192.168.1.11 #添加节点到资源池
gluster peer probe 192.168.1.12
gluster pool list #此时看到三个,已构成集群
c.添加卷
#将两台机器上的挂载的路径连为一个卷(不指定卷类型的话默认为分布卷)
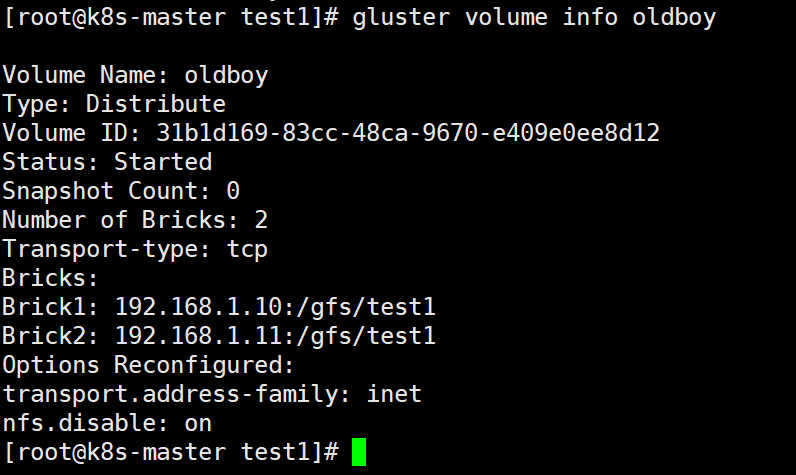
gluster volume create 卷名 192.168.1.10:/gfs/test1 192.168.1.11:/gfs/test1 force
#查看卷信息
gluster volume info 卷名 #如下图
#启动卷
gluster volume start 卷名 #启动之后客户端才能挂载
#客户端挂载(此时写1.10或者1.11都可以,创建几个文件实验下,可发现不同文件分布到不同服务端,客户端是完整的)
mount -t glusterfs 192.168.1.10:/卷名 /mnt
#已存在的卷再添加存储单元
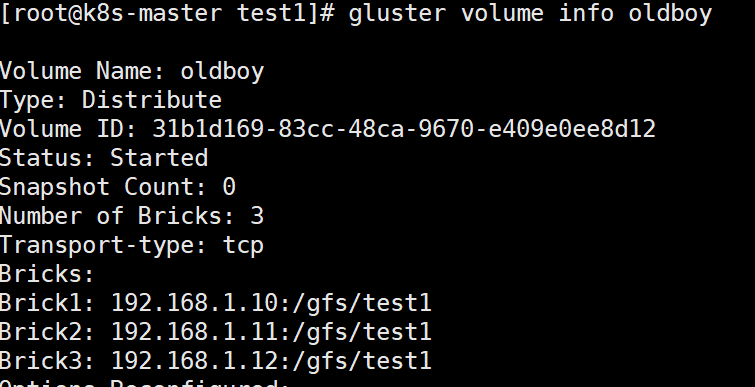
gluster volume add-brick oldboy 192.168.1.12:/gfs/test1 force
#查看(如下图)
gluster volume info oldboy
#再进客户端查看df -h 此时已经是所有卷的存储总和
创建拥有3个副本的卷(这三个存储单元存储数据相同,test1和test1相同,test2和test2相同)
gluster volume create oldqiang replica 3 192.168.1.10:/gfs/test1 192.168.1.11:/gfs/test1 192.168.1.12:/gfs/test1 force
#创建完成之后再添加存储单元,每次都要添加3个,且这3个之后存储的数据都会相同
gluster volume add-brick oldqiang 192.168.1.10:/gfs/test2 192.168.1.11:/gfs/test2 192.168.1.12:/gfs/test2 force
gluster volume add-brick oldqiang 192.168.1.10:/gfs/test3 192.168.1.11:/gfs/test3 192.168.1.12:/gfs/test3 force
#添加完成之后任意服务端查看gluster volume info 卷名都会得到3*3的结果,客户端df -h查看会查到卷总储量
4.glusterfs接入k8s
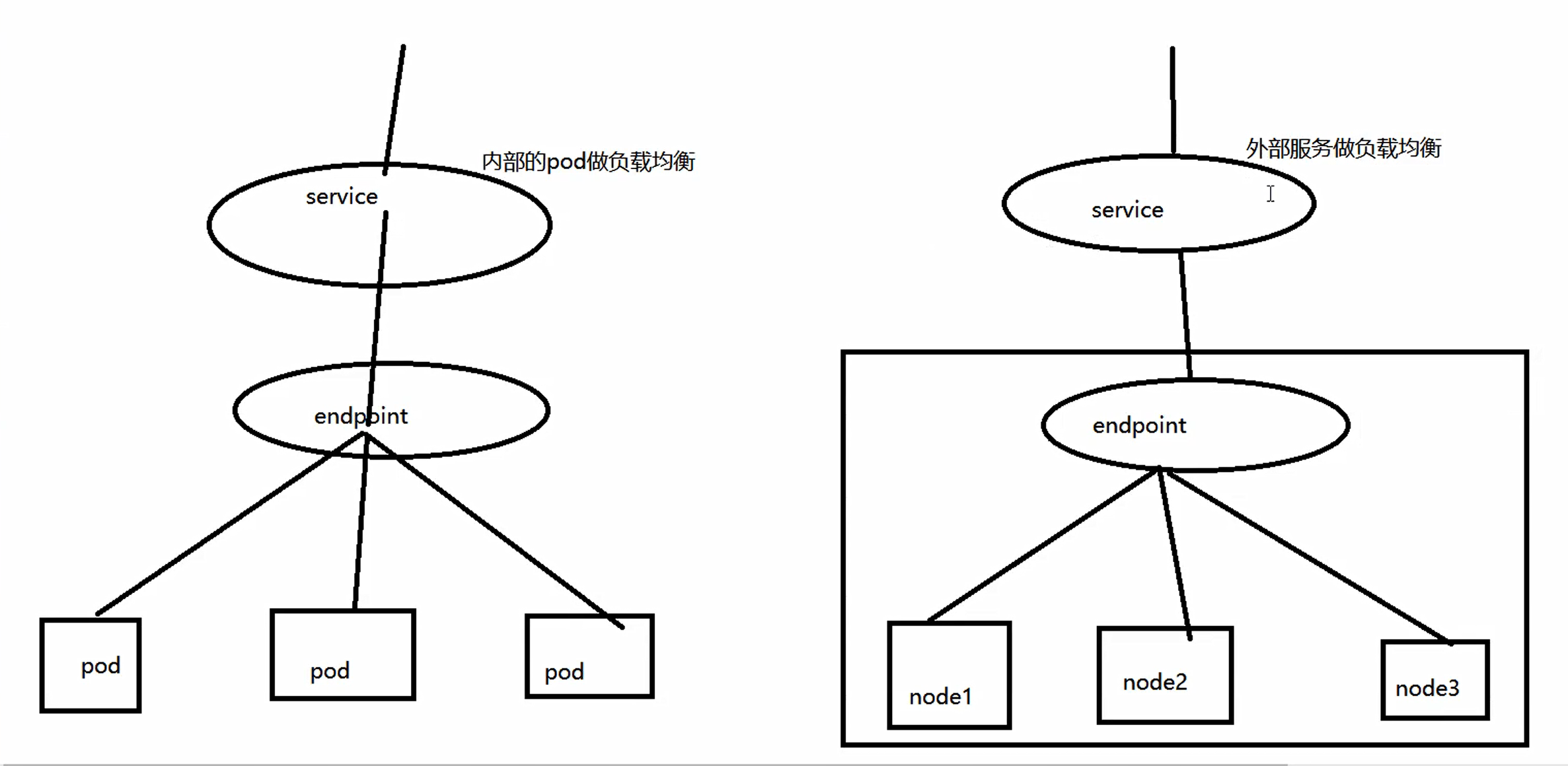
之前我们知道svc的负载均衡主要对象为pod,glusterfs因为是不同node上形成的集群,因此service作为外部服务来对node进行负载均衡
a:glusterfs-ep.yaml
apiVersion: v1
kind: Endpoints
metadata:
name: glusterfs
namespace: tomcat
subsets:
- addresses:
- ip: 192.168.1.10
- ip: 192.168.1.11
- ip: 192.168.1.12
ports:
- port: 49152
protocol: Tcp
b:创建service(用于外部服务映射的svc,不需要标签选择器,根据名字来关联endpoint)
#glusterfs-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: glusterfs
namespace: tomcat
spec:
ports:
- port: 49152
protocol: Tcp
targetPort: 49152
type: ClusterIP
c:创建glusterfs类型pv
apiVersion: v1
kind: PersistentVolume
metadata:
name: gluster
labels:
type: glusterfs
spec:
capacity:
storage: 50Gi
accessModes:
- ReadWriteMany
glusterfs:
endpoints: "glusterfs"
path: "xx" # glusterfs卷名
readOnly: false
d:创建pvc
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: gluster
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 50Gi
e:pod中引用glusterfs的pvc
#nginx_pod.yaml
....
volumeMounts:
- name: nfs-vol2
mountPath: /usr/share/nginx/html
volumes:
- name: nfs-vol2
persistentVolumeClaim:
claimName: gluster
当然也可以直接在pod中使用glusterfs,使用方式和HostPath相同,无论是哪种情况,都需要提前安装好glusterfs



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律