DjangoRestFramework
一.restful规范
在之前的代码习惯中,通常使用一个url对应一个视图函数,现在有了restful规范,就要遵循。简单来说,就是多个url对应一个视图,视图中封装了get,post,put,patch,delete等主要方法。相对于FBV来说更加简单,使用了CBV模式。
1.是一套规则,用于程序之间进行数据交换的约定。 他规定了一些协议,对我们感受最直接的的是,以前写增删改查需要写4个接口,restful规范的就是1 个接口,根据method的不同做不同的操作,比如:get/post/delete/put/patch/delete.
2.除此之外,resetful规范还规定了: - 数据传输通过json 扩展:前后端分离、app开发、程序之间(与编程语言无关)
3.面向资源编程,视网络上一切为资源,因此URL中一般使用名词
4.建议用https代替http
5.URL中体现api
https://www.cnblogs.com/api/xxx.html
6.URL中体现版本
https://www.cnblogs.com/api/v1/userinfo/
7.如果有条件的话,在URL后边进行过滤
https://www.cnblogs.com/api/v1/userinfo/?page=1&category=2
8.返回给用户状态码
- 200,成功 - 300,301永久 /302临时 - 400,403拒绝 /404找不到 - 500,服务端代码错误
9.操作异常时,要返回错误信息
{ error: "Invalid API key" }
二.drf
简单认识
什么是drf
drf是一个基于django开发的组件,本质是一个django的app。
drf可以帮我们快速开发出一个遵循restful规范的程序。
drf提供哪些功能
-免除csrf认证 dispatch中的as_view()函数,return csrf_exempt(view) #路由组件routers 进行路由分发 #视图组件ModelViewSet 帮助开发者提供了一些类,并在类中提供了多个方法 #版本 版本控制用来在不同的客户端使用不同的行为 #认证组件 写一个类并注册到认证类(authentication_classes),在类的的authticate方法中编写认证逻 #权限组件 写一个类并注册到权限类(permission_classes),在类的的has_permission方法中编写认证逻辑。 #频率限制 写一个类并注册到频率类(throttle_classes),在类的的allow_request/wait 方法中编写认证逻辑 #序列化组件:serializers 对queryset序列化以及对请求数据格式校验 #分页 对获取到的数据进行分页处理, pagination_class #解析器 选择对数据解析的类,在解析器类中注册(parser_classes) #渲染器 定义数据如何渲染到到页面上,在渲染器类中注册(renderer_classes)
使用
app注册
服务端会根据访问者使用工具的不同来区分,如果不添加rest_framework,使用postman等工具访问是没有问题的,但是使用浏览器访问会报错,因为会默认找到rest_framework下的静态html文件进行渲染,此时找不到,因此报错。


INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'rest_framework' ]
路由
from django.conf.urls import url from django.contrib import admin from api import views urlpatterns = [ url(r'^drf/info/', views.DrfInfoView.as_view()), ]
视图
from rest_framework.views import APIView from rest_framework.response import Response class DrfInfoView(APIView): def get(self,request,*args,**kwargs): data = {"":""} return Response(data)
自定义序列化
路由
from django.conf.urls import url from django.contrib import admin from api import views urlpatterns = [ url(r'^drf/category/$', views.DrfCategoryView.as_view()), #get/post通过此url url(r'^drf/category/(?P<pk>\d+)/$', views.DrfCategoryView.as_view()), #put/patch/delete通过此url ]
视图
from api import models from django.forms.models import model_to_dict #序列化,将model转为dict类型 class DrfCategoryView(APIView): def get(self,request,*args,**kwargs): """获取所有文章分类/单个文章分类""" pk = kwargs.get('pk') if not pk: queryset = models.Category.objects.all().values('id','name') data_list = list(queryset) return Response(data_list) else: category_object = models.Category.objects.filter(id=pk).first() data = model_to_dict(category_object) return Response(data) def post(self,request,*args,**kwargs): """增加一条分类信息""" models.Category.objects.create(**request.data) return Response('成功')
三.drf序列化
https://www.cnblogs.com/wuzhengzheng/p/10411785.html
序列化器作用
1.进行数据的校验 2.对数据对象进行转换 3.减少代码量,提高编码效率
序列化
将模型转为json称为序列化(对象->字典->json),fields是根本。
-序列化时instance=queryset,反序列化data参数写为data=request.data
-进行序列化时,会将fields中所有字段进行序列化,就是将fields中字段转为serial类中的特定字段,反序列化时,也需要提交fields中的所有字段,如果不想提交某些字段,使用read_only参数。
-在添加数据(post)请求时,可以新建一个serializer,可能有一些不需要的字段。
source:可以指定字段(name publish.name),可以指定方法,外键可用。
SerializerMethodField搭配方法使用(get_字段名字)
read_only:反序列化时,前端不用传此字段到后端
write_only:序列化时,后端不会将此字段传到前端
from django.conf.urls import url from django.contrib import admin from api import views urlpatterns = [ url(r'^new/category/$', views.NewCategoryView.as_view()), url(r'^new/category/(?P<pk>\d+)/$', views.NewCategoryView.as_view()), ]
# ModelSerializer跟表模型绑定序列化 from app import models class BookSerializer(serializers.ModelSerializer): class Meta: # 指定表模型 model = models.Book # 序列化所有的字段 fields = '__all__' # 只想序列化title和id两个字段 # fields = ['title','id'] # exclude 和 fields不要连用 # excude = ['title] # depth深度,表示链表的深度 #不建议使用:下几层要取得参数不能控制,官方建议不要超过10,个人建议不超过3 # depth = 1 # publish = serializers.CharField(source='publish.name') # authors = serializers.SerializerMethodField() # def get_authors(self, obj): # author_list = obj.authors.all() # author_ser = AuthorSer(instance=author_list, many=True) # return author_ser.data #为书名增加自定义需求 title = serializers.CharField(max_length=6,min_length=3,error_messages={'max_length':'太长了'}) #也有局部钩子函数 def validate_title(self,value): from rest_framework import exceptions print(value) if value.startswith('tmd'): raise exceptions.ValidationError('不能以tmd开头') return value
1.要显示当前models之外的字段给前端,用seriamethodfield,此字段是只读字段,前端不用传
2.要跨表查看其他表中的字段,或者显示models.CharField(choice=((1,"发布"),(2,"删除")),三个方式
class ArticleSerializer(serializers.ModelSerializer): #方式一:设置跨表深度 depth=1 #方式二:指定source category = serializers.CharField(source="category.name") status = serializers.CharField(source="get_status_display") #方式三,使用钩子,和下面get_tags_txt结合使用 tags_txt = serializers.SerializerMethodField(read_only=True) class Meta: model = models.Article fields = ["id","title","summary","content","category","status","tags_txt"] def get_tags_txt(self,obj): #obj为表对象 tag_list = [] for i in obj.tags.all(): tag_list.append({"id":i.id,"name":i.name}) return tag_list
#查询
class ArticleView(APIView): def get(self,request,*args,**kwargs): pk = kwargs.get("pk") if not pk: queryset = models.Article.objects.all() ser = ArticleSerializer(instance=queryset,many=True) #查询多个,many=True return Response(ser.data) else: queryset = models.Article.objects.filter(id=pk).first() ser = ArticleSerializer(instance=queryset,many=False) #查询一个,many=False return Response(ser.data)
#新增
def post(self,request,*args,**kwargs): ser = ArticleSerializer(data=request.data) if ser.is_valid(): ser.save() return Response("添加成功!") return Response(ser.errors)
def post(self,request,*args,**kwargs): ser = ArticleSerializer(data=request.data) ser_detail = ArticleDetailSerializer(data=request.data) if ser.is_valid() and ser_detail.is_valid(): #前端提交时没有author_id字段,在save时才添加,此处针对连表添加 article_object = ser.save(author_id=1) ser_detail.save(article=article_object) return Response('添加成功') return Response('错误')
#修改
def put(self,request,*args,**kwargs): pk = kwargs.get("pk") article_object = models.Article.objects.filter(id=pk).first() ser = ArticleSerializer(instance=article_object,data=request.data) #局部更新添加partial=True,所有要反序列化的字段都不是必填的 if ser.is_valid(): ser.save() return Response(ser.data) return Response(ser.errors)
反序列化
将json转为模型称为反序列化(json->字典->对象)
在自己定义的类中重写create方法
class BookSerializer(serializers.Serializer): ... ... def create(self, validated_data): res = models.Book.objects.create(**validated_data) return res
对应的view.py
class Books(APIView): # 使用继承了Serializers序列化类的对象,反序列化 def post(self,request): response_dic = {'code': 100, 'msg': '添加成功!'} # 实例化产生一个序列化类的对象,data是要反序列化的字典 booker = BookSerializer(data=request.data) if booker.is_valid(): # 清洗通过的数据,通过create方法进行保存 res = booker.create(booker.validated_data) return Response(response_dic)
四.分页
drf默认集成了几个分页类
from rest_framework.pagination import BasePagination,PageNumberPagination,LimitOffsetPagination,CursorPagination
自己写类继承这些,只需要配置某些参数
class GoodsPagination(PageNumberPagination): """ 分页 """ page_size = 10 page_size_query_param = 'page_size' page_query_param = 'page' max_page_size = 100
1.PageNumberPagination
url访问
http:127.0.0.1:8000/?page=1
配置settings.py,在配置drf组件都要写在REST_FRAMEWORK字典中
REST_FRAMEWORK = { "PAGE_SIZE":2 }
views中视图函数
def get(self,request,*args,**kwargs): queryset = models.Article.objects.all() # 方式一:仅数据 """ page_object = PageNumberPagination() result = page_object.paginate_queryset(queryset,request,self) ser = PageArticleSerializer(instance=result,many=True) return Response(ser.data) """ # 方式二:数据 + 分页信息 """ page_object = PageNumberPagination() result = page_object.paginate_queryset(queryset, request, self) ser = PageArticleSerializer(instance=result, many=True) return page_object.get_paginated_response(ser.data) """ # 方式三:数据 + 部分分页信息 """ page_object = PageNumberPagination() result = page_object.paginate_queryset(queryset, request, self) ser = PageArticleSerializer(instance=result, many=True) return Response({'count':page_object.page.paginator.count,'result':ser.data}) """ return Response(ser.data)
1.settings中配置(全局配置) REST_FRAMEWORK = { "DEFAULT_PAGINATION_CLASS":"rest_framework.pagination.PageNumberPagination", #默认使用PagenumberPagination "PAGE_SIZE":2, #每页显示数量 } 2.views.py中(局部配置)如果全局配置了此处不用 from rest_framework.pagination import PageNumberPagination class ArticleView(ListAPIView,CreateAPIView): queryset = models.Article.objects.all() serializer_class = ArticleSerials pagination_class = PageNumberPagination 继承自ListAPIView
2.LimitOffffsetPagination
url访问
http://127.0.0.1:8000/?limit=4&offset=0
views视图
from rest_framework.pagination import PageNumberPagination from rest_framework.pagination import LimitOffsetPagination from rest_framework import serializers class HulaLimitOffsetPagination(LimitOffsetPagination): max_limit = 2 class PageArticleView(APIView): def get(self,request,*args,**kwargs): queryset = models.Article.objects.all() page_object = HulaLimitOffsetPagination() result = page_object.paginate_queryset(queryset, request, self) ser = PageArticleSerializer(instance=result, many=True) return Response(ser.data)
五.筛选
url访问
https://www.cnblogs.com/article/?category=1
自定义筛选功能MyFilterBackend
from django.shortcuts import render from rest_framework.views import APIView from rest_framework.response import Response from . import models from rest_framework.filters import BaseFilterBackend class MyFilterBackend(BaseFilterBackend): #继承BaseFilterBackend,是约束作用 def filter_queryset(self, request, queryset, view): val = request.query_params.get('cagetory') return queryset.filter(category_id=val)
应用
class IndexView(APIView): def get(self, request, *args,**kwargs): # http://www.xx.com/cx/index/?category=1 # models.News.objects.filter(category=1) # http://www.xx.com/cx/index/?category=1 queryset = models.News.objects.all() obj = MyFilterBackend() result = obj.filter_queryset(request,queryset,self) print(result) return Response('...')
#views.py中 from rest_framework.filters import BaseFilterBackend #自定义筛选器 class MyFilterBackend(BaseFilterBackend): def filter_queryset(self, request, queryset, view): val = request.query_params.get("category") return queryset.filter(category=val) #视图 class ArticleView(ListAPIView,CreateAPIView): queryset = models.Article.objects.all() serializer_class = ArticleSerials filter_backends = [MyFilterBackend,]
六.视图
2个视图基类
传入到视图方法中的是REST framework的Request对象,而不是Django的HttpRequeset对象;
视图方法可以返回REST framework的Response对象,视图会为响应数据设置(render)符合前端要求的格式;
任何APIException异常都会被捕获到,并且处理成合适的响应信息;
在进行dispatch()分发前,会对请求进行身份认证、权限检查、流量控制。
支持定义的类属性:
authentication_classes 列表或元祖,身份认证类
permissoin_classes 列表或元祖,权限检查类
throttle_classes 列表或元祖,流量控制类
在APIView中仍以常规的类视图定义方法来实现get() 、post() 或者其他请求方式的方法。
from rest_framework.views import APIView from rest_framework.response import Response # url(r'^students/$', views.StudentsAPIView.as_view()), class StudentsAPIView(APIView): def get(self, request): data_list = Student.objects.all() serializer = StudentModelSerializer(instance=data_list, many=True) return Response(serializer.data)
2.
serializer_class 指明视图使用的序列化器
queryset 指明使用的数据查询集
pagination_class 指明分页控制类
filter_backends 指明过滤控制后端
支持的方法:
get_serializer_class(self) 当出现一个视图类中调用多个序列化器时,那么可以通过条件判断在get_serializer_class方法中通过返回不同的序列化器类名就可以让视图方法执行不同的序列化器对象了 get_serializer(self, args, *kwargs) 返回序列化器对象,主要用来提供给Mixin扩展类使用,如果我们在视图中想要获取序列化器对象,也可以直接调用此方法。 get_queryset(self) 返回视图使用的查询集,主要用来提供给Mixin扩展类使用,是列表视图与详情视图获取数据的基础,默认返回queryset属性 get_object(self) 返回详情视图所需的模型类数据对象,主要用来提供给Mixin扩展类使用
5个视图扩展类
ListModelMixin 列表视图扩展类,提供list(request, *args, **kwargs)方法快速实现列表视图返回200状态码。 该Mixin的list方法会对数据进行过滤和分页 CreateModelMixin 创建视图扩展类,提供create(request, *args, **kwargs)方法快速实现创建资源的视图,成功返回201状态码。 如果序列化器对前端发送的数据验证失败,返回400错误。 RetrieveModelMixin 详情视图扩展类,提供retrieve(request, *args, **kwargs)方法,可以快速实现返回一个存在的数据对象。 如果存在,返回200, 否则返回404 UpdateModelMixin 更新视图扩展类,提供update(request, *args, **kwargs)方法,可以快速实现更新一个存在的数据对象。 同时也提供partial_update(request, *args, **kwargs)方法,可以实现局部更新。 成功返回200,序列化器校验数据失败时,返回400错误 DestroyModelMixin 删除视图扩展类,提供destroy(request, *args, **kwargs)方法,可以快速实现删除一个存在的数据对象。 成功返回204,不存在返回404。
GenericAPIView的视图子类
CreateAPIView
提供 post 方法
继承自: GenericAPIView、CreateModelMixin
ListAPIView
提供 get 方法
继承自:GenericAPIView、ListModelMixin
RetrieveAPIView
提供 get 方法
继承自: GenericAPIView、RetrieveModelMixin
DestoryAPIView
提供 delete 方法
继承自:GenericAPIView、DestoryModelMixin
UpdateAPIView
提供 put 和 patch 方法
继承自:GenericAPIView、UpdateModelMixin
RetrieveUpdateAPIView
提供 get、put、patch方法
继承自: GenericAPIView、RetrieveModelMixin、UpdateModelMixin
ListAPIView #查询(内含get请求) CreateAPIView #创建(内含post请求) RetrieveAPIView #单条查询 UpdateAPIView #更新 DestroyAPIView #删除
整体流程
1.发送get请求,会调用ListAPIView中的get方法 2.执行list方法,先去ArticleView中找,找不到,直到找到父类ListModelMixin中的list方法 3.queryset = self.filter_queryset(self.get_queryset())先找ArticleView中的filter_queryset和get_queryset()方法,找不到,直到找到GenericAPIView中有这2中方式,get_queryset()中queryset = self.queryset,从ArticleView中找self.queryset,找不到报错,找到了将其queryset传给此类中的queryset变量,然后将其值返回给filter_querset方法,最后将filter_queryset的返回值赋值给3步中的queryset,在list方法中执行序列化
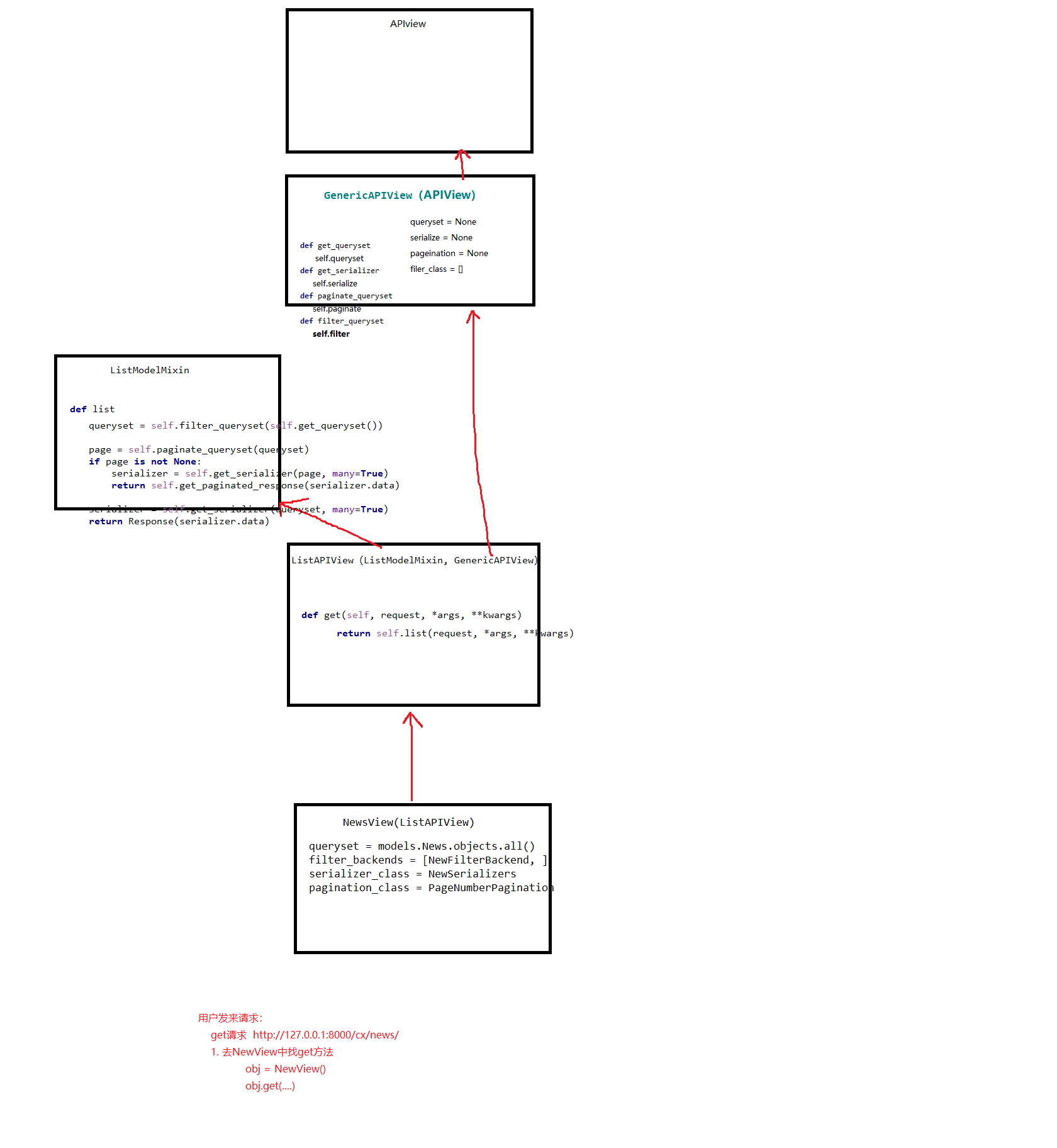
使用
class TagSer(serializers.ModelSerializer): class Meta: model = models.Tag fields = "__all__" class TagView(ListAPIView,CreateAPIView): queryset = models.Tag.objects.all() serializer_class = TagSer def get_serializer_class(self): #重写GenericAPIView中的方法 # self.request # self.args # self.kwargs if self.request.method == 'GET': return TagSer elif self.request.method == 'POST': return OtherTagSer def perform_create(self,serializer): serializer.save(author=1)
七.认证
django自带token认证
先来登录功能,登录成功后将随机字符串加入Userinfo表的token字段中
表
class UserInfo(models.Model): """ 用户表 """ username = models.CharField(verbose_name='用户名',max_length=32) password = models.CharField(verbose_name='密码',max_length=64) token = models.CharField(verbose_name='token',max_length=64,null=True,blank=True)
LoginView登录视图的实现
from rest_framework.views import APIView from rest_framework.response import Response from api import models import uuid class LoginView(APIView): """ 登录接口 """ def post(self,request,*args,**kwargs): user_obj = models.UserInfo.objects.filter(**request.data).first() if not user_obj: return Response("登录失败!") random_string = str(uuid.uuid4()) # 登录成功后将token添加到数据库,且返回给前端 user_obj.token = random_string user_obj.save() return Response(random_string)
在之后写的其他视图函数中,某些视图函数需要验证用户是否登录,就用到drf提供的BaseAuthentication认证功能。
先来单独写认证组件,需要用到的视图函数直接调用即可
from rest_framework.authentication import BaseAuthentication from api import models class LuffyAuthentication(BaseAuthentication): def authenticate(self, request): token = request.query_params.get("token") if not token: return (None,None) user_obj = models.UserInfo.objects.filter(token=token).first() if user_obj: return (user_obj,token) #参数一给request.user,参数二给request.auth return (None,None)
需要用到认证功能的函数如下,调用方式如下:
from rest_framework.views import APIView from rest_framework.response import Response from api.extension.auth import LuffyAuthentication class CommentView(APIView): #authentication_classes = [] 在settings中设置了全局认证,但此处不需,只需设置为空列表即可 authentication_classes = [LuffyAuthentication,] def get(self,request,*args,**kwargs): print(request.user) #request.user得到user object对象,只有request.user才会调用认证 print(request.auth) #得到token值 return Response("获取所有评论") def post(self,request,*args,**kwargs): if request.user: pass
如果你有100个视图想要用认证组件,就需要在全局settings.py中设置了
REST_FRAMEWORK = { "DEFAULT_AUTHENTICATION_CLASSES":["api.extension.auth.LuffyAuthentication",] }
源码分析(从认证功能函数开始)
1.当有请求发来时,会先执行APIView中的dispath方法,dispath方法中会执行initialize_request(request, *args, **kwargs),进行老的request的封装。在封装过程中authenticators=self.get_authenticators(),此时执行get_authenticators(),进去此方法会看到return [auth() for auth in self.authentication_classes],因为自己写的类中有authentication_class变量,此时authenticators=[LuffyAuthentication(),] 2. 当执行到get函数时,也是先进APIView的dispatch()方法,然后进入request的封装函数中,查询def user(self)方法,找到其中的self._authenticate()方法并执行,可以看到 user_auth_tuple = authenticator.authenticate(self),执行自己定义组件中的authenticate方法,返回(a,b)元组,然后self.user, self.auth = 此元组,从而得到request.user等于值1,request.auth等于值2
当用户发来请求时,找到认证的所有类并实例化成为对象列表,然后将对象列表封装到新的request对象中。
以后在视同中调用request.user
在内部会循环认证的对象列表,并执行每个对象的authenticate方法,该方法用于认证,他会返回两个值分别会赋值给
request.user/request.auth
jwt
相同域的2个不同的界面A,B,是两个不同的http请求,在cookie没有出来之前,访问A界面跟访问B没有任何关系,这就引入了cookie,cookie在同一个域名下是全局的,因此在一个界面下登录成功,在其他任何界面都可
以获取其登录成功状态。但是因为cookie存在于客户端、不安全,存储位置又小,这就引出了session。
session基于cookie,保存在服务端,当浏览器请求时,返回给浏览器一个sessionid存储在cookie中。
1.当系统采用分布式架构(一个微服务对应一个数据库,假设此时还是同域),此时如果用户登录了A系统,想不用再次输入账号密码就能进入B系统,还需要将A服务端的session信息同步到B,很费事,而且同步信息多了也会
造成服务端压力。
2.当系统采用分布式架构(此时非同域),就不用再用session了,因为是session是基于cookie来实现的。
综上2原因,引出了token认证,这里直接说jwt吧,保存在客户端,1是为了减少服务端压力,2是为解决跨域访问。但是其最大缺点就是服务端不保存会话状态
jwt的实现原理: - 用户登录成功之后,会给前端返回一段token。 - token是由.分割的三段组成。 - 第一段:类型和算法信心 - 第二段:用户信息+超时时间 - 第三段:hs256(前两段拼接)加密 + base64url - 以后前端再次发来信息时 - 超时验证 - token合法性校验 优势: - token只在前端保存,后端只负责校验。 - 内部集成了超时时间,后端可以根据时间进行校验是否超时。 - 由于内部存在hash256加密,所以用户不可以修改token,只要一修改就认证失败。
使用
app中注册
INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'api.apps.ApiConfig', 'rest_framework', 'rest_framework_jwt' ]
登录
from rest_framework.views import APIView from rest_framework.response import Response from rest_framework_jwt.settings import api_settings from api import models from rest_framework_jwt.views import VerifyJSONWebToken from rest_framework.throttling import AnonRateThrottle,BaseThrottle class LoginView(APIView): authentication_classes = [] def post(self,request,*args,**kwargs): user = models.UserInfo.objects.filter(username=request.data.get("username"),password=request.data.get("password")).first() if not user: return Response({"code":10001,"error":"用户名或密码错误"}) # jwt_payload_handler = api_settings.JWT_PAYLOAD_HANDLER payload = jwt_payload_handler(user) # jwt_encode_handler = api_settings.JWT_ENCODE_HANDLER token = jwt_encode_handler(payload) return Response({"code":10000,"data":token})
认证视图
import jwt from rest_framework import exceptions from rest_framework.authentication import BaseAuthentication from rest_framework_jwt.settings import api_settings from api import models class HulaQueryParamAuthentication(BaseAuthentication): def authenticate(self, request): """ # raise Exception(), 不在继续往下执行,直接返回给用户。 # return None ,本次认证完成,执行下一个认证 # return ('x',"x"),认证成功,不需要再继续执行其他认证了,继续往后权限、节流、视图函数 """ token = request.query_params.get('token') if not token: raise exceptions.AuthenticationFailed({'code':10002,'error':"登录成功之后才能操作"}) jwt_decode_handler = api_settings.JWT_DECODE_HANDLER try: payload = jwt_decode_handler(token) except jwt.ExpiredSignature: raise exceptions.AuthenticationFailed({'code':10003,'error':"token已过期"}) except jwt.DecodeError: raise exceptions.AuthenticationFailed({'code':10004,'error':"token格式错误"}) except jwt.InvalidTokenError: raise exceptions.AuthenticationFailed({'code':10005,'error':"认证失败"}) jwt_get_username_from_payload = api_settings.JWT_PAYLOAD_GET_USERNAME_HANDLER username = jwt_get_username_from_payload(payload) user_object = models.UserInfo.objects.filter(username=username).first() return (user_object,token)
settings配置(全局配置)
REST_FRAMEWORK = { "DEFAULT_AUTHENTICATION_CLASSES":["api.extension.auth.HulaQueryParamAuthentication"], }
如果不想使用此认证,在视图函数中添加以下代码
# def get_authenticators(self): # if self.request.method == "GET": # return [] # elif self.request.method == "POST": # return super().get_authenticators()
最新总结参考:https://www.jianshu.com/p/a399b98ab05b
如果引用自定义的jwt,不用设置playload_handler,obtain_jwt_token会默认根据settings.py中的AUTH_USER_MODEL对应的用户表查询用户名密码,如果前端发来的用户名密码匹配成功,返回正确的token,否则报400错。注意:此处默认传来的数据键值对{"username":"xx","password":"xx"}
八.权限
要用权限需要drf中的BasePermission类,先来自定义权限组件
from rest_framework.permissions import BasePermission from rest_framework import exceptions class MyPermission(BasePermission): message = {'code': 10001, 'error': '你没权限'} #has_permission返回false时会抛出此异常 def has_permission(self, request, view): #针对所有请求 if request.user: return True return False def has_object_permission(self, request, view, obj): #针对有pk值的请求(例RetrieveAPIView) return False
视图函数中使用上定义的权限组件
from rest_framework.views import APIView from rest_framework.response import Response from api.extension.permission import LuffyPermission class CommentView(APIView): permission_classes = [] #如果在settings设置了全局权限,但此视图不想使用 permission_classes = [LuffyPermission,] def get(self,request,*args,**kwargs): return Response("获取所有评论") def post(self,request,*args,**kwargs): if request.user: pass
settings配置全局权限
REST_FRAMEWORK = { DEFAULT_PERMISSION_CLASSES:"api.extension.permission.LuffyPermission" }
源码分析
class APIView(View): permission_classes = api_settings.DEFAULT_PERMISSION_CLASSES def dispatch(self, request, *args, **kwargs): #1执行dispath方法 #2 封装request对象 self.initial(request, *args, **kwargs) 通过反射执行视图中的方法 def initial(self, request, *args, **kwargs): # 权限判断 self.check_permissions(request) def check_permissions(self, request): # [对象,对象,] for permission in self.get_permissions(): if not permission.has_permission(request, self): self.permission_denied(request, message=getattr(permission, 'message', None)) def permission_denied(self, request, message=None): if request.authenticators and not request.successful_authenticator: raise exceptions.NotAuthenticated() raise exceptions.PermissionDenied(detail=message) def get_permissions(self): return [permission() for permission in self.permission_classes] class UserView(APIView): permission_classes = [MyPermission, ] def get(self,request,*args,**kwargs): return Response('user')
1.请求过来,先走APIView中的dispatch方法,执行self.initialize_request()方法进行老的request的封装,然后执行initial方法,进行认证和权限处理: self.perform_authentication(request) self.check_permissions(request) self.check_throttles(request) 2.进入check_permissions方法:for循环遍历自己定义的permission_classes,检查每个对象的has_permission()方法,如果返回false,抛出异常,返回true,继续通过反射执行dispatch方法中的请求分发 for permission in self.get_permissions(): if not permission.has_permission(request, self): self.permission_denied( request, message=getattr(permission, 'message', None) )
九.版本
使用思路
在视图类中配置 versioning_class =注意这是单数形式,只能配置一个类 实现 determine_version 方法 全局配置 DEFAULT_VERSION ALLOWED_VERSIONS VERSION_PARAM 在 initial 中首先执行 determine_version,它里面会生成获取版本的对象以及版本。 获取版本:request.version 获取处理版本的对象:request.versioning_scheme 反向生成 url :url = request.versioning_scheme.reverse(viewname='<url 的别名>', request=request)
使用(局部)
url中写version
url(r'^(?P<version>[v1|v2]+)/users/$', users_list, name='users-list'),
视图中应用
from rest_framework.views import APIView from rest_framework.response import Response from rest_framework.request import Request from rest_framework.versioning import URLPathVersioning class OrderView(APIView): versioning_class = URLPathVersioning def get(self,request,*args,**kwargs): print(request.version) print(request.versioning_scheme) return Response('...') def post(self,request,*args,**kwargs): return Response('post')
settings中配置
REST_FRAMEWORK = { "PAGE_SIZE":2, "DEFAULT_PAGINATION_CLASS":"rest_framework.pagination.PageNumberPagination", "ALLOWED_VERSIONS":['v1','v2'], #允许的版本 'VERSION_PARAM':'version' #默认参数 }
使用(全局)
url中写version
url(r'^(?P<version>[v1|v2]+)/users/$', users_list, name='users-list'), url(r'^(?P<version>\w+)/users/$', users_list, name='users-list'),
视图中应用
from rest_framework.views import APIView from rest_framework.response import Response from rest_framework.request import Request from rest_framework.versioning import URLPathVersioning class OrderView(APIView): def get(self,request,*args,**kwargs): print(request.version) print(request.versioning_scheme) return Response('...') def post(self,request,*args,**kwargs): return Response('post')
settings配置
REST_FRAMEWORK = { "PAGE_SIZE":2, "DEFAULT_PAGINATION_CLASS":"rest_framework.pagination.PageNumberPagination", "DEFAULT_VERSIONING_CLASS":"rest_framework.versioning.URLPathVersioning", # "ALLOWED_VERSIONS":['v1','v2'], 'VERSION_PARAM':'version' }
十.频率限制
如何实现频率限制
匿名用户:用ip作为唯一标记(缺点:如果用户使用代理ip,无法做到真正的限制)
登录用户:用用户名或者id作为标识
具体实现
首先,django会在缓存中生成如下数据结构,用来存储用户访问的时间戳 throttle_匿名标识(anon)_用户ip:[时间戳1,时间戳2...] 每次用户登录时: 1.获取当前时间戳 2.当前时间戳-60(如3/60s,一分钟内3次),循环数据结构中时间戳B,将得到值A和B比较,B<A,则删除B 3.判断数据结构中列表的个数,如果小于3,则可以访问
使用
#settings配置: REST_FRAMEWORK={ "DEFAULT_THROTTLE_RATES":{ "anon":'3/m' #一分钟3次, 3/h 3/d } #"DEFAULT_THROTTLE_CLASSES":"rest_framework.throttling.AnonRateThrottle" #全局设置 } #views函数中使用 from rest_framework.throttling import AnonRateThrottle class ArticleView(APIView): #throttle_classes = [] throttle_classes = [AnonRateThrottle,]
源码剖析
请求发来,先执行dispatch方法,从dispatch方法中进入inital函数。先后执行到check_throttles()方法,在此看到,会执行对象的allow_request()方法 def initial(self, request, *args, **kwargs): self.perform_authentication(request) self.check_permissions(request) self.check_throttles(request) def check_throttles(self, request): throttle_durations = [] for throttle in self.get_throttles(): if not throttle.allow_request(request, self): throttle_durations.append(throttle.wait()) def allow_request(self, request, view): if self.rate is None: return True # 获取请求用户的ip self.key = self.get_cache_key(request, view) if self.key is None: return True # 根据ip获取所有访问记录,得到的一个列表 self.history = self.cache.get(self.key, []) self.now = self.timer() # Drop any requests from the history which have now passed the # throttle duration while self.history and self.history[-1] <= self.now - self.duration: self.history.pop() if len(self.history) >= self.num_requests: #num_requests自己规定的访问次数 return self.throttle_failure() return self.throttle_success()
组件参考:https://www.jianshu.com/p/c16f8786e9f7

 浙公网安备 33010602011771号
浙公网安备 33010602011771号