kafka
Kafka学习笔记_day01
适用场景:大数据场景
消息队列模式
点对点模式
消费者主动拉取数据,消息收到以后清除消息
发布/订阅模式
可以存在多个Topic主题
消费者消费完数据以后,不删除数据
每个消费者相互独立,都可以消费到数据
基础架构
内部将一个Topic(主题)分为了多个partition(分区),并配合分区的设计,在消费者端设计了消费者组的概念,组内的每个消费者并行消费,也就是说同一个组里的消费者不能同时消费同一个分区内的消息。
为了提高可用性,为每一个partition增加了若干个副本,即存在Leader和Follower,所有的消息的生产和消费都是基于Leader进行的,当Leader挂掉以后,将选举出新的Leader。
快速入门Kafka
kafka的官网下载地址:https://kafka.apache.org/downloads.html
1)解压下载的tar包:
tar -zxvf xxxx.tgz -C 复制的目录
2)修改解压后的文件名称:
mv kafka_2.12-3.0.0/ kafka
3)进入到kafka的目录下,里面存在三个重要配置的配置文件
server.properties
producer.properties
consumer.properties
其中,对于server.properties配置文件进行修改:

#broker.id 为每一个kafka的唯一标识,不能重复 broker.id = 0 #kafka运行日志(数据)存放的路径,路径不需要重新创建,配置好kafka会自动帮你创建,可以配置多个磁盘路径,路径与路径之间可以用","分隔 log.dirs=opt/module/kafka/datas #配置连接Zookeeper的集群地址(ps:在zk的根目录下创建/kafka目录,方便进行管理) zookeeper.connect= 服务器1:2181,服务器2:2181,服务器3:2181/kafka #其他参数 #处理网络请求的线程数量 num.network.threads=3 #用来处理磁盘 IO 的线程数量 num.io.threads=8 #发送套接字的缓冲区大小 socket.send.buffer.bytes=102400 #接收套接字的缓冲区大小 socket.receive.buffer.bytes=102400 #请求套接字的缓冲区大小 socket.request.max.bytes=104857600 #topic 在当前 broker 上的分区个数 num.partitions=1 #用来恢复和清理 data 下数据的线程数量 num.recovery.threads.per.data.dir=1 # 每个 topic 创建时的副本数,默认时 1 个副本 offsets.topic.replication.factor=1 #segment 文件保留的最长时间,超时将被删除 log.retention.hours=168 #每个 segment 文件的大小,默认最大 1G log.segment.bytes=1073741824 # 检查过期数据的时间,默认 5 分钟检查一次是否数据过期 log.retention.check.interval.ms=300000
配置完毕以后进入其他服务器进行kafka的分发安装包工作,同时按照上述操作修改其broker.id值,保持其唯一性
#使用脚本xsync进行分发操作
xsync kafka/
4)配置环境变量
在/etc/profile.d/my_env.sh文件中增加kafka环境变量的配置:
vim /etc/profile.d/my_env.sh
添加以下关于Kafka的环境信息:
# KAFKA_HOME export KAFKA_HOME=/opt/module/kafka export PATH=$PATH:$KAFKA_HOME/bin
配置完成以后,进行环境变量的刷新工作
source /etc/profile
同时将环境变量的配置分发到其他节点中,并进行source操作:
xsync /etc/profile.d/my_env.sh
source /etc/profile
此时,kafka的安装及配置工作基本完成。
注意:上面使用的xsnc脚本:
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104[你的集群服务器名称]
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
5)启动Kafka
启动kafka之前,需要先启动Zookeeper集群服务。
#使用zk.sh脚本启动zookeeper集群
zk.sh start
#zk.sh脚本
case $1 in "start"){ for i in hadoop102 hadoop103 hadoop104[服务器名称] do echo ------------- zookeeper $i 启动 ------------ ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh start" done } ;;
"stop"){ for i in hadoop102 hadoop103 hadoop104 do echo ------------- zookeeper $i 停止 ------------ ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh stop" done } ;;
"status"){ for i in hadoop102 hadoop103 hadoop104 do echo ------------- zookeeper $i 状态 ------------ ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh status" done } ;;
esac
依次在集群服务器节点启动kafka:
#先进入到kafka根目录
bin/kafka-server-start.sh -daemon config/server.properties
启动/停止脚本
开发/生产环境中,手动启动kafka集群效率较低,一般编写启动/停止脚本来进行kafka集群的统一启动和关闭。无论是启动还是停止命令,对应的命令路劲均为绝对路径,而非相对路径
#! /bin/bash case $1 in "start"){ for i in hadoop102 hadoop103 hadoop104[服务器名称] do echo " --------启动 $i Kafka-------" ssh $i "/opt/module/kafka/bin/kafka-server-start.sh - daemon /opt/module/kafka/config/server.properties" done };; "stop"){ for i in hadoop102 hadoop103 hadoop104 do echo " --------停止 $i Kafka-------" ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh " done };; esac
注意:
关闭kafka命令到所有的kafka集群关闭成功提示存在一定的时间差,一定要等kafka集群全部关闭完毕以后,再进行Zookeeper集群的关闭操作!!!
Topic命令
操作主题命令参数
bin/kafka-topics.sh
其中,具体包括主题的CRUD操作:
参数 描述
–bootstrap-server <String: server toconnect to> 连接的Kafka Broker主机名称和端口号
–topic <String: topic> 操作的topic名称
–create 创建主题
–delete 删除主题
–alter 修改主题
–list 查看所有主题
–describe 查看主题的详细描述
–partitons 设置分区数
–replication-factor 设置分区的副本数
–config 更新系统默认的配置
Kafka之生产者
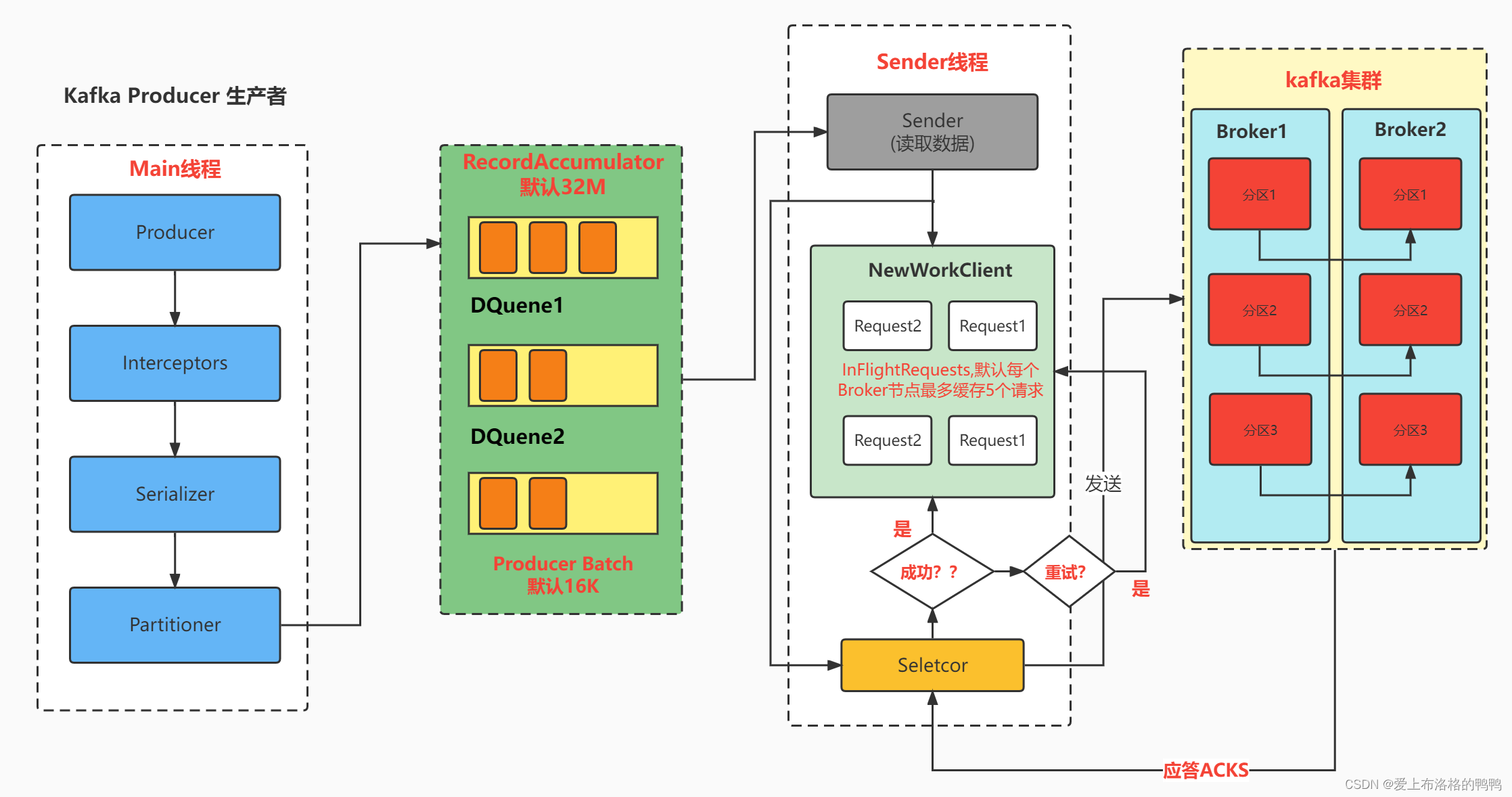
生产者消息发送流程
在消息发送过程中,存在着两个线程:
Main线程:将消息发送给RecordAccumulator的队列中
Sender线程:从RecordAccumulator的队列中拉取消息发送到Kafka Broker
具体流程图:
其中:
RecordAccumulator的默认存储大小为32M,内部每一个消息队列的默认大小为16K。只有当队列的数据达到batch.size以后,sender才会拉取对应的消息,默认batch.size大小为16k;同时,如果数据未达到batch.size,但是sender线程等待时间达到linger.ms时也会发送消息到sender线程。
Sender线程中的请求时基于Kafka节点(Broker)的,每个broker节点上默认最多缓存5个请求,Selector则构成请求的IO通道,当请求通过Selector选择器到达Kafka集群,进行对应的消息处理,处理完成后会给予对应的acks(应答),这里存在三种应答策略:
0:表示生产者发送过来的数据,不需要等数据落盘,直接给予应答
1:生产者发送过来的数据,只要Leader收到数据即应答
-1(all):生产者发送过来的数据,Leader和ISR队列里面的所有节点收齐数据后应答。
如果应答成功,则需要删除Sender中的对应请求,同时删除对应队列中的请求;若应答失败,可以进行重试机制
异步发送
依赖添加:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.0.0</version>
</dependency>
创建一个CustomProducer进行消息的生产:
import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; import java.util.Properties; public class CustomProducer { public static void main(String[] args) throws InterruptedException { // 1. 创建 kafka 生产者的配置对象 Properties properties = new Properties(); // 2. 给 kafka 配置对象添加配置信息:bootstrap.servers properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092"); // key,value 序列化(必须):key.serializer,value.serializer properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer"); // 3. 创建 kafka 生产者对象 KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties); // 4. 调用 send 方法,发送消息 for (int i = 0; i < 5; i++) { kafkaProducer.send(new ProducerRecord<>("first","message " + i)); } // 5. 关闭资源 kafkaProducer.close(); } }
异步发送带回调函数
回调函数会在 producer 收到 ack 时调用,为异步调用,该方法有两个参数,分别是元 数据信息(RecordMetadata)和异常信息(Exception),如果 Exception 为 null,说明消息发 送成功,如果 Exception 不为 null,说明消息发送失败。
在send方法中添加回调逻辑:
kafkaProducer.send(new ProducerRecord<>("first", "message " + i), new Callback() { // 该方法在 Producer 收到 ack 时调用,为异步调用 @Override public void onCompletion(RecordMetadata metadata, Exception exception) { if (exception == null) { // 没有异常,输出信息到控制台 System.out.println(" 主题: " + metadata.topic() + "->" + "分区:" + metadata.partition()); } else { // 出现异常打印 exception.printStackTrace(); } } }); // 延迟一会会看到数据发往不同分区 Thread.sleep(2); }
同步发送
只需要在异步发送的基础上调用一个get()方法即可
kafkaProducer.send(new ProducerRecord<>("first","message" + i)).get();


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!
2022-09-14 查看NFS连接了哪些客户端 获取客户端的IP地址
2022-09-14 k8s pod 重启
2017-09-14 linux大小写转换
2017-09-14 find 命令一个命令多参数如何使用,????,perm
2017-09-14 find 下参数的关系默认是and 一个参数多个选项可以用 -or
2017-09-14 history统计命令最多的20条
2017-09-14 第一关练习题统计网站最大访问量sed法,隐藏知识数组下标不能重复