深入Lucene索引机制
2006 年 7 月 13 日
Lucene 是一个基于 Java 的全文检索工具包,你可以利用它来为你的应用程序加入索引和检索功能。Lucene 目前是著名的 Apache Jakarta 家族中的一个开源项目,下面我们即将学习 Lucene 的索引机制以及它的索引文件的结构。
在这篇文章中,我们首先演示如何使用 Lucene 来索引文档,接着讨论如何提高索引的性能。最后我们来分析 Lucene 的索引文件结构。需要记住的是,Lucene 不是一个完整的应用程序,而是一个信息检索包,它方便你为你的应用程序添加索引和搜索功能。
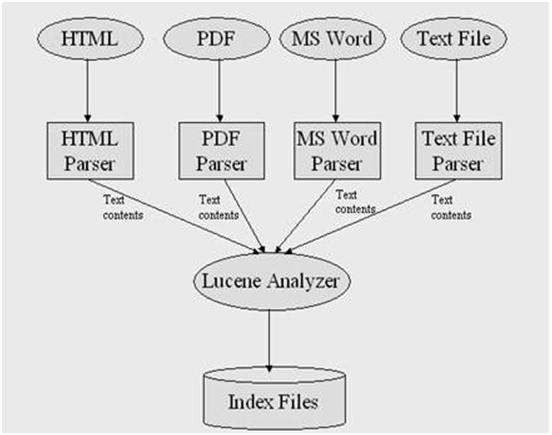



首先把一些以 txt 为后缀名的文本文件放到一个目录中,比如在 Windows 平台上,你可以放到 C:\\files_to_index 下面。
package lucene.index;
import java.io.File; import java.io.FileReader; import java.io.Reader; import java.util.Date;
import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field; import org.apache.lucene.index.IndexWriter;
/** * This class demonstrates the process of creating an index with Lucene * for text files in a directory. */ public class TextFileIndexer { public static void main(String[] args) throws Exception{ //fileDir is the directory that contains the text files to be indexed File fileDir = new File("C:\\files_to_index ");
//indexDir is the directory that hosts Lucene's index files File indexDir = new File("C:\\luceneIndex"); Analyzer luceneAnalyzer = new StandardAnalyzer(); IndexWriter indexWriter = new IndexWriter(indexDir,luceneAnalyzer,true); File[] textFiles = fileDir.listFiles(); long startTime = new Date().getTime();
//Add documents to the index for(int i = 0; i < textFiles.length; i++){ if(textFiles[i].isFile() >> textFiles[i].getName().endsWith(".txt")){ System.out.println("File " + textFiles[i].getCanonicalPath() + " is being indexed"); Reader textReader = new FileReader(textFiles[i]); Document document = new Document(); document.add(Field.Text("content",textReader)); document.add(Field.Text("path",textFiles[i].getPath())); indexWriter.addDocument(document); } }
indexWriter.optimize(); indexWriter.close(); long endTime = new Date().getTime();
System.out.println("It took " + (endTime - startTime) + " milliseconds to create an index for the files in the directory " + fileDir.getPath()); } } |
正如清单1所示,你可以利用 Lucene 非常方便的为文档创建索引。接下来我们分析一下清单1中的比较关键的代码,我们先从下面的一条语句开始看起。
Analyzer luceneAnalyzer = new StandardAnalyzer(); |
IndexWriter indexWriter = new IndexWriter(indexDir,luceneAnalyzer,true); |
Document document = new Document(); document.add(Field.Text("content",textReader)); document.add(Field.Text("path",textFiles[i].getPath())); indexWriter.addDocument(document); |
当我们把文档添加到索引中后,不要忘记关闭索引,这样才保证 Lucene 把添加的文档写回到硬盘上。下面的一句代码演示了如何关闭索引。
indexWriter.close(); |
利用清单1中的代码,你就可以成功的将文本文档添加到索引中去。接下来我们看看对索引进行的另外一种重要的操作,从索引中删除文档。




类IndexReader负责从一个已经存在的索引中删除文档,如清单2所示。
File indexDir = new File("C:\\luceneIndex"); IndexReader ir = IndexReader.open(indexDir); ir.delete(1); ir.delete(new Term("path","C:\\file_to_index\lucene.txt")); ir.close(); |
File indexDir = new File("C:\\luceneIndex"); IndexReader ir = IndexReader.open(indexDir); ir.undeleteAll(); ir.close(); |
你现在也许想知道如何物理上删除索引中的文档,方法也非常简单。清单 4 演示了这个过程。
File indexDir = new File("C:\\luceneIndex"); Analyzer luceneAnalyzer = new StandardAnalyzer(); IndexWriter indexWriter = new IndexWriter(indexDir,luceneAnalyzer,false); indexWriter.optimize(); indexWriter.close(); |
在清单 4 中,第三行创建了类 IndexWriter 的一个实例,并且打开了一个已经存在的索引。第 4 行对索引进行清理,清理过程中将把所有标记为删除的文档物理删除。
Lucene 没有直接提供方法对文档进行更新,如果你需要更新一个文档,那么你首先需要把这个文档从索引中删除,然后把新版本的文档加入到索引中去。




这个参数也会影响索引的性能。它决定了内存中的文档数至少达到多少才能将它们写回磁盘。这个参数的默认值是10,如果你有足够的内存,那么将这个值尽量设的比较大一些将会显著的提高索引性能。
清单 5 列出了这个三个参数用法,清单 5 和清单 1 非常相似,除了清单 5 中会设置刚才提到的三个参数。
/** * This class demonstrates how to improve the indexing performance * by adjusting the parameters provided by IndexWriter. */ public class AdvancedTextFileIndexer { public static void main(String[] args) throws Exception{ //fileDir is the directory that contains the text files to be indexed File fileDir = new File("C:\\files_to_index");
//indexDir is the directory that hosts Lucene's index files File indexDir = new File("C:\\luceneIndex"); Analyzer luceneAnalyzer = new StandardAnalyzer(); File[] textFiles = fileDir.listFiles(); long startTime = new Date().getTime();
int mergeFactor = 10; int minMergeDocs = 10; int maxMergeDocs = Integer.MAX_VALUE; IndexWriter indexWriter = new IndexWriter(indexDir,luceneAnalyzer,true); indexWriter.mergeFactor = mergeFactor; indexWriter.minMergeDocs = minMergeDocs; indexWriter.maxMergeDocs = maxMergeDocs;
//Add documents to the index for(int i = 0; i < textFiles.length; i++){ if(textFiles[i].isFile() >> textFiles[i].getName().endsWith(".txt")){ Reader textReader = new FileReader(textFiles[i]); Document document = new Document(); document.add(Field.Text("content",textReader)); document.add(Field.Keyword("path",textFiles[i].getPath())); indexWriter.addDocument(document); } }
indexWriter.optimize(); indexWriter.close(); long endTime = new Date().getTime();
System.out.println("MergeFactor: " + indexWriter.mergeFactor); System.out.println("MinMergeDocs: " + indexWriter.minMergeDocs); System.out.println("MaxMergeDocs: " + indexWriter.maxMergeDocs); System.out.println("Document number: " + textFiles.length); System.out.println("Time consumed: " + (endTime - startTime) + " milliseconds"); } } |
int mergeFactor = 10; int minMergeDocs = 10; int maxMergeDocs = Integer.MAX_VALUE; IndexWriter indexWriter = new IndexWriter(indexDir,luceneAnalyzer,true); indexWriter.mergeFactor = mergeFactor; indexWriter.minMergeDocs = minMergeDocs; indexWriter.maxMergeDocs = maxMergeDocs; |
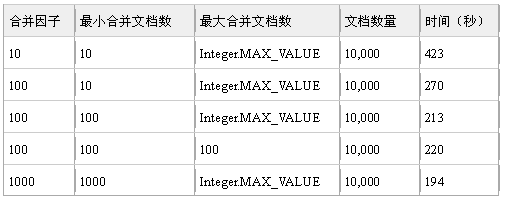
下面我们来看一下这三个参数取不同的值对索引时间的影响,注意参数值的不同和索引之间的关系。我们为这个实验准备了 10000 个测试文档。表 1 显示了测试结果。








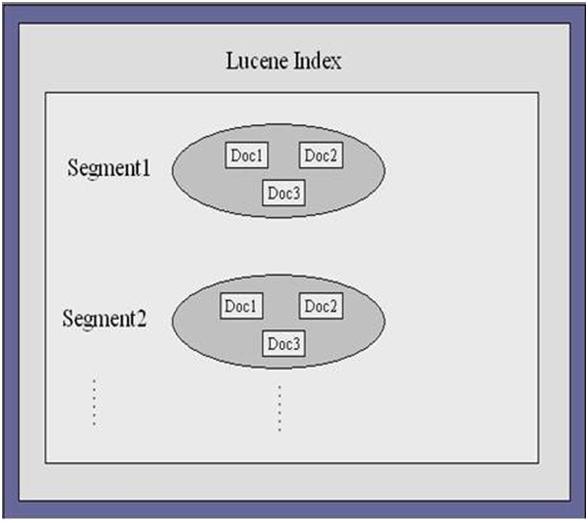




下面的部分将会分析Lucene中的主要的索引文件,可能分析有些索引文件的时候没有包含文件的所有的字段,但不会影响到对索引文件的理解。
这个文件包含了索引中的索引块信息,这个文件包含了每个索引块的名字以及大小等信息。表 2 显示了这个文件的结构信息。

我们知道,索引中的文档由一个或者多个域组成,这个文件包含了每个索引块中的域的信息。表 3 显示了这个文件的结构。

这是索引文件里面最核心的一个文件,它存储了所有的索引项的值以及相关信息,并且以索引项来排序。表 4 显示了这个文件的结构。


这个文件包含了索引项在每个文档中出现的位置信息,你可以利用这些信息来参与对索引结果的排序。表 6 显示了这个文件的结构