

结对编程作业
一、原型设计
| 分工 | ai算法 | 原型设计 | AI 与原型设计实现 | 博客编写 |
|---|---|---|---|---|
| 高逸超 | 70% | 20% | 80% | 30% |
| 吴仕涛 | 30% | 80% | 20% | 70% |
二、AI与原型设计实现
原型设计概述:
- 本次设计为一款简单可玩的数字华容道web小程序。设计目的:可为闲暇的用户打发打发时间,自动生成可解三阶数字华容道,同时可获得本次所需的分解打乱的字母进行复原。有可以查看历史得分,记录步数以及时间的功能。
-
页面设计说明:
- 开始页面和分数记录

- 游戏界面

- 原型工具: Axure,很简单的工具,原型设计基本功,很多人都是新学的,但是还挺得心应手的。原型设计出来但是实现怎么样只能看天命~~
- 结对照片

-
遇到的问题和解决方法
遇到的主要问题没有很大,主要还是沟通上的,想要的不一定能实现,沟通很久才有现在的效果
AI与原型设计实现
AI部分
流程图
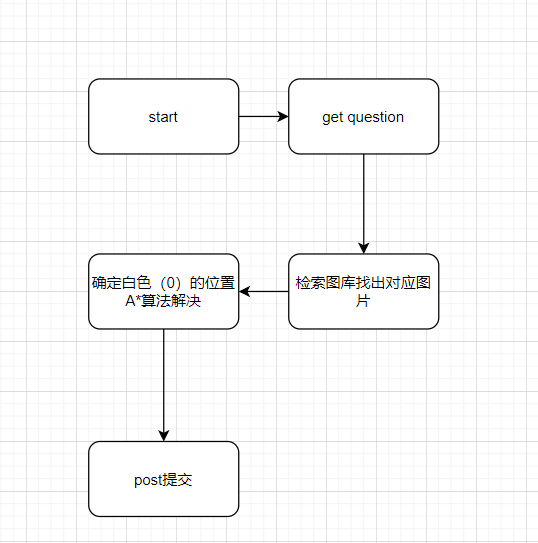
算法思路
一开始拿到这个题就想着识图分割然后编号三阶行列式bfs
但是思路很美好,完成的过程非常坎坷,只能说实力不行
核心算法介绍
A*
• 在全局择优搜索中,每当需要扩展节点时,总是从 Open 表的所有节点中选择一个估价函数值最小的节点进行扩展。其搜索过程可能描述如下:
• ( 1 )把初始节点 S0 放入 Open 表中, f(S0)=g(S0)+h(S0) ;
• ( 2 )如果 Open 表为空,则问题无解,失败退出;
• ( 3 )把 Open 表的第一个节点取出放入 Closed 表,并记该节点为 n ;
• ( 4 )考察节点 n 是否为目标节点。若是,则找到了问题的解,成功退出;
• ( 5 )若节点 n 不可扩展,则转到第 (2) 步;
• ( 6 )扩展节点 n ,生成子节点 ni ( i =1,2, …… ) ,计算每一个子节点的估价值 f( ni ) ( i =1,2, …… ) ,并为每一个子节点设置指向父节点的指针,然后将这些子节点放入 Open 表中;
• ( 7 )根据各节点的估价函数值,对 Open 表中的全部节点按从小到大的顺序重新进行排序;
• ( 8 )转第 (2) 步。
参考代码如下
#include<cstdio>
#include<queue>
#include<map>
using namespace std;
char arr[10],brr[10]="123804765";
struct node{
int num,step,cost,zeroPos;
bool operator<(const node &a)const{
return cost>a.cost;
}
node(int n,int s,int p){
num=n,step=s,zeroPos=p;
setCost();
}
void setCost(){
char a[10];
int c=0;
sprintf(a,"%09d",num);
for(int i=0;i<9;i++)
if(a[i]!=brr[i])
c++;
cost=c+step;
}
};
int des=123804765;
int changeId[9][4]={{-1,-1,3,1},{-1,0,4,2},{-1,1,5,-1},
{0,-1,6,4},{1,3,7,5},{2,4,8,-1},
{3,-1,-1,7},{4,6,-1,8},{5,7,-1,-1}};
map<int,bool>mymap;
priority_queue<node> que;//优先级队列
void swap(char* ch,int a,int b){char c=ch[a];ch[a]=ch[b];ch[b]=c;}
int bfsHash(int start,int zeroPos){
char temp[10];
node tempN(start,0,zeroPos);//创建一个节点
que.push(tempN);//压入优先级队列
mymap[start]=1;//标记开始节点被访问过
while(!que.empty()){
tempN=que.top();
que.pop();//弹出一个节点
sprintf(temp,"%09d",tempN.num);
int pos=tempN.zeroPos,k;
for(int i=0;i<4;i++){
if(changeId[pos][i]!=-1){
swap(temp,pos,changeId[pos][i]);
sscanf(temp,"%d",&k);
if(k==des)return tempN.step+1;
if(mymap.count(k)==0){
node tempM(k,tempN.step+1,changeId[pos][i]);
que.push(tempM);//创建一个新节点并压入队列
mymap[k]=1;
}
swap(temp,pos,changeId[pos][i]);
}
}
}
}
int main(){
int n,k,b;
scanf("%s",arr);
for(k=0;k<9;k++)
if(arr[k]=='0')break;
sscanf(arr,"%d",&n);
b=bfsHash(n,k);
printf("%d",b);
return 0;
}
我们自己的核心代码和上述很像
如下
import time as tm
g_dict_layouts = {}
g_dict_layouts_deep = {}
g_dict_layouts_fn = {}
g_dict_shifts = {0:[1, 3], 1:[0, 2, 4], 2:[1, 5],
3:[0,4,6], 4:[1,3,5,7], 5:[2,4,8],
6:[3,7], 7:[4,6,8], 8:[5,7]}
def dislocation(srcLayout,destLayout):
sum=0
a= srcLayout.index("0")
for i in range(0,9):
if i!=a:
sum=sum+abs(i-destLayout.index(srcLayout[i]))
return sum
def swap(a, i, j, deep, destLayout):
if i > j:
i, j = j, i
b = a[:i] + a[j] + a[i+1:j] + a[i] + a[j+1:]
#存储fn,A*算法
fn = dislocation(b, destLayout)+deep
return b, fn
def solveP(srcLayout, destLayout):
src=0;dest=0
for i in range(1,9):
fist=0
for j in range(0,i):
if srcLayout[j]>srcLayout[i] and srcLayout[i]!='0':
fist=fist+1
src=src+fist
for i in range(1,9):
fist=0
for j in range(0,i):
if destLayout[j]>destLayout[i] and destLayout[i]!='0':
fist=fist+1
dest=dest+fist
if (src%2)!=(dest%2):
return -1, None
g_dict_layouts[srcLayout] = -1
g_dict_layouts_deep[srcLayout]= 1
g_dict_layouts_fn[srcLayout] = 1 + dislocation(srcLayout, destLayout)
stack_layouts = []
gn=0
stack_layouts.append(srcLayout)
while len(stack_layouts) > 0:
curLayout = min(g_dict_layouts_fn, key=g_dict_layouts_fn.get)
del g_dict_layouts_fn[curLayout]
stack_layouts.remove(curLayout)
if curLayout == destLayout:#判断当前状态是否为目标状态
break
ind_slide = curLayout.index("0")
lst_shifts = g_dict_shifts[ind_slide]#当前可进行交换的位置集合
for nShift in lst_shifts:
newLayout, fn = swap(curLayout, nShift, ind_slide, g_dict_layouts_deep[curLayout] + 1, destLayout)
if g_dict_layouts.get(newLayout) == None:#判断交换后的状态是否已经查询过
g_dict_layouts_deep[newLayout] = g_dict_layouts_deep[curLayout] + 1
g_dict_layouts_fn[newLayout] = fn#存入fn
g_dict_layouts[newLayout] = curLayout
stack_layouts.append(newLayout)#存入集合
lst_steps = []
lst_steps.append(curLayout)
while g_dict_layouts[curLayout] != -1:#存入路径
curLayout = g_dict_layouts[curLayout]
lst_steps.append(curLayout)
lst_steps.reverse()
return 0, lst_steps
def run():
srcLayout = "538210467"
destLayout = "123456780"
retCode, lst_steps = solveP(srcLayout, destLayout)
if retCode != 0:
print("不可行")
else:
num=len(lst_steps)
for nIndex in range(num):
print("step #" + str(nIndex))
print(lst_steps[nIndex][:3])
print(lst_steps[nIndex][3:6])
print(lst_steps[nIndex][6:])
def main():
run()
if __name__ == "__main__":
main()
识图算法
我们的识图和图片分割算法可以说是残疾人算法,时灵时不灵 参考
# -*- coding: utf-8 -*-
"""
Created on Tue May 28 19:23:19 2019
将图片按照表格框线交叉点分割成子图片(传入图片路径)
@author: hx
"""
import cv2
import numpy as np
import pytesseract
image = cv2.imread('C:/Users/Administrator/Desktop/7.jpg', 1)
#灰度图片
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
#二值化
binary = cv2.adaptiveThreshold(~gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 35, -5)
#ret,binary = cv2.threshold(~gray, 127, 255, cv2.THRESH_BINARY)
cv2.imshow("二值化图片:", binary) #展示图片
cv2.waitKey(0)
rows,cols=binary.shape
scale = 40
#识别横线
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(cols//scale,1))
eroded = cv2.erode(binary,kernel,iterations = 1)
#cv2.imshow("Eroded Image",eroded)
dilatedcol = cv2.dilate(eroded,kernel,iterations = 1)
cv2.imshow("表格横线展示:",dilatedcol)
cv2.waitKey(0)
#识别竖线
scale = 20
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(1,rows//scale))
eroded = cv2.erode(binary,kernel,iterations = 1)
dilatedrow = cv2.dilate(eroded,kernel,iterations = 1)
cv2.imshow("表格竖线展示:",dilatedrow)
cv2.waitKey(0)
#标识交点
bitwiseAnd = cv2.bitwise_and(dilatedcol,dilatedrow)
cv2.imshow("表格交点展示:",bitwiseAnd)
cv2.waitKey(0)
# cv2.imwrite("my.png",bitwiseAnd) #将二值像素点生成图片保存
#标识表格
merge = cv2.add(dilatedcol,dilatedrow)
cv2.imshow("表格整体展示:",merge)
cv2.waitKey(0)
#两张图片进行减法运算,去掉表格框线
merge2 = cv2.subtract(binary,merge)
cv2.imshow("图片去掉表格框线展示:",merge2)
cv2.waitKey(0)
#识别黑白图中的白色交叉点,将横纵坐标取出
ys,xs = np.where(bitwiseAnd>0)
mylisty=[] #纵坐标
mylistx=[] #横坐标
#通过排序,获取跳变的x和y的值,说明是交点,否则交点会有好多像素值值相近,我只取相近值的最后一点
#这个10的跳变不是固定的,根据不同的图片会有微调,基本上为单元格表格的高度(y坐标跳变)和长度(x坐标跳变)
i = 0
myxs=np.sort(xs)
for i in range(len(myxs)-1):
if(myxs[i+1]-myxs[i]>10):
mylistx.append(myxs[i])
i=i+1
mylistx.append(myxs[i]) #要将最后一个点加入
i = 0
myys=np.sort(ys)
#print(np.sort(ys))
for i in range(len(myys)-1):
if(myys[i+1]-myys[i]>10):
mylisty.append(myys[i])
i=i+1
mylisty.append(myys[i]) #要将最后一个点加入
print('mylisty',mylisty)
print('mylistx',mylistx)
#循环y坐标,x坐标分割表格
for i in range(len(mylisty)-1):
for j in range(len(mylistx)-1):
#在分割时,第一个参数为y坐标,第二个参数为x坐标
ROI = image[mylisty[i]+3:mylisty[i+1]-3,mylistx[j]:mylistx[j+1]-3] #减去3的原因是由于我缩小ROI范围
cv2.imshow("分割后子图片展示:",ROI)
cv2.waitKey(0)
#special_char_list = '`~!@#$%^&*()-_=+[]{}|\\;:‘’,。《》/?ˇ'
pytesseract.pytesseract.tesseract_cmd = 'E:/Tesseract-OCR/tesseract.exe'
text1 = pytesseract.image_to_string(ROI) #读取文字,此为默认英文
#text2 = ''.join([char for char in text2 if char not in special_char_list])
print('识别分割子图片信息为:'+text1)
j=j+1
i=i+1
网络接口使用
因为使用 python 来 编写 ai,所以网络接口的实现就十分简单
使用了业界最流行的 requests 库
from typing import List
import requests
def get_not_answer_list() -> List:
url = 'http://47.102.118.1:8089/api/team/problem/xx'
r = requests.get(url)
return r.json()
访问text
import json
from typing import List, Dict
from ai.util import get_swaps
def test(serial_number: List[int], swap_step: int, swap: List[int], operations: str, my_swap: List[int]):
pass
def main():
fail_list: List[Dict] = []
with open('test.txt', 'r', encoding='utf-8') as f:
while s:=f.readline():
print(s)
fail_list.append(json.loads(s))
# for fail in fail_list:
# ai = get_swaps.Ai(fail['serial_number'], fail['swap_step'], fail['swap'], fail['uuid'])
# ai.get_steps()
# print(ai.operations, ai.is_solution, ai.my_swap)
fail = fail_list[0]
ai = get_swaps.Ai(fail['serial_number'], fail['swap_step'], fail['swap'], fail['uuid'])
ai.get_steps()
print(ai.operations, ai.my_swap, fail)
if __name__ == '__main__':
main()
内存占用

三、最后的部分
贴出Github的代码签入记录,合理记录commit信息。

遇到的代码模块异常或结对困难及解决方法。****
-
问题描述
ai识图功能很难完成,有时候能识别有时候完成不了
-
解决尝试
通过算法调试解决部分问题
-
是否解决
只解决了一部分,还有很多是没做到的
-
有何收获
说明ai算法只是面向网络抄是没有好下场的
评价你的队友。
吴仕涛评价高逸超
-
值得学习的地方
做事很认真,算法做很好
-
需要改进的地方
有点心急,可以戒骄戒躁
高逸超评价吴仕涛
-
值得学习的地方
做原型很快,实力还行
-
需要改进的地方
我们都需要提高编程能力,需要认真一点
.2.5]提供此次结对作业的PSP和学习进度条
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | ||
| Analysis | · 需求分析 (包括学习新技术) | 720 | 700 |
| · Design Spec | · 生成设计文档 | 60 | 90 |
| · Design Review | · 设计复审 | 40 | 60 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| · Design | · 具体设计 | 360 | 120 |
| · Coding | · 具体编码 | 600 | 720 |
| · Code Review | · 代码复审 | 40 | 110 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 450 | 450 |
| Reporting | 报告 | ||
| · Test Report | · 测试报告 | 40 | 30 |
| · Size Measurement | · 计算工作量 | 15 | 45 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 2385 | 2385 |
学习进度条
| 第N周 | 新增代码(行) | 累计代码(行) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|
| 第1周 | 180 | 180 | 10 | postman使用 |
| 第2周 | 330 | 510 | 14 | bfs,A、A*算法 |
| 第3230 | 200 | 710 | 20 | 图像处理方式 |
| 第4周 | 200 | 900 | 20 | ai大比拼加强很多实力 |

