

第一次个人编程作业
我的github
计算模块接口的设计与实现过程
具体算法流程图如下
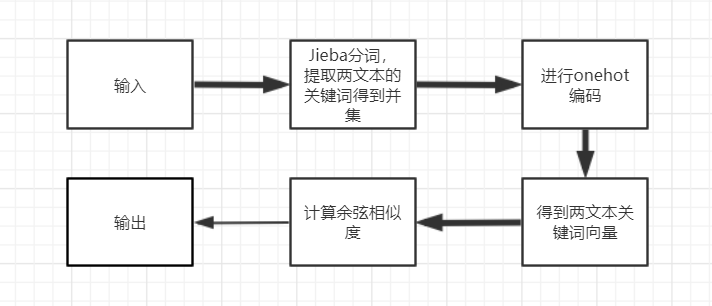
模块介绍
基本思想:余弦相似度算法 参考博客
one_hot用于onehot编码
def one_hot(word_dict, keywords):
cut_code = [word_dict[word] for word in keywords]
cut_code = [0]*len(word_dict)
for word in keywords:
cut_code[word_dict[word]] += 1
return cut_code
def extract_keyword用于提取关键词
def extract_keyword(content):
re_exp = re.compile(r'(<style>.*?</style>)|(<[^>]+>)', re.S)
content = re_exp.sub(' ', content)
content = html.unescape(content)
seg = [i for i in jieba.cut(content, cut_all=True) if i != '']
# 提取关键词
keywords = jieba.analyse.extract_tags("|".join(seg), topK=200, withWeight=False)
return keywords
计算模块接口部分的性能改进
消耗最大的部分
如图所示,main.py消耗最大
性能分析图
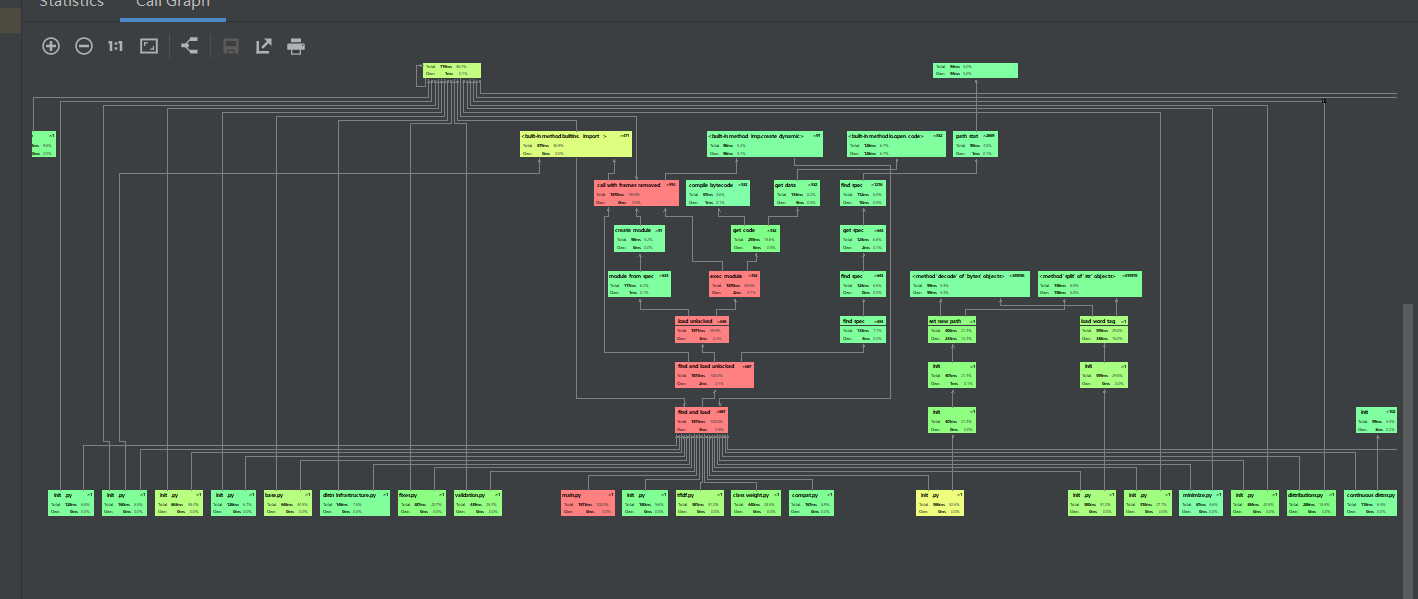
计算模块部分单元测试展示
测试结果:
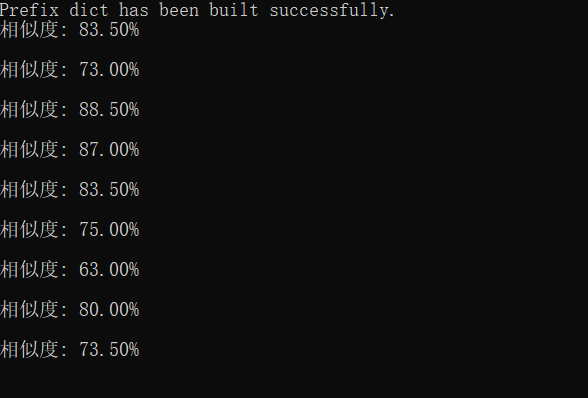
基本都在0.8左右,上下浮动,较为符合预期。
部分测试代码:
if __name__ == '__main__':
with open('F:/qq/sim_0.8/orig.txt', 'r', encoding="UTF-8") as x1, open('F:/qq/sim_0.8/orig_0.8_add.txt', 'r',
encoding="UTF-8") as y1:
content_x1 = x1.read()
content_y1 = y1.read()
similarity = CosineSimilarity(content_x1, content_y1)
similarity = similarity.main()
print('相似度: %.2f%%\n' % (similarity * 100))
with open('F:/qq/sim_0.8/orig.txt', 'r', encoding="UTF-8") as x2, open('F:/qq/sim_0.8/orig_0.8_del.txt', 'r',
encoding="UTF-8") as y2:
content_x2 = x2.read()
content_y2 = y2.read()
similarity = CosineSimilarity(content_x2, content_y2)
similarity = similarity.main()
print('相似度: %.2f%%\n' % (similarity * 100))
with open('F:/qq/sim_0.8/orig.txt', 'r', encoding="UTF-8") as x3, open('F:/qq/sim_0.8/orig_0.8_dis_1.txt', 'r',
encoding="UTF-8") as y3:
content_x3 = x3.read()
content_y3 = y3.read()
similarity = CosineSimilarity(content_x3, content_y3)
similarity = similarity.main()
print('相似度: %.2f%%\n' % (similarity * 100))
with open('F:/qq/sim_0.8/orig.txt', 'r', encoding="UTF-8") as x4, open('F:/qq/sim_0.8/orig_0.8_dis_3.txt', 'r',
encoding="UTF-8") as y4:
content_x4 = x4.read()
content_y4 = y4.read()
similarity = CosineSimilarity(content_x4, content_y4)
similarity = similarity.main()
print('相似度: %.2f%%\n' % (similarity * 100))
with open('F:/qq/sim_0.8/orig.txt', 'r', encoding="UTF-8") as x6, open('F:/qq/sim_0.8/orig_0.8_dis_7.txt', 'r',
encoding="UTF-8") as y6:
content_x6 = x6.read()
content_y6 = y6.read()
similarity = CosineSimilarity(content_x6, content_y6)
similarity = similarity.main()
print('相似度: %.2f%%\n' % (similarity * 100))
with open('F:/qq/sim_0.8/orig.txt', 'r', encoding="UTF-8") as x7, open('F:/qq/sim_0.8/orig_0.8_dis_10.txt', 'r',
encoding="UTF-8") as y7:
content_x7 = x7.read()
content_y7 = y7.read()
similarity = CosineSimilarity(content_x7, content_y7)
similarity = similarity.main()
print('相似度: %.2f%%\n' % (similarity * 100))
with open('F:/qq/sim_0.8/orig.txt', 'r', encoding="UTF-8") as x8, open('F:/qq/sim_0.8/orig_0.8_dis_15.txt', 'r',
encoding="UTF-8") as y8:
content_x8 = x8.read()
content_y8 = y8.read()
similarity = CosineSimilarity(content_x8, content_y8)
similarity = similarity.main()
print('相似度: %.2f%%\n' % (similarity * 100))
with open('F:/qq/sim_0.8/orig.txt', 'r', encoding="UTF-8") as x9, open('F:/qq/sim_0.8/orig_0.8_mix.txt', 'r',
encoding="UTF-8") as y9:
content_x9 = x9.read()
content_y9 = y9.read()
similarity = CosineSimilarity(content_x9, content_y9)
similarity = similarity.main()
print('相似度: %.2f%%\n' % (similarity * 100))
with open('F:/qq/sim_0.8/orig.txt', 'r', encoding="UTF-8") as x0, open('F:/qq/sim_0.8/orig_0.8_rep.txt', 'r',
encoding="UTF-8") as y0:
content_x0 = x0.read()
content_y0 = y0.read()
similarity = CosineSimilarity(content_x0, content_y0)
similarity = similarity.main()
print('相似度: %.2f%%\n' % (similarity * 100))
计算模块部分异常处理说明
设计空白对比文档和完全一致的文档
空白文档的结果:

没有异常。
完全一致文档的结果:
没有异常。
时间有限,暂时没有发现模块异常。
PSP表格如下
PSP2.1 | Personal Software Process Stages | 预估耗时(分钟)| 实际耗时(分钟)
- | - | :-: |:-:
Planning|计划|30|40
Estimate|估计这个任务需要多少时间|20|20
Development|开发|480|300
Analysis|需求分析 (包括学习新技术)|300|200
Design Spec|生成设计文档|60|30
Design Review|设计复审|30|20
Coding Standard|代码规范 (为目前的开发制定合适的规范)|30|30
Design|具体设计|60|60
Coding|具体编码|300|200
Code Review|代码复审|30|30
Test|测试(自我测试,修改代码,提交修改)|120|90
Reporting|报告|60|80
Test Repor|测试报告|30|20
Size Measurement|计算工作量|30|15
Postmortem & Process Improvement Plan|事后总结, 并提出过程改进计划|40|35
Total|合计|1620|1140
小总结
第一次做这种作业,没有经验,难度有点高。只能在网上论坛上找找别人的东西,参考了很多才完成作业。自己还是有很多不足,希望以后再接再厉。
