文字识别(OCR)介绍与免费开源项目使用测评
一、OCR介绍
OCR英文全称是Optical Character Recognition,中文叫做光学字符识别。它是通过扫描等光学技术与计算机技术结合的方式将各种证件、票据、文件及其它印刷品的文字转化为图像信息,再利用文字识别技术将图像信息转化为可以使用的计算机输入技术。也就是说,ocr识别技术 直接从影像中提取各类数据,省去人工录入,节约成本。

原理
为了识别一张图片中的文字,通常包含两个步骤:
1)、文本检测:检测出图片中文字所在的位置;
2)、文字识别:识别包含文字的图片局部,预测具体的文字。
二、OCR开源项目测评
以下为对Github上几个开源ocr项目的测评,主要分为几个方面:新手友好度、使用便捷性、OCR识别效果,并会通过一个简单的demo展示一下
1、cnocr
https://github.com/breezedeus/CnOCR
cnocr是一个基于PyTorch的开源OCR库,它提供了一系列功能强大的中文OCR模型和工具,可以用于图像中的文字检测、文字识别和文本方向检测等任务。它可以识别各种不同风格和字体的中文文字,包括简体字和繁体字,可根据具体需求在官方文档中查找对应的模型作为参数输入实例化cnocr方法。官方也提供有英文的识别模型,但其他语言就暂时没有更多的模型,但可以根据自己的需要和自己准备的数据集对模型进行训练。
可以直接使用pip进行安装,包括对应的文本检测与文本识别算法。也可以直接通过git clone从github上拉取。
pip install cnstd
pip install cnocr
git clone https://github.com/breezedeus/cnstd
git clone https://github.com/breezedeus/cnocrdemo
from cnocr import CnOcr
ocr = CnOcr() # 所有参数都使用默认值
out = ocr.ocr(img_path)
# 结果处理
results = ''
for output in out:
result = output['text']
results = results + str(result) + '\n'
print(results)

2、easyocr
https://github.com/JaidedAI/EasyOCR
EasyOCR是一个基于PyTorch的开源OCR库,可以进行多语言文本识别。它支持超过80种语言,不单单针对中文,并具有较高的准确性和鲁棒性,官方文档也都是英文的,因此对于英文不熟悉的同学可能相对而言没那么方便。
从环境安装角度来讲,该算法的使用是较为便捷的,可以直接使用pip来安装EasyOCR库:
pip install easyocrdemo
import easyocr
# 加载预训练模型,这里是加载可同时识别简体中文和英文的对象,可根据自己需求指定其他语言的预训练模型
reader = easyocr.Reader(['ch_sim', 'en'])
# 返回一个包含识别结果的列表
result = reader.readtext(img_path, detail=0)
# 处理识别结果
results = '\n'.join(result)
results = results.replace(' ', '')
print(results)

3、mmocr
https://github.com/open-mmlab/mmocr
mmocr是一个开源的多模态OCR工具包,用于处理多模态(如图像、文本、语音等)的光学字符识别任务。它基于深度学习技术,提供了一系列强大的OCR模型和工具,可以用于图像中的文字检测、文字识别和文本方向检测等任务。
mmocr是由OpenMMLab团队开发和维护的一个项目。OpenMMLab是一个专注于计算机视觉领域的开源项目组织,致力于推动计算机视觉技术的研究和应用。拥有着强大的功能但该项目对新手不是很友好,笔者曾经使用过几个OpenMMLab下的计算机视觉项目,其环境安装配置部分较为麻烦,需要安装mmcv-full、Visual Studio Community 2019、CUDA、cuDNN等进行环境配置。
环境没问题之后可以通过gitclone获取整个开源项目,有提供一些可供测试的图片,其测试结果也较为准确,对一些扭曲变形的文字也有较为不错的效果。


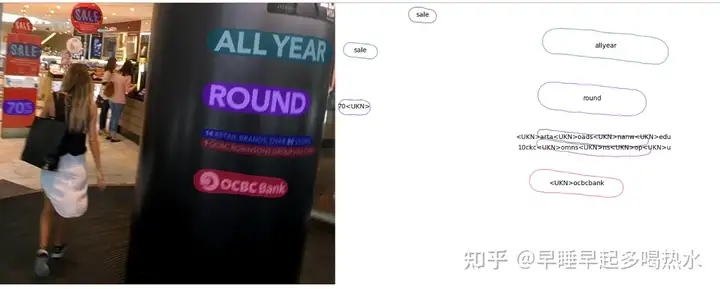
demo
import cv2
from mmocr.apis import MMOCRInferencer
# 载入模型,实例化 MMOCRInferencer
infer = MMOCRInferencer(det='textsnake', rec='SAR')
# 载入图像
img_bgr = cv2.imread(img_path)
result = infer(img_path, save_vis=True, return_vis=True)
# 查看结果文本
result['predictions'][0]['rec_texts']
4、paddleocr
https://github.com/PaddlePaddle/PaddleOCR
PaddleOCR是基于PaddlePaddle深度学习框架的开源OCR工具,但它提供了PyTorch版本的预训练模型。它支持中英文等多种语言的文本识别,并具有较高的准确性和速度。

paddleocr的官方文档就更加的友好,有好几种语言可供选择,讲述的也更为详细,包括从什么是ocr开始到模型的各种细节都有提到

如果想深入算法细节,文档里也给出了非常清晰的paper模型结构和算法细节,更详细的也可以选择阅读原论文
demo
import paddleocr
import numpy as np
ocr = PaddleOCR()
result = ocr.ocr(img_path)
txts = [line[1][0] for line in result]
results = ''
for item in txts:
results = results + '\n' + item
print(results)
5、tesseract
https://github.com/tesseract-ocr/tesseract
Tesseract是一个开源的OCR引擎,支持多种语言的文字,其官方提供发说明文档也是英文的。
tesseract的使用会更麻烦,无法直接使用pip进行安装。需要在系统下安装Tesseract OCR引擎,访问Tesseract OCR的官方网站,找到适用于Windows系统的最新版本的安装程序并在环境变量中添加Tesseract安装目录的路径,在终端或命令提示符中运行以下命令,验证Tesseract是否正确安装,如果成功输出Tesseract的版本号,则表示安装成功。
tesseract --versiondemo
import pytesseract
from PIL import Image
image = Image.open(r"F:\video_script\cnocr\0.jpg")
# lang参数来指定识别语言
text = pytesseract.image_to_string(image, lang='chi_sim')
print(text)
三、开源项目对比
其中识别效果部分仅仅针对中文(mmocr是英文),其他语言包括数据不充足等原因暂时没有做测评
| 项目名称 | 优点 | 缺点 |
|---|---|---|
| cnocr | 安装使用方便,对环境的要求不高,检测精准度和识别准确率较高 | 语言方面有局限性,仅能识别中文简体繁体、英文、数字等,如需识别更高专业度的公式或其他语言需要进行自己的训练。 |
| easyocr | 安装调用方便,支持识别监测多种语言 | 对中文监测的准确度一般,对排版规整的印刷体都有较好的表现,但对于稍有畸变或包含其他字体的图像其效果一般; 模型较大,EasyOCR的内存占用较高 |
| mmocr | 功能完善,包括文本检测、文本识别、以及端到端的文本识别任务都有给出对应的方法以及详细的说明文档 | 环境安装配置较为繁琐 |
| paddleocr | 方便进行自己的训练:官方给到的训练集非常全,也有常用的合成、标注工具。基本满足个性化训练的场景应用,不需要再自己花时间找,一键下载就行,文档中也有详细的说明; 识别准确率较高 |
基于paddle框架,并不是目前所使用的主流框架,对未使用过的小白或是需要进行后续开发可能不是很友好 |
| tesseract | tesseract具有良好的可扩展性,用户可以使用自定义训练数据来训练和优化OCR模型,Tesseract还提供了API和接口,方便用户进行二次开发和集成 | 不是专门针对中文场景且相关文档主要是英文,经过笔者测试感觉其对于复杂字形和字体的识别准确性较低 |
四、总结比对
cnocr:使用便捷,调用对专业知识要求不高,适合需要快速使用完成对简单或复杂的中文文本检测的新手(当然也可以满足更专业一点的数据集训练等)
easyocr:安装调用方便,适合需要直接完成对文件或其他排版规整的印刷体的文本识别,较为复杂的文本图像则不建议使用
mmocr:基于openmmlab的环境配置较为繁琐,不适合快速上手,适用于原本有安装过mmcv或专业知识较高,操作灵活性较强,可根据不同要求灵活调用方法。
paddleocr:环境框架非主流不适合直接快速使用,适用于专业性较高且需要完成个性化训练的,官方提供了很详细的方法与训练集等。
tesseract:安装配置稍麻烦,且直接使用准确率较低,但具有极其可观的可扩展性,适用于二次开发与训练优化模型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号