

全链路追踪
三个追踪级别:
- 跨进程追踪(cross-process):调用另一个微服务
- 数据库追踪
- 进程内部的追踪(in-process):在一个函数内部的追踪
可观察性 (Observability)
可观察性更关注的是从系统自身出发,去展现系统的运行状况,更像是一种对系统的自我审视。
可观察性目前主要包含以下三大支柱:
-
日志(Logging):Logging 主要记录一些离散的事件,应用往往通过将定义好格式的日志信息输出到文件,然后用日志收集程序收集起来用于分析和聚合。虽然可以用时间将所有日志点事件串联起来,但是却很难展示完整的调用关系路径;
-
度量(Metrics):Metric 往往是一些聚合的信息,相比 Logging 丧失了一些具体信息,但是占用的空间要比完整日志小的多,可以用于监控和报警,在这方面 Prometheus 已经基本上成为了事实上的标准;
-
分布式追踪(Tracing):Tracing 介于 Logging 和 Metric 之间, 以请求的维度来串联服务间的调用关系并记录调用耗时,即保留了必要的信息,又将分散的日志事件通过 Span 串联,帮助我们更好的理解系统的行为、辅助调试和排查性能问题。
CNCF 云原生计算基金会
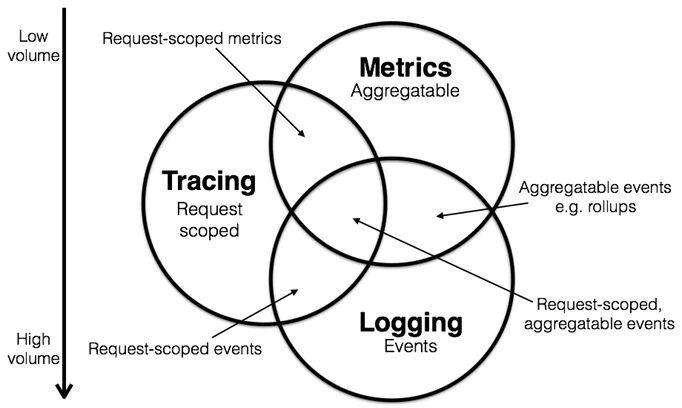
三大支柱有如下特点:
- Metric 的特点是,它是可累加的。具有原子性,每个都是一个逻辑计量单元,或者一个时间段内的柱状图。例如:队列的当前深度可以被定义为一个计量单元,在写入或读取时被更新统计;输入 HTTP 请求的数量可以被定义为一个计数器,用于简单累加;请求的执行时间可以被定义为一个柱状图,在指定时间片上更新和统计汇总。
- Logging 的特点是,它描述一些离散的(不连续的)事件。例如:应用通过一个滚动的文件输出 debug 或 error 信息,并通过日志收集系统,存储到 Elasticsearch 中;审批明细信息通过 Kafka,存储到数据库(BigTable)中;又或者,特定请求的元数据信息,从服务请求中剥离出来,发送给一个异常收集服务,如 NewRelic。
- Tracing 的最大特点就是,它在单次请求的范围内处理信息。任何的数据、元数据信息都被绑定到系统中的单个事务上。例如:一次调用远程服务的 RPC 执行过程;一次实际的SQL查询语句;一次 HTTP 请求的业务性 ID 。
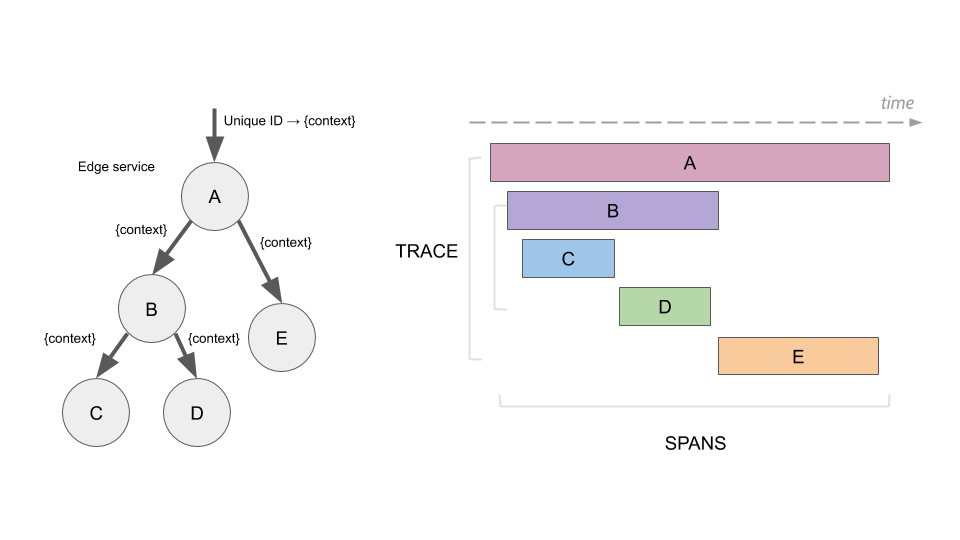
Tracing
分布式追踪,也称为分布式请求追踪,是一种用于分析和监视应用程序的方法,特别是那些使用微服务体系结构构建的应用程序;分布式追踪有助于查明故障发生的位置以及导致性能低下的原因,开发人员可以使用分布式追踪来帮助调试和优化他们的代码,IT 和 DevOps 团队可以使用分布式追踪来监视应用程序。
分布式追踪系统的核心步骤一般有三个:代码埋点,数据存储、查询展示。
OpenTracing
OpenTracing 旨在标准化 Trace 数据结构和格式,其目的是:
- 不同语言开发的 Trace 客户端的互操作性。Java/.Net/PHP/Python/NodeJs 等语言开发的客户端,只要遵循 OpenTracing 规范,就都可以对接 OpenTracing 兼容的监控后端。
- Tracing 监控后端的互操作性。只要遵循 OpenTracing 规范,企业可以根据需要替换具体的 Tracing 监控后端产品,比如从 Zipkin 替换成 Jaeger/CAT/Skywalking 等后端。
OpenTracing 与 OpenCensus 已合并为 OpenTelemetry 。
OpenTracing 不是一个标准,OpenTracing API 提供了一个标准的、与供应商无关的框架,是对分布式链路中涉及到的一系列操作的高度抽象集合。这意味着如果开发者想要尝试一种不同的分布式追踪系统,开发者只需要简单地修改 Tracer 配置即可,而不需要替换整个分布式追踪系统。
OpenTracing 是一个轻量级的标准化层,位于应用程序/类库和追踪或日志分析程序之间。
1
|
+-------------+ +---------+ +----------+ +------------+
|
OpenTracing 数据模型
基本概念
-
Trace (调用链/链路):在广义上,一个 Trace 代表了一个事务或者流程在(分布式)系统中的执行过程。一个 Trace 是由多个 Span 组成的一个有向无环图(DAG),每一个 Span 代表 Trace 中被命名并计时的连续性的执行片段。
-
Span (跨度):一个 Span 代表系统中具有开始时间和执行时长的逻辑运行单元,即应用中的一个逻辑操作。Span 之间通过嵌套或者顺序排列建立逻辑因果关系。一个 Span 可以被理解为一次方法调用,一个程序块的调用,或者一次 RPC / 数据库访问,只要是一个具有完整时间周期的程序访问,都可以被认为是一个 Span。
-
Logs:每个 Span 可以进行多次 Logs 操作,每一次 Logs 操作,都需要一个带时间戳的时间名称,以及可选的任意大小的存储结构。
-
Tags:每个Span可以有多个键值对(key:value)形式的 Tags,Tags 是没有时间戳的,支持简单的对 Span 进行注解和补充。
-
SpanContext:SpanContext 更像是一个“概念”,而不是通用 OpenTracing 层的有用功能。在创建 Span、向传输协议 Inject(注入)和从传输协议 中Extract(提取)调用链信息时,SpanContext 发挥着重要作用。
Span
表示分布式调用链条中的一个调用单元,其边界包含一个请求进到服务内部再由某种途径(例如:http)从当前服务出去。
一个 Span 一般会记录这个调用单元内部的一些信息,例如每个 Span 包含的操作名称、开始和结束时间、附加额外信息的 Span Tag、可用于记录 Span 内特殊事件 Span Log 、用于传递 Span 上下文的 SpanContext 和定义 Span 之间关系的 References 。
Span 状态
- 操作名称 (An operation name)
- 开始时间 (A start timestamp)
- 结束时间 (A finish timestamp)
- 标签信息 (Span Tag):零个或多个键值对(keys:values)组成的 Span Tags。键必须是 string 类型,值可以是字符串,布尔,或者数字类型。
- 日志信息 (Span Log):零个或多个 Span Logs。每次 log 操作包含一个键值对和一个时间戳。 键值对中,键必须为 string 类型,值可以是任意类型。 但并不是所有的支持 OpenTracing 的 Tracer 都需要支持所有的值类型。
- Span 上下文对象 (SpanContext)
- Span 间关系 (References):通过 SpanContext 可以指向零个或者多个因果相关的 Span 。
SpanContext 状态
- 任何一个 OpenTracing 实现都需要将当前调用链的状态(例如:Trace 和 Span 的 id)跨进程边界传输,依赖于一个独特的 Span
- Baggage Items,Trace 的随行数据,是一个键值对集合,存在于 Trace 中,也需要跨进程边界传输
Tracer
Trace 描述在分布式系统中的一次”事务”。一个 Trace 通过归属于此调用链的 Span(跨度)隐性定义,可以被认为是由一个或多个 Span 组成的有向无环图(DAG), Span 与 Span 的关系被命名为 References。
Span 可以理解为一次方法调用, 一个程序块的调用,或者一次 RPC / 数据库访问。只要是一个具有完整时间周期的程序访问,都可以被认为是一个 Span 。
Tracer 用于创建 Span,并理解如何跨进程边界注入(序列化)和提取(反序列化) Span。它有以下的职责:
- 建立和开启一个 Span
- 从某种媒介中提取/注入一个 SpanContext
- 示例 Trace (由 8 个 Span 组成)
单个 Trace 中,Span 间的因果关系
1
|
[Span A] ←←←(the root Span)
|
- 基于时间轴的时序图
单个 Trace 中,Span 间的时间关系
1
|
––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–> time
|
References
一个 Span 可以与一个或多个 Span 存在因果关系。OpenTracing 目前定义了两种关系:ChildOf(父子) 和 FollowsFrom(跟随)。
- ChildOf
一个 Span 可能是一个父级 Span 的孩子,父级 Span 在某种程度上取决于子 Span。以下情况会构成 ChildOf 关系
- 一个 RPC 调用的服务端的 Span,和 RPC 服务客户端的 Span 构成 ChildOf 关系
- 一个 sql insert 操作的 Span,和 ORM 的 save 方法的 Span 构成 ChildOf 关系
- 很多可以并行工作(或者分布式工作)的 Span 都可能是一个父级的 Span 的子项,父级 Span 会合并所有子 Span 的执行结果,并在指定期限内返回
1
|
[-Parent Span---------]
|
- FollowsFrom
一些父级节点不以任何方式依赖他们子节点的执行结果,这种情况下子 Span 和父 Span 之间是 FollowsFrom 的因果关系。
1
|
[-Parent Span-] [-Child Span-]
|
SpanContext
表示一个 Span 对应的上下文,Span 和 SpanContext 基本上是一一对应的关系, SpanContext 可以通过某些媒介和方式传递给调用链的下游来做一些处理(例如子 Span 的 id 生成、信息的继承打印日志等等)。
Span 上下文存储的是一些需要跨越边界的(传播追踪所需的)一些信息,例如:
- SpanId :当前这个 Span 的 id
- TraceId :这个 Span 所属的 TraceId (也就是这次调用链的唯一id)。
- Trace_id 和 Span_id 用以区分 Trace 中的 Span;任何 OpenTraceing 实现相关的状态(比如 Trace 和 Span id)都需要被一个跨进程的 Span 所联系。
- baggage :其他的能过跨越多个调用单元的信息,即跨进程的 key value 对。Baggage Items 和 Span Tag 结构相同,唯一的区别是:Span Tag 只在当前 Span 中存在,并不在整个 Trace 中传递,而 Baggage Items 会随调用链传递。
在跨界(跨服务或者协议)传输过程中实现调用关系的传递和关联,需要能够将 SpanContext 向下游介质注入,并在下游传输介质中提取 SpanContext。
Carrier
Carrier 表示的是一个承载 SpanContext 的媒介,比方说在 http 调用场景中会有 HttpCarrier,在 dubbo 调用场景中也会有对应的 DubboCarrier 。
Formatter
负责具体场景中序列化反序列化上下文的逻辑,例如在 HttpCarrier 使用中通常就会有一个对应的 HttpFormatter 。 Tracer 的注入和提取就是委托给了 Formatter 。
ScopeManager
通过它能够获取当前线程中启用的 Span 信息,并且可以启用一些处于未启用状态的 Span 。在一些场景中,我们在一个线程中可能同时建立多个 Span ,但是同一时间同一线程只会有一个 Span 启用,其他 Span 可能处在下列的状态中:
- 等待子 Span 完成
- 等待某种阻塞方法
- 创建但是并未开始
Reporter
通过它来打印或者上报一些关键链路信息(例如 Span 创建和结束),只有把这些信息进行处理之后才能对全链路信息进行可视化和真正的监控。
开源分布式追踪系统
分布式追踪系统设计目标
- 低侵入性
- 灵活的应用策略:收集数据的范围和粒度
- 时效性:从 agent 采样,到 collect、storage 和 display 尽可能快
- 决策支持
- 可视化
- 低消耗:在 Web 请求链路中,对请求的响应影响尽可能小
- 延展性:随着业务量的增长,分布式追踪系统依然具有高可用和高性能表现
Jaeger
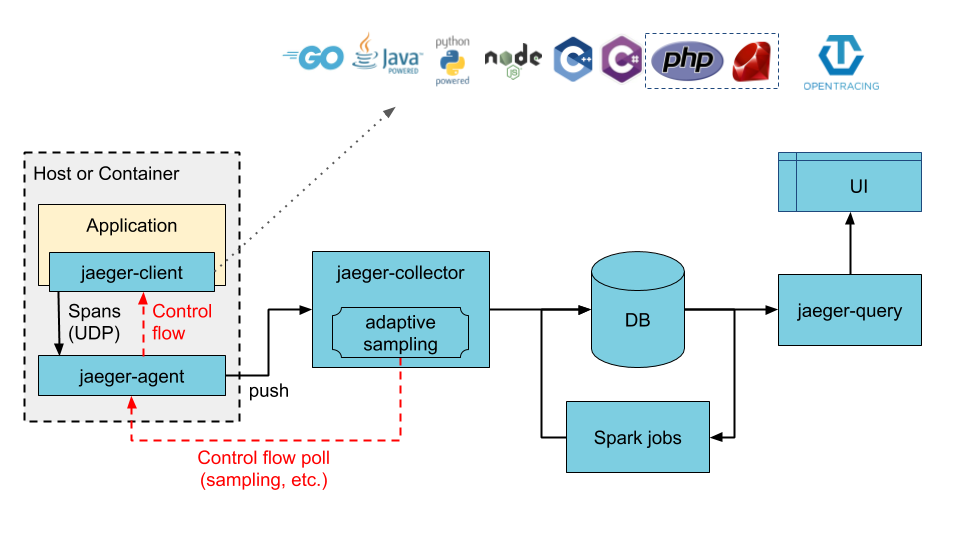
Jaeger 主要有以下几个组成部分:
- Jaeger Client:为不同语言实现符合 OpenTracing 的 SDK。应用程序通过 API 写入数据,client library 把 trace 信息按照应用程序制定的采样策略传递给 jaeger-agent 。
- Agent:一个监听在 UDP 端口上接收 span 数据的网络守护进程,它会将数据批量发送给 collector 。它被设计成一个基础组件,部署到所有的宿主机上。Agent 将 client library 和 collector 解耦,为 client library 屏蔽了路由和发现 collector 的细节。
- Collector:接收 jaeger-agent 发送来的数据,然后将数据写入后端存储。Collector 被设计成无状态的组件,因此用户可以运行任意数量的 Collector。
- Data Store:后端存储被设计成一个可插拔的组件,支持数据写入 cassandra , elastic search 等。
- Query:接收查询请求,从后端存储系统中检索 tarce 并通过 UI 进行展示。Query 是无状态的,可以启动多个实例并把它们部署在例如 nginx 这样的负载均衡器之后。
术语
Span (跨度)表示 Jaeger 中具有操作名称、开始时间和持续时间的逻辑工作单元。Span 可以嵌套和排序,以建模因果关系。
Trace (链路)是系统中的数据/执行路径,可以认为是由 Span 组成的的有向无环图。
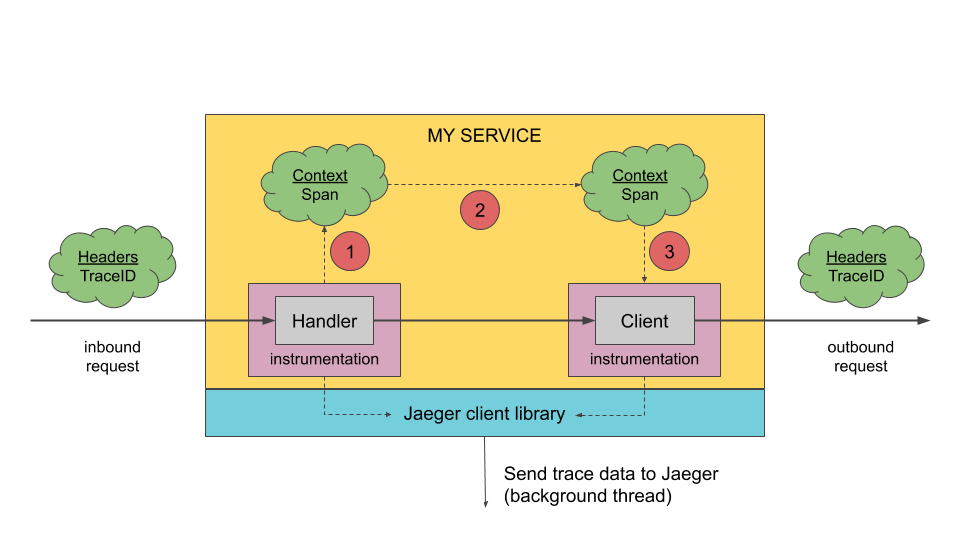
对于一个组件来说,一次处理过程一般是产生一个 Span;这个 Span 的生命周期是从接收到请求到返回响应这段过程。
这里需要考虑的问题是如何与上下游链路关联起来。在 Opentracing 规范中,可以在 Tracer 中 extract 出一个跨进程传递的 SpanContext 。然后通过这个 SpanContext 所携带的信息将当前节点关联到整个 Tracer 链路中去,当然有提取(extract)就会有对应的注入(inject)。
链路的构建一般是 client-server-client-server 这种模式的,那就是会在 client 端进行注入(inject),然后再 server 端进行提取(extract),反复进行,然后一直传递下去。
在拿到 SpanContext 之后,此时当前的 Span 就可以关联到这条链路中了,那么剩余的事情就是收集当前组件的一些数据;整个过程大概分为以下几个阶段:
- 从请求中提取 SpanContext
- 构建 Span,并将当前 Span 存入当前 tracer 上下文中
- 设置一些信息到 Span 中
- 返回响应
- Span 结束并上报
组件
Jaeger 可以被部署为一个一体化的二进制文件,其中 Jaeger 的所有后端组件运行在一个单独的进程中;也可以被部署为一个可扩展的分布式系统,有两个主要的部署方式:
- Collector 直接写入存储
- Collecter 写入 Kafka 作为初始缓冲区
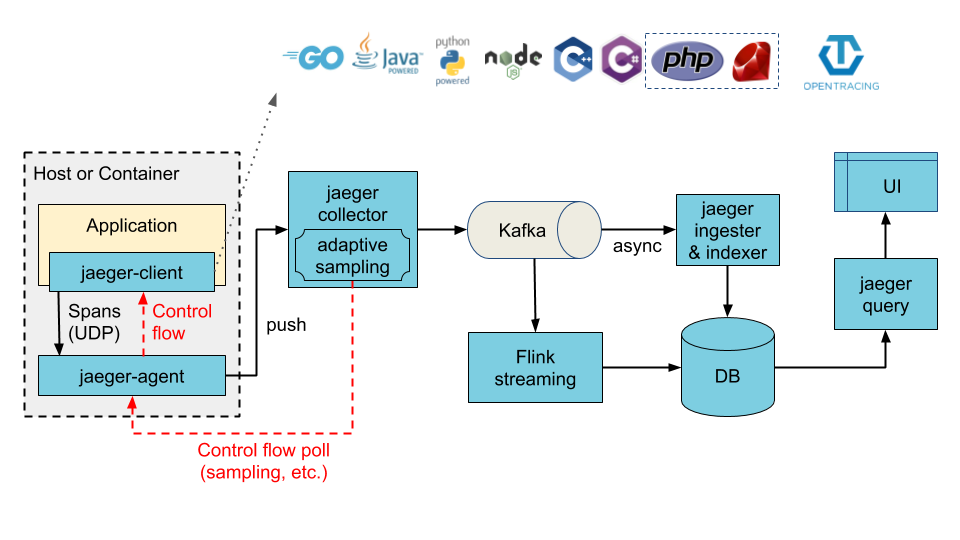
Jaeger Client(客户端)
Jaeger 客户端是 OpenTracing API 特定语言的实现。它们可以用于手动或者通过与 OpenTracing 集成的各种现有的开源框架,比如 Flask、Dropwizard、gRPC 等等,来进行分布式追踪。
被检测的服务在接收新请求时创建 Span,并将上下文信息(trace id、span id、baggage)附加到传出的请求。只有 id 和 baggage 会与请求一起传播;所有其他分析数据,如操作名称、时间、标记和日志,都不会传播。相反,它们在后台异步传输到 Jaeger 后端。
该机制被设计为在生产环境中始终处于开启状态。为了减少开销,Jaeger 客户端使用了各种采样策略。对 trace 进行采样时,Span 分析数据被捕获并传输到 Jaeger 后端。当不对 trace 进行采样时,不会收集任何分析数据,对 OpenTracing API 的调用也会短路,使得开销最小。默认情况下,Jaeger 客户端采样 0.1% 的 trace ,并有能力从 Jaeger 后端检索采样策略。
Agent(代理)
Jaeger 代理是一个网络守护进程,监听通过 UDP 发送的 Span,并将其批量发送给收集器。代理被设计成基础架构组件并部署到所有主机上,它将收集器的路由和发现从客户端抽象出来。
Collector(收集器)
Jaeger 收集器接收来自 Jaeger 代理的 Trace 并通过处理管道运行它们。目前的管道支持对 trace 进行验证、索引、执行任何转换,最后存储它们。
Jaeger 的存储是一个可插拔组件,目前支持 Cassandra , Elasticsearch 和 Kafka 。
Query
从存储中检索 trace 并提供 UI 进行展示。
Ingester
从 Kafka Topic 中读取数据并写入到另一个存储后端(Cassandra, Elasticsearch)。
实验
All-in-one 是为快速本地测试而设计的可执行程序,通过内存存储组件启动 Jaeger UI、收集器、查询和代理,这里使用 Docker 镜像启动。使用浏览器访问 http://localhost:16686 Jaeger UI 。
1
|
docker run -d --name jaeger \
|
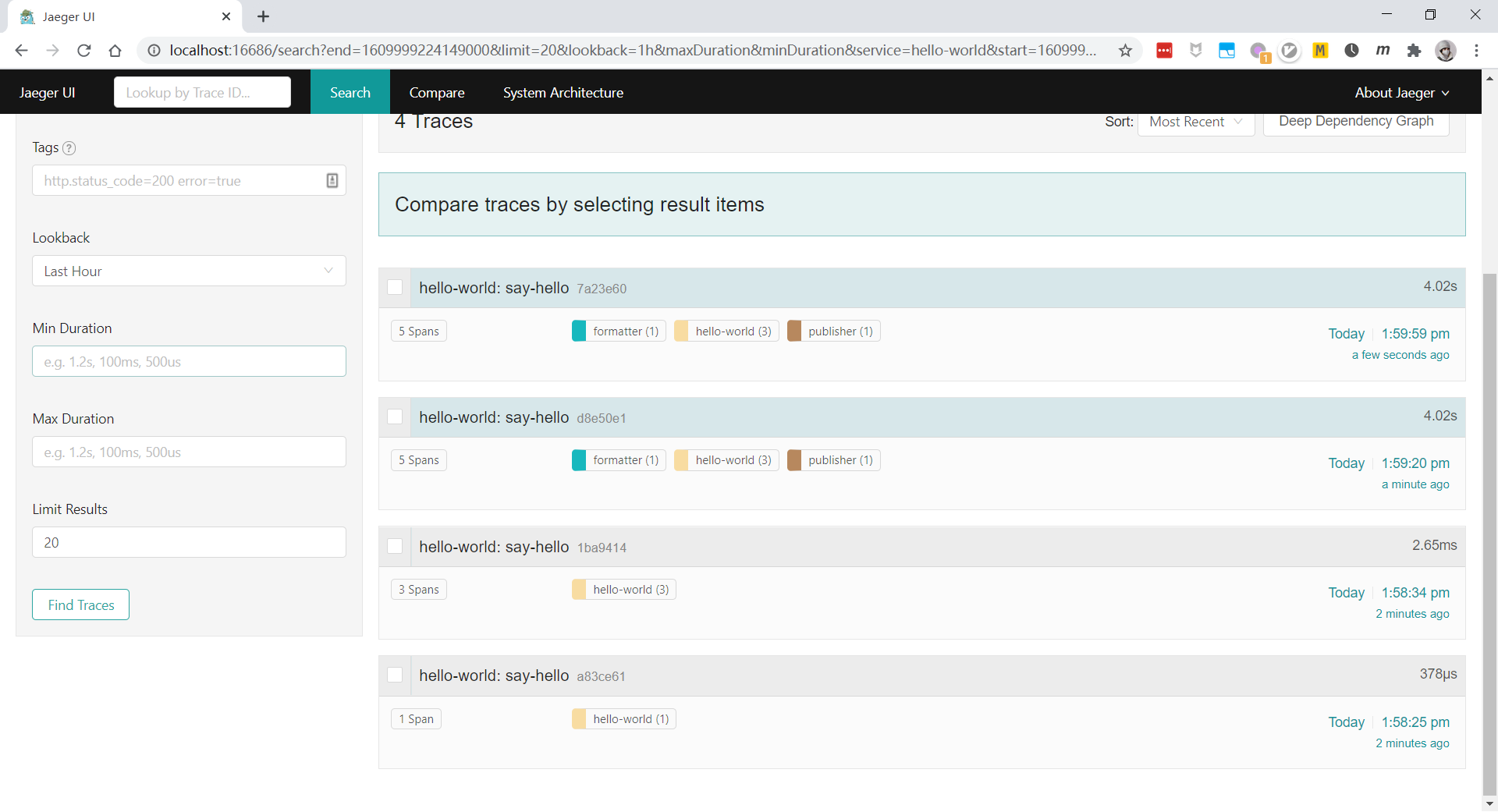
Hello World
trace 是由 span 构成的有向无环图;span 是应用中一些工作的逻辑表示,span 至少包含操作名称、开始时间、结束时间。
OpenTracing API 特征
tracer实例通过start_span开始新的 span- 每个 span 都有一个操作名称,这里是
say-hello- 操作名称代表了一类的 span ,而不是单一的实例
- Jaeger UI 中可以根据操作名称检索 trace
- 每个 span 必须通过调用它的
finish()方法结束- 使用
with上下文管理器
- 使用
- tracer 将自动捕获 span 的开始时间戳和结束时间戳
1
|
import sys
|
标签(tag)或日志(log)
- 标记用于描述应用于整个 span 的属性。
- 日志包含时间戳,记录更详细的信息
- 规范建议所有日志语句包含一个
event字段,描述正在记录的整个事件,事件的其他属性作为附加字段
- 规范建议所有日志语句包含一个
- Standard Span tags and log fields
程序执行结果
1
|
(env) λ python -m lesson01.solution.hello Bryan
|
Context and Tracing Functions
在一个 trace 中追踪多个 span
SpanReference表示 Span 之间的关系SpanContext可跨进程传播ReferenceType表示关系类型ChildOf:依赖FollowsFrom:后继
- Scope Manager 机制
start_active_span激活 Span(active)- 通过
tracer.active_span访问 Span - 返回
Scope,通过scope.span访问 Span - 结束后才能复原先前活跃的 Span
- 通过
1
|
import sys
|
程序执行结果
1
|
(env) λ python -m lesson02.solution.hello Bryan
|
Tracing RPC Requests
追踪进程边界和 RPC 调用(进程间上下文传播)
inject(spanContext, format, carrier)extract(format, carrier)
format 参数是 OpenTracing API 定义的三种标准编码之一
TEXT_MAP:Span 上下文被编码为键值对的集合BINARY:Span 上下文被编码为不透明的字节数组HTTP_HEADERS:和TEXT_MAP类似,键必须是安全的才能用于 HTTP 头部字段
carrier 是底层 RPC 框架的抽象
- 例如,
TEXT_MAP格式的载体是字典(dictionary),BINARY格式的载体是字节数组(bytearray)
客户端,发起 HTTP 请求
1
|
import requests
|
响应请求 GET 'http://localhost:8081/format?helloTo=Bryan' ,返回字符串 Hello, Bryan!
1
|
from flask import Flask
|
响应请求 GET 'http://localhost:8082/publish?helloStr=hi%20there' ,返回字符串 published,打印字符串 hi there 到标准输出流
1
|
from flask import Flask
|
分别在两个命令行终端启动程序
1
|
# 8081
|
用 curl 发起请求,查看响应结果
1
|
$ curl -s 'http://localhost:8081/format?helloTo=Bryan'
|
使用 Client 程序发起请求
1
|
(env) λ python -m lesson03.solution.hello Bryan
|
两个服务的终端信息输出
1
|
(env) λ python -m lesson03.solution.formatter
|
Baggage
分布式上下文传播,使用 baggage 在调用图中传递数据
- 在多租户系统中传递租期
- 传递顶层调用者的身份信息
- 为混沌工程传递故障注入指令
- 为其他监控的数据传递请求范围的维度,比如分离生产环境与测试环境的流量度量
- 由于可能影响系统性能,因此有大小限制
1
|
import requests
|
修改 formatter 程序,读取 baggage 中的信息,进行判断和打印;publisher 程序不作改动
1
|
from flask import Flask
|
分别在两个命令行终端启动程序,然后使用 client 程序发起请求
1
|
(env) λ python -m lesson04.solution.hello Bryan Bonjour
|
两个服务的终端信息输出
1
|
(env) λ python -m lesson04.solution.formatter
|


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 记一次.NET内存居高不下排查解决与启示
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
2020-11-24 k8s 如何对外提供服务
2020-11-24 mysql5.7安装audit审计插件
2020-11-24 mysql 5.7安装密码校验插件validate_password