

同步同一个Kafka Topic的不同消费者
分布式系统中的同步很困难。您可能的目标是尽可能多地防止它。但有时业务需求需要协调对数据新鲜度有严重依赖的不同服务。 为了概括起见,假设架构由_Service-A_、_Service-B_和_Service-C_组成。它们都使用来自同一个 Kafka 主题的消息,但显然根据各自的业务逻辑、API 和 SLA 对它们进行不同的处理。当 Service-A 处理一条消息时,它会调用 Service-B
分布式系统中的同步很困难。您可能的目标是尽可能多地防止它。但有时业务需求需要协调对数据新鲜度有严重依赖的不同服务。
为了概括起见,假设架构由_Service-A_、_Service-B_和_Service-C_组成。它们都使用来自同一个 Kafka 主题的消息,但显然根据各自的业务逻辑、API 和 SLA 对它们进行不同的处理。当 Service-A 处理一条消息时,它会调用 Service-B 和 Service-C 的 API,并希望该消息包含在其中。这就是为什么 Service-A 只能在 Service-B 和 Service-C 处理成功后才能处理该消息的原因。如果其中一个发生故障或数据没有在那里更新,Service-A 唯一能做的就是停下来等待。换句话说,_从可用性和数据新鲜度_方面对服务-B 和服务-C 存在硬依赖。
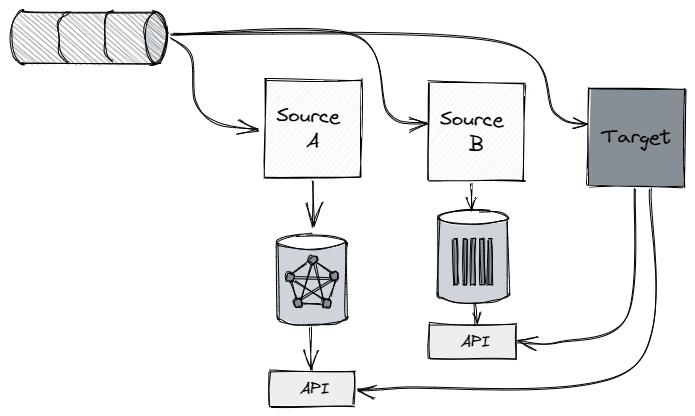
架构挑战是如何通过最可扩展、最具成本效益和最简单的方法在 Service-A 及其依赖项之间进行同步。是的,我相信 Huber 系统的设计原则是降低复杂性。 (如果你还不够信服,可以看看这本很棒的书Philosophy of Software Design,它首先对软件和系统设计中复杂性的危险进行了高尚的解释)。
那么为什么我们最初为自己创造了这个问题?
现在您可能会问自己,如果 Service-A 对消息顺序如此敏感,那么保证顺序的最简单(也许是唯一的一种!)方法是执行 Service-B 和 Service-C 完成的处理,作为内部的串行步骤服务-A。你为什么把它们到处分发?
因此,毫无疑问,微型(或迷你)服务架构是有成本的,但这种架构风格提高了团队的速度,因为每个服务都更容易开发、测试、部署,更重要的是——扩展、维护和操作。这绝对不是我们组织独有的,但就个人而言,通过观察 Dev org 的现实,我已经确信并欣赏这些好处。想象一下,Service-A 是一个 AML 检测过程,它消耗付款并评估其风险。服务 B 处理从同一支付主题中提取的实体关系,服务 C 负责聚合这些支付并提供有效的时间感知聚合查询。与 AML 检测(Service-A)一样,也存在业务逻辑完全不同的欺诈(我们将其命名为 Service-A1),但仍需要查询实体关系图和聚合配置文件。我们不希望每个团队都投资于时间序列数据库和图形数据库技术选择,获得关于如何扩展(或不......)和操作这些的经验,而不是专注于他们各自的业务,即 AML 或欺诈检测。
回到我们最初的问题......
如果我们继续使用 AML 检测作为 Service-A 的具体示例,它如何确保一旦调用关系 API(由 Service-B 公开)或聚合 API(由 Service-C 公开),它就会起床-迄今为止的结果?如果它们由于某种原因暂时下降或减速怎么办?在所有必需的信息可用之前,检测过程无法处理该消息。处理陈旧信息可能最终会错过数百万美元的洗钱!
架构模式
这里的核心思想是利用 Kafka 偏移管理作为跟踪各种服务进度的单一事实来源。偏移量是一个简单的整数,Kafka 使用它来维护消费者的当前位置。当前偏移量是指向 Kafka 在最近轮询中已经发送给消费者的最后一条记录的指针。这样消费者就不会因为当前的偏移量而两次获得相同的记录。由于 Kafka 管理每个主题、消费者组和分区的偏移量,这实际上意味着每个单独的记录只能通过 .消费者如何向 Kafka 提交偏移量有不同的策略,这里我们依赖于仅在消费者成功处理消息后完成的提交。
当 Service-A 从主题中轮询消息时,它应该首先提取该消息的分区和偏移量。然后,它调用 Kafka 管理 API 以验证此偏移量是否已由与 Service-B 和 Service-C 关联的消费者组处理。每个消费者组都会调用 Kafka 管理 API,以检索主题分区到偏移量的映射(查看 Kafka 管理 Java 客户端的listConsumerGroupOffsets函数)。每个分区的最小偏移量表示最慢服务的偏移量。
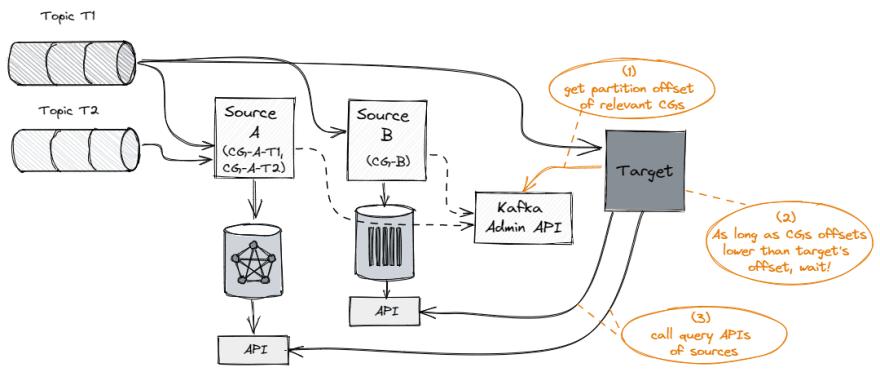
请注意,服务可能会从各种主题中消费,例如使用不同事件类型进行聚合的服务 C,因此服务 A 应该清楚地将其依赖项定义为技术上转换为单个消费者组的组合。
只要 Service-B 和 Service-C 之间的最小偏移量低于 Service-A 消耗的消息偏移量,它就会等待。
更详细的算法......
假设主题 T1 的已提交偏移量如下:
消费者组 CG-A(服务-A):
-
分区 p1 (C1): 0
-
分区 p2 (C1): 0
-
分区 p3 (C2): 0
消费群 CG-B(服务 B):
-
分区p1(C1):30
-
分区p2(C2):30
zz100007 分区pz(Cz):10
消费群 CG-C(Service-C):
-
分区p1(C1):23
-
分区p2(C2):52
-
分区p3(C3):15
如您所见,t1 主题被划分为 3 个分区。 CG-A 和 CG-B 组分别由 3 个消费者组成,因此每个消费者只处理一个分区。但在 CG-A 中,p1 和 p2 都由消费者 C1 处理。
CG-A 中的每个消费者都应该保持更新的分区图。该地图可以定期更新:
for each dependency consumer group // CG-B, CG-C { admin.listConsumerGroupOffsets /// (CG-B -> ( p1 -> 30, p2 -> 30, p3 -> 10)), (CG-C -> ( p1 -> 23, p2 -> 52, p3 -> 15)) update partitionMinOffset map with minimal offset /// (P1 -> 23), (p2 -> 30), (p3 -> 10) }
在正在进行的消息轮询期间:
祖兹 100033
由于最佳实践是防止将分区静态分配给消费者,因此消费者不能假定已处理分区的列表,但需要保留所有主题分区偏移量,因为它可能在任何给定点处理这些分区中的任何一个时间。
假设
这种方式很大程度上是基于Kafka的offset来反映服务的实际进度。实际上,对于如何向 Kafka 提交偏移量有不同的策略。我们在内部使用flink-connector-kafka仅在检查点完成后提交偏移量(当 OffsetCommitMode 设置为 ON_CHECKPOINTS 时)。无论如何,不管具体的技术如何,假设消费者禁用了默认的自动提交,但只有在消息成功处理后才手动提交偏移量,即使在异步操作的情况下也是如此。
建议的替代方案
已经考虑过的另一种方法是,Service-B 和 Service-C 会将已处理消息的消息 ID 省略到专用的输出主题中,而 Service-A 将连接输出主题和原始主题以获得完整的有效负载。只有在所有三个主题中都使用了消息 ID 后,Service-A 才会处理该消息。
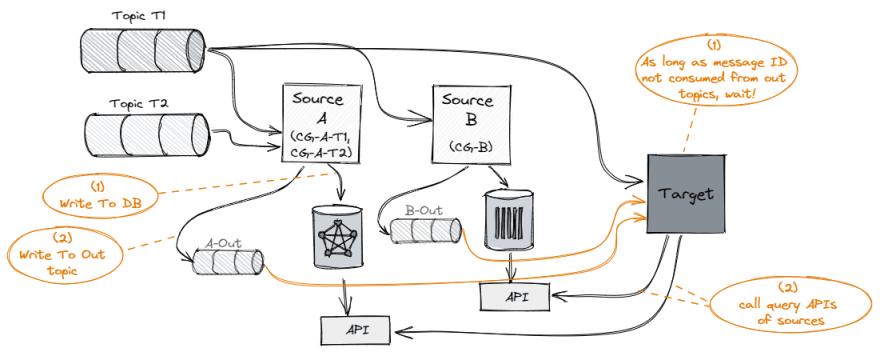
由于以下缺点,这种方法已被拒绝:
-
生产者方面的复杂性:Service-B(和 Service-C)需要写入自己的内部数据库以及输出主题(当然还要提交 Kafka 偏移量)这一事实增加了在某些情况下,DB 和输出主题的这两个接收器可能会不同步。
-
Consumer 方面的复杂性:Service-A 需要加入原始 T1 主题和两个输出主题之间,并小心处理其中一个(或多个)非常落后的情况。它不会崩溃(由于 OOM),而只是停止消费并等待。确实,像 Flink 这样的流处理引擎可以通过管理每个源的阻塞队列来处理背压,但这会大大增加复杂性。
-
大量消息量:这种方法只会显着增加消息的数量,因为每条消息实际上都会被复制(或增加三倍),并且会影响事件总线的性能和成本。
总结
如果您是 Kafka 专家,这对您来说可能很明显,但令人惊讶的是,这并不是那么容易说服人们摆脱额外的输出主题,因为这些主题基本上已经被 Kafka 偏移量本身捕获。
这种模式非常适合同一主题的多个消费者。实际上,即使他们使用不同的主题,只要它们都从一个共同的主题开始,它也可以扩展。但这绝对是更复杂的模式,并证明了后续文章的合理性......


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 记一次.NET内存居高不下排查解决与启示
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
2022-07-14 蓝绿部署、滚动部署、灰度发布(金丝雀发布)