传统虚拟机、物理机环境下,日志文件通常存放于固定的路径下,当应用重启或出现异常退出的情况,日志也会留存下来,不受影响。而 Kubernetes 环境下,提供了相比前者更为细粒度的资源调度,容器(或 Pod)的生命周期是十分短暂的,当主进程退出,容器(或 Pod)便会被销毁,随之而来的是其关联资源也会被释放。因此,在日志采集的这个点上,Kubernetes 场景相比传统环境而言,会更为复杂,需要考虑的点更多。
普遍来说,Kubernetes 环境下的日志采集有如下几种模式:
| | DockerEngine | 业务直写 | DaemonSet | Sidecar |
|---|
| 采集日志类型 |
标准输出 |
业务日志 |
标准输出+部分文件 |
文件 |
| 部署运维难度 |
低 |
低 |
一般,维护daemonSet即可 |
高,每个需采集日志的Pod均需部署Sidecar容器 |
| 隔离程度 |
弱 |
弱 |
一般,只能通过配置间隔离 |
强,通过容器隔离,单独分配资源 |
| 适用场景 |
测试环境 |
对性能要求极高的业务 |
日志分类明确、功能较单一的集群 |
大型集群、PaaS型集群 |
- DockerEngine 直写一般不推荐,也很少会用到;
- 业务直写推荐在日志量极大的场景中使用;
- DaemonSet 一般在节点不超过1000的中小型集群中使用;
- Sidecar 推荐在超大型的集群或是日志需求比较复杂的情况中使用。
因为我司有日志处理分析等需求,所以同时应用了 DaemonSet 与 Sidecar 两种模式。业务直写方案也有少部分复杂场景会用到,因此,本文主要介绍前面两种日志采集模式。
DaemonSet 模式采集日志
由于我们不会在 Kubernetes 下直接运行容器(Kubernetes 的最小资源调度管理单位为 Pod),Kubernetes 会将日志软链至 /var/log/pods/ 与 /var/log/containers 路径下,以帮助我们更好的管理日志。
我们登陆任意一个 k8s 节点:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
[root@ali-k8s-test-002 ~]# cd /var/log/pods/
[root@ali-k8s-test-002 pods]# ls
comp-tools_skywalking-oap-ff949d984-kqnkx_51faece4-3b59-429d-99bf-a8fea9726555
comp-tools_skywalking-ui-95bd55c59-5x2qf_1422b8bd-988a-4739-bc96-53ccd9e164e6
kubesphere-controls-system_kubectl-zhangminghao-6c654bc9c8-m46sj_5eae93cb-fbf4-46a6-ba5c-c728ccb73d1b
kubesphere-devops-system_ks-jenkins-645b997d5f-tvlrs_a0d2ab73-d440-4d85-aa7c-612c3415341e
kubesphere-logging-system_elasticsearch-logging-data-1_6baa822d-f877-4f5f-ba5f-3e0e98a7d617
kubesphere-logging-system_elasticsearch-logging-discovery-0_0611bdb7-1989-4a06-a333-06ff045a4b1d
[root@ali-k8s-test-002 pods]# cd /var/log/containers
[root@ali-k8s-test-002 containers]# ll
总用量 180
lrwxrwxrwx 1 root root 136 4月 12 2021 ack-node-problem-detector-daemonset-vb4wm_kube-system_ack-node-problem-detector-3a8538726f9943d78e81395f29a4c39f3a831042b6264b34bc76068810272b78.log -> /var/log/pods/kube-system_ack-node-problem-detector-daemonset-vb4wm_3d088618-4af7-4def-913a-b85a74b06911/ack-node-problem-detector/0.log
lrwxrwxrwx 1 root root 136 5月 11 2021 ack-node-problem-detector-daemonset-vb4wm_kube-system_ack-node-problem-detector-6b6d7ef089f0fc352afcf3f04aa2a189e92483580e4797fab9298ed7e7eae43f.log -> /var/log/pods/kube-system_ack-node-problem-detector-daemonset-vb4wm_3d088618-4af7-4def-913a-b85a74b06911/ack-node-problem-detector/1.log
|
可以大致的看出其命名结构为: /var/log/pods/<namespace>_<pod_name>_<pod_id>/<container_name>/,/var/log/containers/<pod_name>_<namespace>_<container_id>。(扩展阅读: Where are Kubernetes’ pods logfiles? – StackOverflow )
因此我们只需要在每个节点上都部署采集器,通过 filebeat 等采集器对该路径下的日志进行采集即可。
那么,我们如何方便做到在 k8s 的每个节点上都部署一个采集器呢?这时候我们需要用到 k8s 中 daemonSet 这样的一种资源类型:
DaemonSet 确保全部(或者某些)节点上运行一个 Pod 的副本。 当有节点加入集群时, 也会为他们新增一个 Pod 。 当有节点从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod。 daemonSet | Kubernetes
架构示意如下:
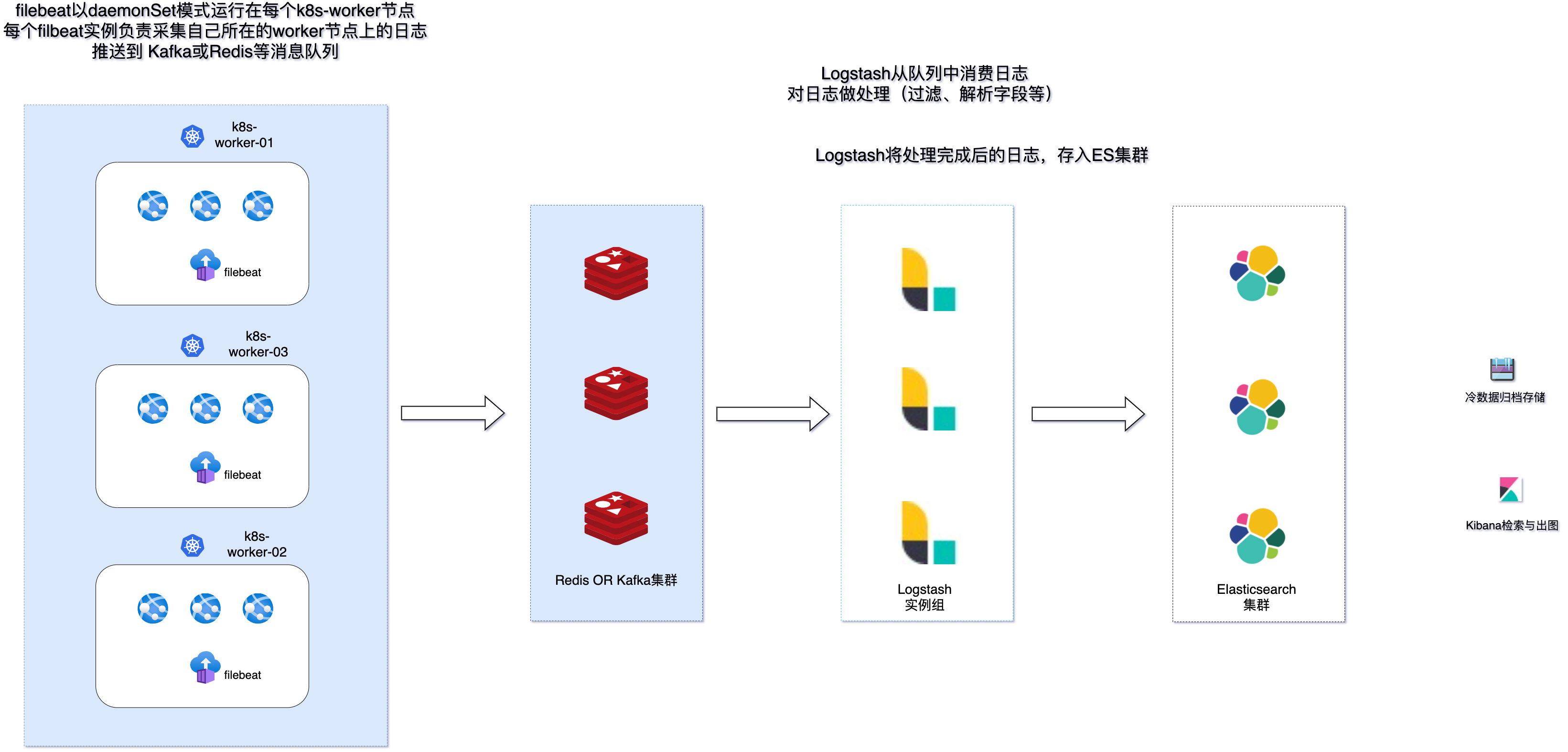
值得注意的是,这种模式下,需要统一应用的日志输出模式为标准输出错误输出,这样才会被日志引擎正确捕捉写入日志文件。同时,目前主流的云服务提供商的 serverless 虚拟 k8s 节点均不支持 daemonSet 模式,有此应用场景的需要使用其他方式来采集日志。
我们大概看一下这种模式的 filebeat 部署文件与配置文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
|
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
namespace: kube-system
name: filebeat
labels:
app: filebeat
spec:
selector:
matchLabels:
app: filebeat
template:
metadata:
labels:
app: filebeat
spec:
serviceAccountName: filebeat
terminationGracePeriodSeconds: 30
hostNetwork: true
dnsPolicy: ClusterFirstWithHostNet
hostAliases:
- ip: "192.168.201.126"
hostnames:
- "kafka01"
containers:
- name: filebeat
image: docker.elastic.co/beats/filebeat:7.14.2
args: [
"-c", "/etc/filebeat.yml",
"-e",
]
env:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
securityContext:
runAsUser: 0
resources:
limits:
memory: 800Mi
requests:
cpu: 400m
memory: 200Mi
volumeMounts:
- name: config
mountPath: /etc/filebeat.yml
readOnly: true
subPath: filebeat.yml
- name: data
mountPath: /usr/share/filebeat/data
- name: varlog
mountPath: /var/log
readOnly: true
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
- name: dockersock
mountPath: /var/run/docker.sock
volumes:
- name: config
configMap:
defaultMode: 0640
name: filebeat-config
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: dockersock
hostPath:
path: /var/run/docker.sock
- name: varlog
hostPath:
path: /var/log
- name: data
hostPath:
|
