

高可用解决方案:同城双活?异地双活?异地多活?怎么实现?

后台服务可以划分为两类,有状态和无状态。高可用对于无状态的应用来说是比较简单的,无状态的应用,只需要通过F5或者任何代理的方式就可以很好的解决。后文描述的主要是针对有状态的服务进行分析。服务端进行状态维护主要是通过磁盘或内存进行保存,比如MySQL数据库,redis等内存数据库。除了这两种类型的维护方式,还有jvm的内存的状态维持,但jvm的状态生命周期通常很短。
高可用的一些解决方案
高可用,从发展来看,大致经过了这几个过程:
- 冷备
- 双机热备
- 同城双活
- 异地双活
- 异地多活
在聊异地多活的时候,还是先看一些其他的方案,这有利于我们理解很多设计的缘由。
冷备
冷备,通过停止数据库对外服务的能力,通过文件拷贝的方式将数据快速进行备份归档的操作方式。简而言之,冷备,就是复制粘贴,在linux上通过cp命令就可以很快完成。可以通过人为操作,或者定时脚本进行。有如下好处:
- 简单
- 快速备份(相对于其他备份方式)
- 快速恢复。只需要将备份文件拷贝回工作目录即完成恢复过程(亦或者修改数据库的配置,直接将备份的目录修改为数据库工作目录)。更甚,通过两次mv命令就可瞬间完成恢复。
- 可以按照时间点恢复。比如,几天前发生的拼多多优惠券漏洞被人刷掉很多钱,可以根据前一个时间点进行还原,“挽回损失”。
以上的好处,对于以前的软件来说,是很好的方式。但是对于现如今的很多场景,已经不好用了,因为:
- 服务需要停机。n个9肯定无法做到了。然后,以前我们的停机冷备是在凌晨没有人使用的时候进行,但是现在很多的互联网应用已经是面向全球了,所以,任何时候都是有人在使用的。
- 数据丢失。如果不采取措施,那么在完成了数据恢复后,备份时间点到还原时间内的数据会丢失。传统的做法,是冷备还原以后,通过数据库日志手动恢复数据。比如通过redo日志,更甚者,我还曾经通过业务日志去手动回放请求恢复数据。恢复是极大的体力活,错误率高,恢复时间长。
- 冷备是全量备份。全量备份会造成磁盘空间浪费,以及容量不足的问题,只能通过将备份拷贝到其他移动设备上解决。所以,整个备份过程的时间其实更长了。想象一下每天拷贝几个T的数据到移动硬盘上,需要多少移动硬盘和时间。并且,全量备份是无法定制化的,比如只备份某一些表,是无法做到的。
如何权衡冷备的利弊,是每个业务需要考虑的。
双机热备
热备,和冷备比起来,主要的差别是不用停机,一边备份一边提供服务。但还原的时候还是需要停机的。由于我们讨论的是和存储相关的,所以不将共享磁盘的方式看作双机热备。
Active/Standby模式
相当于1主1从,主节点对外提供服务,从节点作为backup。通过一些手段将数据从主节点同步到从节点,当故障发生时,将从节点设置为工作节点。数据同步的方式可以是偏软件层面,也可以是偏硬件层面的。
偏软件层面的,比如mysql的master/slave方式,通过同步binlog的方式;sqlserver的订阅复制方式。
偏硬件层面,通过扇区和磁盘的拦截等镜像技术,将数据拷贝到另外的磁盘。偏硬件的方式,也被叫做数据级灾备;偏软件的,被叫做应用级灾备。后文谈得更多的是应用级灾备。
双机互备
本质上还是Active/Standby,只是互为主从而已。双机互备并不能工作于同一个业务,只是在服务器角度来看,更好的压榨了可用的资源。比如,两个业务分别有库A和B,通过两个机器P和Q进行部署。那么对于A业务,P主Q从,对于B业务,Q主P从。整体上看起来是两个机器互为主备。这种架构下,读写分离是很好的,单写多读,减少冲突又提高了效率。
其他的高可用方案还可以参考各类数据库的多种部署模式,比如mysql的主从、双主多从、MHA;redis的主从,哨兵,cluster等等。
同城双活
前面讲到的几种方案,基本都是在一个局域网内进行的。业务发展到后面,有了同城多活的方案。和前面比起来,不信任的粒度从机器转为了机房。这种方案可以解决某个IDC机房整体挂掉的情况(停电,断网等)。
同城双活其实和前文提到的双机热备没有本质的区别,只是“距离”更远了,基本上还是一样(同城专线网速还是很快的)。双机热备提供了灾备能力,双机互备避免了过多的资源浪费。
在程序代码的辅助下,有的业务还可以做到真正的双活,即同一个业务,双主,同时提供读写,只要处理好冲突的问题即可。需要注意的是,并不是所有的业务都能做到。
业界更多采用的是两地三中心的做法。远端的备份机房能更大的提供灾备能力,能更好的抵抗地震,恐袭等情况。双活的机器必须部署到同城,距离更远的城市作为灾备机房。灾备机房是不对外提供服务的,只作为备份使用,发生故障了才切流量到灾备机房;或者是只作为数据备份。原因主要在于:距离太远,网络延迟太大。如上图,用户流量通过负载均衡,将服务A的流量发送到IDC1,服务器集A;将服务B的流量发送到IDC2,服务器B;同时,服务器集a和b分别从A和B进行同城专线的数据同步,并且通过长距离的异地专线往IDC3进行同步。当任何一个IDC当机时,将所有流量切到同城的另一个IDC机房,完成了failover。当城市1发生大面积故障时,比如发生地震导致IDC1和2同时停止工作,则数据在IDC3得以保全。同时,如果负载均衡仍然有效,也可以将流量全部转发到IDC3中。不过,此时IDC3机房的距离非常远,网络延迟变得很严重,通常用户的体验的会受到严重影响的。

异地双活
同城双活可以应对大部分的灾备情况,但是碰到大面积停电,或者自然灾害的时候,服务依然会中断。对上面的两地三中心进行改造,在异地也部署前端入口节点和应用,在城市1停止服务后将流量切到城市2,可以在降低用户体验的情况下,进行降级。但用户的体验下降程度非常大。
所以大多数的互联网公司采用了异地双活的方案。
在这种方式下,由于异地网络问题,双向同步需要花费更多的时间。更长的同步时间将会导致更加严重的吞吐量下降,或者出现数据冲突的情况。吞吐量和冲突是两个对立的问题,你需要在其中进行权衡。例如,为了解决冲突,引入分布式锁/分布式事务;为了解决达到更高的吞吐量,利用中间状态、错误重试等手段,达到最终一致性;降低冲突,将数据进行恰当的sharding,尽可能在一个节点中完成整个事务。
对于一些无法接受最终一致性的业务,饿了么采用的是下图的方式: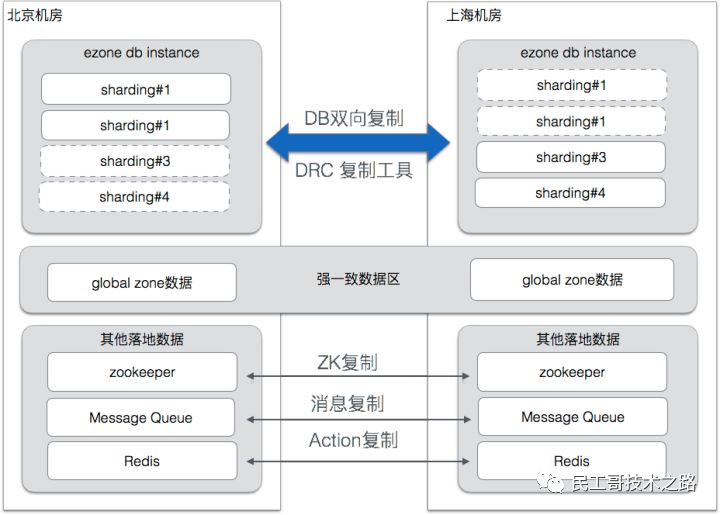
也就是说,在这个区域是不能进行双活的。采用主从而不是双写,自然解决了冲突的问题。
实际上,异地双活和异地多活已经很像了,双活的结构更为简单,所以在程序架构上不用做过多的考虑,只需要做传统的限流,failover等操作即可。但其实双活只是一个临时的步骤,最终的目的是切换到多活。因为双活除了有数据冲突上的问题意外,还无法进行横向扩展。
异地多活
回忆一下我们在解决网状网络拓扑的时候是怎么优化的?引入中间节点,将网状改为星状:
如果我们已经将异地多活的业务部署为上图的结构,很大程度解决了数据到处同步的问题,不过依然会存在大量的冲突,冲突的情况可以简单认为和双活差不多。那么还有没有更好的方式呢?
回顾一下前文提到的饿了么的GlobalZone方案,总体思路就是“去分布式”,也就是说将写的业务放到一个节点的(同城)机器上。阿里是这么思考的:
但是对于电商这种复杂的场景和业务,按照前文说的方式进行sharding已经无法满足需求了。因为业务线非常复杂,数据依赖也非常复杂,每个数据中心相互进行数据同步的情况无可避免。淘宝的解决方式和我们切分微服务的方式有点类似: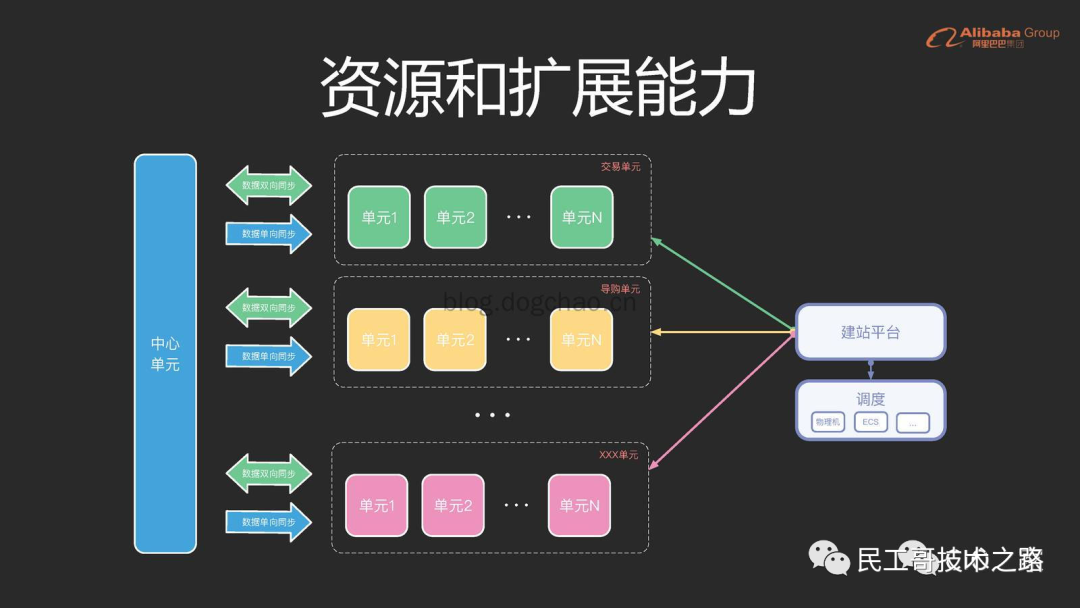
按照业务进行单元切分,已经需要对代码和架构进行彻底的改造了(可能这也是为什么阿里要先从双活再切到多活,历时3年)。比如,业务拆分,依赖拆分,网状改星状,分布式事务,缓存失效等。除了对于编码的要求很高以外,对测试和运维也有非常大的挑战。如此复杂的情况,如何进行自动化覆盖,如何进行演练,如何改造流水线。这种级别的灾备,不是一般公司敢做的,投入产出也不成正比。不过还是可以把这种场景当作我们的“假想敌”,去思考我们自己的业务,未来会怎么发展,需要做到什么级别的灾备。相对而言,饿了么的多活方案可能更适合大多数的企业。
本文只是通过画图的方式进行了简单的描述,其实异地多活是需要很多很强大的基础能力的。比如,数据传输,数据校验,数据操作层(简化客户端控制写和同步的过程)等。
来源 | https://blog.dogchao.cn/?p=299


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 没有源码,如何修改代码逻辑?
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 记一次.NET内存居高不下排查解决与启示
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了