
音频数字信号详解(2022年04月09日更新)
音频数字信号详解
整理者:赤勇玄心行天道
QQ号:280604597
微信号:qq280604597
QQ群:511046632
博客:http://www.cnblogs.com/gaoyaguo http://blog.csdn.net/cyz7758520?type=blog
大家有什么不明白的地方,或者想要详细了解的地方可以联系我,我会认真回复的!
你可以随意转载,无需注明出处!
写文档实属不易,我希望大家能支持我、捐助我,金额随意,1块也是支持,我会继续帮助大家解决问题!

-
信号、Signal
-
信号、Signal
-
信号就是信息的物理表现形式,或者定义为携载信息的自变量函数,信息是信号的具体内容。
根据载体的不同,信号可以分为电的、声音的、光的、磁的、热的、机械的、生物医学的等各类信号。根据一个或多个产生源,信号可分为单通道信号和多通道信号,例如单声道音频、双声道立体声音频、五通道环绕声音频。信号表现上可分为任意时刻都能精确确定信号取值的确定信号,及任意时刻信号取值不能精确确定的随机信号。信号的自变量可以是时间、频率、控件或者其他物理量,按自变量数划分,可以有一维的(多数是以时间或频率为自变量表示,例如音频、心跳等)、二维的(例如黑白图像信号的x,y坐标)、多维的(例如黑白视频信号的x,y坐标及时间t,彩色视频信号的红、绿、蓝三原色的三个三维信号组成的三通道信号)。还有其他划分方法,例如周期信号与非周期信号,功率信号与能量信号等。
在自变量的指定值上信号的取值称为信号的振幅值,也叫幅值或函数值或信号值,作为自变量的函数的振幅值变化称为波形。
-
声音信号、Sound Signal
声音就是先由物体振动产生的声波,声波再通过介质(空气或固体、液体)传播并能被人或动物听觉器官所感知的波动现象。最初发出振动的物体叫声源。振动引起的气压变化的大小称为声压,声压是决定声强即响度的主要因素。气压具有一定的频率,即声波每秒变化的次数,以Hz(赫兹)表示,它决定了声音的高低。声压的测量单位是帕(斯卡)。
通常,人耳只能感受到20Hz至20000Hz的声波,低于20Hz的叫次声波,高于20000Hz的叫超声波,20Hz至250Hz的叫低频,250Hz至2000Hz的叫中低频,2000Hz至6000Hz的叫中高频,6000Hz至20000Hz的叫高频,人说话声音的语音频率(也叫语频)一般在200Hz至3200Hz,人耳对1000Hz至3000Hz的声波感受力最强,足够强的次声波会对人体产生伤害。国际制定的数字电话机的通信标准是300Hz至3400Hz。
声音的频率越高,传播的距离越近;声音的频率越低,传播的距离越远。因为高频的声音在传播中衰减比较快。
人耳对于其中每一种频率,都有一个刚好能引起听觉的最小可听强度(minimal audible intensity),这个最小可听强度称为听阈(hearing threshold)。当振动强度在听阈以上继续增加时,听觉的感受也相应增强,但当振动强度增加到某一限度时,它引起的将不单是听觉,同时还会引起鼓膜的疼痛感觉,这个限度称为痛阈,或者最大可听强度(maximal audible intensity)。在这两者之间即为人的听觉响应范围,又称听域。
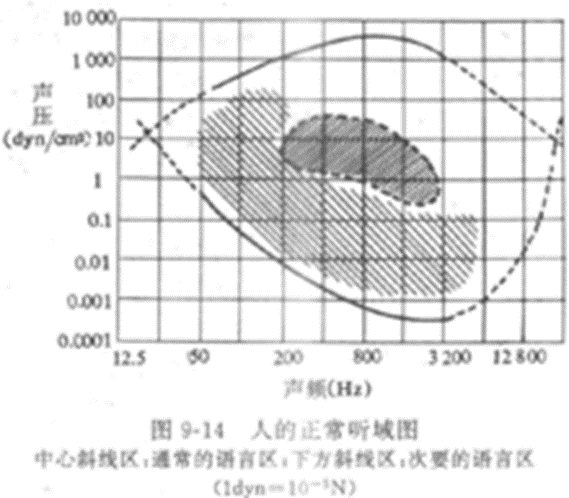
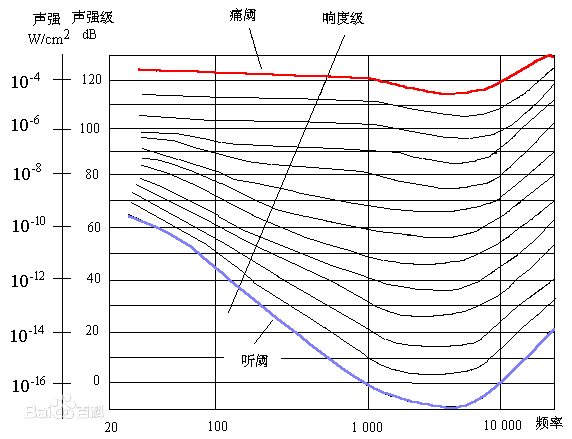
音速是指介质中微弱压强扰动的传播速度,其大小因介质的性质和状态而异。空气中的音速在1个标准大气压和15℃的条件下约为340m/秒。在航空上,通常用M(马赫)来表示音速,1马赫就是1倍音速,2马赫就是2倍音速,超过1倍音速的叫超音速,超过5倍音速的叫高超音速。
-
音频信号、Audio Signal
音频信号是指声波的频率、幅度变化的信息载体。载体可以为电信号、磁带、磁盘、等。
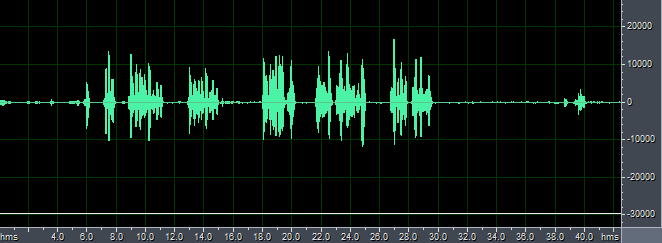
下图就是一段音频信号的时域波形图:
-
图像信号、Image Signal
图像信号是指像素的频率、幅度变化的信息载体。载体可以为电信号、磁带、磁盘、等。
下图就是一张图像信号的黑白像素图:

-
视频信号、Video Signal
视频信号是指图像的频率、幅度变化的信息载体。载体可以为电信号、磁带、磁盘、等。
下图就是一段视频信号的黑白像素图:






-
信号分类
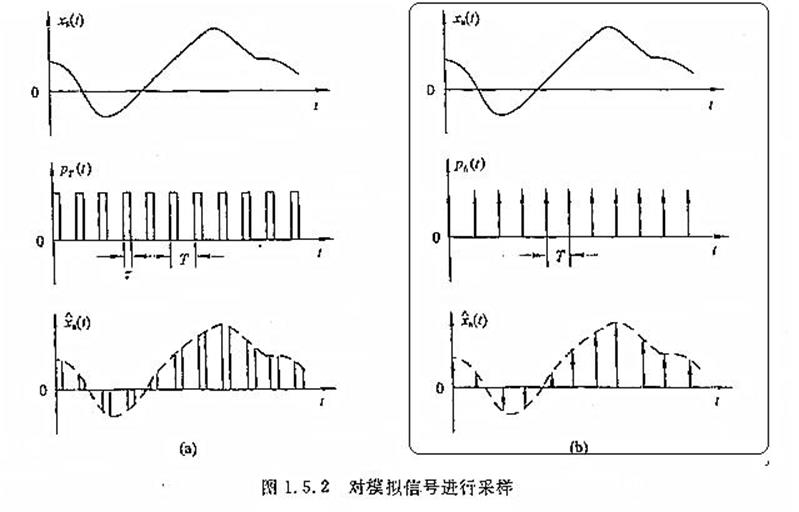
连续时间连续幅值信号是指在以时间为自变量的一维信号中,除个别不连续点外,信号在所讨论的时间段内的任意时间点都有确定的振幅值,且振幅值在取值范围内也有任意种取值。该信号也叫模拟信号。
连续时间离散幅值信号是指在以时间为自变量的一维信号中,除个别不连续点外,信号在所讨论的时间段内的任意时间点都有确定的振幅值,但振幅值在取值范围内只有特定种取值。该信号也叫量化信号。
连续时间连续幅值信号和连续时间离散幅值信号都称为连续时间信号。
例如:信号的时间和幅值都是连续的,即为模拟信号。
离散时间连续幅值信号是指在以时间为自变量的一维信号中,只在离散时间瞬间才有幅值,在其它时间没有,但振幅值在取值范围内有任意种取值。该信号也叫采样信号、抽样信号、取样信号、脉冲信号。
离散时间离散幅值信号是指在以时间为自变量的一维信号中,只在离散时间瞬间才有幅值,在其它时间没有,且振幅值在取值范围内也只有特定种取值。该信号也叫数字信号。
离散时间连续幅值信号和离散时间离散幅值信号都称为离散时间信号,也常称为序列。
确定信号(Deterministic Signal)是指能用确定的数学函数表示的信号,任意时刻都有确定的幅值,预先可以知道该信号的变化规律。
随机信号(Random Signal)是指不能数学函数表示的信号,不能预先可以知道该信号的变化规律。
周期信号是指按照一定的时间间隔周而复始,并且无始无终的信号。
他们的表达式可以写作:
其中称为的周期,而满足关系式的最小值则称为是信号的基本周期。
非周期信号是指该信号在时间上不具有周而复始的特性,即周期信号的周期趋于无限大。
空域信号是指以距离为自变量的信号。
时域信号是指以时间为自变量的信号。
频域信号是指以频率为自变量的信号。
实信号是指现实中真实的、可以测量到的信号。
虚信号是指不存在、虚拟出来的信号,但为了计算方便而引入的概念。
实数信号是指由实数组成的信号。
虚数信号是指由虚数组成的信号。
复数信号是指有复数组成的信号。
共轭对称是指当一个函数的实部为偶函数,虚部为奇函数时,此函数就为共轭对称函数,即的共轭等于。
连续时间信号和离散时间信号与周期信号和非周期信号彼此包含,即连续时间信号和离散时间信号中有周期信号和非周期信号,同理,周期信号和非周期信号中也包含连续时间信号和离散时间信号。
模拟信号是指用连续变化的物理量所表达的信息,其信号的幅度,或频率,或相位随时间作连续变化,如温度、湿度、压力、长度、电流、电压等等,我们通常又把模拟信号称为连续信号,它在一定的时间范围内可以有无限多个不同的取值。而数字信号是指在取值上是离散的、不连续的信号。
数字信号处理利用计算机的信号处理设备,采用数值计算的方法对信号进行处理的一门学科,包括滤波、变换、压缩、扩展、增强、复原、估计、识别、分析、综合等加工处理,已达到提取有用信息、便于应用的目的。
在数字信号处理领域,量化是指将信号的连续取值(或者大量可能的离散取值)近似为有限多个(或较少的)离散值的过程。量化主要应用于从连续信号到数字信号的转换中。连续信号经过采样成为离散信号,离散信号经过量化即成为数字信号。注意离散信号通常情况下并不需要经过量化的过程,但可能在值域上并不离散,还是需要经过量化的过程。信号的采样和量化通常都是由模数转换器实现的。
-
数字信号处理系统、Digital Signal Processing System

防混叠模拟低通滤波器:把会造成混叠失真的高频分量滤除掉。
-
模数转换器、调制器、Analog to Digital Converter、ADC
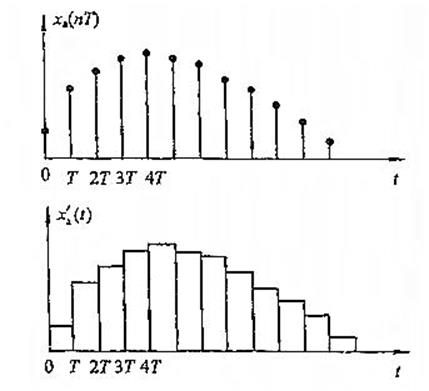
模拟信号转换成数字信号的过程叫做模数转换,简写成A/D,完成这种功能的电路叫做模数转换器,也叫调制器,简称ADC。模数转换器的框图如图所示:
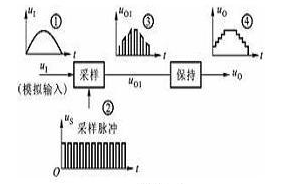
输入端输入的模拟信号,经采样、保持、量化和编码四个过程的处理,转换成对应的二进制数码输出。采样就是利用模拟开关将连续变化的模拟量变成离散的数字量,如上图中波形③所示。由于经采样后形成的数字量宽度较窄,经过保持电路可将窄脉冲展宽,形成梯形波,如波形④所示。量化就是将阶梯形模拟信号中各个值转化为某个最小单位的整数倍,便于用数字量来表示。编码就是将量化的结果(即整数倍值)用二进制数码来表示。这个过程就实现了模数转换。目前集成模数转换器种类较多,有8位、10位模数转换器。

实例:

-
数模转换器、解调器、Digital to Analog Converter、DAC
数字信号转换成模拟信号的过程叫做数模转换,简写成D/A,完成这种功能的电路叫做数模转换器,也叫解调器,简称DAC。


原始信号
采样并转化后的数字信号
理想滤波器滤波(1.5.9式的实现过程)
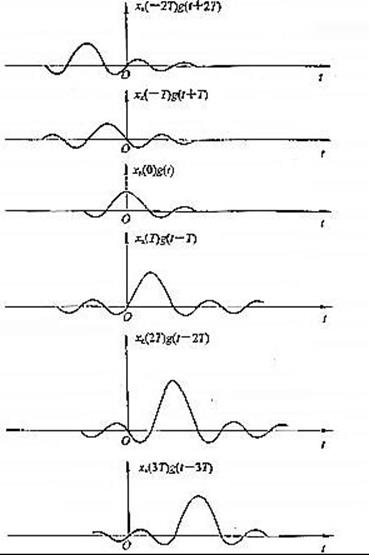
最终还原后的信号
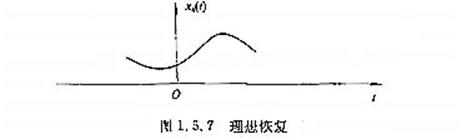
M:理论上,满足采样定理采样得到的数字信号,忽略量化误差,经过理想低通滤波器的滤波,能过无误差的恢复(完全恢复)原始信号。但实际上,有量化误差,而且理想低通滤波器是不存在的(非因果系统),所以需要找到能够逼近理性低通滤波器的可行方案。

零阶保持器的单位冲击响应(DAC的单位冲击响应)
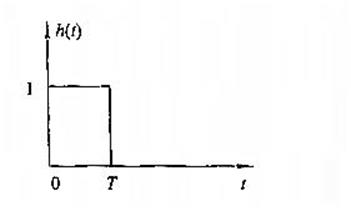
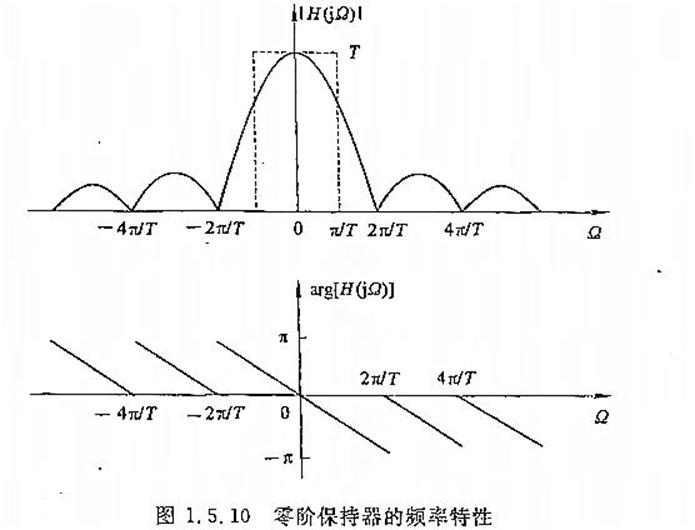
零阶保持器的频率特性(理想低通滤波器的一种逼近方式)
零阶保持器对一个数字信号的恢复过程
-
音频数字信号
-
音频对讲方式
-
非实时单工音频对讲、Non-real-time Simplex Audio Talkback
-
-
一方只发送提前录制的音频信号,其他方只接收音频信号。例如:语音留言机、等等。
-
实时单工音频对讲、Real-time Simplex Audio Talkback
一方只发送实时的音频信号,其他方只接收音频信号。例如:语音广播、收听收音机、音频直播、等等。
-
非实时双工音频对讲、Non-real-time Duplex Audio Talkback
各方都可以发送提前录制的音频信号,并接收其他方发送的音频信号。例如:语音消息、等等。
-
实时半双工音频对讲、Real-time Half-duplex Audio Talkback
各方都可以发送实时的音频信号,并接收其他方发送的音频信号,但接收和发送不能同时进行。例如:PTT一键即按即通对讲、等等。
-
实时全双工音频对讲、Real-time Full-duplex Audio Talkback
各方都可以发送实时的音频信号,并接收其他方发送的音频信号,接收和发送同时进行。例如:固定电话、移动电话、网络电话、等等。
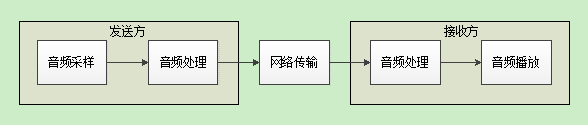
网络电话,也称互联网电话、IP电话、Voice over Internet Protocol、VoIP,是指通话双方将音频信号以数据包的形式在互联网上进行传输,从而实现打电话的功能。网络电话的优点就是资费很低,甚至是免费的,缺点就是网络信号稳定性比电话网要差。
网络电话通常是双向同时进行的,也就是全双工的。一方说话,另一方则听到声音,看似简单,但是其背后的流程却十分复杂,其各个主要环节简化后如下图所示:
-
音频数字信号采样、录音、Audio Record、数字录音、Digital Record
-
原理
-
音频数字信号采样是指,从振动单元采集音频模拟信号,然后转换成音频数字信号,最后存储到存储器中。
音频数字信号采样的主要流程:

振动单元:
当声波到达振动单元时,声波带会带动振动单元一起共振。
不同振动材料在共振时,幅度一定会有些许区别,从而导致会有不同程度的失真。
下图就是一个话筒的振膜:

音频模拟信号:
振动单元在振动时,会产生一个功率随振动幅度变化的交流电信号,这个交流电信号就是音频模拟信号。
把这个幅度值用二维坐标图画出来就是:
信号功率放大:
由于从振动单元出来的音频模拟信号的功率非常小,不足以驱动做后续的电路,所以要将其功率放大到一定的倍数。
不同的放大电路在放大后,幅度一定会有些许区别,从而导致会有不同程度的失真。
抖动:
添加一定的随机噪音,为了防止一些谐波失真等问题。
防混叠模拟低通滤波器:
防止频率混叠造成的失真问题。
不同的防混叠模拟低通滤波器在滤波后,残留的混叠频率可能会有些许区别,从而导致会有不同程度的失真。
模数转换器:
用于将模拟信号转换为数字信号,由于计算机不能处理模拟信号,只能处理一个一个的数据,所以我们要做这个转换。
不同的模数转换器在转换后,数字信号可能会有些许区别,从而导致会有不同程度的失真。
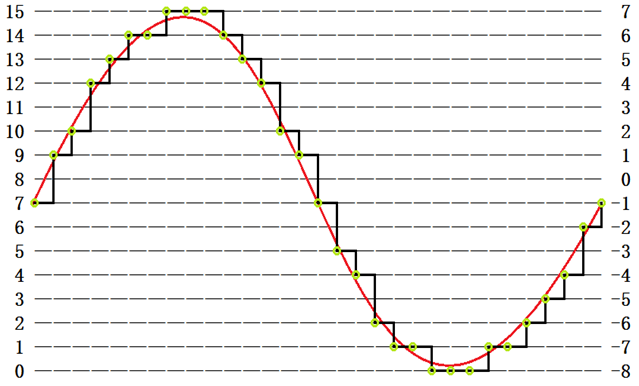
转换原理大致就是每隔一小段时间就采样一次这个时刻的幅度并量化,如下图:
音频数字信号:
经过模数转换后,音频模拟信号就可以量化成一个4位有符号整型序列:{-1,1,2,4,5,6,6,7,7,7,6,5,4,2,1,-1,-3,-4,-6,-7,-7,-8,-8,-8,-7,-7,-6,-5,-4,-2,-1},也可以量化成一个4位无符号整型序列:{7,9,10,12,13,14,14,15,15,15,14,13,12,10,9,7,5,4,2,1,1,0,0,0,1,1,2,3,4,6,7},这个序列就是音频数字信号了。
转换后的数字信号和转换前的模拟信号是有一定的量化误差的,量化误差越大,失真就越大,量化误差越小,失真就越小。
传输:
将转换出来的音频数字信号传输到接收设备里。
不同的传输线材和周围环境在传输后,音频数字信号可能会有些许错误,从而导致会有不同程度的失真。
纠错:
由于传输过程中可能有干扰导致音频数字信号出现错误,所以接收设备在接收到后需使用纠错算法检查出错误的数据并修正。
不同的纠错算法在纠错后,音频数字信号可能会有些许的残留错误,从而导致会有不同程度的失真。
存储:
接收设备最后将音频数字信号存储到对应的存储器,比如内存、硬盘、磁带、光盘、等等。
不同的存储器在存储后,音频数字信号可能会有些许错误,从而导致会有不同程度的失真。
-
音频通道、Audio Channel、声道、Channel
我们可以简单的理解为通过一个振动单元采样到的音频就是一个声道,两个振动单元就是两个声道,以此类推。
一个麦克风里面有的有一个振动单元,有的有两个振动单元。一个振动单元的麦克风进行的是Mono单声道录音,两个振动单元的麦克风进行的是Stereo双声道立体声录音。五声道环绕立体声录音就是麦克风1录取东北方向的声音,麦克风2录取西北方向的声音,麦克风3录取西南方向的声音,麦克风4录取东南方向的声音,麦克风5录取正前方的声音。另外还有四声道环绕立体声录音和七声道环绕立体声录音。
单声道麦克风: ,双声道立体声麦克风:
,双声道立体声麦克风: 。
。
采样频率就是每秒对音频模拟信号的采样次数,单位赫兹。采样频率越高,音频数字信号就越接近之前的音频模拟信号,音质也就越好,硬件成本也就越高,存储空间占用也就越大。
常见音频采样频率有:
8000 Hz:电话所用采样频率,对于人的说话已经足够。
11025 Hz:
12000 Hz:
16000 Hz:电话所用采样频率,比8000 Hz电话听起来更有细节感。
22050 Hz:无线电广播所用采样频率。
24000 Hz:
32000 Hz:电话所用采样频率,比16000 Hz电话听起来更细腻。miniDV 数码视频 camcorder、DAT(LP mode)所用采样频率。
44100 Hz:音频CD,也常用于MPEG-1音频(VCD,SVCD,MP3)所用采样频率。
47250 Hz:Nippon Columbia(Denon)开发的世界上第一个商用PCM录音机所用采样频率。
48000 Hz:电话所用采样频率,比32000 Hz电话听起来更真实。miniDV、数字电视、DVD、DAT、电影和专业音频所用的数字声音所用采样频率。
50000 Hz:二十世纪七十年代后期出现的3M和Soundstream开发的第一款商用数字录音机所用采样频率。
50400 Hz:三菱 X-80 数字录音机所用所用采样频率。
96000 Hz、192000 Hz:DVD-Audio、一些LPCM DVD音轨、Blu-ray Disc(蓝光盘)音轨、和HD-DVD (高清晰度 DVD)音轨所用所用采样频率。
2822400 Hz:SACD、索尼和飞利浦联合开发的称为 Direct Stream Digital 的 1 位 sigma-delta modulation 过程所用采样频率。
-
采样周期、Sampling Period、Sampling Cycle、采样间隔、Sampling Interval
采样周期就是两次采样之间的时间间隔,单位秒。
计算公式:1÷采样频率。
例如:如果采样频率为8000Hz,则采样周期为1/8000秒;如果采样频率为16000Hz,则采样周期为1/16000秒。
-
采样位数、Sampling Bit、Sampling Digit、位深、Bit Depth
采样位数可以理解数字音频设备处理声音的解析度,即对声音的辨析度。采样位数一般有8位、16位、24位、32位等,就像表示颜色的表示位数一样(8位能表示256种颜色,16位能表示65536种颜色)。
采样位数越高,采样数据的级别越密集,幅值量化就越精准,音质也就越好,但硬件成本也就越高,存储空间占用也就越高。16位采样已经接近了人听觉极限和痛苦极限,是音乐的理想范围,一般采样位数都是这么高了。
-
采样数据、Sampling Data
采样数据就是指每一次采样所得到的那个振幅值。具体取值范围如下:
|
采样位数 |
数据类型 |
取值区间 |
|
8位 |
无符号整型 |
|
|
8位 |
有符号整型 |
|
|
16位 |
无符号整型 |
|
|
16位 |
有符号整型 |
|
|
24位 |
无符号整型 |
|
|
24位 |
有符号整型 |
|
|
32位 |
无符号整型 |
|
|
32位 |
有符号整型 |
|
|
看情况 |
有符号浮点型 |
采样单元就是指一次采样所得到的全部声道的采样数据。
例如:单声道音频的每个采样单元只包含一个采样数据,双声道音频的每个采样单元包含两个采样数据,以此类推。
-
帧、Frame、帧的长度、帧长、Frame Length
帧就是将多个连续的采样数据分为一组,一般是以时间为单位进行分帧,主要是为了便于处理采样数据。例如:音频编解码一般是以帧为单位进行的,每次编解码一帧。
帧的长度是指一帧包含多少个采样单元、或多少个采样数据、或多少个字节。
帧的长度计算公式(单位采样单元):采样频率×时间。
例如:采样频率为16000Hz,每帧的时间为20ms即0.02s,那么每帧的长度为:16000×0.02=320个采样单元。
帧的长度计算公式(单位采样数据):声道数×采样频率×时间。
例如:声道数为1,采样频率为16000Hz,每帧的时间为20ms即0.02s,那么每帧的长度为:1×16000×0.02=320个采样数据。
帧的长度计算公式(单位字节):声道数×采样频率×(采样位数÷8)×时间。
例如:声道数为1,采样频率为16000Hz,采样位数为16位,每帧的时间为20ms即0.02s,
那么每帧的长度为:16000×1×0.02=320个采样数据,1×16000×(16÷8)×0.02=640个字节。
-
帧率、Frame Rate
帧率就是每秒的帧数,单位为f/s、frames per second、fps。
例如:采样频率为16000Hz,帧的长度为320个采样单元,那么每帧的时间为20ms,则每秒有1000÷20=50帧,帧率为50帧/秒。
-
字节率、Byte Rate
字节率就是每秒的字节数,单位为B/s、byte per second、Bps。
-
比特率、Bit Rate
比特率就是每秒的二进制位数,单位为bit/s、bit per second、bps。
-
脉冲编码调制、脉码调制、Pulse Code Modulation、PCM
我们采样到的最原始的音频数字信号的那一串数列就是脉冲编码调制格式的,也叫PCM格式。具体格式如下:
|
声道数 |
采样位数 |
字节1 |
字节2 |
字节3 |
字节4 |
字节5 |
字节6 |
字节7 |
字节8 |
…… |
|
单声道 |
8位 |
采样单元1 |
采样单元2 |
采样单元3 |
采样单元4 |
采样单元5 |
采样单元6 |
采样单元7 |
采样单元8 |
…… |
|
FRONT 前声道 |
FRONT 前声道 |
FRONT 前声道 |
FRONT 前声道 |
FRONT 前声道 |
FRONT 前声道 |
FRONT 前声道 |
FRONT 前声道 |
|||
|
单声道 |
16位 |
采样单元1 |
采样单元2 |
采样单元3 |
采样单元4 |
…… |
||||
|
FRONT 前声道 |
FRONT 前声道 |
FRONT 前声道 |
FRONT 前声道 |
|||||||
|
双声道 |
8位 |
采样单元1 |
采样单元2 |
采样单元3 |
采样单元4 |
…… |
||||
|
LEFT 左声道 |
RIGHT 右声道 |
LEFT 左声道 |
RIGHT 右声道 |
LEFT 左声道 |
RIGHT 右声道 |
LEFT 左声道 |
RIGHT 右声道 |
|||
|
双声道 |
16位 |
采样单元1 |
采样单元2 |
…… |
||||||
|
LEFT 左声道 |
RIGHT 右声道 |
LEFT 左声道 |
RIGHT 右声道 |
|||||||
注意:16位的采样数据保存到文件中会有大端小端的区别,请根据实际情况选择,一般为小端。
通常情况下多声道音频数据格式如下:
1: F (Mono)
2: FL FR (Stereo)
2.1: FL FR LFE (2.1 surround)
4: FL FR BL BR (quad surround)
5: FL FR FC BL BR (quad + center)
5.1: FL FR FC LFE SL SR (5.1 surround - last two can also be BL BR)
6.1: FL FR FC LFE BC SL SR (6.1 surround)
7.1: FL FR FC LFE BL BR SL SR (7.1 surround)
-
响度、Loudness、音量、Volume、声压级、Sound Presure Level、SPL、分贝、Decibel
声音的强弱叫做响度,也叫音量,单位为分贝。
分贝中,分指十分之一(deci),贝指贝尔(电话之父——亚历山大·格拉汉姆·贝尔,bel),合起来就是decibel(音标[ˈdesɪbel]),简称dB。
分贝的定义:两个同类功率量或可与功率类比的量之比值的常用对数乘以10等于1时的级差。在中华人民共和国法定单位的补充说明中对"可与功率类比的量"加以了说明:"通常是指电流平方、电压平方、质点速度平方、声压平方、位移平方、速度平方、加速平方、力平方、振幅平方、场强和声能密度等"。
分贝的计算公式:,表示当前功率量,表示参考功率量,表示分贝。
响度的计算公式:,表示当前音频电压,表示参考音频电压,表示分贝。
为什么分贝的计算公式要用对数?因为人耳对声音强弱程度的感知是对数关系,而不是线性关系,比如从静音开始线性提高电压,刚开始觉得声音变强比较明显,当达到了一定强度后,再提高电压就会感觉声音变强不怎么明显了。
为什么分贝的计算公式要乘以10?因为对数算出来的数值比较小,乘以10是为了提高10倍,方便化成整数使用。
为什么计算出来的分贝值不符合国家标准?因为一般的音频输入设备采样到的音频数据与国家标准定义的声压级不匹配。
SPL(Sound Presure Level)声压级,单位为Pa。比如1米外步枪射击的声音大概是7000Pa,10米外开过的汽车大概为0.2Pa。使用声压作为作为测量量的分贝单位为dBSPL。
声压级的计算公式:,表示当前声压,单位为Pa,表示参考声压,单位为Pa,表示分贝。
这里参考声压选择0.00002Pa,即20uPa,差不多是人耳在1000Hz时能听到的最小声音。
例如:1Pa声压的声压级。
以下是有符号16位采样数据对应到响度的曲线:
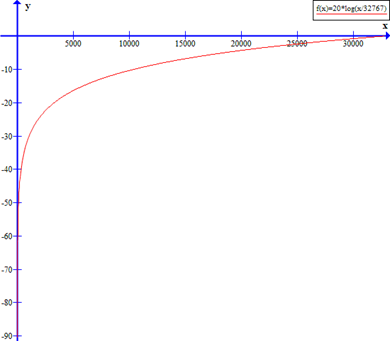
以下是响度对应到有符号16位采样数据的曲线:
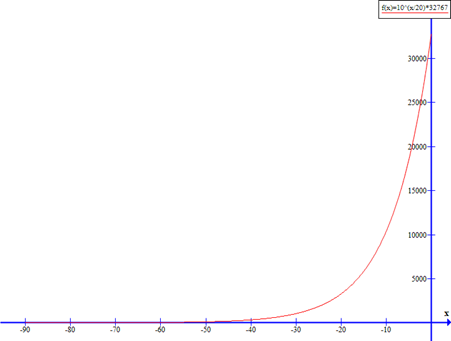
|
采样数据 |
参考振幅值 |
最小值 |
最大值 |
动态范围 |
|
有符号8位 |
||||
|
无符号8位 |
||||
|
有符号16位 |
||||
|
无符号16位 |
||||
|
有符号24位 |
||||
|
无符号24位 |
||||
|
有符号32位 |
||||
|
无符号32位 |
||||
-
响度调节、音量调节、分贝调节
令,。
为调节前的响度量,为要调节的响度增量,为调节前的音频电压,为调节后的音频电压。
-
音频输入设备性能参数、灵敏度、频率响应曲线、本底噪音、信噪比、总谐波失真、最大声压级、指向性
音频输入设备又称为话筒、麦克风、传声器、咪头、咪芯、拾音器、监听器、监听头、等等。
音频输入设备的基本性能参数如下:
灵敏度、Sensitivity:
表示音频输入设备对1000Hz正弦波94dB声压级或1Pa声压的声音的响应程度。
高灵敏度的音频输入设备可以与较弱的声音共振,从而记录距离较远或音量较低的声音。
低灵敏度的音频输入设备只能与较强的声音共振,只能记录距离较近或音量较高的声音。
计算方法:
对于输出为音频模拟信号的音频输入设备,参考电压为1V,如果输出的交流电信号的电压为0.01V,则灵敏度为
对于输出为音频数字信号的音频输入设备,参考振幅值为32767,如果输出的数字信号为327,则灵敏度为
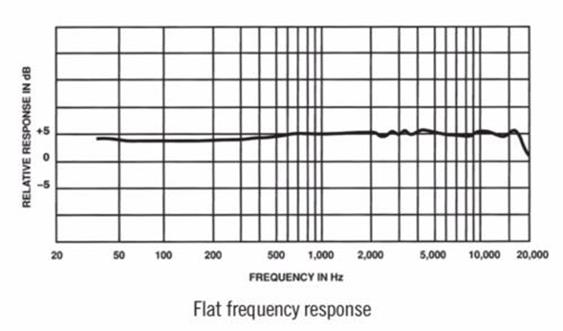
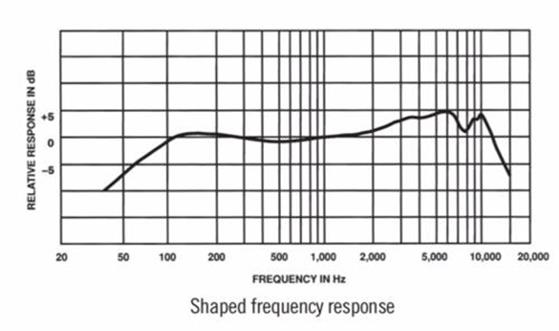
频率响应曲线、Frequency Response Curve、频响曲线:
表示音频输入设备对20Hz至20000Hz正弦波94dB声压级或1Pa声压的声音的响应程度所连成的曲线。
频响曲线其实就是在不同频率下的灵敏度。
频响曲线越平直,失真就越小,但有些场合可能需要有形状的频响曲线。
|
平直的频响曲线 |
有形状的频响曲线 |
|
|
|
本底噪音、Noise floor:
表示音频输入设备在没有任何声音输入时的响应程度。
本底噪音越小,失真就越小。
计算方法:
对于输出为音频模拟信号的音频输入设备,参考电压为1V,如果输出的交流电信号的电压为0.00003V,则本底噪音为
对于输出为音频数字信号的音频输入设备,参考振幅值为32767,如果输出的数字信号为1,则本底噪音为
信噪比、Signal to Noise Ratio、SNR:
表示音频输入设备对1000Hz正弦波94dB声压级或1Pa声压的声音的响应程度与音频输入设备在没有任何声音输入时的响应程度之比。
信噪比越大,失真就越小。
计算方法:
对于输出为音频模拟信号的音频输入设备,参考电压为1V,如果输出的交流电信号的电压分别为0.01V和0.00003V,则信噪比为
对于输出为音频数字信号的音频输入设备,参考振幅值为32767,如果输出的数字信号为327和1,则信噪比为
总谐波失真、Total Harmonic Distortion、THD:
表示音频输入设备对1000Hz正弦波94dB声压级或1Pa声压的声音所产生的所有谐波的功率与基波的功率之比。
振动单元在与声音共振时,会产生一定的谐波,原始声音称为基波,谐波的频率为基波的正整数倍,一倍频率的谐波称为一次谐波,二倍频率的谐波称为二次谐波,以此类推,一次谐波也就是基波。
总谐波失真越小,失真就越小,通常小于1%人耳就分辨不出来了。
计算方法:
最大声压级、Acoustic Overload Point、AOP、声过载点:
表示音频输入设备对1000Hz正弦波的声音总谐波失真小于10%的最大声压级。
常见音频输入设备的最大声压级为120dB声压级,某些低灵敏度的可以达到130dB声压级。
最大声压级越高,在强音环境下失真越小。
指向性、Directivity:
表示音频输入设备对声音的采集方向,全向型的音频输入设备可以采集整个现场的声音,定向型的音频输入设备只能采集某个或某几个方向的声音。
|
全向型 |
心型 |
超心型 |
枪型 |
双向型、8字型 |
|
|
|
|
|
|

基本性能参数只是简单的反应了性能情况,并不能完整的判断出实际的性能表现,所以还是要实际测试才能知道。
-
音频数字信号还原、回放、Audio Playback、播放、Audio Play、数字回放、Digital Playback
-
原理
-
音频数字信号还原是指,从存储器中读取音频数字信号,然后转换成音频模拟信号,最后驱动振动单元。
音频数字信号还原的主要流程:

存储:
发送设备从存储器中读取音频数字信号。
不同的存储器在读取后,音频数字信号可能会有些许错误,从而导致会有不同程度的失真。
音频数字信号:
就是之前的整型序列。
传输:
将读取出来的音频数字信号传输到音频设备里。
不同的传输线材和周围环境在传输后,音频数字信号可能会有些许错误,从而导致会有不同程度的失真。
纠错:
由于传输过程中可能有干扰导致音频数字信号出现错误,所以音频设备在接收到后需使用纠错算法检查出错误的数据并修正。
不同的纠错算法在纠错后,音频数字信号可能会有些许的残留错误,从而导致会有不同程度的失真。
数模转换器:
用于将模拟信号转换为数字信号,由于音频设备不能播放数字信号,只能播放模拟信号,所以我们要做这个转换。
不同的数模转换器在转换后,模拟信号可能会有些许区别,从而导致会有不同程度的失真。
信号功率放大:
由于从数模转换器出来的音频模拟信号的功率非常小,不足以驱动做后续的电路,所以要将其功率放大到一定的倍数。
不同的放大电路在放大后,幅度一定会有些许区别,从而导致会有不同程度的失真。
振动单元:
振动单元在大功率的音频模拟信号驱动下产生振动,从而产生声波。
不同振动材料在振动时,幅度一定会有些许区别,从而导致会有不同程度的失真。
下图就是一个扬声器的振膜:

-
音频输出设备性能参数、灵敏度、频率响应曲线、本底噪音、信噪比、总谐波失真、最大声压级
音频输出设备又称为扬声器、耳机、听筒、音箱、音响、等等。
音频输出设备的基本性能参数如下:
灵敏度、Sensitivity:
表示音频输出设备在输入端加上1000Hz正弦波1V或1mV或1W或1mW的电信号、距离音频输出设备正前方1米或0米处所产生声音的声压级。
灵敏度越高,音频输出设备在同等功率下发出的声音越强。
频率响应曲线、Frequency Response Curve、频响曲线:
表示音频输出设备在输入端加上20Hz至20000Hz正弦波1V或1mV或1W或1mW的电信号、距离音频输出设备正前方1米或0米处所产生声音的声压级。
频响曲线其实就是在不同频率下的灵敏度。
频响曲线越平直,失真就越小,但有些场合可能需要有形状的频响曲线。
阻抗、Impedance:
表示音频输出设备在输入端加上1000Hz正弦波的电信号的总阻值,包括电阻、电容、电感。
通常阻抗越高,灵敏度越低,低音表现越好。
阻抗曲线、Impedance Curve:
表示音频输出设备在输入端加上20Hz至20000Hz正弦波的电信号的总阻值所连成的曲线,包括电阻、电容、电感。
本底噪音、Noise floor:
信噪比、Signal to Noise Ratio、SNR:
总谐波失真、Total Harmonic Distortion、THD:
表示音频输出设备在输入端加上1000Hz正弦波1W或1mW声压的电信号所产生声音的所有谐波的功率与基波的功率之比。
振动单元在与声音共振时,会产生一定的谐波,原始声音称为基波,谐波的频率为基波的正整数倍,一倍频率的谐波称为一次谐波,二倍频率的谐波称为二次谐波,以此类推,一次谐波也就是基波。
最大声压级、Acoustic Overload Point、AOP、声过载点:
表示音频输出设备在输入端加上1000Hz正弦波的电信号所产生声音的总谐波失真小于10%的最大声压级。
最大声压级越高,在强音信号下失真越小。
基本性能参数只是简单的反应了性能情况,并不能完整的判断出实际的性能表现,所以还是要实际测试才能知道。
-
网络传输、Network Transport
发送方依次将各个音频帧通过网络发送给通话的对方。由于音频对讲对实时性要求比较高,所以低延迟和平稳连续是非常重要的,这样音频对讲才能顺畅。
网络传输必须要注意的问题就是,一个是乱序到达,一个是重复到达,一个是丢包。
一般常用的网络传输协议是实时传输协议(Real-time Transport Protocol、RTP),也有用TCP或UDP协议的。
-
音频数字信号处理、Audio Digital Signal Processing、Audio DSP
-
简介
-
如果只是实现网络电话,那就只需要进行采样、传输、播放就好了,但是实际使用中我们会发现各种问题严重影响我们的电话体验,所以效果良好的网络电话应该达到以下几点:
-
声音延迟低,实时感很强。
-
声音流畅,没有卡顿的感觉。
-
声音清晰,没有失真的感觉。
-
音量适中,没有忽大忽小的感觉。
-
没有声学回音和线路回音。
-
噪音很小。
-
网络流量要小。
-
编码、Encode、解码、Decode
-
简介
-
如果我们将采样到的PCM格式音频数据直接发送或者存储,那么每秒需要占用的带宽就是16000Hz×16bit=31.25KB/S,这就要占用很大的带宽了。那么我们就需要对PCM格式进行压缩了,将压缩后的音频数据再进行发送或者存储,当需要播放的时候,再解压缩成PCM格式进行播放。我们把音频数据压缩的过程称之为编码,把音频数据解压缩的过程称之为解码。
通常情况下没有解码的音频数据是不能播放的,除非直接传输PCM格式,但也有些操作系统可以直接播放某些常用编码格式的音频数据,其实就是操作系统帮我们做了解码。
音频编码算法按音质可分为:无损压缩,有损压缩。
音频编码算法按编码方式可分为:波形编码、参数编码、波形参数混合编码。
音频编码算法按比特率可分为:固定比特率、可变比特率、平均比特率。
-
无损压缩、Lossless Compression
无损压缩是指编码前的PCM格式音频数据和解码后的PCM格式音频数据是完全一样的,所以经过编解码的音频信号没有任何的损失,音质是最好的,但带宽占用会较高。
-
有损压缩、Lossy Compression
有损压缩是指解码后的PCM格式音频数据只是近似于编码前的PCM格式音频数据,并不完全一样,所以经过编解码的音频信号的音质是有损失的,但带宽占用会较低。
-
波形编码、Waveform Encode
波形编码是指不利用音频信号的任何特性参数,直接将时间域音频数字信号波形变换为数字代码,使重构的音频数字信号波形尽可能地与原始的形状保持一致。
波形编码方法简单、易于实现、适应能力强并且语音质量好。不过因为压缩方法简单也带来了一些问题:压缩比相对较低,需要较高的编码速率。一般来说,波形编码的复杂程度比较低,编码速率较高、通常在16 kbit/s以上,质量相当高。但编码速率低于16 kbit/s时,音质会急剧下降。
最简单的波形编码方法是PCM(Pulse Code Modulation,脉冲编码调制),它只对语音信号进行采样和量化处理。优点是编码方法简单,延迟时间短,音质高,重构的语音信号与原始语音信号几乎没有差别。不足之处是编码速率比较高(64 kbit/s),对传输通道的错误比较敏感。
-
参数编码、Parameter Encode
参数编码是指从音频数字信号中提取音频特性参数,使用这些参数通过音频生成模型重构出音频数字信号,使重构的音频数字信号尽可能地保持原始的语意。也就是说,参数编码是把音频数字信号产生的数字模型作为基础,然后求出数字模型的模型参数,再按照这些参数还原数字模型,进而合成音频。
参数编码的编码速率最低可以达到2.4 kbit/s,产生的语音信号是通过建立的数字模型还原出来的,因此重构的语音信号波形与原始语音信号的波形可能会存在较大的区别、失真会比较大。而且因为受到语音生成模型的限制,增加数据速率可能也无法提高合成音频的质量。
-
波形参数混合编码、Waveform Parameter Mixed Encode
波形参数混合编码是指同时使用波形编码和参数编码进行编码,这种方法克服了波形编码和参数编码的弱点,并结合了波形编码高质量和参数编码的低编码速率,编码速率和音质介于它们之间,能够取得比较好的效果。
-
固定比特率、静态比特率、固定码率、Constant Bit Rate、CBR
对于视频编码来说,CBR编码指的是编码器每秒钟的输出码数据量(或者解码器的输入码率)应该是固定制(常数)。编码器检测每一帧图像的复杂程度,然后计算出码率。如果码率过小,就填充无用数据,使之与指定码率保持一致;如果码率过大,就适当降低码率,也使之与指定码率保持一致。因此,固定码率模式的编码效率比较低。在快速运动画面部分,画面细节较多,一般需要更多的比特来描述,但由于强行降低码率,因此会丢失部分画面的细节信息,而出现画面模糊、不清晰现象。对于音频压缩来说,比如MP3,比特率是最重要的因素,它用来表示每秒钟的音频数据占用了多少个比特,这个值越高,音质就越好。CBR使用固定比特率编码音频,一首MP3从头至尾为某固定值,如128 kbps进行编码。
-
可变比特率、动态比特率、可变码率、Variable Bit Rate、VBR
可变比特率可以随着图像的复杂程度的不同而变化,因此其编码效率比较高,快速运动画面的马赛克就很少。编码软件在压缩时,根据视频数据,即时确定使用什么比特率,这样既保证了质量,又兼顾了文件大小。使用这种方式时,编码程序可以选择从最差音视频质量(一般此时压缩比最高)到最好音视频质量(一般此时压缩比最低)之间的各种视频质量。在视频文件编码的时候,编码程序会尝试保持所选定的整个文件的品质,对视频文件的不同部分选择不同的比特率来编码。例如,使用MP3格式的音频编解码器,音频文件可以以8~320kbps的可变码率进行压缩,得到相对小的文件来节约存储空间。
当形容编解码器的时候,VBR编码指的是编码器的输出码率(或者解码器的输入码率)可以根据编码器的输入源信号的复杂度自适应的调整,目的是达到保持输出质量保持不变而不是保持输出码率保持不变。VBR适用于存储(不太适用于流式传输),可以更好的利用有限的存储空间:用比较多的码字对复杂度高的段进行编码,用比较少的码字对复杂度低的段进行编码。
像Vorbis这样的编解码器和几乎所有的视频编解码器内在的都是VBR的。*.mp3文件也可以以VBR的方式进行编码。
例如:有一段采样频率8000Hz的PCM格式音频数据,一共10帧,每帧20ms,可能其中5帧声音变化较大,其他5帧声音变化较小,那么用VBR来编码时,就会把声音变化较大的那5帧用较高的采样频率编码,编码后体积也较大,另外那声音变化较小的那5帧就用较低的采样频率编码,编码后体积也较小。
-
平均比特率、平衡比特率、平均码率、Average Bitrate Rate、ABR
平均比特率是VBR的一种插值参数。它针对CBR不佳的文件体积比和VBR生成文件大小不定的特点独创了这种编码模式。ABR在指定的文件大小内,例如以每50帧(30帧约1秒)为一段,低频和不敏感频率使用相对低的流量,高频和大动态表现时使用高流量,可以做为VBR和CBR的一种折衷选择。
-
声学回音消除、Acoustic Echo Cancellation、AEC
-
简介
-
当我们在音频通话时,经常会用到电脑的扬声器外放功能,或者手机的免提功能。这是一个很方便的功能,但此时扬声器播放的声音会被麦克风再次采集,然后在传给对方时,对方就会听到自己的声音,俗称声学回音。这个声学回音在被循环很多次之后,还有可能会变成啸叫。所以,我们需要将这个声学回音消除掉。注意,如果用耳机或听筒通话或半双工通话时,通常不需要做声学回音消除,因为此时通常不会产生声学回音。
我们这种情况产生的声学回音其实是一种自噪声,还有一种声学回音是由其他声源发出的声音并超过100毫秒时延的混响音,人类能够明显区分出,似乎一个声音同时出现了两次或多次,比如天坛著名的回音壁。
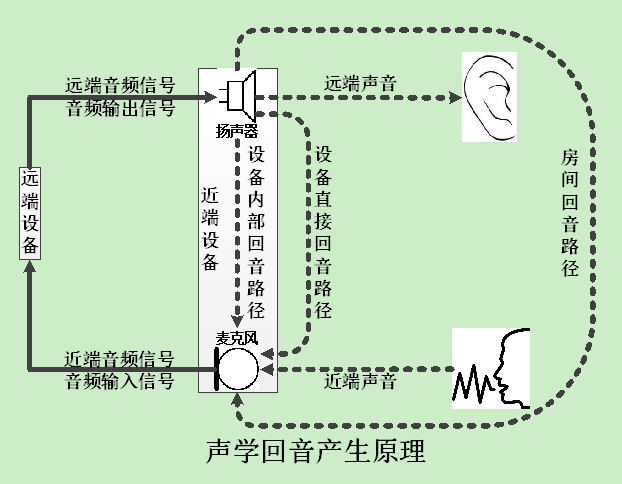
声学回音消除算法的原理就是,根据音频输出信号,在音频输入信号中做一些类似抵消的运算,从而将声学回音从音频输入信号中过滤掉。这个算法过程是相当复杂的,因为根据你聊天时所处的房间的大小、以及你在房间中的位置,回音的声波反射音量、时长和次数将会不一样,所以声学回音消除算法需要自动调整内部参数来适应当前的设备和环境。
做声学回音消除必须注意的问题:
-
首先应该尽量避免产生声学回音。比如:让麦克风与扬声器的距离尽量远;麦克风与扬声器之间尽量隔音;麦克风与扬声器的朝向尽量相反;降低麦克风的灵敏度;降低扬声器的功率;等等。这么做可以减少声学回音消除算法的难度,还可以提升远近端同时说话时近端声音的保留量,这是声学回音消除最有效的办法。
-
再次必须保证软硬件环境没有问题,否则声学回音消除算法可能无法正确识别声学回音,从而导致声学回音无法消除。比如:音频输入设备采样到的音频数字信号没有非环境音的杂音、没有干扰音、没有失真、没有掉帧;音频输出设备播放出来的音频模拟信号没有非原始信号的杂音、没有干扰音、没有失真、没有掉帧。造成这些问题的可能原因有:从音频输入输出设备到声卡芯片再到CPU的电路中有被干扰,需要尽量远离其他电路;音频输入输出设备使用同一个声卡芯片导致相互干扰,需要尽量分开两个芯片或降低音频输出设备功率;音频输入输出设备刚通电一瞬间可能会有脉冲电流通过,需要尽量避免或减少;音频输入输出设备质量问题导致声音有失真,需要更换质量更好的;操作系统的声卡驱动有问题,需要尽量更换稳定的声卡驱动;等等。
-
做声学回音消除前,要尽量保证音频输入帧和音频输出帧是同步的,时间差越小,声学回音消除效果就越好,时间差越大,声学回音消除效果也就越差,因为声学回音消除算法是需要同时传入音频输入帧和音频输出帧的。
-
声学回音消除一般都是在一个音频输入帧刚采样完毕和一个音频输出帧刚播放完毕后,就立刻做,不要在做了其他处理之后再做,这样会降低效果。
-
声学回音必须在远端音频出现之后出现,因为必须是先播放出来,然后麦克风才能采样到,否则声学回音消除算法会认为这是近端声音,而不是声学回音。
-
声学回音与远端音频会有一段时间间隔,有些声学回音消除算法可以自动适应这个时间间隔,但有些声学回音消除算法无法自动适应这个时间间隔,需要手动设置,这个时间间隔设置是否精准,将直接导致声学回音消除效果的好坏,设置不好可能会导致声学回音无法消除,或者近端声音被误消除掉。
-
声学回音一般都比远端音频的音量要小,但也有些扬声器的音量较大,会将远端音频的音量放大很多,导致声学回音的音量要比远端音频的音量大很多,这种情况下有些声学回音消除算法可能无法正确识别声学回音,这就需要更换更好的声学回音消除算法。
-
如果说话双方同时说话,那么声学回音与近端声音就会重叠,这种情况下有些声学回音消除算法可能无法正确识别声学回音,从而导致声学回音与近端声音都被消除了,这就需要更换更好的声学回音消除算法。
-
测试声学回音消除算法的时候,如果对讲的两个设备在同一个房间,那么两个设备会相互采样到对方扬声器播放出来的声音,会导致产生啸叫,所以测试时尽量要在不同的房间,两个设备之间不能相互听见。
声学回音消除算法一般有这几种:时域算法,频域算法,子带算法。
声学回音消除算法分为两大类:基于DSP等实时平台的回音消除,基于Windows等非实时平台的回音消除。两者的技术难度和重点是不一样的。
各个操作系统是否自带声学回音消除功能:
Windows、UNIX、Linux操作系统没有自带声学回音消除功能,需要调用第三方库实现。
Android操作系统虽然自带有声学回音消除功能,但是需要设备厂商自己实现,由于很多厂商都实现不了该功能,所以很多手机都不自带该功能,仍然需要调用第三方库实现。
IOS操作系统自带有声学回音消除功能,而且效果非常好,可以放心调用,当然也可以调用第三方库实现。
声学回音消除效果演示:
音频输入信号:
音频输出信号:
音频结果信号: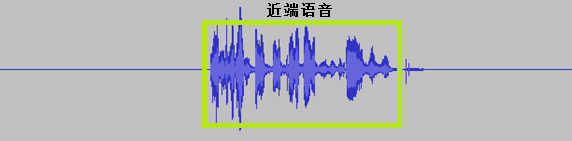
-
音频输入输出帧同步的方法
所谓音频输入输出帧同步就是指,音频输入帧和音频输出帧的开始时间及结束时间都是相同的时刻。
由于声学回音消除算法要求音频输入输出帧同步得非常好,所以在做声学回音消除前,必须先研究如何做同步。但是,其实声学回音消除算法要求并不一定完全同步,主要是要求音频输入帧必须比音频输出帧要先开始,只要能保证音频输入信号中的声学回音出现在音频输出信号中的远端声音之后,声学回音就可以被消除掉,但又不能先开始太久,越靠近越好,一般先开始0ms~300ms都是可以正常消除的。
比如:一帧20ms,音频输入帧的开始时间为13点05分15秒220毫秒、结束时间为13点05分15秒240毫秒,那么音频输出帧的开始时间也应该为13点05分15秒220毫秒、结束时间也应该为13点05分15秒240毫秒。如果做不到完全同步,音频输出帧的开始时间也可以为13点05分15秒340毫秒、结束时间也可以为13点05分15秒360毫秒,慢120ms左右回音消除一般是不会有问题的。
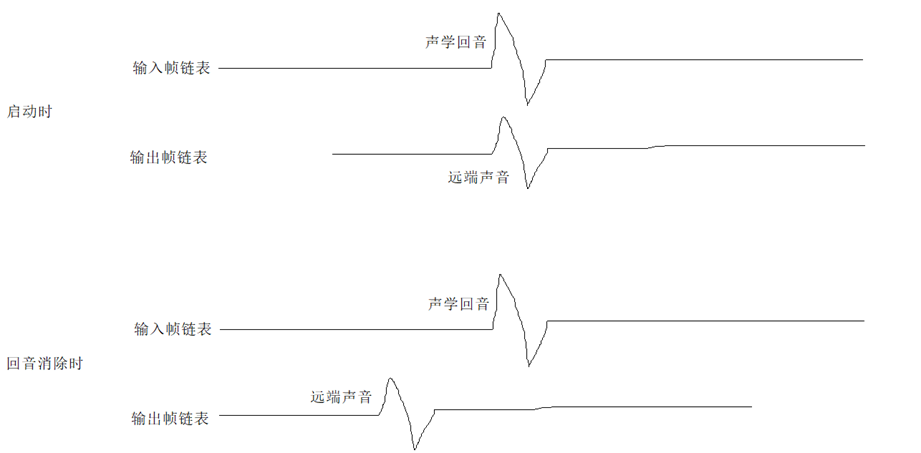
同步的方法:
Windows、UNIX、Linux操作系统:
第一种:直接用PortAudio库可以完美同步。
第二种:本人认为PortAudio库用起来不是很顺手,所以决定直接调用Windows系统的API来做同步。
UNIX、Linux操作系统:
还没有做过。
Android操作系统:
第一种:调用第三方修改的jni层的Android版的PortAudio的OpenSLES库实现同步,本方法可以完美同步,但是有些手机对OpenSLES库支持并不好,导致播放或录音有很高的延迟,所以本方法兼容性较差。下载地址:https://github.com/Gundersanne/portaudio_opensles
第二种:在单线程中,先初始化AudioRecord类和AudioTrack类,并先调用AudioRecord.startRecording()函数再调用AudioTrack.play()函数,然后进入循环体,先调用AudioTrack.write()函数阻塞播放音频输出帧,然后再调用AudioRecord.read()函数获取音频输入帧,循环体完毕。理论上这样做出来的音频输入输出帧就是同步的,但是由于Android操作系统Java代码的函数调用是有延迟的,不同的手机延迟会不一样,最终就会导致大部分的手机不能同步,所以本方法兼容性和稳定性都很差。
第三种:先在主线程中,初始化AudioRecord类和AudioTrack类,并先调用AudioRecord.startRecording()函数再调用AudioTrack.play()函数,然后再启动两个线程,一个音频输入线程负责调用AudioRecord.read()函数获取音频输入帧,并依次存放到已录音的音频输入帧链表,一个音频输出线程负责调用AudioTrack.write()函数播放音频输出帧,并依次存放到已播放的音频输出帧链表。先启动音频输入线程,再启动音频输出线程,这样已录音的音频输入帧链表和已播放的音频输出帧链表里的帧就是一一对应同步的,本方法在大部分情况下可以差不多完美同步,但是极少数情况下如果系统出现突然卡顿,就可能会不同步了,所以本方法兼容性和稳定性都很好。
第四种:本人后来发现,有些手机在调用AudioRecord.startRecording()函数后,居然并没有真正开始录音,而是要在调用AudioRecord.read()函数过程中时才会真正开始,那么这样就有可能会导致播放线程走在前面了,所以在第三种方法中,改为在音频输入线程调用一次AudioRecord.read()函数并丢弃掉后,再在音频输入线程中启动音频输出线程。这样本方法在绝大部分情况下可以差不多完美同步。
第五种:本人后来又发现,有些手机在调用AudioRecord.read()函数后,居然并没有真正开始录音,而是要在调用好几次AudioRecord.read()函数后才会真正开始,那么这样就有可能会导致播放线程走在前面了,所以在第四种方法中,改为在音频输入线程调用多次AudioRecord.read()函数,直到读取到的音频数据不是全0了并全部丢弃掉后,再在音频输入线程中启动音频输出线程。这样本方法在所有手机上可以差不多完美同步。
第六种:本人后来又发现,在调用AudioRecord.read()函数后,读取到的音频帧有可能就是全0的,并不一定是没有真正开始录音,所以就可能会丢失正常音频,并且对声学回音的延迟估计也不准。现在改为初始化AudioRecord类和AudioTrack类,然后启动音频输入线程,音频输入线程先调用AudioTrack.write()函数播放空的音频输出帧,直到如果播放耗时较长,就表示AudioTrack类的缓冲区已经写满,写入的空的音频帧的时长就是音频输出的延迟,然后再在调用AudioRecord.startRecording()函数后,开始计时,然后在调用一次AudioRecord.read()函数后,结束计时,这段时间就是音频输入的延迟,最后把音频输入的延迟和音频输出的延迟加起来就约等于声学回音的延迟。经过这么一计算,再启动音频输出线程,这样也保证了音频输入线程能走在音频输出线程的前面。这是我目前认为最好的同步办法。
IOS操作系统:
应该和Android操作系统的第六种方法同理,本人没有测试过。
如果是调用系统自带的声学回音消除功能是不需要做同步的。
-
多声道音频声学回音消除的方法
一般的语音通话都是单声道的录音和播放,做声学回音消除比较简单,但是如果是多声道的录音和播放,就需要对每个声道依次做声学回音消除了。
具体方法就是,先分别将录音和播放的一个多声道音频帧拆分成多个单声道音频帧,然后将录音的每个单声道音频帧依次与播放的每个单声道音频帧做声学回音消除,最后把录音的多个单声道音频帧合并成一个多声道音频帧。
例如,录音和播放都是双声道,先分别将录音和播放的一个双声道音频帧拆分成一个左声道音频帧和一个右声道音频帧,然后将录音的左声道音频帧与播放的左声道音频帧做声学回音消除,再用刚刚做了声学回音消除的左声道音频帧与播放的右声道音频帧做声学回音消除,现在这个录音的左声道音频帧才是做完声学回音消除了,同理再对录音的右声道音频帧做声学回音消除,最后把做完声学回音消除的录音的左声道音频帧和右声道音频帧合并成一个双声道音频帧,最终这个录音的双声道音频帧就是做完声学回音消除的了。
-
同一房间声学回音消除的方法
同一房间的声学回音就是因为近端和远端挨得比较近,那么近端发送给远端的音频,在远端播放以后,又被近端的麦克风录音了,然后近端又发送给了远端,这样就产生了声学回音。
消除的方法就是将近端的音频延时一段时间作为声学回音消除的参考音频,然后又和近端未延时的音频做声学回音消除,再将做了声学回音消除后的近端未延时的音频发送给远端就可以了。
-
解密回声消除技术(转载)
http://blog.51cto.com/silversand/166095
http://blog.51cto.com/silversand/166101
一、前言
因为工作的关系,笔者从2004年开始接触回声消除(Echo Cancellation)技术,而后一直在某大型通讯企业从事与回声消除技术相关的工作,对回声消除这个看似神秘、高端和难以理解的技术领域可谓知之甚详。
要了解回声消除技术的来龙去脉,不得不提及作为现代通讯技术的理论基础——数字信号处理理论。首先,数字信号处理理论里面有一门重要的分支,叫做自适应信号处理。而在经典的教材里面,回声消除问题从来都是作为一个经典的自适应信号处理案例来讨论的。既然回声消除在教科书上都作为一种经典的具体的应用,也就是说在理论角度是没有什么神秘和新鲜的,那么回声消除的难度在哪里?为什么提供回声消除技术(不管是芯片还是算法)的公司都是来自国外?回声消除技术的神秘性在哪里?
二、回声消除原理
从通讯回音产生的原因看,可以分为声学回音(Acoustic Echo)和线路回音(Line Echo),相应的回声消除技术就叫声学回声消除(Acoustic Echo Cancellation,AEC)和线路回声消除(Line Echo Cancellation, LEC)。声学回音是由于在免提或者会议应用中,扬声器的声音多次反馈到麦克风引起的(比较好理解);线路回音是由于物理电子线路的二四线匹配耦合引起的(比较难理解)。
回音的产生主要有两种原因:
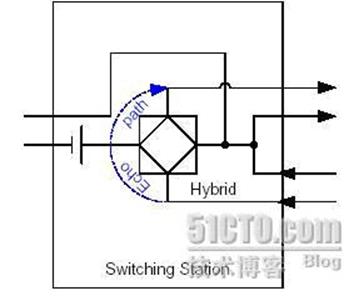
1、由于空间声学反射产生的声学回音(见下图):
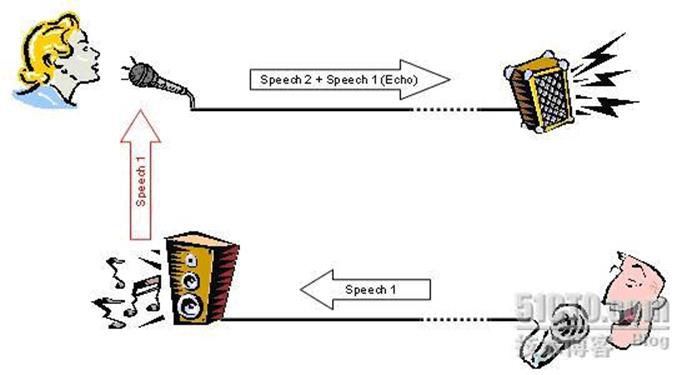
图中的男子说话,语音信号(speech1)传到女士所在的房间,由于空间的反射,形成回音speech1(Echo)重新从麦克风输入,同时叠加了女士的语音信号(speech2)。此时男子将会听到女士的声音叠加了自己的声音,影响了正常的通话质量。此时在女士所在房间应用回音抵消模块,可以抵消掉男子的回音,让男子只听到女士的声音。
2、由于2-4线转换引入的线路回音(见下图):
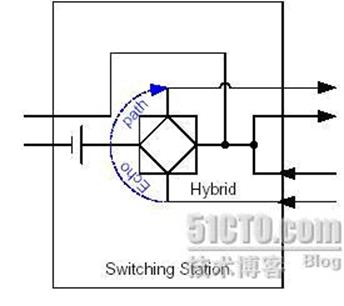
在ADSL Modem和交换机上都存在2-4线转换的电路,由于电路存在不匹配的问题,会有一部分的信号被反馈回来,形成了回音。如果在交换机侧不加回音抵消功能,打电话的人就会自己听到自己的声音。
不管产生的原因如何,对语音通讯终端或者语音中继交换机需要做的事情都一样:在发送时,把不需要的回音从语音流中间去掉。
试想一下,对一个至少混合了两个声音的语音流,要把它们分开,然后去掉其中一个,难度何其之大。就像一瓶蓝墨水和一瓶红墨水倒在一起,然后需要把红墨水提取出来,这恐怕不可能了。所以回声消除被认为是神秘和难以理解的技术也就不奇怪了。诚然,如果仅仅单独拿来一段混合了回音的语音信号,要去掉回音也是不可能的(就算是最先进的盲信号分离技术也做不到)。但是,实际上,除了这个混合信号,我们是可以得到产生回音的原始信号的,虽然不同于回音信号。
我们看下面的AEC声学回声消除框图(本图片转载)。
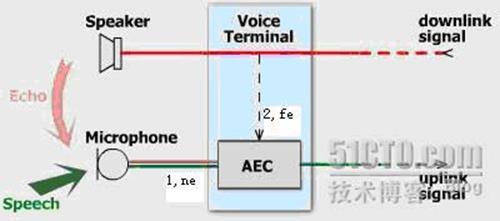
Figure Acoustic Echo Cancellation in a voice communication terminal
其中,我们可以得到两个信号:一个是蓝色和红色混合的信号1,也就是实际需要发送的speech和实际不需要的echo混合而成的语音流;另一个就是虚线的信号2,也就是原始的引起回音的语音。那大家会说,哦,原来回声消除这么简单,直接从混合信号1里面把把这个虚线的2减掉不就行了?请注意,拿到的这个虚线信号2和回音echo是有差异的,直接相减会使语音面目全非。我们把混合信号1叫做近端信号ne,虚线信号2叫做远端参考信号fe,如果没有fe这个信号,回声消除就是不可能完成的任务,就像"巧妇难为无米之炊"。
虽然参考信号fe和echo不完全一样,存在差异,但是二者是高度相关的,这也是echo称之为回音的原因。至少,回音的语义和参考信号是一样的,也还听得懂,但是如果你说一句,马上又听到自己的话回来一句,那是比较难受的。既然fe和echo高度相关,echo又是fe引起的,我们可以把echo表示为fe的数学函数:echo=F(fe)。函数F被称之为回音路径。在声学回声消除里面,函数F表示声音在墙壁,天花板等表面多次反射的物理过程;在线路回声消除里面,函数F表示电子线路的二四线匹配耦合过程。很显然,我们下面要做的工作就是求解函数F。得到函数F就可以从fe计算得到echo,然后从混合信号1里面减掉echo就实现了回声消除。
尽管回声消除是非常复杂的技术,但我们可以简单的描述这种处理方法:
1、房间A的音频会议系统接收到房间B中的声音
2、声音被采样,这一采样被称为回声消除参考
3、随后声音被送到房间A的音箱和声学回声消除器中
4、房间B的声音和房间A的声音一起被房间A的话筒拾取
5、声音被送到声学回声消除器中,与原始的采样进行比较,移除房间B的声音
求解回音路径函数F的过程恐怕就是比较难以表达的数学公式了。鉴于通俗表达数学公式的难度比发现数学公式还难,笔者就不费力解释了。下面这段表达了利用自适应滤波器原理求解函数F的过程。(以下可以跳过)
自适应滤波器
自适应滤波器是以输入和输出信号的统计特性的估计为依据,采取特定算法自动地调整滤波器系数,使其达到最佳滤波特性的一种算法或装置。自适应滤波器可以是连续域的或是离散域的。离散域自适应滤波器由一组抽头延迟线、可变加权系数和自动调整系数的机构组成。附图表示一个离散域自适应滤波器用于模拟未知离散系统的信号流图。自适应滤波器对输入信号序列x(n)的每一个样值,按特定的算法,更新、调整加权系数,使输出信号序列y(n)与期望输出信号序列d(n)相比较的均方误差为最小,即输出信号序列y(n)逼近期望信号序列d(n)。
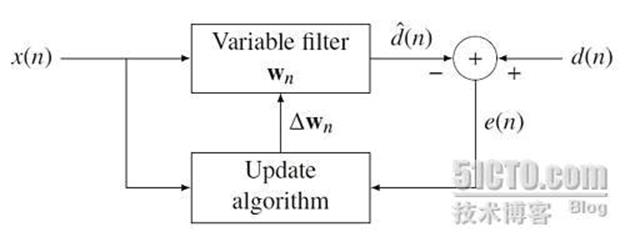
以最小均方误差为准则设计的自适应滤波器的系数可以由维纳-霍甫夫方程解得。
B.维德罗提出的一种方法,能实时求解自适应滤波器系数,其结果接近维纳-霍甫夫方程近似解。这种算法称为最小均方算法或简称LMS法。这一算法利用最陡下降法,由均方误差的梯度估计从现时刻滤波器系数向量迭代计算下一个时刻的系数向量
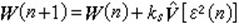
式中ks为一负数,它的取值决定算法的收敛性, V【ε2(n)】为均方误差梯度估计,
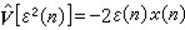
自适应滤波器应用于通信领域的自动均衡、回声消除、天线阵波束形成,以及其他有关领域信号处理的参数识别、噪声消除、谱估计等方面。对于不同的应用,只是所加输入信号和期望信号不同,基本原理则是相同的。(以上部分可以跳过)
上面这段话表明,需要求解的回音路径函数F就是一个自适应滤波器W(n)收敛的过程。所加输入信号x(n)是fe,期望信号是echo,自适应滤波器收敛后的W(n)就是回音路径函数F。 收敛之后,当实际回音发生,我们把fe通过函数W(n),就可以得到一个很准确的echo,把混合信号直接减去echo,得到实际需要发送的语音speech,完成回声消除任务。
值得注意的两点:
1、自适应滤波器收敛阶段,期望信号是完全的echo,不能混杂有speech。因为speech和fe是没有关系的,会扰乱W(n)的收敛过程。也就是说要求回声消除算法开始运转后收敛要非常快,最好对方还来不及说话,你一说就收敛好了;收敛好之后,如果对方开始说话,也就是有speech混合过来,这个W(n)系数就不要变化了,需要稳定下来。
2、回音路径可能是变化的,一旦出现变化,回声消除算法要能判断出来,因为自适应滤波器学习要重新开始,也就是W(n)需要一个新的收敛过程,以逼近新的回音路径函数F。
基本上来说,上面这两点是两难的,一个需要自适应滤波器收敛后保持系数稳定,以保证不受speech说话干扰,另一个需要自适应滤波器随时保持更新状态,以保证能够追踪变化的回音路径。这样一来,仅从数学算法层面,回声消除已经是难上加难!简单地说,回声消除自适应滤波器的设计具有两个互相矛盾的特性,也就是快速收敛和高度的稳定性,如何同时实现这两项特性,正是设计上的主要挑战。
经过上面的分析,相信大家对回声消除的原理和技术有了深刻的理解,这是一门即容易理解又难以实现的技术。
从应用平台来看,根据笔者多年的经验,可以把回声消除分为两大类:基于DSP等实时平台的回声消除技术和基于Windows等非实时平台的回声消除技术。两者的技术难度和重点是不一样的。
三、基于DSP平台的回声消除技术
回声消除技术传统的应用领域是各种嵌入式设备,包括各种电信网络设备和终端设备。网络设备比如交换机,网关等等,终端则包括移动电话终端,视频会议终端等。现代通讯产品里面大量应用了回声消除技术,包括在我们看得到的终端产品(比如手机)和看不到的局端产品(比如交换机)。这种嵌入式设备的共同点就是采用各种型号的DSP芯片作为回声消除的载体。一个有效的回声消除算法需要持续的在一颗DSP芯片上面运行,会遇到以下方面的难点:
实时性与高效性,因为DSP芯片资源有限。虽然自从二十世纪七十年代DSP应用以来,日新月异的硬件芯片技术使许多沉睡在教科书上的信号处理理论算法大规模应用,但是回声消除算法需要的资源还是大得惊人。以视频会议系统,大规模的会议室可以产生超过512ms的回音,要消除这么长延时的回音,即使按照8k赫兹采样率计算,自适应滤波器W(n)的长度都会达到4096个点,这样一方面需要非常大的存储空间来存储W(n),另一方面,W(n)的更新需要的计算量也是成倍增长,同时,W(n)的收敛难度也在加大,传统自适应滤波器的效率很难保证。对于电信设备中的应用,虽然回声消除不需要这么长的延时,但是在交换机等设备中,成本和效率就是生命,所有的处理算法都是按路或按线计算的,对算法的优化效率提出了无止境的要求。相对而言,只有像车载免提这种应用对效率要求不那么高,因为车内空间小,回音延时有限,又不要求多路应用。
传统的回声消除技术是从国外二十世纪七十年代的早期算法发展而来,这类技术的采用一直相当昂贵,提供电信级回声消除硬件应用(包括芯片或者设备)的厂家都是国外的。对于移动网络用户来说,语音品质一直是他们最关切的议题,对电信业者来说,语音也仍是他们最能获利的服务项目,因此语音的品质是不容妥协的。为了满足今日与未来的网路需求,回声消除技术的挑战正在于如何有效地降低成本并持续改善语音品质。
算法级的DSP软件解决方案,也是解决嵌入式设备回音问题的一种途径,对用户也有一定的灵活性,用户只需要把回声消除模块集成到自己的DSP软件中,再简单调整几个相关参数,就能达到较好的回声消除效果。
目前基于DSP的回声消除算法已经比较成熟,市场上也有一批专门的算法/芯片公司的能够对外提供已经优化好的基于DSP的软件回声消除模块:如俄罗斯Spririt DSP、加拿大Octastic Semiconductor、瑞典GIPS、国内科莱特斯科技Conatus Technologies以及美国Adaptive Digital、和GAO Research、英国CSR等等,另外还有美国Fortemedia、Acoustic Technologies和日本OKI等可以提供专用的回声消除DSP芯片。其中性能较好的有Octastic、Conatus、和Spririt这三家,Octastic可以提供完整的从专用芯片、板卡到DSP算法的完整方案,而Conatus和Spririt的回声消除效果更好,值得一提的是Conatus公司是目前市面上唯一提供针对专业视讯会议应用宽带回声消除模块的公司,其音频采样率可以达到48k赫兹。
四、基于Windows平台的回声消除技术
回声消除技术最新的应用领域是基于Windows平台的各种VoIP应用,比如软件视频会议,VoIP软件电话等。当回声消除算法应用到Windows平台,相对于传统的DSP平台,既带来优势,也带来了新的难点。高效性在Windows平台已经不是问题,现在的pc机,拥有丰富的cpu资源和海量的内存资源,再复杂的回声消除算法都可以运行自如。但是,新增加的麻烦比带来的好处要多。
首先,Windows平台是一个非实时的平台,音频的采集和播放对回声消除算法而言,也是非实时的。和DSP平台不一样,DSP平台可以直接控制AD/DA芯片的采集播放,获得实时的音频流(不存在同步问题),但是Windows平台下,应用程序很难在底层直接控制声卡的采集播放,获得的是非实时的音频流,从而带来了采集和播放音频流的同步问题。
实际应用时,传给回声消除算法的两个声音信号(采集的回音信号ne和播放的参考信号fe),必须同步得非常的好。就是说,本地接收到远端说的话以后,要把这些话音数据传给回声消除算法做参考,这是一个算法需要的输入信号;然后再传给声卡,声卡放出来后经过回音路径,这时,本地再采集,然后传给回声消除算法,这是算法需要的另一个输入信号。这里的同步是指:两个信号虽然存在延时,但这个延时必须固定,在时序上要保持连贯,不能一个信号多来几个帧,另外一个信号少来几个帧。如果传给回声消除算法的两个信号同步得不好,即两个信号发生帧错位,就没有办法进行消除了。因为这时系统会变成了非因果系统,比如期望信号收到了,参考信号还没来,时间上都没有因果关系,肯定是没有办法消除的。
实际情况是,在一般的VoIP软件中,接收对方的声音并传到声卡中播放是在一个线程中进行的,而采集本地的声音并传送到对方又是在另一个线程中进行的,而声学回声消除算法在对采集到的声音进行回声消除的同时,还需要播放线程中的数据作为参考,而要同步这两个线程中的数据是非常重要的,因为稍稍有些不同步,声学回声消除算法中的自适应滤波器就会发散,不但消除不了回音,还会破坏原始采集到的声音,使声音难以分辨。
另外,pc机器的声卡种类繁多,各种各样的声卡特性进一步加剧了同步问题的复杂性。所以,同步和声卡等问题对回声消除算法的内部特性提出了更多苛刻的要求。
从上面分析来看,由于Windows平台的非实时性,基于Windows平台的回声消除技术比DSP平台要难得多。
在PC平台语音通讯领域,目前公认音质做得比较好的国外软件是Skype,记得几年前Skype一直是在用瑞典一家叫GIPS(Global IP Sound)公司的语音引擎技术。GIPS是最早介入PC平台语音通讯领域的厂商之一,在改领域具有一定的权威性,其主要优势表现在对IP网络的延时、抖动和丢包等处理较好,基于Windows平台的回音消除也做得不错,不过最近的新版本Skype上已经看不到GIPS的标志了,据说是因为Skype自己研发了一套新的更好的语音引擎的缘故。 目前大家接触最多的采用了GIPS语音引擎技术的通讯软件就是腾讯QQ了,其超级语音的效果普遍评价都还不错。另外微软经过多年的研发,其最新版本的MSN语音特别是回音消除效果终于有了质的提升,目前网上评价也还不错。另外还有一些专业厂商也对外提供包含回音消除功能的语音引擎,如俄罗斯的Spirit DSP、美国的GH Innovation和国内的科莱特斯科技(Conatus Technologies)以及赛声科技(Soft Acoustic)等等。除此之外,网络上还可以下载到一个很好的开源的语音软件Speex也提供了回音消除功能。为了进一步了解目前PC Windows平台回音消除技术的业界水平,笔者对各家的回音消除技术做一个详细的横向对比测试(所有测试都是免提状态)
为了对比,各家语音引擎的版本信息列举如下:
国外厂商:
Skype V3.8.4.182
Spirit DSP(厂家DEMO)
GIPS(QQ 2009beta)
Micorsoft (Windows Live Messenger 2009 V14.0.8064.2006)
GH Innovation(厂家DEMO)
国内厂商:
Conatus Technologies(厂家DEMO)
Soft Acoustic(厂家DEMO)
开源算法:
Speex(V1.2RC1 自己写了测试软件)
测试结果:
|
测试项目 |
Skype |
MSN |
|
Conatus |
Spirit |
Speex |
SoftAcoustic |
GH I |
|
笔记本免提模式,外接麦克风和音箱应用模式的适应性 |
两种模式都无回音 |
笔记本免提模式有时一直有较小回音 |
笔记本免提模式偶尔有较小回音 |
两种模式都无回音 |
笔记本免提模式有时一直有较小回音 |
两种模式都有一直较小回音 |
两种模式有时都会出现较大回音 |
笔记本免提模式一直有很小回音 |
|
单方讲话效果 |
无回音,效果很好 |
基本无回音,效果好 |
基本无回音,效果好 |
无回音,效果很好 |
基本无回音,效果好 |
一直有较小回音,效果差 |
有时有很大回音,效果差 |
基本无回音,效果好 |
|
双方同时讲话效果 |
双方交流流畅无回音,对方声音偶尔有轻微断续 |
双方交流流畅,但对方声音中会夹杂着轻微回音 |
双方交流流畅,但对方声音中会夹杂着一些回音 |
双方交流流畅无回音,对方声音偶尔有轻微断续 |
双方交流流畅,但对方声音中间会夹杂着一些回音 |
双方交流比较流畅,但一直听到一个较小的回音 |
双方交流不流畅,对方声音经常会断续 |
双方交流无回音,但对方声音很小很难听清楚 |
|
麦克风和扬声器相对的位置改变等 |
收敛比较快,基本没有回音出现。 |
收敛比较快,基本没有回音出现。 |
收敛比较快,基本没有回音出现。 |
收敛比较快,基本没有回音出现。 |
收敛比较快,基本没有回音出现。 |
收敛速度慢,有好几句回音 |
收敛速度慢,有好几句回音 |
收敛比较快,基本没有回音出现。 |
|
CPU重载(CPU负载达到100%)时效果 |
XP和Vista下声音都流畅,基本不会出现回音和声音断续现象 |
XP和Vista下声音都流畅,基本不会出现回音和声音断续现象 |
XP下声音流畅,基本不会出现回音;Vista下声音断续,偶尔会出现回音 |
XP和Vista下声音都流畅,基本不会出现回音和声音断续现象 |
XP下声音流畅,基本不会出现回音;Vista下声音断续,偶尔会出现回音 |
此项未测 |
XP下声音流畅,基本不会出现回音;Vista下声音断续,偶尔会出现回音 |
XP下声音流畅,基本不会出现回音;Vista下不加负载声音都是断续的 |
|
PC和声卡适应性 |
稳定,基本都能消除回音 |
稳定,基本都能消除回音 |
比较稳定,偶尔有些笔记本免提时有回音 |
稳定,基本都能消除回音 |
稳定,基本都能消除回音 |
不稳定,有时无法消除回音 |
不稳定,经常无法消除回音 |
稳定,基本都能消除回音 |
|
噪声抑制 |
噪声抑制效果弱 |
噪声抑制效果一般 |
噪声抑制效果弱 |
噪声抑制效果强 |
噪声抑制效果一般 |
噪声抑制效果强 |
噪声抑制效果强 |
噪声抑制效果强 |
|
自动硬件增益控制和免提时能达到的最大播放音量 |
支持,音量较大 |
支持,音量较小 |
支持,音量适中 |
支持,音量适中 |
支持,音量较小 |
不支持 |
支持,音量较小 |
支持,音量非常小 |
|
整体效果评价(0-10分评分) |
很好,基本没有回音,双方交流很顺畅,9分 |
较好,有的笔记本免提时偶尔有回音且音量较小,双方交流比较顺畅,7.5分 |
较好,有的笔记本免提时偶尔有回音,双方交流顺畅,8分 |
很好,基本没有回音,音量比skype略小,双方交流很顺畅,8.5分 |
较好,有的笔记本免提效果稍差且音量比较小,vista效果稍差,7分 |
不好,一直有个较小的残余回音,双方交流困难,3分 |
不好,经常有完整的回音,感觉不稳定,双方交流比较困难,5分 |
一般,没有回音,但是音量太小,双方交流困难,且VISTA下声音断续,5.5分 |
|
测试项目 |
Skype |
MSN |
|
Conatus |
Spirit |
Speex |
SoftAcoustic |
GH I |
可以看出,Skype、Conatus和QQ(GIPS)的效果最好,MSN和Spirit的效果还不错,而GH Innovation、Soft Acoustic效果一般,Speex的效果较差。
-
微软声学回声消除demo AECMicArray的使用(转载)
原文地址:https://blog.csdn.net/yjjat1989/article/details/20372589
代码下载:https://github.com/pauldotknopf/WindowsSDK7-Samples/tree/master/multimedia/audio/aecmicarray
AECMicArray基于Core Audio APIs,用MMDevice、WASAPI、DeviceTopology和EndpointVolume APIs来捕获高质量声音流。这个例子支持声学回声消除(AEC)和麦克风阵列处理。关于麦克风阵列处理,主要是波束形成和声源定位,具体的在以后总结。
1、说明
AECMicArray有如下特征:用MMDevice来枚举和选择多媒体设备;用WASAPI来管理音频流操作如开始和结束音频流;用DeviceTopology来枚举音频适配器;用EndpointVolume来控制声音级别。
2、要求
AECMicArray要求Windows SDK(Windows Vista及以后版本)和Visual Studio(2005版本以后)。
3、源码下载
AECMicArray代码位于\Program Files\Microsoft SDKs\Windows\v7.0\Samples\multimedia\audio\aecmicrray目录下,源代码包括4个文件,分别是mediabuf.h、AecKsBinder.h、AecKsBinder.cpp、AecSDKDemo.cpp。
4、构建项目
msdn上说明可以分以下四步:
1)打开SDK命令行窗口,即开始——>所有程序——>Microsoft Windows SDK 7.0——>CMD Shell,如下图:
提示中说VC++编译器当前使用的是Windows SDK v6.0A,所以输入WindowsSdkVer.exe -version:v7.0来使用Windows SDK v7.0,输入后会有如下结果:

2)输入cd %MSSDK%\Setup,如下图
3)运行VCIntegrate.exe。以上3步设置了使用SDK的环境。我的电脑中就没有VCIntegrate.exe,可能被破坏,需要修复,比较麻烦。
4)构建示例,成功后会生成AecSDKDemo.exe。
上面是msdn中说的步骤,也可以在VS2010中新建一个工程,然后将4个源文件加进去,然后编译运行生成AecSDKDemo.exe,具体注意事项及代码说明可参见aecmicarray目录里AecSDKDemo.cpp中的说明及readme.rtf文件。
5、执行示例
成功生成AecSDKDemo.exe文件后在命令行窗口中输入一下指令:
AecSDKDemo -out mic_out.pcm -mod system_mod [-option value]
其中-out和-mod是必选项,-out指定存储处理后的数据的pcm格式文件,-mod指定模式,目前demo支持4种模式,及仅AEC(0)、仅MicArray(2)、AEC+MicArray(4)和既没有AEC也没有MicArray(5)。-option是可选参数,具体参见readme.rtf。
6、测试结果
因为仅测试AEC,所以选择模式0,并开启噪声抑制和自动增益控制,同时设置运行时间为40s,即输入AecSDKDemo -out micout.pcm -mod 0 -ns 1 -agc 1 -duration 40,如果仅有一个录音设备和一个播放设备,程序会默认使用这些设备,否则会提示你进行选择。因为只能产生回声消除处理后的数据,所以我们在运行程序的同时,开启录音机,得到麦克风采集到的混合音频,与程序输出对比,如下图:
NearEnd.wav
out.pcm
从上图及主观听觉的结果来看,微软的回声消除效果很好,几乎听不见系统播放出来的声音。
-
技术指标
1.回声抑制算法处理时延估计:
实际时延(拍掌记录掌声信号和其回声信号,求平均值)与算法补偿时延(估计时延)之差小于80ms。
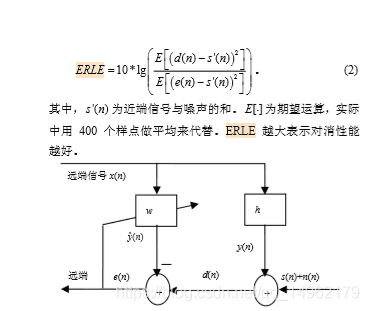
2.回声抑制比ERLE:
近端信号能量除以误差信号能量取对数乘以10。
-
声学回音消除器效果对比
|
名称 |
收敛时间 |
回音延迟不稳定 |
残余回音 |
远近端同时说话 |
同一房间对讲 |
运算量 |
|
Speex声学回音消除器 |
有语音活动1~3秒 |
0~3秒自适应调节 |
回音延迟稳定时没有 回音延迟不稳定时有很大 |
近端语音被消除20% |
会产生一定回音 |
一般 |
|
WebRtc定点版声学回音消除器 |
0秒 |
延迟400ms以内0秒自适应调节 延后超过400ms将无法消除 |
回音延迟稳定时没有 回音延迟不稳定时偶尔有一丝丝,偶尔有很大 |
近端语音被完全消除 |
会产生较大回音 |
一般 |
|
WebRtc浮点版声学回音消除器 |
有语音活动1秒 |
0秒自适应调节 |
回音延迟稳定时没有 回音延迟不稳定时偶尔有一丝丝 |
近端语音被消除50% |
会产生较小回音 |
较大 |
|
Speex声学回音消除器 +WebRtc定点版声学回音消除器 |
0秒 |
0~3秒自适应调节 |
回音延迟稳定时没有 回音延迟不稳定时有很大 |
近端语音被消除20% |
会产生一定回音 |
一般 |
|
WebRtc定点版声学回音消除器 +WebRtc浮点版声学回音消除器 |
0秒 |
0秒自适应调节 |
回音延迟稳定时没有 回音延迟不稳定时偶尔有一丝丝 |
近端语音被消除50% |
会产生较小回音 |
较大 |
|
Speex声学回音消除器 +WebRtc定点版声学回音消除器 +WebRtc浮点版声学回音消除器 |
0秒 |
0秒自适应调节 |
回音延迟稳定时没有 回音延迟不稳定时极低概率会有一丝丝 |
近端语音被消除50% |
会产生很小回音 |
很大 |
特别注意:以上是在不使用系统自带的声学回音消除器的效果,且不同设备或不同环境或不同时间效果都会不同,所以需要自己亲自测试。
-
残余回音消除、Residual Echo Cancellation、REC
有些声学回音消除算法在做完声学回音消除后,还会残余一部分声学回音没有彻底消除干净,这时候就需要再使用残余回音消除算法过滤掉。
-
声学回音消除挑战赛
https://github.com/microsoft/AEC-Challenge/tree/main/datasets
-
线路回音消除、电路回音消除、Line Echo Cancellation、LEC
线路回音是由于物理电子线路的二四线匹配耦合引起的。
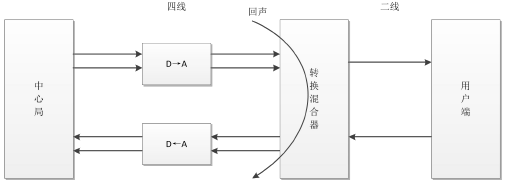
由于2-4线转换引入的线路回音:
在ADSL Modem和交换机上都存在2-4线转换的电路,由于电路存在不匹配的问题,会有一部分的信号被反馈回来,形成了回音。如果在交换机侧不加回音抵消功能,打电话的人就会自己听到自己的声音。
电路回声通常产生于有线通话中,而造成电路回声的根本原因是转换混合器的二线-四线阻抗不能完全匹配。中心局至转换混合器之间采用四线的连接方式传输信号,上面两条线路用于发送给用户端信号,下面两条线路用于接收用户端信号。通信公司为了降低远距离信号传输成本,将混合器至用户端的连接线减少为二线连接,分别用于用户端信号的接受与发送。中间的转换混合电路功能是将四线连接转换为二线连接,由于在转换过程中使用了不同型号的电线或者负载线圈没有被使用的原因,不可避免地会产生阻抗不匹配现象,导致混合器接收线路上的语音信号流失到了发送线路,产生了回声信号,使得另一端的用户在接收信号的同时听到了自己的声音。
电路回声产生原理
在现如今的数字通信网络中,转换混合器与数模转换器融为一体,但无论是模拟电子线路还是数字电子线路,二-四线的转换都会造成阻抗不匹配问题,从而导致其产生电路回声,影响现代通信质量。由于电路回声的线性以及稳定性,用一个简单的线性叠加器就可以实现电路回声消除。首先将产生的回声信号在数值上取反,线性地叠加在回声信号上,将产生的回声信号抵消,实现电路回声的初步消除。然而由于技术缺陷,线性叠加器不能完整地将回声信号抹去,因此需要添加一个非线性处理器,其实质是一个阻挡信号的开关,将残余的回声信号经过非线性处理之后,就可以实现电路回声的消除,或者得到噪声很小的静音信号。由于电路回声信号是线性且稳定的,所以比较容易将其消除,而本文主要研究的是如何消除非线性的声学回声。
电路回声消除的基本原理
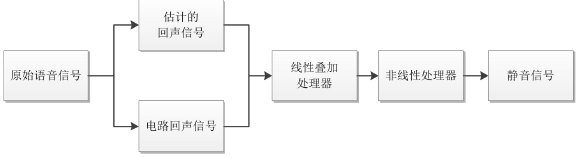
-
自动噪音抑制、Automatic Noise Suppression、ANS、噪音抑制、Noise Suppression、NS、噪音降低、降噪、Noise Reduction、NR、噪音消除、去除噪音、Denoise
-
简介
-
噪音分为环境背景噪音和信道干扰噪音。
噪声抑制就是根据音频数据的特点,将属于环境背景噪音和信道干扰噪音的部分识别出来,并从音频数据中过滤掉,尽可能的让音频数据中只保留语音。
噪音抑制算法一般有两种,一种叫单麦克风噪音抑制,简称单麦降噪,另一种叫双麦克风噪音抑制,简称双麦降噪。
单麦克风噪音抑制算法的原理就是:将单个麦克风采样到的信号进行分析,根据一些预定义的噪音特征,对信号的内容进行匹配,然后将匹配成功的内容过滤掉。
双麦克风噪音抑制算法的原理就是:一个麦克风为普通的用户通话时使用的麦克风,用于采样语音信号,而另一个配置在机身顶端的麦克风,用于采样环境背景噪音信号,然后根据采样到的环境背景噪音信号,将语音信号中采样到的环境背景噪音过滤掉。这种算法一般只能在听筒模式下使用,不能在免提模式下使用,因为免提模式下两个麦克风采样到的信号都包含语音。
支持噪音抑制的开源库有Speex、WebRTC、RNNoise。
包含噪音的语料库有NOIZEUS、NoiseX-92、TIMIT。
噪音抑制效果演示:
噪音抑制前:
噪音抑制后:
-
基本谱减法和改进谱减法
https://blog.csdn.net/Lebronze/article/details/53541123
https://wenku.baidu.com/view/9663e5da5022aaea998f0fdc
https://www.cnblogs.com/riddick/p/6848673.html
https://blog.csdn.net/leixiaohua1020/article/details/47276353
http://www.woc88.com/mv-11812218.html
《Suppression of acousic noise in speech using spectral subtraction》
《Enhancement of speech corrupted by a acoustic noise》
-
最优修正对数谱幅度估计算法、OM-LSA
-
拾音束形成、BF
-
按键音抑制、KS
抑制键盘输入时产生的敲击噪音。
-
主动噪音控制、Active Noise Control、ANC、主动噪音降低、Active Noise Reduction、ANR、主动降噪
主动噪音控制就是通过噪音控制系统产生与外界噪音相等的反向声波,将噪音中和,从而实现降噪的效果。
它的原理是:所有的声音都由一定的频谱组成,如果可以找到一种声音,其频谱与所要消除的噪声完全一样,只是相位刚好相反(相差180°),就可以将这噪声完全抵消掉。关键就在于如何得到那抵消噪声的声音。实际采用的办法是:从噪声源本身着手,设法通过电子线路将原噪声的相位倒过来。由此看来,有源消声这一技术实际上是"以毒攻毒"。
主动噪音控制主要针对有持续性噪音的环境,比如:飞机、火车、地铁、公交、汽车、车间等。
主动噪音控制原理示意图: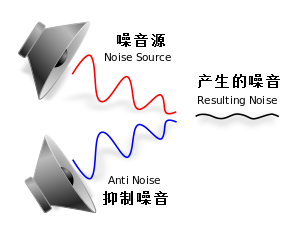
-
被动噪音控制、Passive Noise Control、PNC、被动噪音降低、Passive Noise Reduction、PNR、被动降噪
被动噪音控制是通过绝缘材料、吸声砖或消音器等隔音材料来被动降低噪音。
混响音,也叫交混回响音,其产生过程为:当语音信号在封闭的房间内传播时,由于房间墙壁、室内物体的反射、吸收,语音信号会通过多种路径传达到麦克风,这些语音信号按时间先后顺序可分为三部分:直达音、早期反射音(只经过一两次的反射,能量较大、时延较短的反射音)、混响音(经过多次反射以后到达的数目众多、能量较小、时延较长的反射音群)。
早期反射音是指未达到稳定状态时的反射音,也就是在直达音之后混响音开始衰减之前的这段时间差内的反射音。直达音以后50ms以内到达的早期反射音有加强直达音和提高清晰度的作用,可以被接受作为直达音的一部分。
混响音是指早期反射音之后到达的反射音群。它会引起语音幅值的变化、相位的延时、共振峰的偏移以及产生其它的谱峰、拖尾,还会造成语言音节的相互掩蔽,从而降低了语音清晰度和可懂度。
一般在空旷封闭的房间内使用免提打电话时,如果麦克风与声源之间的距离较远,混响音就会比较强,此时就需要做混响音消除,如果不在这种情况下打电话时就不需要做混响音消除了。
在语音对话中,要是当一方没有说话时,就不会产生流量就好了。语音活动检测就是用于这个目的的。语音活动检测通常也集成在编码模块中。语音活动检测算法结合前面的噪音抑制算法,可以识别出当前是否有语音活动,如果没有语音活动,就可以编码输出一个特殊的的编码帧(比如长度为0)。
特别是在多人视频会议中,通常只有一个人在发言,这种情况下,利用语音活动检测技术而节省带宽还是非常可观的。
-
不连续传输、Discontinuous transmission、DTX
不连续传输是指,在网络传输编码后的音频帧时,如果编码器发现某一些音频帧没有任何信息,编码器就会返回一个特殊值来告诉程序,程序就通过这个特殊值来判断可以不发送哪些编码后的音频帧,然后接收方就会误以为这些数据包都丢失了,那么接收方就会使用数据包丢失隐藏算法来猜测这些音频帧,由于发送方确定这些音频帧没有任何信息,所以猜测出来的音频帧也就会没有任何信息,这样就节省了网络流量。
-
自动增益控制、Automatic Gain Control、AGC
自动增益控制是指,当较弱信号输入时,可以将其放大到指定幅度,当较强信号输入时,可以将其降低到到指定幅度。
由于不同设备的麦克风灵敏度不一样,导致采样到的信号幅度就会有偏大或者偏小的情况,最终播放时就会有些人声音大、有些人声音小,这种情况下通过使用自动增益控制算法,将所有人的音频信号都控制在同一级别的幅度上,这样播放时的声音都是一样大了。
由于网络环境可能不稳定,造成网络延迟一会大一会小,俗称网络抖动。在网络抖动情况下,通过网络传输音频帧时,即使发送方是定时发送音频帧的(比如每20ms发送一个包),接收方也无法定时收到,可能一段时间内一个包都收不到,也可能一段时间内收到好几个包,最终导致接收方播放时声音出现一卡一卡的。因此,就需要使用自适应抖动缓冲区先将接收到的音频帧缓冲起来,当缓冲到一定数量后,才从最老的帧一个一个依次开始取出,这样接收方听到的声音就是连续的了。
自适应抖动缓冲区的缓冲深度不是一直不变的,它取决于网络抖动的程度,当网络抖动增大时,缓冲深度就会增大,音频播放的延迟也就越大,当网络抖动减小时,缓冲深度就会减小,音频播放的延迟也就越小。所以,自适应抖动缓冲区就是利用了较高的延迟来换取声音的流畅播放,因为相比声音一卡一卡的来说,较高的延迟和流畅的声音,其主观感受要更好。
自适应抖动缓冲区还可以将乱序到达的数据重新排序,然后在取出的时候就是正确的顺序了。
-
数据包丢失隐藏、Packet Loss Concealment、PLC
数据包丢失隐藏是指,在网络传输编码后的音频帧时,如果某一个编码后的音频帧丢失了,那么接收方可以根据曾经接收到所有音频帧猜测出已丢失的解码后的音频帧。
例如,某一个Speex格式音频帧丢失了,那么接收方就可以直接用Speex解码器猜测出这个已丢失的PCM格式音频帧。
-
前向纠错、Forward Error Correction、FEC
前向纠错是指,在网络传输编码后的音频帧时,如果某一个编码后的音频帧丢失了,但其后一个编码后的音频帧接收到了,那么接收方可以根据后一个编码后的音频帧恢复出其前一个解码后的音频帧。
例如,某一个Opus格式音频帧丢失了,但其后一个Opus格式音频帧接收到了,那么接收方就可以用Opus解码器,根据后一个Opus格式音频帧恢复出其前一个PCM格式音频帧。
-
重采样、Resample
-
重采样简介
-
重采样是指将已采样的音频数据进行重新采样,从而改变它的采样频率。
将采样频率低的音频数据重采样到采样频率高的音频数据,称为上采样、升采样(upsampling)。
将采样频率高的音频数据重采样到采样频率低的音频数据,称为下采样、降采样(downsampling、subsampling)。
例如,已有一段8000Hz采样频率的音频数据,但是声卡最低支持播放16000Hz采样频率的音频数据,那么就要用重采样算法将这段音频数据重采样成16000Hz。
重采样其实内部使用的就是插值算法,采用不同的插值算法,新信号的运算速度和质量将会不同。
-
插值算法简介
插值在数学发展史上是个古老问题。插值是和拉格朗日(Lagrange)、牛顿(Newton)、高斯(Gauss)等著名数学家的名字连在一起的。在科学研究和日常生活中,常常会遇到计算函数值等一类问题。插值法有很丰富的历史渊源,它最初来源人们对天体研究——有若干观测点(我们称为节点)计算任意时刻星球的位置(插值点和插值)。现在,人们在诸如机械加工等工程技术和数据处理等科研都有很好的应用,最常见的应用就是气象预报。插值理论和方法能解决在实际中当许多函数表达式未知或形式复杂,如何去构造近似表达式及求得在其他节点处的值的问题。
插值问题描述:
设已知某函数在区间上连续,且已知在该区间的个互异离散点上的函数值为:
|
… |
||||||
|
… |
根据这些已知点来构造函数的一种简单近似函数,使其满足:
从而我们可以使用函数来计算函数的其他未知节点上的函数值,或计算函数的一阶、二阶导数值。
这里,函数的构造算法称为插值算法(Interpolation Algorithm),称为的一个插值函数(Interpolation Function),称为被插值函数(Interpolated Function),已知的这些互异离散点称为插值节点(Interpolation Node),区间称为插值区间,在区间内计算未知节点上的函数值称为内插值,在区间外计算未知节点上的函数值称为外插值。
我们构造出来的插值函数是近似被插值函数,所以除了在插值节点处没有误差外,在其他点上一般是有误差的,若记,则就是用近似的截断误差,我们称截断误差为的插值余项。
插值算法共分为逼近插值算法和拟合插值算法两种,逼近插值算法要求插值函数逼近所有的插值节点就行,不要求插值函数经过所有的插值节点,而拟合插值算法就要求插值函数必须经过所有的插值节点,所以逼近插值算法适合要求不高的情况,拟合插值算法适合要求较高的情况。
从几何上看,拟合插值算法就是求曲线, 使其通过给定的个互异离散点, 并使它近似曲线,如图:
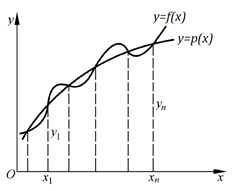
若是次数不超过的代数多项式, 即:,则称为插值多项式。若为分段的多项式, 就称为插值分段多项式。若为三角多项式, 就称为插值三角多项式。通过构造多项式来插值的算法统称为多项式插值算法。
多项式插值的存在性和唯一性:
定理:若插值节点是个互异离散点,则满足插值条件的次插值多项式存在而且唯一。
证明:


-
各种插值算法的特点比较
线性插值算法
公式复杂度:十分简单。
插值节点顺序:乱序。
插值节点上下左右移动:未知节点也跟着一样的移动。
插值节点上下左右伸缩:
增加插值节点:需要重新计算新增插值节点附近的插值函数,再通过新的插值函数重新计算未知节点。
删除插值节点:需要重新计算被删插值节点附近的插值函数,再通过新的插值函数重新计算未知节点。
未知节点光滑性:不光滑。
未知节点稳定性:稳定。
抛物线插值算法
公式复杂度:十分简单。
插值节点顺序:乱序。
插值节点上下左右移动:未知节点也跟着一样的移动。
插值节点上下左右伸缩:
增加插值节点:需要重新计算新增插值节点附近的插值函数,再通过新的插值函数重新计算未知节点。
删除插值节点:需要重新计算被删插值节点附近的插值函数,再通过新的插值函数重新计算未知节点。
未知节点光滑性:比线性插值算法略光滑,但总体还是不光滑。
未知节点稳定性:稳定。
拉格朗日插值算法
公式复杂度:比较简单、比较方便。
插值节点顺序:乱序。
插值节点上下左右移动:未知节点也跟着一样的移动。
插值节点上下左右伸缩:
增加插值节点:所有的基本插值多项式都要重新计算,所有的未知节点也都要重新计算。
删除插值节点:所有的基本插值多项式都要重新计算,所有的未知节点也都要重新计算。
未知节点光滑性:总体都是光滑的。
未知节点稳定性:不稳定,当插值节点较多时,拉格朗日插值多项式的次数可能会很高,因此插值结果的数值会不稳定,也就是说尽管在插值节点处能得到给定的数值,但在未知节点处得到的函数值与期望值之间会有很大的偏差,这类现象被称为龙格现象,这时可以考虑把插值节点分段用较低次数的拉格朗日插值多项式,或者使用切比雪夫插值节点。
重心拉格朗日插值算法
公式复杂度:比较简单、比较方便。
插值节点顺序:乱序。
插值节点上下左右移动:未知节点也跟着一样的移动。
插值节点上下左右伸缩:
增加插值节点:需要重新计算重心权,插值函数不需要全部重新计算,但所有的未知节点都要重新计算。
删除插值节点:需要重新计算重心权,插值函数不需要全部重新计算,但所有的未知节点都要重新计算。
未知节点光滑性:总体都是光滑的。
未知节点稳定性:不稳定,插值结果和拉格朗日插值算法是一样的,所以都会出现龙格现象,这时可以考虑把插值节点分段用较低次数的拉格朗日插值多项式,或者使用切比雪夫插值节点。
牛顿插值算法
公式复杂度:比较简单、比较方便。
插值节点顺序:乱序。
插值节点上下左右移动:未知节点也跟着一样的移动。
插值节点上下左右伸缩:
增加插值节点:需要在之前的插值函数上增加一个子函数,插值函数不需要全部重新计算,但所有的未知节点都要重新计算。
删除插值节点:插值函数需要全部重新计算,所有的未知节点都要重新计算。
未知节点光滑性:总体都是光滑的。
未知节点稳定性:不稳定,插值结果和拉格朗日插值算法是一样的,所以都会出现龙格现象,可以考虑把插值节点分段用较低次数的牛顿插值多项式。
牛顿等距插值算法
公式复杂度:比较简单、比较方便。
插值节点顺序:乱序。
插值节点上下左右移动:未知节点也跟着一样的移动。
插值节点上下左右伸缩:
增加插值节点:需要在之前的插值函数上增加一个子函数,插值函数不需要全部重新计算,但所有的未知节点都要重新计算。
删除插值节点:需要把之前的插值函数全部重新计算,所有的未知节点都要重新计算。
未知节点光滑性:总体都是光滑的。
未知节点稳定性:不稳定,牛顿等距插值算法就是在插值节点都是等距离的情况下对牛顿插值算法进行了简化计算,插值结果和牛顿插值算法是一样的。
连分式插值算法
公式复杂度:比较简单、比较方便。
插值节点顺序:乱序。
插值节点上下左右移动:未知节点也跟着一样的移动。
插值节点上下左右伸缩:
增加插值节点:需要在之前的插值函数上增加一个子函数,插值函数不需要全部重新计算,但所有的未知节点都要重新计算。
删除插值节点:需要把之前的插值函数全部重新计算,所有的未知节点都要重新计算。
未知节点光滑性:在某些情况下是总体都是光滑的,在某些情况下某些点会不连续。
未知节点稳定性:在某些情况下是总体都是稳定,在某些情况下某些点会趋于正无穷大或负无穷大。
其他:在某些情况下,如果出现除数为0,则这些情况下不能使用连分式插值算法。
-
最邻近插值算法、Nearest Neighbor interpolation、零阶插值算法
最邻近插值算法也叫做零阶插值算法,主要原理是未知节点等于邻域内离它距离最近的插值节点。
例如下图,未知节点P1距离插值节点0的距离小于插值节点100的距离,因此,未知节点P1插值为0。这个算法的优点是计算简单方便,缺点是插值结果不够平滑。

-
线性插值算法、Linear Interpolation Algorithm、两点插值算法、直线插值算法、折线插值算法、一次函数插值算法
设已知某函数在给定两个互异的点、上的函数值为、,构造一个线性函数,使其近似于函数,且满足、,那么我们将这样的线性函数称为的线性插值函数,整个这个算法称为线性插值算法、两点插值算法、直线插值算法、折线插值算法、一次函数插值算法。
从几何上看,线性插值就是经过给定两个互异的点、的一条直线,如图:
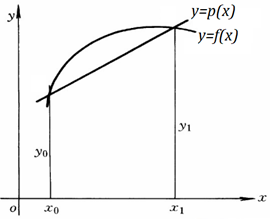
线性插值函数的构造算法:
第一种:
用线性函数的一般公式进行求解,将点、代入公式中,得到一个二元一次方程组,然后求解出和,最后得到的一元二次函数就是经过这点、的线性插值函数了。
第二种:
线性插值函数可以看成是两个直线函数相加而成的,第一个直线函数要经过点和,第二个直线函数要经过点和。
构造两个函数和,使函数满足、,使函数满足、,则可以使得函数成立。如图:
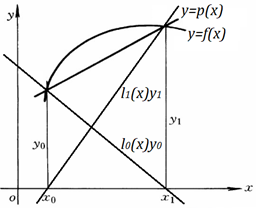
那么只要构造出函数和就可以了。
构造函数:
因为,且式子在时等于0,所以。
因为,所以,所以。
所以。
构造函数:
因为,且式子在时等于0,所以。
因为,所以,所以。
所以。
最后得出函数,这个函数就叫做线性插值函数、线性插值多项式,我们将这里的函数和称为线性插值基函数、线性基本插值多项式。
第三种:
我们先构造一个函数,要使函数经过点,则,函数。
再构造一个函数。
要使函数经过点,则要使函数,那么我们设函数,则。
要使函数经过点,则,则,则。
最后得出函数,这个函数就叫做线性插值函数、线性插值多项式。
如果我们已知有多个互异的点,那么当内插值时,我们要求的未知点在哪两个点之间,就用这两个点的线性插值函数去求,当外插值时,我们要求的未知点离哪两个点最近,就用这两个点的线性插值函数去求。如图:
总结:线性插值算法计算方便、应用很广,但由于它是用直线去近似曲线,因而一般要求相邻两个点的范围比较小,且在相邻两个点上变化比较平稳,否则线性插值的误差可能很大。
例题:已知、,用线性插值算法求。
解:根据已知条件得到两点、,代入线性插值函数得
那么
例题:已知两个点、,用线性插值算法求的函数值。
解:根据已知条件得到两点、,代入线性插值函数得
那么
-
抛物线插值算法、Parabolic Interpolation Algorithm、二次曲线插值算法、二次函数插值算法
设已知某函数在给定三个互异的点、、上的函数值为、、,构造一个线性函数,使其近似于函数,且满足、、,那么我们将这样的抛物线函数称为的抛物线插值函数,整个这个算法称为抛物线插值算法、二次曲线插值算法、二次函数插值算法。
从几何上看,抛物线插值就是经过给定三个互异的点、、的一条曲线,如图:
抛物线插值函数的构造算法:
第一种:
用抛物线函数的一般公式进行求解,将点、、代入公式中,得到一个三元一次方程组,然后求解出、、,最后得到的一元三次函数就是经过这点、、的抛物线插值函数了。
第二种:
抛物线插值函数可以看成是三个抛物线函数相加而成的,第一个抛物线函数要经过点、、,第二个抛物线函数要经过点、、,第三个抛物线函数要经过点、、。
构造三个函数、、,使函数满足、、,使函数满足、、,使函数满足、、,则可以使得函数成立。如图:
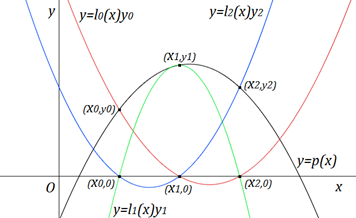
那么只要构造出函数、、就可以了。
构造函数:
因为、,且式子在或时等于0,所以。
因为,所以要使,则。
所以。
构造函数:
因为、,且式子在或时等于0,所以。
因为,所以要使,则。
所以。
构造函数:
因为、,且式子在或时等于0,所以。
因为,所以要使,则。
所以。
最后得出函数,这个函数就叫做抛物线插值函数、抛物线插值多项式,我们将这里的函数、、称为抛物线插值基函数、抛物线基本插值多项式。
第三种:
在线性插值函数的基础上,我们再构造一个函数。
要使函数经过点、,则要使函数且,那么我们设函数,则。
要使函数经过点,则,则,则。
最后得出函数,这个函数就叫做抛物线插值函数、抛物线插值多项式。
如果我们已知有多个互异的点,就要每三点分为一组,那么当内插值时,我们要求的未知点在哪三个点之间,就用这三个点的抛物线插值函数去求,当外插值时,我们要求的未知点离哪三个点最近,就用这三个点的抛物线插值函数去求。如图:
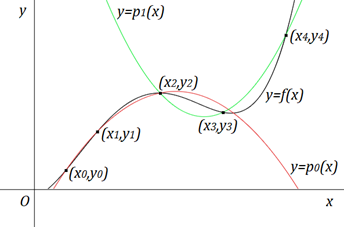
总结:抛物线插值算法相比线性插值算法的计算量略大,但由于它是用抛物线去近似曲线,所以比线性插值算法略好,但还是要求相邻三个点的范围比较小,且在相邻三个点上变化比较平稳,否则抛物线插值的误差可能较大。
例题:已知、、,用抛物线插值算法求。
解:根据已知条件得到三点、、,代入抛物线插值函数得
那么
-
联立方程式
-
拉格朗日插值算法、Lagrange Interpolation Algorithm
我们根据线性插值算法和抛物线插值算法的插值函数,可以推导出已知个互异离散点的插值函数。
根据已知两个互异离散点的线性插值函数:
和已知三个互异离散点的抛物线插值函数:
得出,已知四个互异离散点的插值函数就是可以看成是四个基函数相加而成的,函数的公式为:
归纳可得,已知个互异离散点的插值函数就是可以看成是个基函数相加而成的,函数的公式为
其中
我们将最后推导出来的函数称为拉格朗日插值函数、拉格朗日插值多项式,其中基函数称为拉格朗日插值基函数、拉格朗日基本插值多项式,整个这个算法称为拉格朗日插值算法。
-
拉格朗日插值误差估计算法







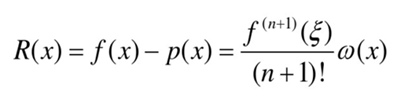
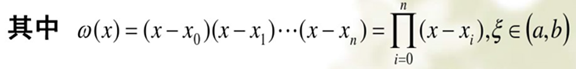




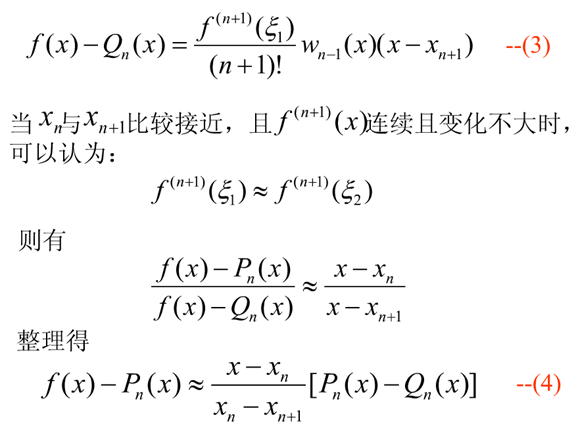





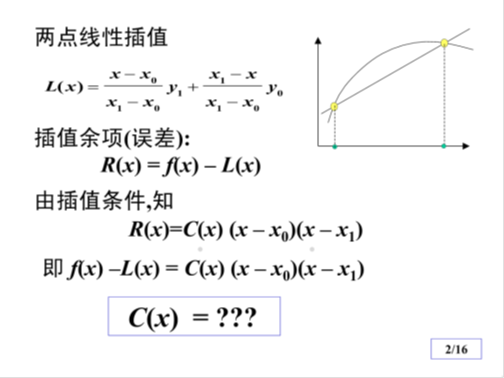





插值法的事后误差估计:
已知,,,试用线性插值求的近似值,并估计插值误差。
解:要用线性插值求在点的值,可取,为插值节点,记线性插值式为。经计算易得。
但是,由于不知道的解析式,故不能直接利用拉格朗日余项式做误差估计。为此,下面用另外一种方法来估计误差。
设以,为节点的线性插值式为,则有
其中,均属于由、、和所决定的区间。假设在该区间内变化不大,则将上面两个式子相除,消去近似相等的和,结果有
整理得
这表明,的插值误差大致等于,按此估计式,只要再计算出。由此可得的误差估计
进一步还可以考虑用事后误差估计式对进行修正。因为事后误差估计给出了大致误差值,如果用这个误差值作为的一种补偿,得到
可以期望,是的更好的插值结果。在本题中,利用上述可以算得
事实上,被插值函数为,按上述方法得到的插值结果与抛物插值的结果相同,精度的确提高了。
值得说明的是,这并不只是简单的巧合。将式展开即可证明,上述就是抛物线插值多项式。
根据这种思想,人们还建立了逐步线性插值的埃特金插值法。
-
重心拉格朗日插值算法、Barycentric Lagrange Interpolation Algorithm
重心拉格朗日插值法是拉格朗日插值法的一种改进。在拉格朗日插值法中,运用多项式
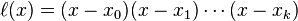
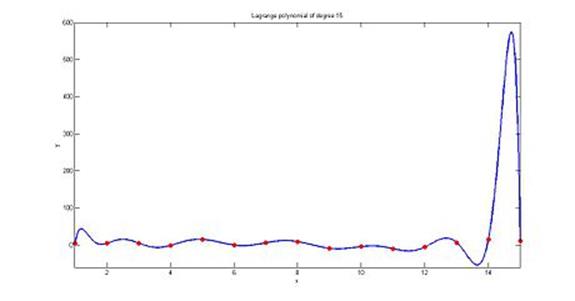


拉格朗日插值法的数值稳定性:如图,用于模拟一个十分平稳的函数时,插值多项式的取值可能会突然出现一个大的偏差(图中的14至15中间),也就是龙格现象。
可以将拉格朗日基本多项式重新写为:
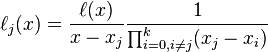
定义重心权
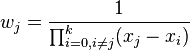
上面的表达式可以简化为:
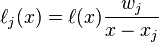
于是拉格朗日插值多项式变为:
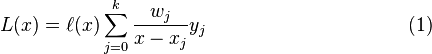
即所谓的重心拉格朗日插值公式(第一型)或改进拉格朗日插值公式。它的优点是当插值点的个数增加一个时,将每个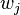 都除以
都除以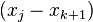 ,就可以得到新的重心权
,就可以得到新的重心权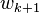 ,计算复杂度为
,计算复杂度为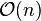 ,比重新计算每个基本多项式所需要的复杂度
,比重新计算每个基本多项式所需要的复杂度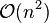 降了一个量级。
降了一个量级。
将以上的拉格朗日插值多项式用来对函数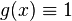 插值,可以得到:
插值,可以得到:
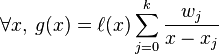
因为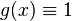 是一个多项式。
是一个多项式。
因此,将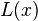 除以
除以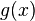 后可得到:
后可得到:
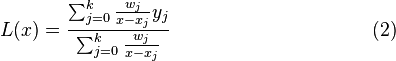
这个公式被称为重心拉格朗日插值公式(第二型)或真正的重心拉格朗日插值公式。它继承了(1)式容易计算的特点,并且在代入x值计算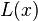 的时候不必计算多项式
的时候不必计算多项式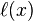 。它的另一个优点是,结合切比雪夫节点进行插值的话,可以很好地模拟给定的函数,使得插值点个数趋于无穷时,最大偏差趋于零。同时,重心拉格朗日插值结合切比雪夫节点进行插值可以达到极佳的数值稳定性。第一型拉格朗日插值是向后稳定的,而第二型拉格朗日插值是向前稳定的,并且勒贝格常数很小。
。它的另一个优点是,结合切比雪夫节点进行插值的话,可以很好地模拟给定的函数,使得插值点个数趋于无穷时,最大偏差趋于零。同时,重心拉格朗日插值结合切比雪夫节点进行插值可以达到极佳的数值稳定性。第一型拉格朗日插值是向后稳定的,而第二型拉格朗日插值是向前稳定的,并且勒贝格常数很小。
注意:当时,除数为0,这时就不能使用重心拉格朗日插值算法了。
java代码:
|
import java.util.Scanner;
public class BarycentricLagrangeInterpolation { private static double[] BELIE(double x[],double y[],double x0[]) { int m = x.length; int n = x0.length; double y0[] = new double[n]; for(int yi = 0;yi < n;yi ++) { double j = 0,k = 0,l = 0; int ic = 0; for(int ia = 0;ia < m;ia ++) { double w = 1; for(int ib = 0;ib < m;ib ++) { if(ia != ib) w /= (x[ia] - x[ib]); } System.out.println(w); k += (w / ((x0[yi] - x[ic]))) * y[ic]; l += (w / ((x0[yi] - x[ic]))); ic ++ ; j = k / l; } y0[yi] = j; } return y0; }
public static void main(String[] args) { System.out.println("请输入给定的插值点数量:"); Scanner input = new Scanner(System.in); int m = input.nextInt(); System.out.println("请输入需求解的插值点数量:"); int n = input.nextInt(); double x[] = new double[m]; double y[] = new double[m]; double x0[] = new double[n]; System.out.println("依次输入给定的插值点:"); for(int i = 0;i < m;i ++){ x[i] = input.nextDouble(); } System.out.println("依次输入给定的插值点对应的函数值:"); for(int i = 0;i < m;i ++){ y[i] = input.nextDouble(); } System.out.println("依次输入需求解的插值点"); for(int i = 0;i < n;i ++){ x0[i] = input.nextDouble(); } double y0[] = BELIE(x, y, x0); System.out.println("运用重心拉格朗日插值法求解得:"); for(int i = 0;i < n;i ++){ System.out.println(y0[i] + " "); } System.out.println(); input.close(); } } |
-
牛顿插值算法、Newton Interpolation Algorithm
我们根据线性插值算法和抛物线插值算法,可以推导出已知个互异离散点的插值函数。
根据已知两个互异离散点的线性插值函数:
和已知三个互异离散点的抛物线插值函数:
得出,已知四个互异离散点的插值函数就是可以看成是函数与相加而成的,函数的公式为:
用差商公式,函数的公式可以变形为:
归纳可得,已知个互异离散点的插值函数就是可以看成是函数与相加而成的,函数的公式为
我们将最后得到的函数称为牛顿插值函数、牛顿插值多项式,整个这个算法称为牛顿插值算法。
-
牛顿等距插值算法、Newton Equidistance Interpolation Algorithm
设函数经过个等距节点、、…、,且,代入牛顿插值函数得
根据等距向前差商公式得
所以牛顿等距向前插值函数为
设函数经过个等距点、、…、、,且,代入牛顿插值函数得
根据等距向后差商公式得
所以牛顿等距向后插值函数为
整个这个算法称为牛顿等距插值算法。
使用本公式前,需要先建立差分表,然后再计算未知点的函数值就能大大降低计算量。
-
连分式插值算法、Continued Fraction Interpolation Algorithm
插值函数的推导:
常量的推导:
-
二次样条曲线插值算法、Quadratic Spline Interpolation Algorithm
二次样条曲线插值算法的原理:
我们会想到既然直线不行,那么我们就用曲线来近似的代替和描述。最简单的曲线是二次函数,如果我们用二次函数:aX^2+bx+c来描述曲线,最后的结果可能会好一点,下图中一共有4个点,可以分成3个区间。每一个区间都需要一个二次函数来描述,一共需要9个未知数。下面的任务就是找出9个方程。
如下图所示:一共有x0,x1,x2,x3四个点,三个区间,每个区间上都有一个方程。
1>曲线方程在节点处的值必须相等,即函数在x1,x2两个点处的值必须符合两个方程,这里一共是4个方程:
a1*x1^2+b1*x1+c1=f(x1)
a2*x1^2+b2*x1+c2=f(x1)
a2*x2^2+b2*x2+c2=f(x2)
a3*x2^2+b3*x2+c3=f(x2)
2>第一个端点和最后一个端点必须过第一个和最后一个方程:这里一共是2个方程
3>节点处的一阶导数的值必须相等。这里为两个方程。
2*a1*x1+b1=2*a2*x1+b2
2*a2*x2+b2=2*a3*x2+b3
4>在这里假设第一个方程的二阶导数为0:这里为一个方程:
a1=0
上面是对应的9个方程,现在只要把九个方程联立求解,最后就可以实现预测x=5处节点的值。


下面是写成矩阵的形式,由于a1=0,所以未知数的个数少了一个。


二次样条函数运行之后的结果如下,从图像中,我们可以看出,二次样条在函数的连接处的曲线是光滑的。这时候,我们将x=5输入到函对应的函数端中,就可以预测相应的函数值。但是,这里还有一个问题,就是二次样条函数的前两个点是直线,而且函数的最后一个区间内看起来函数凸出很高。我们还想解决这些问题,这时候,我们想是否可以用三次样条函数来进行函数的模拟呢?
-
三次样条曲线插值算法、Cubic Spline Interpolation Algorithm
设已知某函数在给定个互异的点、、、上的函数值为、、、,且,且,这个互异点共组成了个区间,每个区间都对应一个一元三次多项式函数用于插值,每个函数都满足、,且、,然后再指定一种边界条件,最后得到一个分段插值函数,那么我们将这样的分段插值函数称为的三次样条曲线插值函数,整个这个算法称为三次样条曲线插值算法。
三次样条曲线插值函数的构造算法:
设第个区间对应的一元三次多项式函数为
则
因为,所以
因为,,所以
因为,,所以
因为,,所以
整理得
因为,,所以
整理得
因为,,所以
整理得
因为,,,所以
整理得
因为,所以得到个方程:
以上方程一共有个未知数,如果要解出这些未知数,必须要方程,所以还需要个方程,因此我们再指定一种边界条件来构造这个方程。
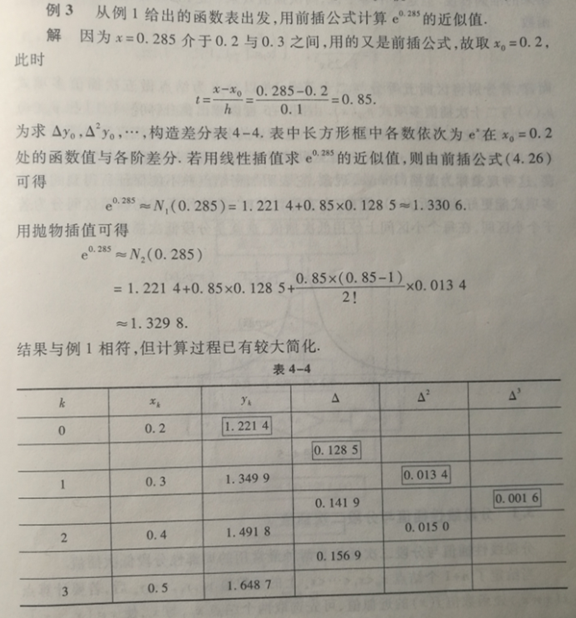
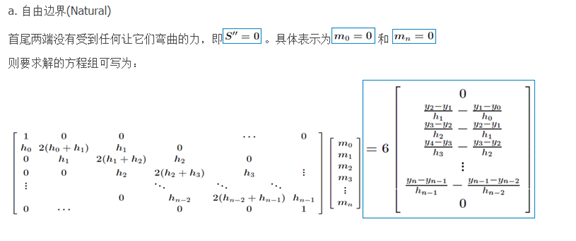
自然边界条件(Natural Boundary Condition):
第一类自然边界条件就是当首尾端点的一阶导数都等于的情况,也就是,。
第二类自然边界条件就是当首尾端点的二阶导数都等于的情况,也就是,。
固定边界条件(Clamped Boundary Condition):
第一类固定边界条件就是当首尾端点的一阶导数都等于指定的数的情况,也就是,。
第二类固定边界条件就是当首尾端点的二阶导数都等于指定的数的情况,也就是,。

周期边界条件(Period Boundary Condition):
周期边界条件就是当插值函数是以为周期的情况,也就是,,。
非节点边界条件(Not-A-Knot Boundary Condition):
非节点边界条件就是当首尾插值函数的三阶导数相等的情况,也就是,。
计算过程:
因为,,,,所以
整理得
最后由个方程的系数组成的系数行列式和常数项为
用克拉默定理解出以上行列式中个,然后再因为、,从而解出个、,最终得到一个分段插值函数就是三次样条曲线插值函数了。
当插值节点大于等于个时,用克拉默定理可以推导出,,,从而简便计算。当插值节点为或个时,还是要按照克拉默定理计算。当插值节点为个时,系数行列式等于方程组无唯一解。当插值节点为或个时,系数行列式无法解出。
-
三次B样条曲线插值算法
https://blog.csdn.net/liumangmao1314/article/details/54586761
https://blog.csdn.net/liumangmao1314/article/details/54588155
-
埃尔米特插值算法、Hermite Interpolation Algorithm
-
分段低次插值算法
-
贝塞尔曲线插值算法
-
克里金插值算法
-
埃特金逐步线性插值法、Aitken successive lin-ear interpolation method
样条之埃特金(Aitken)逐步插值函数
//////////////////////////////////////////////////////////////////////
// 埃特金逐步插值
//////////////////////////////////////////////////////////////////////
static float GetValueAitken(const void* valuesPtr, int stride, int n, float t, float eps)
{
int i,j,k,m,l;
float z,xx[10],yy[10];
// 初值
z = 0.0f;
// 特例处理
if (n < 1)
{
return(z);
}
if (n == 1)
{
z = YfGetFloatValue(valuesPtr, stride, 0);
return(z);
}
float xStep = 1.0f/(n - 1);
// 开始插值
m=10;
if (m > n)
{
m = n;
}
if (t <= 0.0f)
{
k = 1;
}
else if (t >= (n-1)*xStep)
{
k = n;
}
else
{
k = 1;
j = n;
while ((k-j != 1) && (k-j != -1))
{
l = (k+j)/2;
if (t < (l-1)*xStep)
j = l;
else
k = l;
}
if (fabs(t-((l-1)*xStep)) > fabs(t-(j-1)*xStep))
{
k = j;
}
}
j = 1;
l = 0;
for (i = 1; i <= m; i++)
{
k = k+j*l;
if ((k<1) || (k>n))
{
l = l+1;
j = -j;
k = k+j*l;
}
xx[i-1] = (k-1)*xStep;
yy[i-1] = YfGetFloatValue(valuesPtr, stride, k - 1);
l = l+1;
j = -j;
}
i = 0;
do
{
i = i+1;
z = yy[i];
for (j = 0; j <= i-1; j++)
{
z = yy[j]+(t-xx[j])*(yy[j]-z)/(xx[j]-xx[i]);
}
yy[i] = z;
}
while ((i != m-1) && (fabs(yy[i]-yy[i-1]) > eps));
return(z);
}
-
最小二乘法
最小二乘估计参数可以用James–Stein estimator方法代替。
-
Lanczos插值算法
-
混音、Audio Mixing、MIX
在多人语音聊天时,我们需要同时播放来自于多个人的语音数据,而声卡播放的缓冲区只有一个,所以,需要将多路语音混合成一路,这就是混音算法要做的事情。混音可以在客户端进行,也可以在服务端进行(可节省下行的带宽)。
混音公式:C = A + B - ( A * B >> 0x10 )
A和B就是两路不同的音频数据,C就是混音后的音频数据,混音后还需要对C进行防止数据溢出的处理,否则,可能会有破音。
如果是16位整型音频数据,就是:
if( C > 32767 ) C = 32767;
else if( C < -32768 ) C = -32768;
如果是32位浮点型音频数据,就是:
if( C > 1 ) C = 1;
else if( C < -1 ) C = -1;
icoolmedia的混音方法:


-
远距离拾音、FFP
用户可以在远距离对着麦克风说话,录音依然清晰。
-
自动语音识别、Automatic Speech Recognition、ASR、语音识别、Speech Recognition
将人类语音中的语句内容转换为计算机可显示的字符信息,这个过程我们称为自动语音识别,也称语音识别。
例如:有人说"拨打电话给114",计算机就会根据这段声波识别出这句的内容是"拨打电话给114",然后如果有软件设定好了"拨打电话给"这样的内容就是调用打电话接口,那么计算机就会拨号114。
-
文语转换、Text To Speech、TTS、语音合成、Speech Synthesis
将计算机可显示的字符信息转变为可以人类听得懂的语音,这个过程我们称为文语转换,也称语音合成。
例如:计算机中有一段字符"你好,我是人工智能机器人。",计算机就可以将这段字符信息换转换为语音信号播放出来给人类听,并且人类还可以听懂。
语音合成系统有:WORLD。
pitchshift之world: https://github.com/mmorise/World
pitchshift之straight: https://github.com/HidekiKawahara/legacy_STRAIGH
-
声纹识别、Voiceprint Recognition
-
自发性知觉经络反应、Autonomous Sensory Meridian Response、ASMR
-
音频变时不变调
SoundTouch库
波形相似叠加、Waveform Similarity Overlap-Add、WSOLA
https://blog.csdn.net/audio_algorithm/article/details/105126728
https://www.docin.com/p-1271886370.html
-
预加重
在语音发音过程中,口唇辐射的影响下,声带和嘴唇造成的效应,发音系统压抑了高频部分。
为了消除发声过程中,声带和嘴唇造成的效应,来补偿语音信号受到发音系统所压抑的高频部分。并且能突显高频的共振峰。
简单理解就是在频域上面都乘以一个系数,这个系数跟频率成正相关,所以高频的幅值会有所提升。
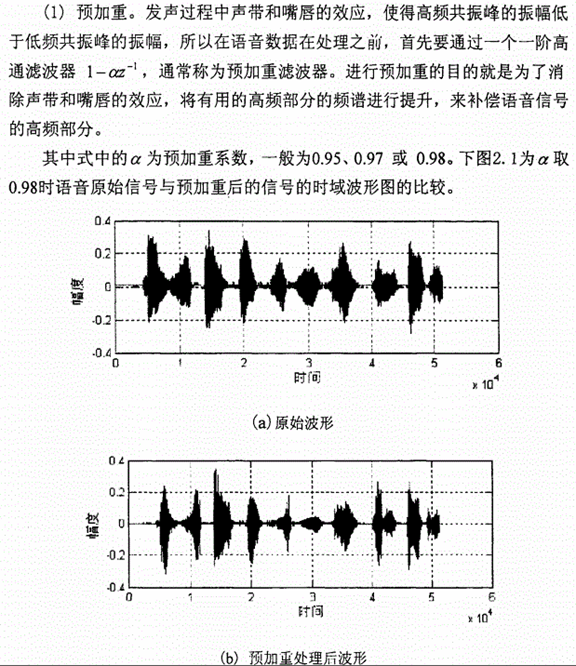
一般通过传递函数为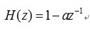 一阶FIR高通数字滤波器来实现预加重,其中a为预加重系数,0.9<a<1.0。设n时刻的语音采样值为x(n),经过预加重处理后的结果为y(n))=x(n)-ax(n-1),这里取a=0.98。
一阶FIR高通数字滤波器来实现预加重,其中a为预加重系数,0.9<a<1.0。设n时刻的语音采样值为x(n),经过预加重处理后的结果为y(n))=x(n)-ax(n-1),这里取a=0.98。
预加重实验:
%预加重程序 2013/9/25
clear all;
[x,sr]=wavread('test2.wav'); %sr为采样频率
ee=x(1500:1755);
r=fft(ee,1024);
r1=abs(r);
pinlv=(0:1:255)*8000/512;
yuanlai=20*log10(r1);
signal(1:256)=yuanlai(1:256);
[h1,f1]=freqz([1,-0.98],[1],256,4000);
pha=angle(h1);
H1=abs(h1);
r2(1:256)=r(1:256);
u=r2.*h1';
u2=abs(u);
u3=20*log10(u2);
un=filter([1,-0.98],[1],ee);
figure(1);subplot(2,1,1);
plot(f1,H1);title('高通滤波器的幅频特性');
xlabel('频率/Hz');ylabel('幅度');
subplot(2,1,2);plot(pha);title('高通滤波器的相频特性');
xlabel('频率/Hz');ylabel('角度/rad');
figure(2);subplot(2,1,1);plot(ee);title('原始语音信号');
%axis([0 256 -3*10^4 2*10^4]);
xlabel('样点数');ylabel('幅度');
subplot(2,1,2);plot(un);title('经高通滤波后的语音信号');
%axis([0 256 -1*10^4 1*10^4]);
xlabel('样点数');ylabel('幅度');
figure(3);subplot(2,1,1);plot(pinlv,signal);title('原始语音信号频谱');
xlabel('频率/Hz');ylabel('幅度/dB');
subplot(2,1,2);plot(pinlv,u3);title('经高通滤波后的语音信号频谱');
xlabel('频率/Hz');ylabel('幅度/dB');
实验结果:
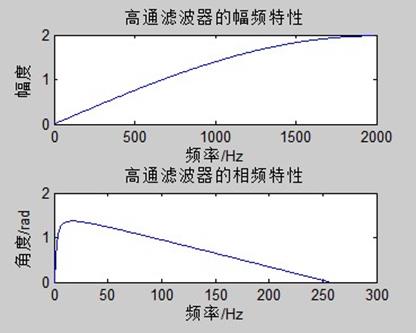
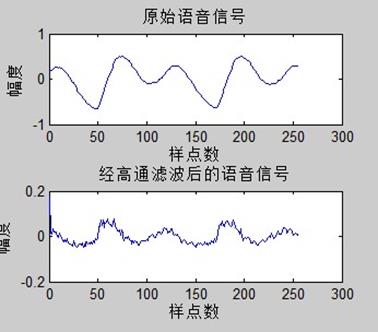
可以看出,预加重后的频谱在高频部分的幅度得到了提升。
-
分帧(chunk)
傅里叶变换要求输入的信号的平稳的。


语音信号在宏观上是不平稳的,在微观上是平稳的,具有短时平稳性(10---30ms内可以认为语音信号近似不变),这个就可以把语音信号分为一些短段来进行处理,每一个短段称为一帧(CHUNK)。
如果后续操作需要加窗,则在分帧的时候,不要背靠背地截取,而是相互重叠一部分。相邻两帧的起始位置的时间差叫做帧移(STRIDE)。
-
加窗

加窗即与一个窗函数相乘,加窗之后是为了进行傅里叶展开。
1、使全局更加连续,避免出现吉布斯效应
2、加窗时候,原本没有周期性的语音信号呈现出周期函数的部分特征。
加窗的代价是一帧信号的两端部分被削弱了,所以在分帧的时候,帧与帧之间需要有重叠。

进行预加重数字滤波处理后,下面就是进行加窗分帧处理,语音信号具有短时平稳性(10--30ms内可以认为语音信号近似不变),这样就可以把语音信号分为一些短段来来进行处理,这就是分帧,语音信号的分帧是采用可移动的有限长度的窗口进行加权的方法来实现的。一般每秒的帧数约为33~100帧,视情况而定。一般的分帧方法为交叠分段的方法,前一帧和后一帧的交叠部分称为帧移,帧移与帧长的比值一般为0~0.5,。
汉明窗函数如下:
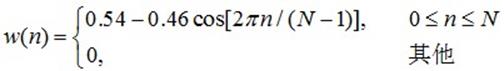
汉明窗的时域和频域波形,窗长N=61
x=linspace(20,80,61);
h=hamming(61);
figure(1);
subplot(1,2,1);
plot(x,h,'k');title('汉明窗时域波形');
xlabel('样点数');ylabel('幅度');
w1=linspace(0,61,61);
w1(1:61)=hamming(61);
w2=fft(w1,1024);
w3=w2/w2(1);
w4=20*log10(abs(w3));
w=2*[0:1023]/1024;
subplot(1,2,2);
plot(w,w4,'k');
axis([0,1,-100,0]);
title('汉明窗幅度特性');
xlabel('归一化频率');ylabel('幅度/dB');
结果:
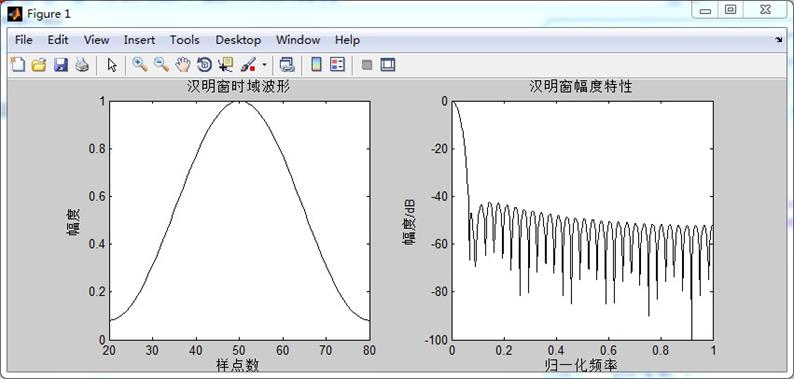
汉明窗的主瓣宽度较宽,是矩形窗的一倍,但是汉明窗的旁瓣衰减较大,具有更平滑的低通特性,能够在较高的程度上反应短时信号的频率特性。
矩形窗的主瓣宽度小于汉明窗,具有较高的频谱分辨率,但是矩形窗的旁瓣峰值较大,因此其频谱泄露比较严重。
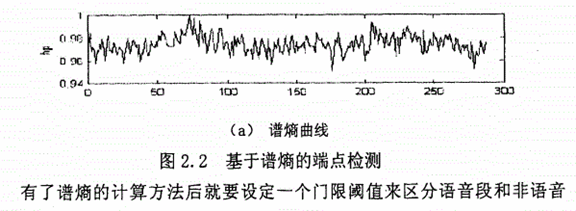
端点检测


-
专业术语
模数转换器、Analog to Digital Converter、ADC
数模转换器、Digital to Analog Converter、DAC
数字信号处理、Digital Signal Processing、DSP
数字信号处理器、Digital Signal Processor、DSP
声学回音消除、Acoustic Echo Cancellation、AEC
声学回音消除器、Acoustic Echo Canceller、AEC
残余回音消除、Residual Echo Cancellation、REC
残余回音消除器、Residual Echo Canceller、REC
噪音抑制、降噪、Denoise、Noise Suppression、NS
混响消除、Dereverberation、De-Reverberation、Dereverb、DR
自适应抖动缓冲区、Adaptive Jitter Buffer、AJB
自适应抖动缓冲器、Adaptive Jitter Buffer、AJB
Speex专用自适应抖动缓冲器、Speex Adaptive Jitter Buffer、SpeexAJB
预处理、Preprocess
预处理器、Preprocessor
数据包丢失隐藏、Packet Loss Concealment、PLC
非连续传输、Discontinuous transmission、DTX
强化立体声编码、Intensity Stereo Encoding、ISE
固定比特率、Constant Bit Rate、CBR
可变比特率、Variable Bit Rate、VBR
平均比特率、Average Bit Rate、ABR
非连续传输、Discontinuous transmission、DTX
定点执行、Fixed-point implementation
浮点执行、Floating-point implementation
自动增益控制、Automatic Gain Control、AGC
语音活动检测、Voice Activity Detection、VAD
多速率、multi-rate
嵌入式、Embedded
重采样、Resample
-
参考资料
https://blog.csdn.net/qq_34218078/article/details/102830558
https://www.cnblogs.com/LXP-Never/p/11703440.html
https://huaweicloud.blog.csdn.net/article/details/109592524
https://bbs.huaweicloud.com/blogs/207318
https://my.oschina.net/anevernet/blog/37285?p=1
https://www.cnblogs.com/haibindev/archive/2011/12/07/2277366.html
https://blog.jianchihu.net/pcm-volume-control.html
https://blog.jianchihu.net/pcm-vol-control-advance.html
https://docs.microsoft.com/en-us/windows/win32/coreaudio/audio-tapered-volume-controls
噪音门(Noise Gate):
https://zhuanlan.zhihu.com/p/68707538
懂听:
https://www.bilibili.com/video/BV147411j7fL
https://www.bilibili.com/video/BV1tE41147LP
https://www.bilibili.com/video/BV1fE411M7Ug
https://www.bilibili.com/video/BV1tE41157cB
【硬件科普】音响耳机麦克风这些设备是怎么工作的?音频的采样率和采样精度是什么?:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】