
sphinx中文版Coreseek中文检索引擎安装和使用方法(Windows)
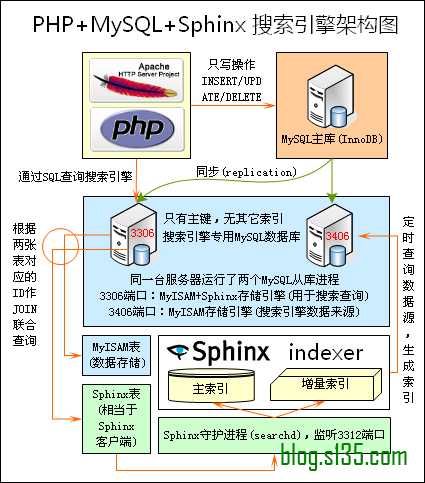
昨天闲下来研究了MYSQL的索引优化,继而了解了MYSQL的全文检索,在大数据量下如果你使用like去检索数据库的信息的实现全文检索,那么恭喜你你会暴库。。
全文检索引擎中Sphinx是比较优秀的,但是对中文支持不是很多,所以就有了Coreseek,核心是Sphinx引擎,但是对中文检索有了很好的支持,而且有很全的中文文档,开源免费试用,支持Windows、Linunx甚至是Mac。
Coreseek介绍
Coreseek 全面支持: FreeBSD6/7/8,Mac OS X 10.6,RHEL5、CentOS-5、Fedora-12/13、gentoo-10、openSUSE-10/11、slackware-13.0/13.1、debian-5、ubuntu-9/10、archlinux-2010,WindowsXP、Windows2003、Windows7、Windows Server 2008等,32与64位操作系统均可使用,可支持MySQL、MariaDB、PostgreSQL、SQL Server、Oracle等多种数据库系统,并提供Python万能数据源以支持任意来源的数据。
常用的文件和目录
Coreseek/
/api/
sphinxapi.php #针对PHP的api,实际上是一个类
/bin/
indexer.exe #建立索引的命令
searchd.exe #监听端口,开启服务的命令
search.exe #执行搜索命令
mmseg.exe #词库相关命令
/etc/
*.conf #配置文件
unigram.txt #词库文件txt
thesaurus.txt #同义词词库文件 txt
uni.lib #建立索引用到的词库文件,由mmseg命令加工 # unigram.txt文件形成
/var/
/data/ #索引存放位置
Coreseek安装
以下是介绍在windows下测试环境的安装(不建议把coreseek正式部署在windows),首先去官方网站下载稳定版本的安装包(3.2版本),下载后解压缩到一个文件夹,如解压缩到C盘:路径为 C:\coreseek-3.2.14-win32,以下为安装coreseek windows版本记录
1. 安装searchd服务
cd c:/ C:\coreseek-3.2.14-win32\bin\searchd.exe --install --config C:\coreseek-3.2.14-win32\csft.conf --servicename coreseekd
注意: 命令一定要是绝对路径,不能使用PATH变量或短路径
你需要先配置csft.conf文件,笔者测试的MYSQL,详见第二条
Coreseek/Sphinx有几个命令调用命令 searchd,search,indexer,spelldump,indextool,以下为摘录于官方文档:
1.
indexer命令参考
indexer是Sphinx的两个关键工具之一。不管是从命令行直接调用,还是作为一个较大的脚本的一部分使用,indexer都只负责一件事情——收集要被检索的数据。
indexer的调用语法基本上是这样:indexer [OPTIONS] [indexname1 [indexname2 [...]]]用户可以在
sphinx.conf中设置好可能有哪些索引(index)(这些索引可以在晚些时候别搜索),因此在调用indexer的时候,最简单的情况下,只需要告诉它你要简历哪个(或者哪些)索引就行了。假设
sphinx.conf包含了两个索引的具体设置,mybigindex和mysmallindex, ,你可以这么调用:$ indexer mybigindex $ indexer mysmallindex mybigindex在配置文件
sphinx.conf里面,用户可以为他们的数据指定一个或多个索引。然后调用indexer来对其中一个特定的索引进行重新编制索引操作,或者是重新编制所有索引——不限于某一个或同时全部,用户总是可以指定现有索引的一个组合。
indexer的大部分选项都可以在配置文件中给出,然而有一部分选项还需要在命令行上指定,这些选项影响编制索引这一操作是如何进行的。这些选项列举如下:
--config <file>(简写为-c <file>) 使indexer将指定的文件file作为配置文件。 通常,indexer是会在安装目录(例如e.g./usr/local/sphinx/etc/sphinx.conf,如果sphinx被安装在/usr/local/sphinx)中寻找sphinx.conf,若找不到,则继续在用户在shell中调用indexer时所在的目录中寻找。 这个选项一般在共享sphinx安装的情况下使用,比如二进制文件安装在/usr/local/sphinx,而不同用户都有权定制自己的sphinx设置。或者在同一个服务器上运行多个实例的情况下使用。在上述两中情况中,用户可以创建自己的sphinx.conf文件,然后把它做为参数传给indexer。例如:$ indexer --config /home/myuser/sphinx.conf myindex--all使indexer对sphinx.conf文件中列出的所有索引进行重新编制索引,这样就不比一次列出每个索引的名字了。这个选项在配置文件较小的情况下,或者在类似基于cron的维护工作中很有用。在上述情况中,整个索引集每天或每周或别的什么合适的时间间隔中就重新建立一次。用法示例:$ indexer --config /home/myuser/sphinx.conf --all--rotate用于轮换索引。对新的文档建立索引时几乎肯定都确保搜索服务仍然可用,除非你有信心在搜索服务停止同时不给你的用户带来困扰。--rotate建立一个额外的索引,并列于原有索引(与原有索引在相同目录,简单地在原有索引文件名基础上加一个.new后缀)。一旦这个额外的索引建立完成,indexer给searchd发一个SIGHUP信号做为通知。searchd会尝试将索引重新命名(给原有索引加上.old后缀,而把带有.new后缀的新索引改为原名,以达替换之目的),继而用新的文件重启服务。依 seamless_rotate 选项设定之不同,在新索引可用之前可能有一点小的延迟。用法示例:$ indexer --rotate --all--quiet使indexer不输出除错误(error)外的任何东西。这个选项仍然拽可用在cron定时任务的情境下或者脚本中,这些情况下大部分输出是无关紧要或完全没用的,除非是发生了某些种类的错误。用法示例:$ indexer --rotate --all --quiet--noprogress不随时显示进度信息,而是仅在索引结束时报告最终的状态细节(例如为哪些文档建立了索引,建立索引的速度等)。当脚本没有运行在一个控制台(console,或“tty”)时,这个选项是默认的。用法示例:$ indexer --rotate --all --noprogress--buildstops <outputfile.text> <N>像建立索引一样扫描索引对应的数据源,产生一个最终会被加入索引的词项的列表。换种说法,产生一个用这个索引可以检索的词项的列表。注意,这个选项使indexer并不真正更新指定的索引,而只是“假装”建在立索引似地处理一遍数据,包括运行sql_query_pre或者sql_query_post选项指定的查询。outputfile.txt文件最终会包含一个词表,每行一个词,按词频排序,高频在前。参数N指定了列表中最多可出现的词项数目,如果N比索引中全部词项的数目还大,则返回的词项数就是全部词项数。客户端应用程序利用这种字典式的词表来提供“您是要搜索。。。吗?(Did you mean…)”的功能,通常这个选项与下面要讲的--buildfreqs选项一同使用。示例:$ indexer myindex --buildstops word_freq.txt 1000这条命令在当前目录产生一个word_freq.txt文件,内含myindex这个索引中最常用的1000个词,且最常用的排在最前面。注意,当指定了多个索引名或使用了--all选项(相当于列出配置文件中的所有索引名)时,这个选项对其中的最后一个索引起作用。--buildfreqs与--buildstops一同使用 (如果没有指定--buildstops则--buildfreqs也被忽略). 它给--buildstops产生的词表的每项增加一个计数信息,即该词在索引中共出现了多少次,这在建立停用词(stop words,出现特别普遍的词)表时可能有用。在开发“您是要搜索。。。吗?(Did you mean…)”的功能时这个选项也能帮上忙,因为有了它你就能知道一个词比另一个相近的词出现得更频繁的程度。示例:$ indexer myindex --buildstops word_freq.txt 1000 --buildfreqs这个命令将产生一个类似于上一条命令的word_freq.txt,但不同在于,每个词的后面都会附加一个数字,指明在指定的索引中这个词出现了多少次。--merge <dst-index> <src-index>用于在物理上将多个索引合并,比方说你在使用“主索引+增量索引”模式,主索引很少改变,但增量索引很频繁地重建,而--merge选项允许将这两个索引合而为一。操作是从右向左进行的,即先考察src-index的内容,然后在物理上将之与dst-index合并,最后结果留在dst-index里。用伪代码说就是dst-index += src-index。示例:$ indexer --merge main delta --rotate上例中main是主索引,很少更动,delta是增量索引,频繁更新。上述命令调用indexer将delta的内容合并到main里面并且对索引进行轮换。--merge-dst-range <attr> <min> <max>在合并索引的时候运行范围过滤。具体地说,向目标索引 (是--merge的一个参数,如果没有指定--merge, 则--merge-dst-range也被忽略)合并时,indexer会对将要合并进去的文档做一次过滤,只有通过过滤才能最终出现在目标索引中。举一个实用的例子,假设某个索引有一个“已删除(deleted)”属性,0代表“尚未删除”。这样一个索引可以用如下命令进行合并:$ indexer --merge main delta --merge-dst-range deleted 0 0这样标记为已删除的文档(值为1)就不会出现在新生成的目标索引中了。这个选项可以在命令行上指定多次,以便指定多个相继的过滤,这样一个文档要想合并到最终的目标索引中去,就必须依次通过全部这些过滤。
searchd也是sphinx的两个关键工具之一。searchd是系统实际上处理搜索的组件,运行时它表现得就像一种服务,他与客户端应用程序调用的五花八门的API通讯,负责接受查询、处理查询和返回数据集。不同于
indexer,searchd并不是设计用来在命令行或者一般的脚本中调用的, 相反,它或者做为一个守护程序(daemon)被init.d调用(在Unix/Linux类系统上),或者做为一种服务(在Windows类系统上),因此并不是所有的命令行选项都总是有效,这与构建时的选项有关。调用
searchd就像这么简单:$ searchd [OPTIONS]不管
searchd是如何构建的,下列选项总是可用:
--help(可以简写为-h) 列出可以在你当前的searchd构建上调用的参数。--config <file>(可简写为-c <file>) 使searchd使用指定的配置文件,与上述indexer的--config开关相同。--stop用来停掉searchd,使用sphinx.conf中所指定的PID文件,因此您可能还需要用--config选项来确认searchd使用哪个配置文件。值得注意的是,调用--stop会确保用UpdateAttributes()对索引进行的更动会反应到实际的索引文件中去。示例:$ searchd --config /home/myuser/sphinx.conf --stop--status用来查询运行中的searchd实例的状态,,使用指定的(也可以不指定,使用默认)配置文件中描述的连接参数。它通过配置好的第一个UNIX套接字或TCP端口与运行中的实例连接。一旦连接成功,它就查询一系列状态和性能计数器的值并把这些数据打印出来。在应用程序中,可以用Status() API调用来访问相同的这些计数器。示例:$ searchd --status $ searchd --config /home/myuser/sphinx.conf --status--pidfile用来显式指定一个PID文件。PID文件存储着关于searchd的进程信息,这些信息用于进程间通讯(例如indexer需要知道这个PID以便在轮换索引的时候与searchd进行通讯)searchd在正常模式运行时会使用一个PID(即不是使用--console选项启动的),但有可能存在searchd在控制台(--console)模式运行,而同时正在索引正在进行更新和轮换操作的情况,此时就需要一个PID文件。$ searchd --config /home/myuser/sphinx.conf --pidfile /home/myuser/sphinx.pid--console用来强制searchd以控制台模式启动;典型情况下searchd像一个传统的服务器应用程序那样运行,它把信息输出到(sphinx.conf配置文件中指定的)日志文件中。但有些时候需要调试配置文件或者守护程序本身的问题,或者诊断一些很难跟踪的问题,这时强制它把信息直接输出到调用他的控制台或者命令行上会使调试工作容易些。同时,以控制台模式运行还意味着进程不会fork(因此搜索操作都是串行执行的),也不会写日志文件。(要特别注意,searchd并不是被主要设计用来在控制台模式运行的)。可以这样调用searchd:$ searchd --config /home/myuser/sphinx.conf --console--iostats当使用日志时(必须在sphinx.conf中启用query_log选项)启用--iostats会对每条查询输出关于查询过程中发生的输入输出操作的详细信息,会带来轻微的性能代价,并且显然会导致更大的日志文件。更多细节请参考 query log format 一节。可以这样启动searchd:$ searchd --config /home/myuser/sphinx.conf --iostats--cpustats使实际CPU时间报告(不光是实际度量时间(wall time))出现在查询日志文件(每条查询输出一次)和状态报告(累加之后)中。这个选项依赖clock_gettime()系统调用,因此可能在某些系统上不可用。可以这样启动searchd:$ searchd --config /home/myuser/sphinx.conf --cpustats--port portnumber(可简写为-p) 指定searchd监听的端口,通常用于调试。这个选项的默认值是9312,但有时用户需要它运行在其他端口上。在这个命令行选项中指定端口比配置文件中做的任何设置优先级都高。有效的端口范围是0到65535,但要使用低于1024的端口号可能需要权限较高的账户。使用示例:$ searchd --port 9313--index <index>强制searchd只提供针对指定索引的搜索服务。跟上面的--port相同,这主要是用于调试,如果是长期使用,则应该写在配置文件中。使用示例:$ searchd --index myindex
searchd在Windows平台上有一些特有的选项,与它做为windows服务所产生的额外处理有关,这些选项只存在于Windows二进制版本。注意,在Windows上searchd默认以
--console模式运行,除非用户将它安装成一个服务。
--install将searchd安装成一个微软管理控制台(Microsoft Management Console, 控制面板 / 管理工具 / 服务)中的服务。如果一条命令指定了--install,那么同时使用的其他所有选项,都会被保存下来,服务安装好后,每次启动都会调用这些命令。例如,调用searchd时,我们很可能希望用--config指定要使用的配置文件,那么在使用--install的同时也要加入这个选项。一旦调用了这个选项,用户就可以在控制面板中的管理控制台中对searchd进行启动、停止等操作,因此一切可以开始、停止和重启服务的方法对searchd也都有效。示例:C:\WINDOWS\system32> C:\Sphinx\bin\searchd.exe --install --config C:\Sphinx\sphinx.conf如果每次启动searchd你都希望得到I/O stat信息,那就应该把这个选项也用在调用--install的命令行里:C:\WINDOWS\system32> C:\Sphinx\bin\searchd.exe --install --config C:\Sphinx\sphinx.conf --iostats--delete在微软管理控制台(Microsoft Management Console)和其他服务注册的地方删除searchd,当然之前要已经通过--install安装过searchd服务。注意,这个选项既不删除软件本身,也不删除任何索引文件。调用这个选项之后只是使软件提供的服务不能从windows的服务系统中调用,也不能在机器重启后自动启动了。如果调用时searchd正在做为服务运行中,那么现有的示例并不会被结束(一直会运行到机器重启或调用--stop)。如果服务安装时(用--servicename)指定了自定义的名字,那在调用此选项卸载服务时里也需要用--servicename指定相同的名字。示例:C:\WINDOWS\system32> C:\Sphinx\bin\searchd.exe --delete--servicename <name>在安装或卸载服务时指定服务的名字,这个名字会出现在管理控制台中。有一个默认的名字searchd,但若安装服务的系统可能有多个管理员登录,或同时运行多个searchd实例,那么起一个描述性强的名字将是个好好主意。注意,只有在与--install或者--delete同时使用的时候--servicename才有效,否则这个选项什么都不做。示例:C:\WINDOWS\system32> C:\Sphinx\bin\searchd.exe --install --config C:\Sphinx\sphinx.conf --servicename SphinxSearch--ntservice在Windows平台,管理控制台将searchd做为服务调用时将这个选项传递给它。通常没有必要直接调用这个开关,它是为Windows系统准备的,当服务启动时,系统把这个参数传递给searchd。然而理论上,你也可以用这个开关从命令行将searchd启动成普通服务模式(与--console代表的控制台模式相对)最后但并非最不重要的,类似其他的守护进程(daemon),
searchd多种信号。
- SIGTERM
- 进行一次平滑的重启。新的请求不会被接受;但是已经开始的请求不会被强行中断。
- SIGHUP
- 启动索引轮询。取决于 seamless_rotate 的设置,新的请求可能会在短期内陷入停顿;客户端将接收到临时错误。
- SIGUSR1
- 强制重新打开searchd日志和查询日志,使得日志轮询可以进行。
search是Sphinx中的一个辅助工具。searchd负责服务器类环境中的搜索,而search专注于在命令行上对索引进行快速测试,而不需要构建一个复杂的架构来处理到服务器端的连接和处理服务器返回的响应。注意:
search并不是设计用来做为客户端应用程序的一部分。我们强烈建议用户不要针对search编写接口,相反,应该针对searchd。Sphinx提供的任何客户端API也都不支持这种用法。(任何时候search总是每次都重新调入索引,而searchd会把索引缓冲在内存中以利性能)。澄清了这些我们就可以继续了。很多通过API构造的查询也可以用
search来做到,然而对于非常复杂的查询,可能还是用个小脚本和对应的API调用来实现比较简单。除此之外,可能有些新的特性先在searchd系统中实现了而尚未引入到search中。
search的调用语法如下:search [OPTIONS] word1 [word2 [word3 [...]]]调用
search并不要求searchd正在运行,只需运行search的账户对配置文件和索引文件及其所在路径有读权限即可。默认行为是对在配置文件中设置的全部索引的全部字段搜索word1(AND word2 AND word3….)。如果用API调用来构建这个搜索,那相当于向
SetMatchMode传递参数SPH_MATCH_ALL,然后在调用Query的时候指定要查询的索引是*。
search有很多选项。首先是通用的选项:
--config <file>(可简写为-c <file>) 使search使用指定的配置文件,这与上述indexer的对应选项相同。--index <index>(可简写为-i <index>) 使search仅搜索指定的索引。通常它会尝试搜索sphinx.conf中列出的全部物理索引,不包括分布式索引。--stdin使search接受标准输入(STDIN)上传入的查询,而不是命令行上给出的查询。有时你要用脚本通过管道给search传入查询,这正是这个选项的用武之地。设置匹配方式的选项:
--any(可简写为-a) 更改匹配模式,匹配指定的任意一个词(word1 OR word2 OR word3),这对应API调用中向SetMatchMode传递参数SPH_MATCH_ANY。--phrase(可简写为-p) 更改匹配模式,将指定的全部词做为一个词组(不包括标点符号)构成查询,这对应API调用中向SetMatchMode传递参数SPH_MATCH_PHRASE。--boolean(可简写为-b) 将匹配模式设为 Boolean matching。注意如果在命令行上使用布尔语法,可能需要对某些符号(用反斜线“\”)加以转义,以避免外壳程序(shell)或命令行处理器对这些符号做特殊理解,例如,在Unix/Linux系统上必须转义“&”以防止search被fork成一个后台进程,尽管这个问题也可以像下文一样通过使用--stdin选项来解决。这个选项对应API调用中向SetMatchMode传递参数SPH_MATCH_BOOLEAN。--ext(可简写为-e) 将匹配模式设为Extended matching。这对应与API调用中向SetMatchMode传递参数SPH_MATCH_EXTENDED。要注意的是因为已经有了更好的扩展匹配模式版本2,所以并不鼓励使用这个选项,见下一条说明。--ext2(可简写为-e2) 将匹配模式设为 Extended matching, version 2。这个选项对应在API调用中向SetMatchMode传递参数SPH_MATCH_EXTENDED2。要注意这个选项相比老的扩展匹配模式更有效也提供更多的特性,因此推荐使用这个新版的选项。--filter <attr> <v>(可简写为-f <attr> <v>) 对结果进行过滤,只有指定的属性attr匹配指定的值v时才能通过过滤。例如--filter deleted 0只匹配那些有deleted属性,并且其值是0的文档。也可以在命令行上多次给出--filter以便指定多重过滤,但是如果重复定义针对同一个属性的过滤器,那么第二次指定的过滤条件会覆盖第一次的。用于处理搜索结果的选项:
--limit <count>(可简写为-l count) 限制返回的最多匹配结果数。如果指定了分组(group)选项,则表示的是返回的最多匹配组数。默认值是20个结果(与API相同)--offset <count>(可简写为-o <count>) 从第count个结果开始返回,用于给搜索结果分页。如果想要每页20个结果,那么第二页就从偏移量20开始,第三页从偏移量40开始,以此类推。--group <attr>(可简写为-g <attr>) 搜索结果按照指定的属性attr进行分组。类似SQL中的GROUP BY子句,这会将attr属性值一致的结果结合在一起,返回的结果集中的每条都是一组中最好的那条结果。如果没有特别指定,那“最好”指的是相关度最大的。--groupsort <expr>(可简写为-gs <expr>) 尽搜索结果根据-group分组后,再用表达式<expr>的值决定分组的顺序。注意,这个选项指定的不是各组内部哪条结果是最好的,而是分组本身返回的顺序。--sortby <clause>(可简写为-s <clause>) 指定结果按照<clause>中指定的顺序排序。这使用户可以控制搜索结果展现时的顺序,即根据不同的列排序。例如,--sortby "@weight DESC entrytime DESC"的意思是将结果首先按权值(相关度)排序,如果有两条或以上结果的相关度相同,则他们的顺序由时间值entrytime决定,时间最近(值最大)的排在前面。通常需要将这些项目放在引号里(--sortby "@weight DESC")或者用逗号隔开(--sortby @weight,DESC),以避免它们被分开处理。另外,与通常的排序模式相同,如果指定了--group(分组),这个选项就影响分组内部的结果如何排序。--sortexpr expr(可简写为-S expr) 搜索结果展现的顺序由指定的算术表达式expr决定。例如:--sortexpr "@weight + ( user_karma + ln(pageviews) )*0.1"(再次提示,要用引号来避免shell对星号*做特殊处理)。扩展排序模式在Sorting modes 一章下的SPH_SORT_EXTENDED条目下具体讨论。--sort=date搜索结果按日期升序(日期较久远的在前)排列。要求索引中有一个属性被指定为时间戳。要求索引中有一个属性被指定为时间戳。--rsort=datespecifies that the results should be sorted by ascending (i.e. oldest first) date. This requires that there is an attribute in the index that is set as a timestamp.--sort=ts搜索结果按时间戳分成组。先返回时间戳在最近一小时内的这组结果,在组内部按相关度排序。其后返回时间戳为最近一天之内的结果,也按相关度排序。再之后是最近一周的,最后是最近一个月的。在Sorting modes 一章的SPH_SORT_TIME_SEGMENTS条目下对此有更详细的讨论。其他选项:
--noinfo(可简写为-q) 令search不在SQL数据库中查询文档信息(Document Info)。具体地说,为了调试search和MySQL共同使用时出现的问题,你可以在使用这个选项的同时提供一个根据文档ID搜索整个文章全文的查询。细节可参考sql_query_info指令。
spelldump是Sphinx的一个辅助程序。用于从
ispell或者MySpell格式的字典文件中可用来辅助建立词形列表(wordforms)的内容——词的全部可能变化都预先构造好。一般用法如下:
spelldump [options] <dictionary> <affix> [result] [locale-name]两个主要参数是词典的主文件(
[language-prefix].dict)和词缀文件([language-prefix].aff);通常这两种文件被命名为[语言简写].dict和[语言简写].aff,大多数常见的Linux发行版中都有这些文件,网上也到处找得到。
[result]指定的是字典数据的输出位置,而[locale-name]指定了具体使用的区域设置(locale)还有一个
-c [file]选项,用来指定一个包含大小写转换方面细节的文件。用法示例:
spelldump en.dict en.aff spelldump ru.dict ru.aff ru.txt ru_RU.CP1251 spelldump ru.dict ru.aff ru.txt .1251结果文件会包含字典中包含的全部词,字典序排列,wordforms文件格式。可以根据具体的使用环境定制这些文件。结果文件的一个例子:
zone > zone zoned > zoned zoning > zoning
indextool是版本0.9.9-rc2中引入的辅助工具。用于输出关于物理索引的多种调试信息。(未来还计划加入索引验证等功能,因此起名较indextool而不是indexdump)。 基本用法如下:indextool <command> [options]唯一一个所有命令都有的选项是
--config,用于指定配置文件:
--config <file>(可简写为-c <file>) 覆盖默认的配置文件名。其他可用的命令如下:
--dumpheader FILENAME.sph在设计任何其他索引文件甚至配置文件的前提下,快速输出索引头文件的内容,包括索引的全部设置,尤其是完整的属性列表、字段列表。在版本0.9.9-rc2之前,这个命令是由search工具提供的。--dumpheader INDEXNAME输出给定索引名的索引头内容,索引头文件的路径是在配置文件中查得的。--dumpdocids INDEXNAME输出给定索引名涉及的文档ID。数据是从属性文件(.spa)中抽取的,因此要求doc_info=extern正常工作。--dumphitlist INDEXNAME KEYWORD输出指定关键字KEYWORD在执行索引中的的全部出现。
2. 配置csft.conf文件
#MySQL数据源配置,详情请查看:http://www.coreseek.cn/products-install/mysql/ #请先将var/test/documents.sql导入数据库,并配置好以下的MySQL用户密码数据库 #源定义 source mysql { type = mysql sql_host = localhost sql_user = root sql_pass = 123456 sql_db = test sql_port = 3306 sql_query_pre = SET NAMES utf8 #预查询 sql_query = SELECT id, group_id,author_id, UNIX_TIMESTAMP(date_added) AS date_added, title, content FROM documents #主查询-查询的数据将被索引sql_query第一列id需为整数 sql_attr_uint = author_id #title、content作为字符串/文本字段,被全文索引 sql_attr_uint = group_id #从SQL读取到的值必须为整数 sql_attr_timestamp = date_added #从SQL读取到的值必须为整数,作为时间属性 sql_query_info_pre = SET NAMES utf8 #命令行查询时,设置正确的字符集 sql_query_info = SELECT * FROM documents WHERE id=$id #命令行查询时,从数据库读取原始数据信息 #区段查询 每次查询一段数据来建立索引 #sql_query_range = SELECT MIN(id),MAX(id) FROM documents #sql_range_step = 1000 #sql_query = SELECT * FROM documents WHERE id>=$start AND id<=$end } #index定义 index mysql { source = mysql #对应的source名称 path = C:/coreseek-3.2.14-win32/var/data/mysql/ #请修改为实际使用的绝对路径,例如:/usr/local/coreseek/var/... docinfo = extern mlock = 0 morphology = none min_word_len = 1 html_strip = 0 #中文分词配置,详情请查看:http://www.coreseek.cn/products-install/coreseek_mmseg/ #charset_dictpath = /usr/local/mmseg3/etc/ #BSD、Linux环境下设置,/符号结尾 charset_dictpath = C:/coreseek-3.2.14-win32/etc/ #Windows环境下设置,/符号结尾,最好给出绝对路径,例如:C:/usr/local/coreseek/etc/... charset_type = zh_cn.utf-8 } #全局index定义 indexer { mem_limit = 128M } #searchd服务定义 searchd { listen = 9312 read_timeout = 5 max_children = 30 max_matches = 1000 seamless_rotate = 0 preopen_indexes = 0 unlink_old = 1 pid_file = C:/coreseek-3.2.14-win32/var/log/searchd_mysql.pid #请修改为实际使用的绝对路径,例如:/usr/local/coreseek/var/... log = C:/coreseek-3.2.14-win32/var/log/searchd_mysql.log #请修改为实际使用的绝对路径,例如:/usr/local/coreseek/var/... query_log = C:/coreseek-3.2.14-win32/var/log/query_mysql.log #请修改为实际使用的绝对路径,例如:/usr/local/coreseek/var/... }
详细官方文档:http://www.coreseek.cn/products-install/mysql/
生成索引
将MYSQL数据源中的数据查询到sphinx中,再根据配置文件csft.conf配置的索引index进行索引生成,索引一般分为主索引、增量索引和实时索引。一般20W条的MYSQL数据行生成索引的时间为2分钟左右(indexer命令详见以上)
C:\coreseek-3.2.14-win32\bin\indexer -c C:\coreseek-3.2.14-win32\csft.conf --all
使用API进行测试
将api/sphinxapi.php包含到PHP文件中就可以使用API程序调用coreseek了,1000W的数据行中,使用API调用全文检索返回的时间<500ms,使用接口的相关参数比如可以控制搜索返回行数、分组排序、限制条件等,从sphinx返回 ids(MYSQL数据库表中的主键),根据ids可以到MYSQL中检索到需要的数据。

一段PHP的测试代码
include 'sphinxapi.php'; $sp = new SphinxClient; $sp->SetServer('127.0.0.1', 9314); $sp->SetConnectTimeout(5); $sp->SetLimits(0, 10);//($start, $limit); $keyword=(isset($_GET['kw'])&& !empty($_GET['kw'])) ?trim($_GET['kw']) : '搜索内容'; //在执行搜索之前,可以加入各种条件 $result=$sp>Query($keyword,'iiyicms');//'*‘ 'iiyicms:iiyicms_increment'


