服务发现-从原理到实现

服务发现,作为互联网从业人员,大家应该都不陌生,一个完善的服务集群,微服务是必不可少的功能之一。
最近一直想写这个话题,也一直在构思,但不知道从何入手,或者说不知道写哪方面。如果单纯写如何实现,这个未免太乏味枯燥了;而如果只是介绍现有成熟方案呢,却达不到我的目的。想了很久,准备先从微服务的架构入手,切入 服务发现 要解决什么问题,搭配常见的处理模式,最后介绍下现有的处理方案。
微服务服务于分布式系统,是个分散式系统。服务部署跨主机、网段、机房乃至大区。各个服务之间通过RPC(remote procedure call)进行调用。然后,在架构上最重要的一环,就是服务发现。如果说服务发现是微服务架构的灵魂也当之无愧,试想一下,当一个系统被拆分成多个服务,且被大量部署的时候,有什么能比"找到"想调用的服务在哪里,以及能否正常提供服务重要呢?同样的,有新服务启动时,如何让其他服务知道该服务在哪里?
微服务考研的是治理大量服务的能力,包含多种服务,同样也包含多个实例。
1概念
服务发现之所以重要,是因为它解决了微服务架构最关键的问题:如何精准的定位需要调用的服务ip以及端口。无论使用哪种方式来提供服务发现功能,大致上都包含以下三点:
- Register, 服务启动时候进行注册
- Query, 查询已注册服务信息
- Healthy Check,确认服务状态是否健康
整个过程很简单。大致就是在服务启动的时候,先去进行注册,并且定时反馈本身功能是否正常。由服务发现机制统一负责维护一份正确或者可用的服务清单。因此,服务本身需要能随时接受查下,反馈调用方服务所要的信息。
2注册模式
一整套服务发现机制顺利运行,首先就得维护一份可用的服务列表。包含服务注册与移除功能,以及健康检查。服务是如何向注册中心"宣告"自身的存在?健康检查,是如何确认这些服务是可用的呢?
做法大致分为两类:
-
自注册模式 自注册,顾名思义,就是上述这些动作,有服务(client)本身来维护。每个服务启动后,需要到统一的服务注册中心进行注册登记,服务正常终止后,也可以到注册中心移除自身的注册记录。在服务执行过程中,通过不断的发送心跳信息,来通知注册中心,本服务运行正常。注册中心只要超过一定的时间没有收到心跳消息,就可以将这个服务状态判断为异常,进而移除该服务的注册记录。
-
三方注册模式 这个模式与自注册模式相比,区别就是健康检查的动作不是有服务本身(client)来负责,而是由其它第三方服务来确认。有时候服务自身发送心跳信息的方式并不精确,因为可能服务本身已经存在故障,某些接口功能不可用,但仍然可以不断的发送心跳信息,导致注册中心没有发觉该服务已经异常,从而源源不断的将流量打到已经异常的服务上来。
这时候,要确认服务是否正常运转的健康检查机制,就不能只依靠心跳,必须通过其它第三方的验证(ping),不断的从外部来确认服务本身的健康状态。
这些都是有助于协助注册中心提高服务列表精确到的方法。能越精确的提高服务清单状态的可靠性,整套微服务架构的可靠度就会更高。这些方法不是互斥的,在必要的时候,可以搭配使用。
3发现模式
服务发现的发现机制主要包括三种:
-
服务提供者:服务启动时将服务信息注册到注册中心,服务退出时将注册中心的服务信息删除掉。
-
服务消费者:从服务注册表获取服务提供者的最新网络位置等服务信息,维护与服务提供者之间的通信。
-
注册中心:服务提供者和服务消费者之间的一个桥梁
服务发现机制的关键部分是注册中心。注册中心提供管理和查询服务注册信息的API。当服务提供者的实例发生变更时(新增/删除服务),服务注册表更新最新的状态列表,并将其最新列表以适当的方式通知给服务消费者。目前大多数的微服务框架使用Netflix Eureka、Etcd、Consul或Apache Zookeeper等作为注册中心。
为了说明服务发现模式是如何解决微服务实例地址动态变化的问题,下面介绍两种主要的服务发现模式:
- 客户端发现模式
- 服务端发现模式。
客户端模式与服务端模式,两者的本质区别在于,客户端是否保存服务列表信息。
客户端发现模式
在客户端模式下,如果要进行微服务调用,首先要进行的是到服务注册中心获取服务列表,然后再根据调用端本地的负载均衡策略,进行服务调用。
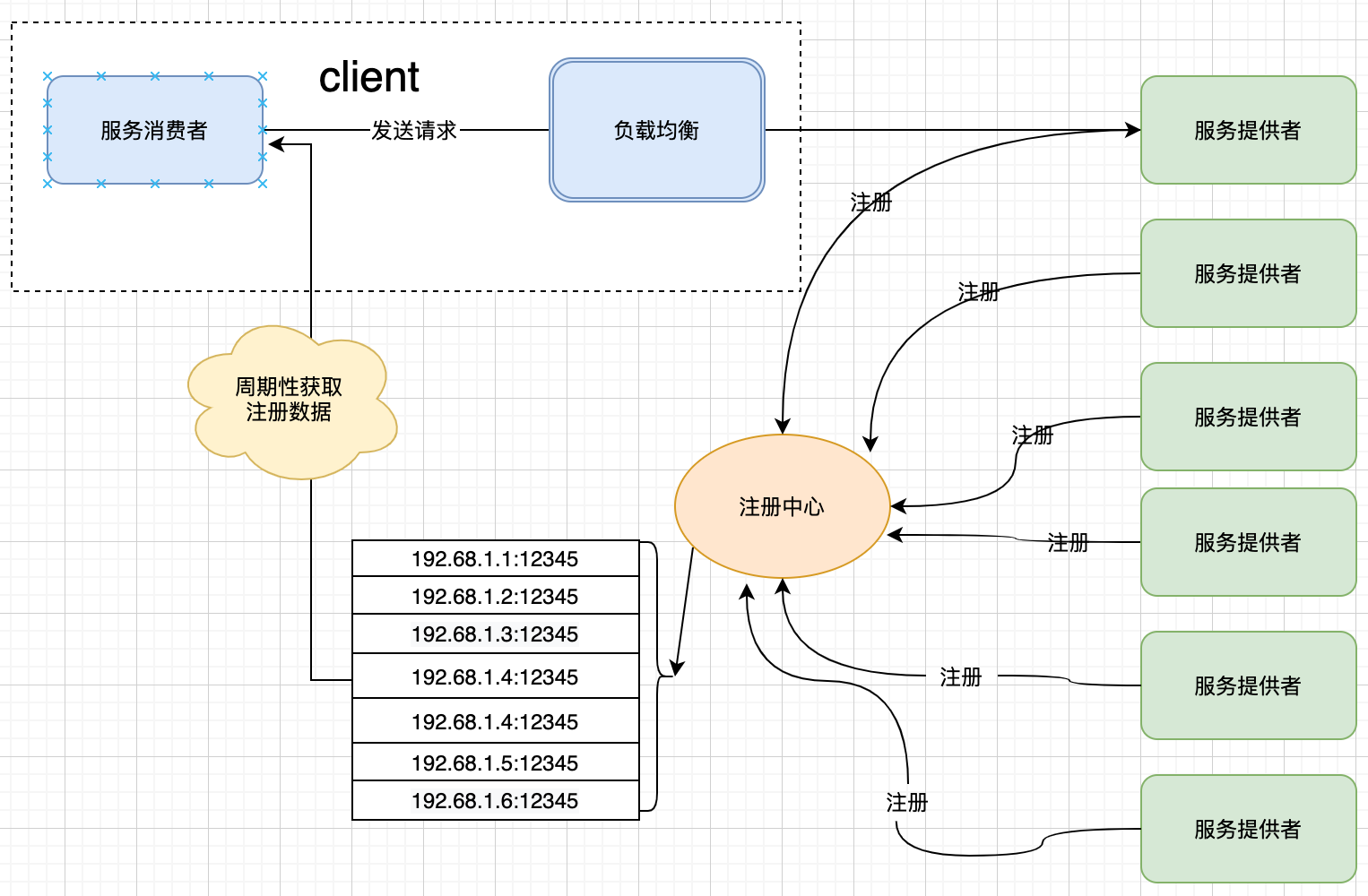
在上图中,client端提供了负载均衡的功能,其首先从注册中心获取服务提供者的列表,然后通过自身负载均衡算法,选择一个最合理的服务提供者进行调用:
1、 服务提供者向注册中心进行注册,提交自己的相关信息
2、 服务消费者定期从注册中心获取服务提供者列表
3、 服务消费者通过自身的负载均衡算法,在服务提供者列表里面选择一个合适的服务提供者,进行访问
客户端发现模式的优缺点如下:
-
优点:
- 负载均衡作为client中一个功能,用自身的算法,从服务提供者列表中选择一个合适服务提供者进行访问,因此client端可以定制化负载均衡算法。优点是服务客户端可以灵活、智能地制定负载均衡策略,包括轮询、加权轮询、一致性哈希等策略。
- 可以实现点对点的网状通讯,即去中心化的通讯。可以有效避开单点造成的性能瓶颈和可靠性下降等问题。
- 服务客户端通常以SDK的方式直接引入到项目,这种方式语言的整合程度最佳,程序执行性能最佳,程序错误排查更加容易。
-
缺点:
- 当负载均衡算法需要更新时候,很难做到同一时间全部更新,所以就造成新旧算法同时运行
- 与注册中心紧密耦合,如果要换注册中心,需要去修改代码,重新上线。微服务的规模越大,服务更新越困难,这在一定程度上违背了微服务架构提倡的技术独立性。
目前来说,大部分服务发现的实现都采取了客户端模式。
服务端发现模式
在服务端模式下,调用方直接向服务注册中心进行请求,服务注册中心再通过自身负载均衡策略,对微服务进行调用。这个模式下,调用方不需要在自身节点维护服务发现逻辑以及服务注册信息。
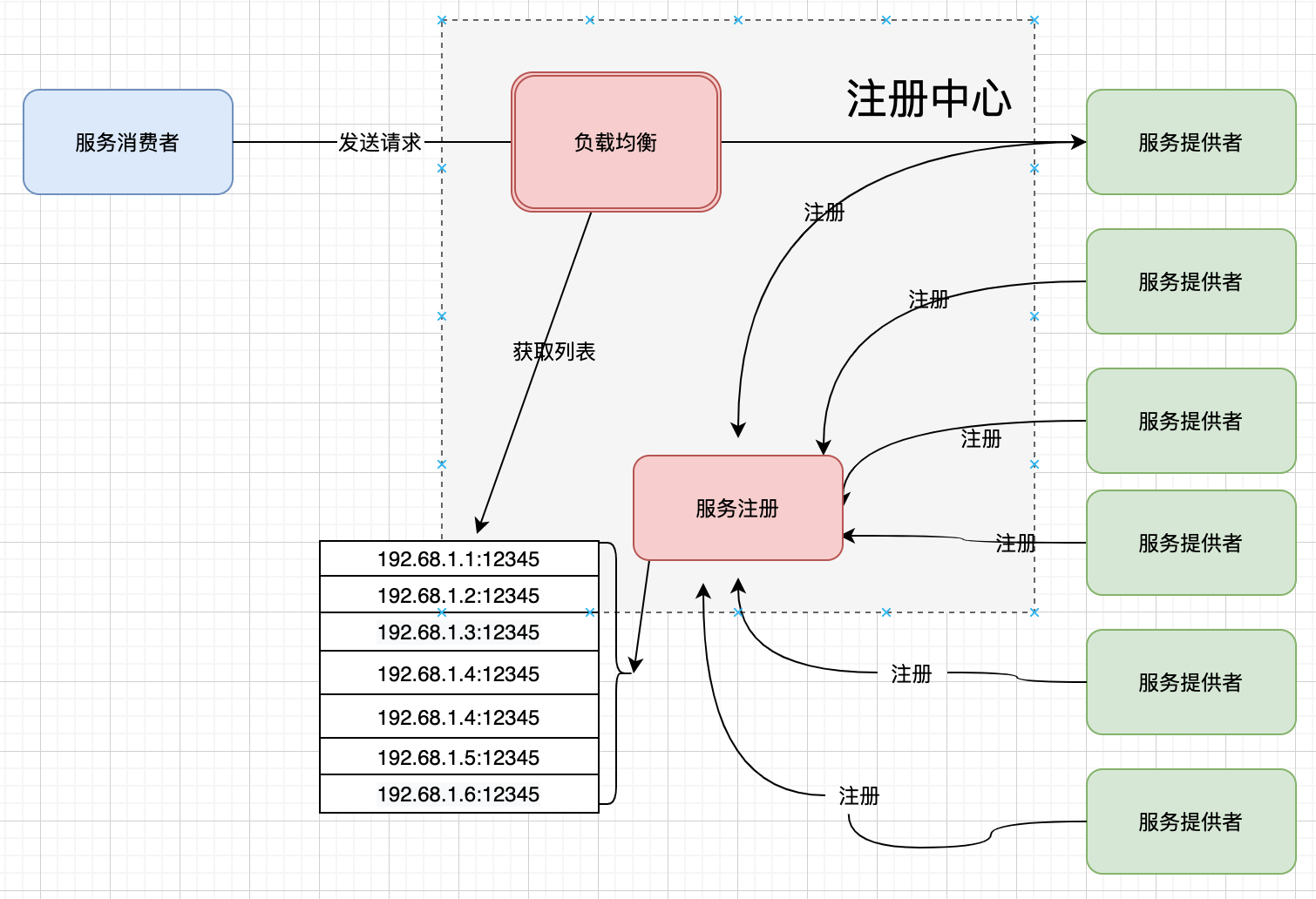
在服务端模式下: 1、 服务提供者向注册中心进行服务注册 2、 注册中心提供负载均衡功能, 3、 服务消费者去请求注册中心,由注册中心根据服务提供列表的健康情况,选择合适的服务提供者供服务消费者调用
现代容器化部署平台(如Docker和Kubernetes)就是服务端服务发现模式的一个例子,这些部署平台都具有内置的服务注册表和服务发现机制。容器化部署平台为每个服务提供路由请求的能力。服务客户端向路由器(或者负载均衡器)发出请求,容器化部署平台自动将请求路由到目标服务一个可用的服务实例。因此,服务注册,服务发现和请求路由完全由容器化部署平台处理。
服务端发现模式的特点如下:
- 优点:
- 服务消费者不需要关心服务提供者的列表,以及其采取何种负载均衡策略
- 负载均衡策略的改变,只需要注册中心修改就行,不会出现新老算法同时存在的现象
- 服务提供者上下线,对于服务消费者来说无感知
- 缺点:
- rt增加,因为每次请求都要请求注册中心,尤其返回一个服务提供者
- 注册中心成为瓶颈,所有的请求都要经过注册中心,如果注册服务过多,服务消费者流量过大,可能会导致注册中心不可用
- 微服务的一个目标是故障隔离,将整个系统切割为多个服务共同运行,如果某服务无法正常运行,只会影响到整个系统的相关部分功能,其它功能能够正常运行,即去中心化。然而,服务端发现模式实际上是集中式的做法,如果路由器或者负载均衡器无法提供服务,那么将导致整个系统瘫痪。
4实现方案
file
以文件的形式实现服务发现,这是一个比较简单的方案。其基本原理就是将服务提供者的信息(ip:port)写入文件中,服务消费者加载该文件,获取服务提供者的信息,根据一定的策略,进行访问。
需要注意的是,因为以文件形式提供服务发现,服务消费者要定期的去访问该文件,以获得最新的服务提供者列表,这里有个小优化点,就是可以有个线程定时去做该任务,首先去用该文件的最后一次修改时间跟服务上一次读取文件时候存储的修改时间做对比,如果时间一致,表明文件未做修改,那么就不需要重新做加载了,反之,重新加载文件。
文件方式实现服务发现,其特点显而易见:
- 优点:实现简单,去中心化
- 缺点:需要服务消费者去定时操作,如果某一个文件推送失败,那么就会造成异常现象
zookeeper
ZooKeeper 是一个集中式服务,用于维护配置信息、命名、提供分布式同步和提供组服务。
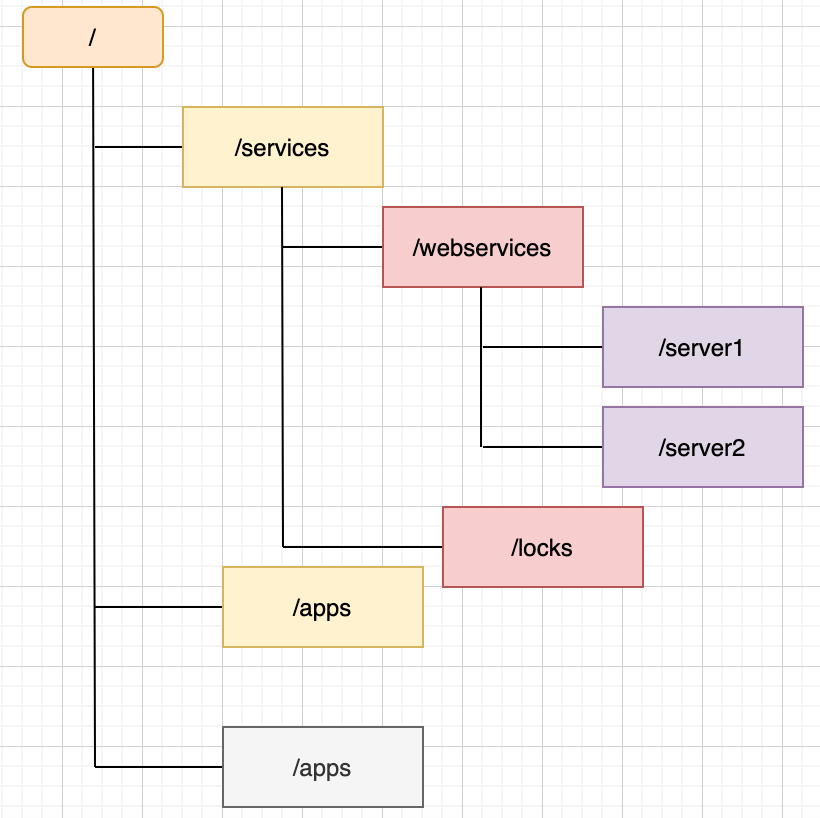 zookeeper 树形结构
zookeeper 树形结构
zookeeper是一个树形结构,如上图所示。
使用zookeeper实现服务发现的功能,简单来讲,就是使用zookeeper作为注册中心。服务提供者在启动的时候,向zookeeper注册其信息,这个注册过程其实就是实际上在zookeeper中创建了一个znode节点,该节点存储了ip以及端口等信息,服务消费者向zookeeper获取服务提供者的信息。 服务注册、发现过程简述如下:
- 服务提供者启动时,会将其服务名称,ip地址注册到配置中心
- 服务消费者在第一次调用服务时,会通过注册中心找到相应的服务的IP地址列表,并缓存到本地,以供后续使用。当消费者调用服务时,不会再去请求注册中心,而是直接通过负载均衡算法从IP列表中取一个服务提供者的服务器调用服务
- 当服务提供者的某台服务器宕机或下线时,相应的ip会从服务提供者IP列表中移除。同时,注册中心会将新的服务IP地址列表发送给服务消费者机器,缓存在消费者本机
- 当某个服务的所有服务器都下线了,那么这个服务也就下线了
- 同样,当服务提供者的某台服务器上线时,注册中心会将新的服务IP地址列表发送给服务消费者机器,缓存在消费者本机
- 服务提供方可以根据服务消费者的数量来作为服务下线的依据
服务注册
假设我们服务提供者的服务名称为services,首先在zookeeper上创建一个path /services,在服务提供者启动时候,向zookeeper进行注册,其注册的原理就是创建一个路径,路径为/services/$ip:port,其中ip:port为服务提供者实例的ip和端口。如下图所示,我们现在services实例有三个,其ip:port分别为192.168.1.1:1234、192.168.1.2:1234、192.168.1.3:1234和192.168.1.4:1234,如下图所示: 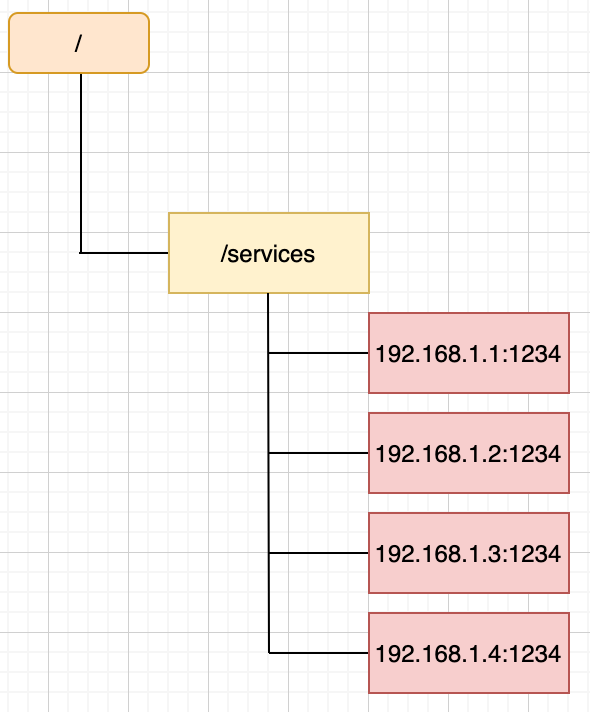
健康检查
zookeeper实现了一种TTL的机制,就是如果客户端在一定时间内没有向注册中心发送心跳,则会将这个客户端摘除。
获取服务提供者的列表
前面有提过,zookeeper实际上是一个树形结构,那么服务消费者是如何获取到服务提供者的信息呢?最重要的也是必须的一点就是 知道服务提供者信息的父节点路径。以上图为例,我们需要知道
/services
通过zookeeper client提供的接口 getchildren(path)来获取所有的子节点。
感知服务上线与下线
zookeeper提供了“心跳检测”功能,它会定时向各个服务提供者发送一个请求(实际上建立的是一个 socket 长连接),如果长期没有响应,服务中心就认为该服务提供者已经“挂了”,并将其剔除,比如192.168.1.2这台机器如果宕机了,那么zookeeper上的路径/services/下就会只剩下192.168.1.1:1234, 192.168.1.2:1234,192.168.1.4:1234。如下图所示:
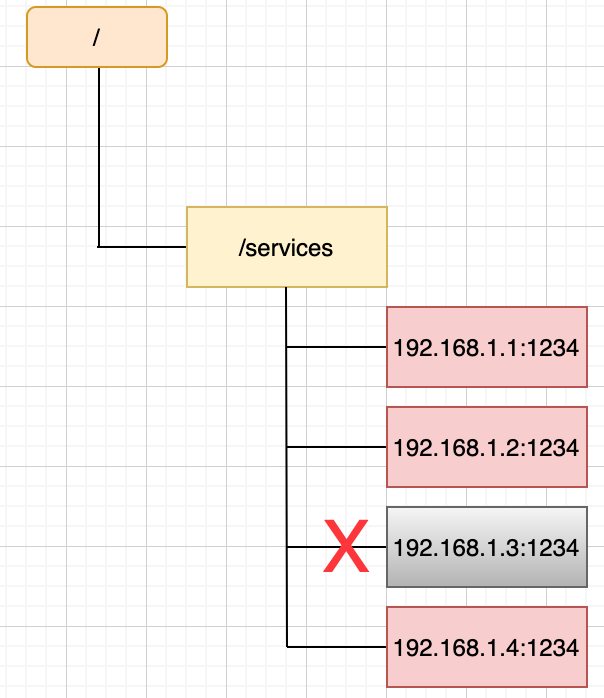 服务下线
服务下线
假设此时,重新上线一个实例,其ip为192.168.1.5,那么此时zookeeper树形结构如下图所示:
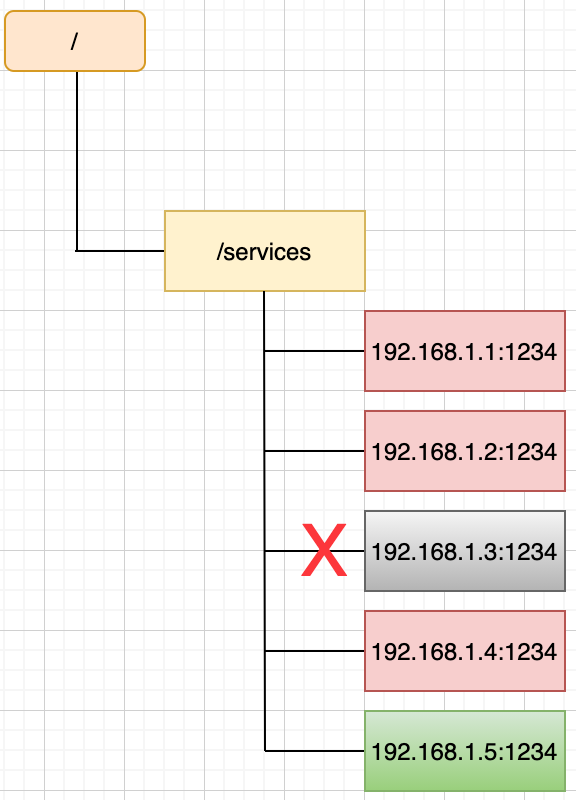 服务上线
服务上线
服务消费者会去监听相应路径(/services),一旦路径上的数据有任务变化(增加或减少),zookeeper都会通知服务消费方服务提供者地址列表已经发生改变,从而进行更新。
实现
下面是服务提供者在zookeeper注册中心注册时候的核心代码:
int ZKClient::Init(const std::string& host, int timeout,
int retry_times) {
host_ = host;
timeout_ = timeout;
retry_times_ = retry_times;
hthandle_ = zookeeper_init(host_.c_str(), GlobalWatcher, timeout_,
NULL, this, 0);
return (hthandle_ != NULL) ? 0 : -1;
}
int ZKClient::CreateNode(const std::string& path,
const std::string& value,
int type) {
int flags;
if (type == Normal) {
flags = 0;
} else if (type == Ephemeral) {
flags = ZOO_EPHEMERAL;
} else {
return -1;
}
int ret = zoo_exists(hthandle_, path.c_str(), 0, NULL);
if (ret == ZOK) {
return -1;
}
if (ret != ZNONODE) {
return -1;
}
ret = zoo_create(hthandle_, path.c_str(), value.c_str(), value.length(),
&ZOO_OPEN_ACL_UNSAFE, flags, NULL, 0);
return ret == ZOK ? 0 : -1;
}
int main() {
std::string ip; // 当前服务ip
int port; // 当前服务的端口
std::string path = "/services/" + ip + ":" + std::to_string(port);
ZKClient zk;
zk.init(...);
//初始化zk客户端
zk.CreateNode(path, "", Ephemeral);
...
return 0
}
上面是服务提供者所做的一些操作,其核心功能就是:
在服务启动的时候,使用zookeeper的客户端,创建一个临时(Ephemeral)节点
从代码中可以看出,创建znode的时候,指定了其node类型为Ephemeral,这块非常重要,在zookeeper中,如果znode类型为Ephemeral,表明,在服务提供者跟注册中心断开连接的时候,这个节点会自动小时,进而注册中心会通知服务消费者重新获取服务提供者列表。
下面是服务消费者的核心代码:
int ZKClient::Init(const std::string& host, int timeout,
int retry_times) {
host_ = host;
timeout_ = timeout;
retry_times_ = retry_times;
hthandle_ = zookeeper_init(host_.c_str(), GlobalWatcher, timeout_,
NULL, this, 0);
return (hthandle_ != NULL) ? 0 : -1;
}
int ZKClient::GetChildren(const std::string& path,
const std::function<int(const std::vector<std::tuple<std::string, std::string>>)>& on_change,
std::vector<std::tuple<std::string, std::string>>* children) {
std::lock_guard<std::recursive_mutex> lk(mutex_);
int ret = zoo_get_children(handle, path, 1, children); // 通过来获取子节点
if (ret == ZOK) {
node2children_[path] = std::make_tuple(on_change, *children); // 注册事件
}
return ret;
}
int main() {
ZKClient zk;
zk.Init(...);
std::vector children
// 设置回调通知,即在某个path下子节点发生变化时,进行通知
zk.GetChildren("/services", callback, children);
...
return 0;
}
对于服务消费者来说,其需要有两个功能:
- 获取服务提供者列表
- 在服务提供者列表发生变化时,能得到通知
其中第一点可以通过
zoo_get_children(handle, path, 1, children);
来获取列表,那么如何在服务提供者列表发生变化时得到通知呢? 这就用到了zookeeper中的watcher机制。
watcher目的是在 znode 以某种方式发生变化时得到通知。watcher仅被触发一次。 如果您想要重复通知,您将需要重新注册观察者。 读取操作(例如exists、get_children、get_data)可能会创建监视。
okeeper中的watcher机制,不在本文的讨论范围内,有兴趣的读者,可以去查阅相关书籍或者资料。
下面,我们对使用zookeeper作为注册中心,服务提供者和消费者需要做的操作进行下简单的总结:
- 服务提供者
- 在服务启动的时候,使用zookeeper的客户端,创建一个临时(Ephemeral)节点
- 服务消费者
- 通过zoo_get_children获取子节点
- 注册watcher回调,在path下发生变化时候,会直接调用该回调函数,在回调函数内重新获取子节点,并重新注册回调
etcd
Etcd是基于Go语言实现的一个KV结构的存储系统,支持服务注册与发现的功能,官方将其定义为一个可信赖的分布式键值存储服务,主要用于共享配置和服务发现。其特点如下:
- :安装配置简单,而且提供了 HTTP API 进行交互,使用也很简单 键值对存储:
- 据存储在分层组织的目录中,如同在标准文件系统中
- 变更:监测特定的键或目录以进行更改,并对值的更改做出反应
- :根据官方提供的 benchmark 数据,单实例支持每秒 2k+ 读操作
- :采用 Raft 算法,实现分布式系统数据的可用性和一致性
服务注册
每一个服务器启动之后,会向Etcd发起注册请求,同时将自己的基本信息发送给 etcd 服务器。服务器的信息是通过KV键值进行存储。key 是用户真实的 key, value 是对应所有的版本信息。keyIndex 保存 key 的所有版本信息,每删除一次都会生成一个 generation,每个 generation 保存了这个生命周期内从创建到删除中间的所有版本号。
更新数据时,会开启写事务。
- 会根据当前版本的key,rev在 keyindex 中查找是否有当前 key 版本的记录。主要获取 created 与 ver 的信息。
- 生成新的 KeyValue 信息。
- 更新 keyindex 记录。
健康检查
在注册时,会初始化一个心跳周期 ttl 与租约周期 lease。服务器需要在心跳周期之内向 etcd 发送数据包,表示自己能够正常工作。如果在规定的心跳周期内,etcd 没有收到心跳包,则表示该服务器异常,etcd 会将该服务器对应的信息进行删除。如果心跳包正常,但是服务器的租约周期结束,则需要重新申请新的租约,如果不申请,则 etcd 会删除对应租约的所有信息。
在 etcd 中,并不是在磁盘中删除对应的 keyValue 信息,而是对其进行标记删除。
- 首先在 delete 中会生成一个 ibytes,对其追加标记,表示这个 revision 是 delete。
- 生成一个 KeyValue,该 KeyValue 只包含Key的信息。
- 同时修改 Tombstone 标志位,结束当前生命周期,生成一个新的 generation,更新 kvindex。
再次需要做个说明,因为笔者是从事c++开发的,现在线上业务用的zookeeper来作为注册中心实现服务发现功能。上半年的时候,也曾想转到etcd上,但是etcd对c++并不友好,笔者用了将近两周时间各种调研,编译,发现竟然不能将其编译成为一个静态库...
需要特别说明的是,用的是etcd官网推荐的c++客户端etcd-cpp-apiv3
纵使etcd功能再强大,不能支持c++,算是一个不小的遗憾。对于笔者来说,算是个损失吧,希望后续能够支持。
下面是etcd c++ client 不支持静态库,作者以及其他使用者的反馈,以此作为本章节的结束。
 etcd官网指定的c++client
etcd官网指定的c++client 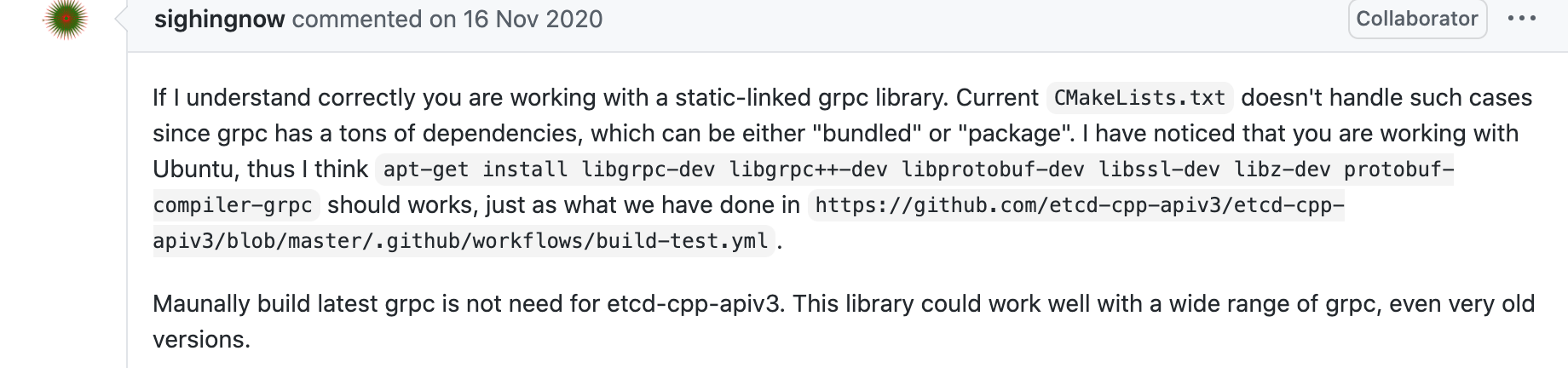 作者回复
作者回复  使用者反馈
使用者反馈
5结语
微服务架构模式下,服务实例动态配置,因此服务消费者需要动态了解到服务提供者的变化,所以必须使用服务发现机制。
服务发现的关键部分是注册中心。注册中心提供注册和查询功能。目前业界开源的有Netflix Eureka、Etcd、Consul或Apache Zookeeper,大家可以根据自己的需求进行选择。
服务发现主要有两种发现模式:客户端发现和服务端发现。客户端发现模式要求客户端负责查询注册中心,获取服务提供者的列表信息,使用负载均衡算法选择一个合适的服务提供者,发送请求。服务端发现模式,客户端每次都请求注册中心,由注册中心内部选择一个合适的服务提供者,并将请求转发至该服务提供者,需要注意的是 当一个请求过来的时候,注册中心内部获取服务提供者列表和使用负载均衡算法。
这个世界没有完美的架构和模式,不同的场景都有适合的解决方案。我们在调研决策的时候,一定要根据实际情况去权衡对比,选择最适合当前阶段的方案,然后通过渐进迭代的方式不断完善优化方案。
> 关注公众号【高性能架构探索】,第一时间获取干货;回复【pdf】,免费获取计算机经典书籍

